Разработка и применение программного обеспечения в физических исследованиях
Вячеслав Федоров, ИЯФ СО РАН
Для студентов физических специальностей и начинающих ИТ-специалистов, которые хотят познакомиться с Python, Linux, DevOps и SRE.
Цель этой книги — помочь тебе научиться писать более красивые, надёжные и легко сопровождаемые программы для физических исследований. То, о чём мы здесь будем говорить, это не начальный уровень, предполагается, что ты уже знаешь основы физики, минимально умеешь программировать, и хочешь научиться делать это лучше.
И это — отличная цель, к которой мы вместе будем двигаться!
Часто на физических факультетах не уделяется должного внимания IT-дисциплинам, в то время как они очень важны и могут значительно улучшить качество твоих исследований.
В ревью кода моих коллег часто видны результаты того, что в учебных материалах не уделяется отдельное внимание вопросам качества кода. Качество программы и её надёжность страдают — а это гораздо более важные параметры, чем многие поначалу думают. Поначалу кажется, что я написал программу, она в моих идеальных условиях работает и этого достаточно. Но нет, этого недостаточно. Наличие функциональности это одно, а надёжность этой функциональности и качество реализации этой функциональности это совсем другое. То, что мы написали программу и она имеет функциональность — это вовсе не означает, что программа действительно хороша. В этой небольшой книге мы поговорим о том, как разрабатывать, думая не только о функциональности, но и о качестве и надёжности её реализации.
Цели книги:
- Познакомиться с основами Linux: Изучить архитектуру операционной системы GNU/Linux, файловые системы, процессы загрузки и методы управления дисками.
- Освоить Python: Погрузиться в мир программирования на Python, изучить синтаксис, использование интерактивной оболочки IPython и применять язык для решения физических задач.
- Изучить DevOps и SRE: Разобраться в жизненном цикле программного обеспечения, управлении версиями, автоматизации процессов разработки и обеспечения надежности систем.
- Научиться работать с базами данных: Понять различные системы управления базами данных (СУБД) и их применение в реальных проектах.
- Освоить инструменты для обработки и анализа данных: Изучить библиотеки NumPy, SciPy, Pandas, Matplotlib и другие для эффективного анализа больших данных.
- Погрузиться в машинное обучение и нейронные сети: Изучить базовые алгоритмы классификации и основы работы с нейронными сетями для обработки данных физических экспериментов.
- Оптимизировать производительность программ: Научиться измерять время выполнения кода, использовать параллельные вычисления и работать с GPU для ускорения обработки данных.
Общие знания
Введение в алгоритмы
Одна из основных задач при работе с алгоритмами — оценка эффективности программы и поиск наиболее экономичного подхода. Самое простое и поверхностное решение этой задачи — написать программу и замерить время её выполнения. Программа тормозит? Изменить программу, оптимизировав решение.
Линейный поиск
Дан массив целых чисел длины $N$. Нужно найти в нём заданное число $x$ и вернуть его индекс. Если $x$ в массиве не встречается — вернуть -1.
def find_element(numbers, x):
for i in range(len(numbers)):
if numbers[i] == x:
return i
return -1
Можем сказать, что скорость работы алгоритма в худшем случае пропорциональна размеру массива. На математическом языке ещё говорят: «Вычислительная сложность алгоритма линейно зависит от размера входных данных».
Разберём эту фразу:
Вычислительная сложность алгоритма. Обычно под этой фразой понимают количество элементарных операций, которые будут совершены.
Размер входных данных. Входные данные — то, что алгоритм получает на вход. В нашей задаче это массив numbers и переменная x. Размер входных данных примерно равен N.
Линейная зависимость. Описывается формулой $y = kx+b$.
Бинарный поиск
Есть и другой способ решить задачу поиска элемента в массиве. Если элементы в массиве упорядочены по возрастанию, то найти нужный можно гораздо быстрее.
Допустим, мы хотим применить этот алгоритм к словарю из 100 страниц. Объём рассматриваемой части книги будет каждый раз уменьшаться вдвое до тех пор, пока не останется всего одна страница. Делить словарь из 100 страниц пополам мы можем максимум 7 раз. Получается, чтобы найти нужное слово, нам достаточно будет просмотреть не более 7 страниц.
Рассмотренный алгоритм называется бинарным поиском. Ещё его называют: двоичный поиск, метод деления пополам, дихотомия. Скорость его работы имеет логарифмическую зависимость от размера входных данных.
def binary_search(arr, x):
mid, low, high = 0, 0, len(arr) - 1
while low <= high:
mid = (high + low) // 2
if arr[mid] < x:
low = mid + 1
elif arr[mid] > x:
high = mid - 1
else:
return mid
return -1
Линейный vs Бинарный поиск
Запустим линейный и бинарный поиск на одинаковых данных и посмотрим, как меняется время работы в зависимости от размера массива, в котором производится поиск:
| Размер массива | Линейный поиск | Бинарный поиск |
|---|---|---|
| 10 элементов | 0.01 с. | 0.01 с. |
| 100 элементов | 0.1 с. | 0.02 с. |
| 1 000 элементов | 0.9 с. | 0.03 с. |
| 10 000 элементов | 9.75 с. | 0.06 с. |
| 100 000 элементов | 67.25 с. | 0.45 с. |
arr = [x for x in range(10_000)]
x = 999
%timeit find_element(arr, x)
37.4 µs ± 1.98 µs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
%timeit binary1.39 µs ± 44 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)1.39 µs ± 44 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)_search(arr, x)
1.39 µs ± 44 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
Сложность алгоритма. О-нотация
В О-нотации не учитываются константы и коэффициенты. То есть если в алгоритме совершается $5\cdot n+3$ операций, его сложность будет $O(n)$. В асимптотической оценке не учитываются значения констант при $n$. Нельзя сказать, что константы совсем уж не важны, но они не могут принципиально изменить применимость алгоритма на практике.
Кроме линейной и логарифмической, при оценке времени работы алгоритмов часто встречаются ещё такие зависимости:
- Квадратичная зависимость — $O(n^2)$.
- Кубическая зависимость — $O(n^3)$.
- Экспоненциальная зависимость — $O(2^n)$.
- Константная зависимость — $O(1)$. Бывает и так, что время работы алгоритма не зависит от размера входных данных, и в любом случае выполняется константное количество операций.
Как оценивать время исполнения
Теперь нужно понять, как быстро работает компьютер. Современный процессор выполняет около 2.5 миллиардов действий (их называют «инструкциями») в секунду. Или «тактовая частота процессора = 2.5 ГГц».
Если говорить немного точнее, за секунду проходит 2.5 миллиарда тактов. Как метроном задаёт ритм музыки, так же специальный генератор тактовой частоты задаёт ритм, в котором работают процессор и микросхемы компьютера. В первом приближении можно считать, что один такт соответствует одной инструкции.
Предположим, что обработка каждой итерации цикла занимает один такт процессора. Возьмем $10^9$ итераций, тогда:
$$ t = \frac{10^9 [итер] \cdot 1 [\frac{такт}{итер}]}{2.5 \cdot 10^9 [\frac{такт}{с}]} = 0.4 [с] $$
Количество инструкций в программе может немного отличаться в зависимости от процессора или от использованного компилятора. Бывают команды, которым требуется несколько тактов, а другие инструкции, наоборот, справляются за доли такта.
Получается, даже если бы мы хотели узнать константы в оценке временной сложности алгоритма, мы бы не смогли это сделать — слишком много нюансов пришлось бы учесть. Это ещё одна причина, почему мы пользуемся О-нотацией и опускаем константы. Но это не значит, что нельзя уменьшить константу, сократив число действий.
Чтобы оценить, во сколько раз мы ошиблись в действительности, измерим, сколько секунд займёт цикл, который миллиард раз не делает ничего.
# Python
import time
time_start = time.time()
i = 0
while i < 1000000000:
# Do nothing
i += 1
time_finish = time.time()
time_span = time_finish - time_start
print(time_span, 'seconds')
97.01491403579712 seconds
// CPP
#include <chrono>
#include <iostream>
int main() {
using namespace std::chrono;
auto time_start = high_resolution_clock::now();
int i = 0;
while (i < 1000000000) {
// Do nothing
++i;
}
auto time_finish = high_resolution_clock::now();
auto time_span = duration_cast<duration<double>>(time_finish - time_start);
std::cout << time_span.count() << " seconds\n";
return 0;
}
Каждая итерация цикла состоит из трёх действий: прибавить единицу, проверить условие и переместиться обратно к началу цикла. Три миллиарда команд должны занимать приблизительно 1 секунду. Программа на C++ работает почти столько же времени. А вот аналогичная программа на Python выполняется около 100 секунд, то есть в сто раз медленнее. Так происходит, поскольку код на языках низкого уровня почти один к одному транслируется в инструкции процессору.
Пространственная сложность алгоритма
Поговорили про понятие вычислительной (или временнóй) сложности, которое определяет, насколько эффективно алгоритм использует процессорное время. Ещё одна важная характеристика — объём оперативной памяти. Программы, которым не хватает памяти, будут зависать и мешать работе других программ. А во многих случаях и вовсе не смогут доделать свою работу до конца.
Если программе не хватает оперативной памяти, она пытается использовать файл подкачки, или swap-раздел (от англ. swap — «подкачивать»), расположенный во внешней памяти (на жёстком диске или на SSD-диске). При недостатке оперативной памяти программа начинает перекладывать данные из небольшой, но быстрой оперативной памяти на большой, но медленный диск. И по мере необходимости возвращать требуемые данные с диска в память. Это очень медленный процесс. Именно из-за него программы, вышедшие за пределы оперативной памяти, начинают тратить много процессорного времени и зависать, даже если у них небольшая временна́я сложность. И, что ещё хуже, они могут вытеснять из памяти другие программы, которые в таком случае тоже зависают. Если запущенные на компьютере программы заняли не только всю оперативную память, но и файл подкачки, то какая-то из программ завершится аварийно.
Каждый объект в программе занимает некоторый объём памяти, а для хранения всех объектов может потребоваться немало пространства. Особенное внимание, конечно, следует уделять массивам, строкам и прочим контейнерам, ведь их размер не строго фиксирован и зависит от входных данных. Пространственной сложностью алгоритма называется зависимость объёма потребляемой памяти от входных данных. Как и в случае с временной сложностью, нас в первую очередь интересует не точный объём памяти, а асимптотика, то есть скорость роста без учёта констант и коэффициентов.
Взаимосвязь пространственной и временной сложности алгоритма
Типичная ситуация: мы сохранили вспомогательную информацию, чтобы тратить меньше времени, то есть «обменяли» память на скорость. При решении задач вам порой придётся делать непростой выбор: либо сохранять больше данных, чтобы уменьшить объём вычислений; либо считать медленнее, но сэкономить память. Следует помнить о том, что слишком большой расход памяти может привести к тому, что программа завершится с ошибкой. Или её производительность ухудшится из-за использования файла подкачки.
Как тестировать свою программу
Код, разделённый на функции, удобно тестировать. Для тестирования отдельных функций пишут юнит-тесты.
Краевые случаи:
| тип теста | строки | числа | набор данных/массивы |
|---|---|---|---|
| самый маленький тест | пустая строка | 0 или минимальное отрицательное число для задачи | пустой набор данных |
| самый большой тест | самая длинная строка по условию | самое большое положительное число для задачи | набор данных максимального размера |
| особые случаи | строки со строчными и заглавными буквами строки с кириллицей и латиницей | положительное/отрицательное число ноль четное/нечет число вещественное число | набор с одинаковыми элементами отсортированные наборы неотсортированные наборы |
Задача
Дана строка (UTF-8). Найти самый часто встречающийся в ней символ.
Решение 1
Переберем все позиции и для каждой позиции в строке еще раз переберем все позиции и в случае совпадения прибавим к счетчику единицу. Найдем максимальное значение счетчика.
s = 'ababa'
ans = ''
anscnt = 0
for i in range(len(s)):
nowcnt = 0
for j in range(len(s)):
if s[i] == s[j]:
nowcnt += 1
if nowcnt > anscnt:
ans = s[i]
anscnt = nowcnt
print(ans)
a
Решение 2
Переберем все символы, встречающиеся в строке, а затем переберем все позиции и в случае совпадения прибавим к счетчику единицу. Найдем максимальное значение счетчика.
s = 'ababa'
ans = ''
anscnt = 0
for now in set(s):
nowcnt = 0
for j in range(len(s)):
if now == s[j]:
nowcnt += 1
if nowcnt > anscnt:
ans = now
anscnt = nowcnt
print(ans)
a
Решение 3
Заведем словарь, где ключом является символ, а значением - сколько раз он встретился. Если символ встретился впервые - создаем элемент словаря с ключом, совпадающем с этим символом и значением ноль. Прибавляем к элементу словаря с ключом, совпадающем с этим символом, единицу.
s = 'ababa'
ans = ''
anscnt = 0
symcnt = {}
for now in s:
if now not in symcnt:
symcnt[now] = 0
symcnt[now] += 1
if symcnt[now] > anscnt:
ans = now
anscnt = symcnt[now]
print(ans)
a
Сравнение сложности
N - длина строки, К - кол-во различных символов
| Решение | Время | Память |
|---|---|---|
| 1 | О(N^2) | О(N) |
| 2 | О(NK) | O(N+K) = O(N) |
| 3 | O(N) | O(K) |
Зачем программисту алгоритмы
- Знание алгоритмов помогает эффективному решению задач
- Дополнительная готовность к собеседованию
- Общая когнитивная тренировка
Свойства алгоритмов
- Дискретность
- Детерминированность
- "Понятность"
- Завершаемость
- Массовость
- Результативность
Лайфхаки. Оценка сложности
- Видишь цикл - сложность линейная
- Видишь вложенный цикл - сложность полиномиальная, степень - глубина вложенности
- Видишь деление пополам - сложность логарифмическая
- Видишь полный перебор - сложность экспоненциальная
Есть ли неразрешенные алгоритмические проблемы
Проблема останова
- Допустим, что у нас есть алгоритма $A$ и входные данные $N$. Нужен такой алгоритм, который скажет, остановится ли $A$ на входных данных $N$.
- Доказательство: от противного с подачей этого алгоритма на вход самому себе
Ресурсы
- https://tproger.ru/digest/competitive-programming-practice/
- Введение в анализ сложности: https://habr.com/ru/post/196560/
- Гейл Макдауэлл «Карьера программиста»
Бонус. Задача. Поиск простых чисел
def is_prime(n):
if n == 1:
return False
i = 2
while i < n:
if n % i == 0:
return False
i = i + 1
return True
Можно решить эту задачу быстрее. Проверять числа, которые больше чем $\sqrt n$, необязательно.
def is_prime(n):
if n == 1:
return False
i = 2
while i * i <= n:
if n % i == 0:
return False
i = i + 1
return True
C помощью функции is_prime(n) можно найти все простые числа, не больше числа $n$.
Для этого заведём пустой массив smaller_primes. Будем проверять все числа, меньшие или равные $n$, на простоту. Если число простое, добавим его в массив smaller_primes. В конце работы алгоритма в этом массиве будет содержаться ответ.
def get_smaller_primes(n):
smaller_primes = []
for num in range(2, n + 1):
if is_prime(num):
smaller_primes.append(num)
return smaller_primes
Но этот метод не оптимальный — его не стоит применять на практике. Есть более оптимальный метод - решето Эратосфена.
Алгоритм такой:
- Выписываем все целые числа от 0 до $n$. Сразу помечаем, что числа 0 и 1 не являются простыми (записываем на соответствующих этим числам позициях
False). - Заводим переменную $\mathrm{num}$, равную первому не рассмотренному простому числу. Изначально она равна 2.
- Помечаем в списке числа от $2 \cdot \mathrm{num}$ до $n$ с шагом, равным $\mathrm{num}$, составными. Например, для 2 пометим значением
cчётные числа — 4, 6, 8 и так далее. - Теперь в $\mathrm{num}$ присваиваем следующее простое число, то есть следующее не рассмотренное число в списке. Для этого достаточно увеличивать $\mathrm{num}$ с шагом 1, пропуская числа, отмеченные как составные. На первом найденном простом числе следует остановиться.
- Повторяем два предыдущих шага, пока это возможно. Код функции, реализующий решето Эратосфена:
def eratosthenes(n):
numbers = list(range(n + 1))
numbers[0] = numbers[1] = False
for num in range(2, n):
if numbers[num]:
for j in range(2 * num, n + 1, num):
numbers[j] = False
return numbers
eratosthenes(9)
[False, False, 2, 3, False, 5, False, 7, False, False]
Простые числа остались на своём месте. Там, где были составные числа, стоит False. Алгоритм можно оптимизировать. Для каждого простого числа pp начнём отмечать числа, начиная с $p^2$, как составные. Ведь все составные числа, которые меньше его, будут уже рассмотрены. Получится такой код:
def eratosthenes_effective(n):
numbers = list(range(n + 1))
numbers[0] = numbers[1] = False
for num in range(2, n):
if numbers[num]:
for j in range(num * num, n + 1, num):
numbers[j] = False
return numbers
Рассмотрим подробно пример работы алгоритма для $n = 15$.
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # Запишем числа от 0 до 15
False False 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # Отметим, что 0 и 1 не простые
num = 2 # Пометим все числа, кратные 2, начиная с 4, значением False
False False 2 3 False 5 False 7 False 9 False 11 False 13 False 15
num = 3 # Пометим все числа, кратные 3, начиная с 9, значением False
False False 2 3 False 5 False 7 False False False 11 False 13 False False
num = 5 # Алгоритм можно завершить, так как num**2 больше 15.
# Все числа, кратные 5 и меньшие 15, уже рассмотрены.
Решето Эратосфена работает за $O(n \log(\log n))$. Чтобы это доказать, нужно знать некоторые сложные факты из теории чисел.
Существует метод решения задачи нахождения всех простых чисел, не превосходящих $n$, которому требуется $O(n)$ операций. Он называется линейное решето. Этот метод помечает каждое число как составное только один раз.
Как и прежде, мы будем перебирать числа в порядке увеличения. Только в отличие от классического решета Эратосфена, составные числа не вычёркиваются. Вместо этого для каждого числа $x$ мы запишем наименьший простой делитель $p$. В программе мы будем записывать этот делитель в ячейку массива $\mathrm{lp}[x]$ (от англ. least prime). Если число простое, его наименьший простой делитель — оно само. Если число составное, его наименьший простой делитель $p$ уже встречался раньше. Более того, нам встречалось и число $i$, такое, что $x = i \cdot p$. На шаге $i$ мы должны пометить число $x$ как составное и указать его наименьший простой делитель. Каждое число будет помечено только один раз, на шаге $i = x/p$. Число $i$ может быть взято только одним способом, потому что у любого числа существует только один наименьший простой делитель $p$.
Алгоритм такой:
- Для каждого числа
iбудем хранитьlp[i]— минимальный простой делитель числаi. Заведём массивlpдлиныn + 1. А также массивprimes, в который будем добавлять найденные простые числа. - Перебираем
iпо возрастанию. - Если
lp[i] = 0, можно сделать вывод, что число i простое, и добавить его в массив primes. - Рассматриваем все простые числа p, которые не больше
lp[i]. Обновляемlp[p * i] = p.
def get_least_primes_linear(n):
lp = [0] * (n + 1)
primes = []
for i in range(2, n + 1):
if lp[i] == 0:
lp[i] = i
primes.append(i)
for p in primes:
x = p * i
if (p > lp[i]) or (x > n):
break
lp[x] = p
return primes, lp
get_least_primes_linear(8)
([2, 3, 5, 7], [0, 0, 2, 3, 2, 5, 2, 7, 2])
Основные структуры данных
Оперативная память и представление данных
Эффективность программы можно оценить по тому, как она расходует разные типы ресурсов компьютера. Основные из них — процессорное время и оперативная память. А ещё есть пропускная способность сетевых подключений, время работы жёсткого диска и некоторые другие ограниченные ресурсы.
На первом уроке мы говорили о том, как алгоритм использует процессорное время. Теперь нас будет интересовать потребление оперативной памяти — это называется пространственной сложностью алгоритма.
Как устроена оперативная память
Оперативная память, или ОЗУ — это своего рода «черновик», который программа использует для вычислений. В него можно записывать и перезаписывать информацию, и оттуда же её можно считывать.
Современные компьютеры располагают всего несколькими гигабайтами оперативной памяти, и данные исчезают из неё сразу после завершения работы программы. Поэтому эта память не подходит для длительного хранения информации, зато она работает в сотни раз быстрее SSD и во многие тысячи раз быстрее обыкновенного жёсткого диска.
Оперативная память разбита на ячейки размером в 1 байт. У каждой ячейки есть свой порядковый номер, который называется «адрес» (отдельные биты внутри ячейки адресов не имеют). Процессор взаимодействует с оперативной памятью напрямую и использует адреса, чтобы обращаться к данным, — почти как программа обращается к переменным по имени.
Чтобы понять, сколько памяти потребляет программа, нужно выяснить, сколько места занимают отдельные объекты. В разных языках программирования этот объём памяти может отличаться, но основные принципы будут общими. Для начала мы разберём, как используется память в языке C++, так как он позволяет сделать это очень эффективно, гибко и предсказуемо.
Представление базовых типов данных в ОП
Что можно записать в одну ячейку памяти? Как мы уже говорили, размер наименьшей ячейки — 1 байт, состоящий из 8 бит. Каждый бит может принимать одно из двух значений: либо 0, либо 1. Восемь бит позволяют закодировать всего $2^8=2562$ вариантов значений. Получается, что в такую ячейку можно записать, например, целое число в промежутке от 0 до 255.
Если считать эти числа номерами символов, то в 1 байт можно уместить 1 символ текста (тип char): все буквы латиницы и кириллицы, цифры и основные символы вполне умещаются в 256 вариантов.
Самый распространённый тип целых чисел int занимает 4 байта и позволяет закодировать числа от –2 147 483 648 до 2 147 483 647.
Эти границы можно вычислить: в 4 байтах содержится 32 бита. Один бит тратится на то, чтобы закодировать знак. Оставшийся 31 бит позволяет закодировать $2^{31} =2;147;483;6482$ чисел. Число «ноль» тоже нужно закодировать, поэтому положительных чисел остаётся на одно меньше, чем отрицательных.
Если ваши числа не превышают по модулю два миллиарда, можно пользоваться этим типом чисел. Обратите внимание, что всего чисел около четырёх миллиардов, но половина из них отрицательные. Если точно известно, что переменная не может быть отрицательной, можно воспользоваться типом беззнаковых целых unsigned int, он позволяет хранить числа от 0 до 4 294 967 295.
Вещественные (то есть дробные) числа чаще всего кодируются типом double — это «числа с плавающей точкой», которые занимают 8 байт. Они могут кодировать как очень большие числа, такие как $\pm10^{308}$, так и близкие к нулю, например $\pm10^{-308}$.
Составные типы данных
Теперь посчитаем, сколько памяти потребуется для хранения массива из 10 строк по 20 символов каждая.
Во-первых, потребуется хранить сам текст. Это займёт $$10; строк \cdot (20; \frac{символов}{строка}) \cdot (1;\frac{байт}{символ}) = 200; байт$$ Этого было бы достаточно, если бы строки располагались в памяти друг за другом. Но производить с ними какие-либо операции будет сложно.
Поэтому в массивы (и в другие составные структуры) зачастую помещаются не сами объекты, а только указатели на них — адреса, по которым они хранятся в ячейках оперативной памяти.
Во многих других языках каждый объект в программе записан в специальную «обёртку», которая, помимо данных, содержит вспомогательную информацию. Из-за этого, например, в языке Python даже короткие целые числа могут занимать не 4 байта, а почти 30 байт. Для хранения строки требуется около 40 байт вспомогательной информации, для хранения массива — ещё больше. Обычно объекты в таких языках ведут себя подобно строкам из предыдущего примера: они могут находиться в произвольном месте памяти, и любое обращение к ним происходит по сохранённому адресу.
Посчитаем, например, сколько памяти расходует массив из 10 чисел в Python и на что она уходит:
import sys
print(sys.getsizeof(42)) # => 28 байт занимает короткое целое число
print(sys.getsizeof([])) # => 56 байт занимает пустой массив
print(sys.getsizeof([42])) # => 64 = (56 + 8) байт занимает массив с одним элементом.
print(sys.getsizeof([1,2,3,5,6,7,8,9,10])) # => 136 = (56 + 8*10) байт занимает массив
# с десятью элементами.
# сами данные хранятся отдельно
# и добавляют 280 = (28 * 10) байт
Получается, мы тратим 56 байт на то, чтобы создать массив, а дальше по 8 байт на каждый новый объект в массиве — это адреса элементов. Но это ещё не всё. Ведь каждому числу нужно ещё по 28 байт. Итого массив из десяти чисел в Python занимает суммарно 56 + (8 + 28) * 10 байт = 416 байт. Сравните это с 40 байтами в языке C++.
Как освобождается память
Важно понимать, что если вы перестали пользоваться объектом, это ещё не значит, что он освободил занимаемую память. В языке C++ приходится следить за тем, чтобы выделенная память освобождалась. Встроенные контейнеры, такие как std::vector, упрощают задачу: они автоматически выделяют необходимую память при создании контейнера и освобождают её при выходе переменной контейнера из области видимости.
В большинстве других языков за освобождение памяти отвечает сборщик мусора, который время от времени проверяет, может ли объект ещё быть использован. Если оказывается, что на него больше не ссылается никакая переменная и никакой другой объект, то этот объект уничтожается.
Но сборка мусора — трудоёмкая операция, поэтому некоторые языки откладывают её до тех пор, пока свободное пространство не подойдёт к концу. Например, программы на Java (если их специально не ограничить при запуске) часто сталкиваются с проблемой высокого потребления памяти из-за хранения множества старых и уже неиспользуемых объектов.
Массивы постоянного размера
В предыдущих уроках мы говорили о том, как простые и составные типы данных могут храниться в оперативной памяти компьютера. Начиная с этого урока мы будем говорить о различных структурах данных. Структура данных — это способ организации информации в памяти, который позволяет проводить с ней определённый набор операций. Например, быстро искать или изменять данные.
Массив — одна из базовых структур данных. В этом уроке мы посмотрим, какие возможности бывают у разных типов массивов и как они могут быть реализованы.
Самый простой тип массивов имеет фиксированный размер и может хранить элементы одного и того же типа. Например, если мы создадим массив из десяти целых чисел, в него нельзя будет добавить ещё один элемент или записать объект неподходящего типа. Такие массивы вы можете встретить, например, в языке C — int numbers[10], или в С++ — std::array<int, 10> numbers.
С массивами фиксированного размера можно выполнить только две операции:
- узнать значение элемента по индексу,
- перезаписать значение по индексу.
Да, они не слишком функциональные, но зато очень эффективные. Каждая из операций выполняется за $O(1)$. Чтобы понять, как массиву удаётся настолько быстро находить нужный элемент, — разберёмся в его механике работы и посмотрим, как он хранит данные.
Как устроен массив
Массив — это набор однотипных данных, расположенных в памяти друг за другом. Поэтому он всегда занимает один непрерывный участок памяти. Точное местоположение этого участка операционная система сообщает программе в момент создания массива.
В начале выделенного участка памяти находится нулевой элемент, сразу за ним — первый и далее по порядку. Они идут друг за другом, без пропусков. Зная положение элемента в памяти — его адрес, мы можем этот элемент прочитать или записать. Теперь посмотрим, как узнать адрес элемента.
Пусть у нас есть массив numbers из 10 беззнаковых целых чисел. Адрес нулевого элемента нам известен — это 1000. Чтобы узнать положение следующего элемента, нам нужно прибавить к адресу начала размер элемента в байтах. Каждое число занимает по 4 байта, так что первый (нулевой) элемент займёт байты 1000, 1001, 1002, 1003. Значит, элемент с индексом 1 будет записан по адресу 1004.
Сложность вставки и удаления в динамических массивах
В прошлом уроке мы говорили о том, что такое массив и как он устроен. Теперь настало время познакомить вас с динамическими массивами. Иногда их ещё называют «векторами», потому что в C++ они реализуются классом std::vector. В Python динамические массивы реализуются классом list, но пусть вас не обманывает название — это не список, а именно массив.
Сложность вставки в динамический массив
Бывают ситуации, когда невозможно сказать точно, какая длина массива может понадобиться. Поэтому так важно иметь возможность добавлять элементы в массив прямо во время выполнения программы.
Нужно вставить элемент в произвольное место массива? Конечно, вставка в начало и в конец — частные случаи этой задачи. Вставка элемента в начало — худший случай. Сложность этой операции $O(n)$. Добавление элемента в конец — лучший случай. И его сложность $O(1)$.
Сложность удаления из динамического массива
При удалении, как и при вставке в массив, требуется сдвинуть все элементы правее ячейки, в которой происходит операция. При добавлении в массив элементы сдвигаются на один вправо. А при удалении — на один влево.
Реаллокация в динамических массивах
Массив нельзя просто расширить — ведь за его пределами в памяти уже записаны другие данные. При расширении массива они перезапишутся, что может привести к ошибке выполнения программы.
Поэтому, как правило, при расширении массива программе приходится произвести «реаллокацию» — выделить новый участок памяти и скопировать туда старое содержимое.
Выделение памяти — долгая операция, но копирование — это ещё большая проблема, ведь оно требует прохода по всем элементам, затратив $O(n)$ операций. Как же мы тогда можем утверждать, что добавление в конец массива стоит $O(1)$?
Напишем программу, которая добавляет в массив тысячу элементов — по одному за раз:
values = []
for i in range(1000):
values.append(i)
Операция append() может быть представлена как две операции: реаллокация и присваивание значения элементу массива. Для простоты мы не будем учитывать операции присваивания. Их число равно количеству добавляемых элементов; эта часть оптимизации не требует (и не может быть оптимизирована). А вот время, затрачиваемое на реаллокации, может существенно отличаться — в зависимости от выбранного подхода.
Если бы рассматриваемой программе приходилось при каждом добавлении элемента производить реаллокацию, итоговая сложность алгоритма была бы квадратичной. Теперь попробуем сократить число реаллокаций.
Во-первых, чтобы не приходилось на каждом шаге выделять дополнительную память, нужно держать запас свободного места в массиве. Например, если мы решим увеличить размер доступного массиву места сразу на 100 элементов, программа будет выделять память в 100 раз реже. Но программа всё ещё будет работать за $O(n^2)$, хотя и с небольшой константой при квадратичном члене.
Теперь у нас есть два разных размера массива: size (количество элементов) и capacity (ёмкость), причём size ≤ capacity.
Во-вторых, чтобы сделать сложность алгоритма линейной, нужно увеличивать размер не на фиксированное количество элементов (арифметическая прогрессия), а в фиксированное число раз (геометрическая прогрессия).
Пусть изначальная ёмкость массива равна 1, а при каждой реаллокации она удваивается. Тогда на первой реаллокации копируется 1 элемент, на второй — 2, на третьей — 4, затем — 8, 16, 32, 64, 128, 256, 512. После этих действий ёмкость массива равна 1024.
Посчитаем, сколько операций копирования нам нужно будет произвести к моменту добавления 1000-го элемента. Общее число копирований: $S = 1 + 2 + 4 + \cdots + 512 = 1024 - 1$.
В общем случае, если нужно добавить $n$ элементов (где $2^k \lt n \le 2^{k+1}$, последнее копирование затронет $2^k$ элементов. Напишем сумму такой геометрической прогрессии: $S = \sum_{i=0}^k 2^i = 2^{k+1} - 1 = 2 \cdot 2^k - 1 \le 2\cdot n$.
Итак, у нас получилось добиться того, что общее количество копирований при реаллокации будет линейно зависеть от числа элементов.
Связные списки
Как вы помните, элементы массива в памяти компьютера расположены последовательно. Чтобы вставить или удалить элемент из начала массива, нужно $O(n)$ операций. Потому что придётся передвинуть каждый последующий элемент.
Хорошо бы иметь структуру данных, в которой при вставке или удалении элемента передвигать остальные было бы не нужно.
Такая структура существует. Она называется «связный список» (англ. linked list). Во многих языках программирования реализована в стандартных типах, например, std::list в C++, LinkedList в Java.
Важно помнить, что в языке Python list — это динамический массив, хотя и обозначен словом «список».
Как устроен связный список
В связном списке у каждого элемента, помимо его значения, есть ссылка на следующий элемент списка. За исключением последнего — он ссылается в никуда. В зависимости от языка программирования ссылка в никуда может представлять собой объект None, нулевой указатель или аналогичную сущность. Кроме того, у связного списка принято определять точку старта — её называют «головой списка».
Достоинства и недостатки связного списка
Их элементы расположены в памяти компьютера в произвольных местах, а не по порядку, как в массиве. Это бывает очень удобно, если элементов много и расположить их единым блоком не представляется возможным.
Недостаток в том, что нельзя получить доступ к элементу за $O(1)$ по индексу, так как элементы хранятся в памяти непоследовательно. Для этого нужно пройти по всем элементам, начиная с головы списка, пока не дойдём до нужного. Это займёт $O(n)$ операций.
Двигаться по односвязному списку можно только в одном направлении. Из этого недостатка следует ещё один: мы не можем быстро удалить элемент, так как не знаем, какой элемент на него ссылается. В худшем случае потребуется $O(n)$ операций для поиска предыдущего. А вот вставить элемент после текущего мы можем быстро.
Структура данных стек
Структура данных стек часто встречается в программировании и во многих вещах, связанных с компьютерами. Стек работает по принципу LIFO.
Вы наверняка пользуетесь возможностью браузеров, реализованной с применением стека. Речь идёт о кнопке «назад». Нажмёте на неё один раз — вернётесь на предыдущую страницу, нажмёте снова — попадёте на страницу, где были до неё.
Во многих текстовых редакторах можно отменять последние операции. Эта функция тоже реализована при помощи стека.
Чтобы лучше понять, как устроен стек, представьте себе стопку книг в коробке. Если вам захочется почитать, вы сможете взять только верхнюю книгу. А если она окажется неинтересной, что ж, можно будет отбросить её и попытать удачу, взяв ещё одну книгу сверху, и так далее. Из стека также можно взять только верхний — последний, положенный в стек, — элемент.
Интерфейс стека
В отличие от массивов и связных списков, стек — это прежде всего удобный интерфейс для взаимодействия с данными, а не физическая особенность их хранения. Когда мы говорим про стек, мы подразумеваем структуру данных, которая реализует следующие методы:
push(item)— добавляет элемент на вершину стека;pop()— возвращает элемент с вершины стека и удаляет его;size()— возвращает размер стека (количество лежащих в нём элементов).
Иногда стек реализует дополнительные операции:
peek()илиtop()— возвращает элемент с вершины стека, не удаляя его;isEmpty()— определяет, пуст ли стек.
В большинстве случаев стек удобно реализовывать на массиве. Но бывают ситуации, когда стек должен хранить очень много элементов, а выделить единый блок памяти для этого невозможно. Тогда для реализации лучше воспользоваться связным списком.
Реализация стека
Посмотрите, как реализуется стек на основе массива. В конструкторе для экземпляра класса создаётся пустой массив. Далее при вызове методов push() и pop() этот массив будет меняться:
class Stack:
def __init__(self):
self.items = []
def push(self, item):
self.items.append(item)
def pop(self):
return self.items.pop()
def peek(self):
return self.items[-1]
def size(self):
return len(self.items)
stack = Stack()
stack.push('apple')
stack.push('banana')
stack.push('orange')
stack.pop()
Структуры данных: очередь и дек
В прошлом уроке вы познакомились со стеком и узнали, как он устроен. Ещё одна важная структура данных — «очередь». В отличие от стека, который работает по принципу LIFO, очередь основана на концепции FIFO. То есть первым извлекают элемент, который добавили раньше всех.
В повседневной жизни мы все сталкиваемся с очередями:
- Кассир в магазине обслуживает покупателей по одному: пока кто-то оплачивает свои продукты, остальным приходится стоять в очереди и ждать. И, конечно, вас обслужат не раньше, чем всех тех людей, которые встали в очередь до вашего прихода.
- Если мы звоним на горячую линию и все операторы заняты, нам тоже приходится ждать в очереди.
Подобные сценарии часто встречаются и в мире компьютеров. При их моделировании удобно применять структуру данных очередь.
Интерфейс очереди
Как и стек, очередь — интерфейс общения с данными. Он гарантирует наличие определённых методов, но не даёт никаких обещаний по способу хранения этих данных. То есть «под капотом» может находиться всё что угодно. При том, что интерфейс не накладывает ограничений на внутреннее устройство, очередь принято реализовывать таким образом, чтобы операции вставки и удаления элемента выполнялись за $O(1)$.
Когда мы говорим про очередь, мы ожидаем, что у структуры будут следующие методы:
push(item)— добавляет элемент в конец очереди;pop()— берёт элемент из начала очереди и удаляет его;peek()— берёт элемент из начала очереди без удаления;size()— возвращает количество элементов в очереди.
Стек вызовов
Код любой сложной программы разделён на множество функций. Поэтому работа всей системы описывается как взаимодействие небольших блоков кода. Базовые функции объединяются в сложные, а те — в ещё более сложные. В результате вся программа может быть представлена как одна сложносоставная функция, которая вызывает множество простых.
Как устроен стек вызовов
Допустим, мы написали программу на С++. Первой вызывается функция main(). В ней вызывается функция A. Она вызывает функцию B, которая, в свою очередь, вызывает C.
Так выглядит стек вызовов этой программы:

После возврата из функции управление должно вернуться туда, откуда эту функцию вызвали. Для этого при вызове функции в стеке вызовов сохраняется адрес той инструкции программы, которая будет выполнена после возврата из функции.
Для примера рассмотрим функцию, которая приветствует пользователя по имени и выдаёт ему гороскоп на сегодняшний день. Для простоты предположим, что пользователь пришёл на сайт, где всем выдают один и тот же гороскоп.
def say_hello(name):
print(f"Привет, {name}")
print_horoscope(name.upper())
print(f"Пока, {name}, хорошего дня!")
def print_horoscope(name):
print(f"{name}! Сегодня подходящий день для прогулок в парке и изучения рекурсии")
say_hello('Гоша')
Обратите внимание, что в разных частях программы переменная name может хранить разные значения. Например, при входе в функцию say_hello() в переменной name будет записано 'Гоша'. А если мы вызовем print_horoscope(), там появится 'ГОША'. Но, когда мы перейдём обратно в say_hello(), значение вновь вернётся к первоначальному 'Гоша'.
Чтобы добиться такого поведения, программа хранит все локальные переменные на том же стеке. Можно представить это так: на вершине стека находится структура, в которой записаны локальные переменные и аргументы функции, а также адрес возврата. Проследим, как меняется содержимое стека в нашем примере.
Работа стека: шаг за шагом
Первая команда, которая будет выполнена при старте программы, — вызов функции say_hello(). Под этот вызов на стеке выделяется блок памяти.

В выделенный блок памяти записывается адрес возврата. Он нужен для того, чтобы определить, куда передать управление после завершения работы функции. Как мы уже говорили, этот адрес соответствует инструкции, следующей сразу за местом вызова функции.
Также в стек помещаются переданные в функцию аргументы. С этих параметров начинается формирование набора локальных переменных функции. В нашем случае есть один аргумент name = 'Гоша', а другие локальные переменные отсутствуют.

Затем выполняется первая инструкция в функции say_hello(), которая выводит сообщение: «Привет, Гоша».
Далее происходит вызов метода upper(), который вернёт вызвавшей его функции строку 'ГОША', написанную большими буквами. Эта строка станет параметром функции print_horoscope().
Вызовы функции print() и метода upper() мы для краткости на картинке не показываем, хотя они, конечно же, тоже кладутся на стек при вызове и снимаются с него после завершения выполнения.
Когда вызывается функция print_horoscope() с параметром 'ГОША', под этот вызов выделяется новый блок памяти, куда записываются значения переданных функции параметров и новый адрес возврата, а также выделяется место для других локальных переменных. Блок памяти для функции print_horoscope() помещается поверх блока, отведённого под say_hello(). Помните стопку книг в коробке, о которой мы говорили пару уроков назад? Вот она, перед вами! Только вместо книг — блоки памяти.

Затем исполнится первая инструкция в функции print_horoscope(). Выведется сообщение: «ГОША! Сегодня подходящий день для прогулок в парке и изучения рекурсии!».
В print_horoscope() больше нет инструкций. Настал момент возвращения управления. В блоке памяти функции print_horoscope(), лежащем на стеке, записан адрес возврата, поэтому программе известно, какая инструкция должна исполниться следующей. Блок, отведённый под print_horoscope(), больше не нужен, и теперь извлекается из стека. Значение переменной name восстанавливается.

Затем исполняется инструкция из say_hello(), следующая за вызовом функции print_horoscope(). Эта инструкция — вывод сообщения: «Пока, Гоша, хорошего дня!»
Так как это последняя из инструкций в say_hello(), происходит возврат из функции. Блок памяти, выделенный под неё, освобождается.

Теперь вы знаете, как интерпретатор (или компилятор) языка программирования вызывает функции.
Рекурсия. Переполнение стека вызовов
В этом уроке мы поговорим о функциях, которые вызывают сами себя, но с изменёнными значениями аргументов. Такие функции называются «рекурсивными». И они тоже используют стек вызовов.
Факториал
Посмотрим на примере, в каких случаях могут понадобиться такие функции.
Факториал натурального числа можно вычислить как произведение всех натуральных чисел от 1 до n: $n! = 1 \cdot 2 \cdot ... \cdot (n-1) \cdot n$
Рекурсия и стек вызовов
Теперь напишем код рекурсивной функции вычисления факториала:
def factorial(n):
if n == 1 or n == 0:
return 1
return n * factorial(n - 1)
Проанализируем, что происходит при вызове функции factorial(3).

При каждом вызове функции на стеке создаётся новый набор локальных переменных. Таким образом, переменная n в каждом вызове оказывается новая. Благодаря этому переменные с одним и тем же именем даже в одной и той же функции не конфликтуют между собой. Невозможно обратиться к переменной n, которая относится к другому уровню рекурсии. Ни узнать, ни поменять её значение не получится.
Однако, чтобы хранить локальные переменные и адрес возврата на каждом уровне рекурсии, потребуется $O(d)$ памяти на стеке, где d — глубина рекурсии. При вычислении факториала $n!$ глубина рекурсии равна n, поэтому этот метод расходует $O(n)$ памяти на стеке.
А что будет, если эта память закончится, а рекурсивные вызовы продолжатся?
Стек вызовов переполнится и программа аварийно завершит работу.
Объём памяти, выделяемой под стек, ограничен очень небольшим объёмом — гораздо меньшим, чем общий объём оперативной памяти. Рекурсию нельзя делать больше, чем на несколько десятков тысяч вызовов в глубину, потому что при использовании слишком глубокой рекурсии стек переполнится (англ. stack overflow) и программа завершит работу аварийно с ошибкой. Программы на одних языках при этом выдадут исключение “Stack Overflow”, другие же завершатся с ошибкой “Segmentation Fault”.
factorial(10_000)
Что делать, чтобы стек не переполнялся
Есть несколько способов избежать переполнения стека:
- В некоторых случаях можно вовсе избавиться от рекурсии, заменив её на обыкновенный цикл. Например, вычисление факториала легко переписать следующим образом:
def factorial(n):
accumulator = 1
i = n
while i > 1:
accumulator *= i
i -= 1
return accumulator
- Другой способ заключается в том, чтобы написать свой собственный стек, эмулирующий стек вызовов, но лишённый ограничений встроенного.
Объёмом памяти, который выделяется под стек вызовов, можно управлять.
В некоторых языках это можно делать прямо в процессе работы программы. Например, в Python можно применить метод setrecursionlimit() модуля sys. Передаваемый в функцию параметр limit — задаёт максимальную глубину рекурсии. Наибольшее возможное значение зависит от платформы и всё равно существенно ограничено. Можно узнать текущее значение этой величины, вызвав метод getrecursionlimit().
В других языках программирования, таких как Java и JavaScript, размер стека вызовов можно задать настройками виртуальной машины при запуске программы, но в процессе работы программы он остаётся неизменным.
Кроме того, размер стека вызовов иногда может быть изменён на уровне операционной системы.
sys.getrecursionlimit()
Практика
Наивное решение. GET
@app.route('/', methods=['GET'])
def paginated_get():
page = int(request.args.get('page', '0'))
first = page * PAGE_SIZE
last = first + PAGE_SIZE
result = []
with open(FILE_PATH, 'r') as f:
for i, line in enumerate(f.readlines()[first:last]):
result.append( {'id': first + i, 'data': line.strip()})
return {"result": result}
Наивное решение. POST
@app.route('/', methods=['POST'])
def post():
data = request.json['data']
with open(FILE_PATH, 'a') as f:
f.write('\n' + data)
return {}, 201
Наивное решение. PUT
@app.route('/<int:data_id>', methods=['PUT'])
def put(data_id):
data = request.json['data']
with open(FILE_PATH, 'r') as f:
new_data = f.readlines()
new_data[data_id] = data + '\n'
with open(FILE_PATH, 'w') as f:
f.writelines(new_data)
return {}, 204
Наивное решение. DELETE
@app.route('/<int:data_id>', methods=['DELETE'])
def delete(data_id):
with open(FILE_PATH, 'r') as f:
new_data = f.readlines()
del new_data[data_id]
with open(FILE_PATH, 'w') as f:
f.writelines(new_data)
return {}, 204
Фиксированный. GET
@app.route('/', methods=['GET'])
def paginated_get():
page = int(request.args.get('page', '0'))
first = page * PAGE_SIZE
result = []
with open(FILE_PATH, 'rb') as f:
f.seek(first * ELEMENT_SIZE)
data = f.read(PAGE_SIZE * ELEMENT_SIZE)
for i, n in enumerate(range(PAGE_SIZE)):
result.append(
{
"id": first + i,
"data": (
data[n * ELEMENT_SIZE: (n + 1) * ELEMENT_SIZE].
strip(FILL_CHAR).decode('utf-8')
)
}
)
return {"result": result}
Фиксированный. POST
def post():
data = str(request.json['data'])
with open(FILE_PATH, 'a+b') as f:
f.write(data.encode('utf-8').ljust(ELEMENT_SIZE, FILL_CHAR))
return {}, 201
Фиксированный. PUT
@app.route('/<int:data_id>', methods=['PUT'])
def put(data_id):
data = request.json['data']
with open(FILE_PATH, 'r+b') as f:
f.seek(data_id * ELEMENT_SIZE)
f.write(data.encode('utf-8').ljust(ELEMENT_SIZE, FILL_CHAR))
return {}, 204
Фиксированный. DELETE
@app.route('/<int:data_id>', methods=['DELETE'])
def delete(data_id):
with open(FILE_PATH, 'r+b') as f:
point = data_id * ELEMENT_SIZE
f.seek(point)
while True:
f.seek(point + ELEMENT_SIZE)
complex_data = f.read(ELEMENT_SIZE)
f.seek(point)
if len(complex_data):
f.write(complex_data)
point += ELEMENT_SIZE
else:
f.truncate()
break
return {}, 204
Database. GET
@app.route('/', methods=['GET'])
def paginated_get():
page = int(request.args.get('page', '0'))
with closing(psycopg2.connect(dbname=dbname, host=host)) as conn:
with conn.cursor() as cursor:
cursor.execute(
'SELECT "id", "todo" FROM "todos" ORDER BY "id" OFFSET %s LIMIT %s;',
(page * PAGE_SIZE, (page + 1) * PAGE_SIZE)
)
return {
"result": [ {"id": row[0], "data": row[1]} for row in cursor]
}
Database. POST
@app.route('/', methods=['POST'])
def post():
data = str(request.json['data'])
with closing(psycopg2.connect(dbname=dbname, host=host)) as conn:
with conn.cursor() as cursor:
cursor.execute(
'INSERT INTO "todos" ("todo") VALUES (%s) RETURNING "id";',
(data,)
)
conn.commit()
return {"id": cursor.fetchone()[0]}, 201
Database. PUT
@app.route('/<int:data_id>', methods=['PUT'])
def put(data_id):
data = request.json['data']
with closing(psycopg2.connect(dbname=dbname, host=host)) as conn:
with conn.cursor() as cursor:
cursor.execute(
'UPDATE "todos" SET "todo" = %s WHERE "id" = %s;',
(data, data_id)
)
conn.commit()
return {}, 204
Database. DELETE
@app.route('/<int:data_id>', methods=['DELETE'])
def delete(data_id):
with closing(psycopg2.connect(dbname=dbname, host=host)) as conn:
with conn.cursor() as cursor:
cursor.execute(
'DELETE FROM "todos" WHERE "id" = %s;',
(data_id,)
)
conn.commit()
return {}, 204
Cache. GET
@app.route('/', methods=['GET'])
def paginated_get():
page = int(request.args.get('page', '0’))
redis_client = redis.StrictRedis(**redis_creds)
cached_page = redis_client.get(page)
if cached_page:
return cached_page
with closing(psycopg2.connect(**postgres_creds)) as conn:
with conn.cursor() as cursor:
cursor.execute(
'SELECT "id", "todo" FROM "todos" ORDER BY "id" OFFSET %s LIMIT %s;',
(page * PAGE_SIZE, (page + 1) * PAGE_SIZE)
)
result = json.dumps({
"result": [{"id": row[0], "data": row[1]} for row in cursor]
})
redis_client.set(page, result, ex=ttl)
return result
Рекурсия и сортировки
Введение. Примеры задач на рекурсию
Представь, что хочешь найти файл Kormen.pdf у себя в папке C:\books\. Как это сделать без использования автоматического поиска? Рассмотрим два варианта.
Вот схема первого варианта решения этой задачи:

Вот схема рекурсивного решения:

На каждом уровне погружения рекурсия добавляет блок в стек вызовов. Найдя нужный файл, функция останавливает рекурсию и начинает по цепочке — от одного уровня к другому — возвращать результат вызвавшей её программе.
Кстати, если говорить о скорости, то рекурсия не ускоряет работу программы, а наоборот, может её замедлить. Более того, алгоритмы, реализованные с применением циклов, часто исполняются быстрее. Зато рекурсия экономит время программиста, потому что код получается компактный и понятный, в нём труднее сделать ошибку. А ещё в такой код проще вносить изменения.
Рекурсивный и базовый случаи
Теперь мы расскажем о том, как правильно создавать рекурсию и что делать, если написанный вами рекурсивный алгоритм уходит в бесконечный цикл.
Любая корректно работающая рекурсия состоит из двух обязательных частей:
- рекурсивного случая, благодаря которому начинается прямой ход рекурсии и происходит её углубление;
- и базового случая, который в нужный момент останавливает это углубление и запускает обратный ход рекурсии.
Давайте поговорим о них подробнее.
Рекурсивный случай
функция stairs_builder(n):
построить 1 ступеньку
print("Осталось построить {n} ступеней.")
stairs_builder(n - 1)
Когда функция вызывает саму себя с изменёнными параметрами: stairs_builder(n - 1) — это и есть рекурсивный случай. И всё же, если мы запустим эту программу, компьютер зависнет.
Потому что наша рекурсия уйдёт в бесконечный цикл. На каждом следующем уровне рекурсии число ʜeпостроенных ступеней n уменьшается на 1. Но после n = 0 функция не остановит работу, а вызовется со значением −1, потом с −2 и так далее. Если бы у компьютера были неограниченные ресурсы, твоя лестница строилась бы вечно и имела бесконечное количество ступеней.
Базовый случай
При написании любой рекурсивной функции нужно указывать базовый случай — условие, при котором цепочка рекурсивных вызовов останавливается. При этом важно уметь определять, что именно должно происходить в базовом случае.
Чтобы функция stairs_builder() работала корректно, рекурсия должна остановиться в тот момент, когда будет построено нужное количество ступеней. То есть когда счётчик n = 0. Это и будет базовый случай!
функция stairs_builder(n):
if n == 0:
return
построить 1 ступеньку
print("Осталось построить {n} ступеней.")
stairs_builder(n - 1)
Как правильно создать рекурсию?
Чтобы решить задачу рекурсивным методом, нужно определить базовый и рекурсивный случаи.
Рекурсивный случай сводит задачу для большого набора данных к задаче с меньшим набором данных. Или для большого значения аргумента к задаче с меньшим значением аргумента.
А базовый случай определяет ситуацию, при которой рекурсию нужно остановить. Результат выполнения функции для базового случая следует вычислить явно, не прибегая к рекурсивным вызовам.
Ошибка, которую часто допускают, применяя рекурсию, — зацикливание. Обычно это происходит, если забыть указать базовый случай. Другая частая причина ухода в бесконечный цикл — это неверное изменение параметров в рекурсивном случае.
Например, если функция в какой-то ситуации вызывает саму себя, но значение параметра при этом не меняется. Тогда даже если базовый случай, который должен был бы прервать рекурсию, определён, функция может до него не дойти. При написании рекурсии мы должны убедиться, что для любого набора параметров функция рано или поздно сведётся к одному из базовых случаев.
В большинстве случаев программа, упавшая в кроличью нору бесконечной рекурсии, не будет работать вечно, а завершится с ошибкой переполнения стека вызовов или с ошибкой сегментации (англ. segmentation fault). Это происходит из-за ограниченности ресурсов компьютера, ведь каждый рекурсивный вызов расходует память на стеке.Как именно программа себя поведёт — зависит и от самого алгоритма, и от используемого компилятора. Подробнее об этом можно почитать в статье про оптимизацию хвостовой рекурсии (англ. tail call optimization).
Разбор задач. Рекурсивный перебор вариантов
Рекурсию часто применяют для генерации объектов. Например, числовых или скобочных последовательностей.
Генерация последовательностей из 0 и 1
Рассмотрим пример генерации всех возможных последовательностей длины n из нулей и единиц.
Функция принимает в качестве параметра число n и строку prefix. Вызываем функцию с параметром n и значением prefix, равным пустой строке. Далее будем добавлять в эту строку 0 и 1. В каждом рекурсивном вызове n означает, сколько ещё символов нужно добавить в строку. Рекурсия останавливается, когда n = 0, то есть символы добавлять больше не требуется. Это базовый случай рекурсии.
В рекурсивном случае функция вызывает себя дважды, но с разными параметрами. В первый раз она добавляет в строку prefix цифру 0, а во второй раз — 1. При этом значение n каждый раз уменьшается на 1, а prefix удлиняется на один символ. Таким образом, рекурсия уходит на n уровней в глубину.
Решение этой задачи удобно представлять в виде бинарного дерева. Начинаем с пустой строки. Если идём влево, добавляем 0, если вправо — 1. Если пройти от корня по всем веткам, получим все возможные последовательности из 0 и 1 длины 3.

Рекурсия часто используется для перебора вариантов. Например, у нас есть n различных предметов. Каждый из предметов может быть взят или отложен в сторону. Тогда есть $2^n$ вариантов того, как взять набор предметов. Пронумеруем предметы числами от 1 до $n$. Каждый предмет может быть взят (обозначим цифрой 1) или отложен в сторону (обозначим как 0). Так мы фактически свели задачу перебора вариантов к задаче генерации последовательностей из нулей и единиц.
def generate(n, prefix):
if n == 0:
print(prefix)
return
generate(n - 1, prefix + '0')
generate(n - 1, prefix + '1')
generate(3, '')
000
001
010
011
100
101
110
111
Алгоритмы сортировки. Знакомство
В прошлых уроках мы говорили о том, как с помощью рекурсии реализовывать двоичный поиск по отсортированному массиву, быстро возводить число в степень и перебирать всевозможные комбинации элементов. Теперь настало время познакомить вас с алгоритмами сортировок, с помощью которых можно наводить порядок в самых разных типах данных.
Сортировки среди нас
Упорядоченность данных очень важна в повседневной жизни.
Например, в вашем смартфоне контакты отсортированы по алфавиту. А расписание автобусов составляется по времени их отправления. Поисковая система выдаёт ранжированный список ответов — по степени их релевантности запросу.
Роль сортировок в решении задач
Во многих задачах работать с отсортированными данными удобнее, чем с неупорядоченными. Например:
- найти элемент в массиве быстрее чем за $O(n)$, воспользовавшись бинарным поиском, получится только на отсортированных данных;
- составить таблицу «10 лучших студентов курса» будет удобнее, если список студентов отсортирован не в алфавитном порядке, а по среднему баллу.
Нередко именно сортировка становится бутылочным горлышком и замедляет решение задачи. Поэтому важно знать, каким образом в каждом отдельном случае можно отсортировать массив наиболее эффективно.
Лучшей сортировки в общем случае не существует. Для разных типов входных данных и разных ограничений будет эффективнее использовать разные алгоритмы сортировки.
Выбор алгоритма сортировки
Рассмотрим два алгоритма сортировки:
- один работает быстро, но требует O(n)O(n) дополнительной памяти;
- другой алгоритм медленнее, но ему нужно лишь O(1)O(1) дополнительной памяти.
Например, сейчас в компании, старые сервера, на них совсем не осталось свободной памяти. На одном из них лежат все данные об удовлетворенности жизнью в разных городах страны. Для ежемесячного отчёта необходимо отсортировать данные и предоставить названия 100 городов с самыми довольными жителями. Отчёт надо сдать через неделю.
Лучше выбрать более медленный алгоритм, но эффективный по памяти.
Например, теперь команде поручили сделать стенд, на котором отображаются данные об удовлетворённости жителей страны в реальном времени. Под эту задачу был куплен новый мощный сервер. Каждую секунду на вход программы поступает обновлённый массив с текущими значениями индекса удовлетворённости по всем городам. Алгоритм должен составить «Топ-5 самых довольных городов» и обновлять этот список в режиме реального времени.
Лучше выбрать более быстрый алгоритм, но требующий больше памяти.
Таким образом, при решении задачи важно верно оценить имеющиеся ресурсы. В этом вам могут помочь следующие вопросы:
- Как быстро необходим ответ? Если результат сортировки нужен не срочно, то можно реализовать менее быстрый алгоритм, зато не использовать дополнительную память.
- С каким объёмом данных будет работать алгоритм? Если у вас в массиве всего 1000 элементов, то любой алгоритм сортировки упорядочит их так быстро, что вы и не заметите. Если же у вас в наличии 5 000 000 элементов, разница может быть уже существенной.
- Сколько памяти доступно? Если вам хватит свободного места на то, чтобы записать массив второй раз, можно упростить себе задачу и собирать отсортированный массив в дополнительной памяти, а не переставлять элементы в исходном массиве.
Устойчивость сортировок
Если после применения сортировки первоначальный порядок элементов с равным значением сравниваемого признака сохраняется, такая сортировка называется устойчивой (англ. stable sort). В противном случае, если элементы с равным значением поменялись местами, — неустойчивой.
Сортировка по ключу
Признак, по которому элементы сравниваются, называют «ключом сортировки». Мы уже сортировали элементы по ключу, когда нам требовалось упорядочить города по их индексу удовлетворённости.
Итак, с точки зрения алгоритма сортировки меняется только один этап — операция сравнения элементов.
Обычно функция сортировки принимает в качестве вспомогательного аргумента функцию, описывающую, в каком порядке идут элементы. Есть два распространённых способа это сделать:
- В одном варианте алгоритму сортировки передаётся в качестве параметра функция одного аргумента
key(object). Эта функция будет применена к каждому сравниваемому объекту, чтобы получить значение ключа для этого элемента. Все объекты попарно будут сравниваться между собой по этому ключу. - В другом варианте в алгоритм сортировки передаётся функция с двумя аргументами less(object_1, object_2), которая сравнивает два объекта и возвращает true, если первый объект должен быть расположен раньше второго, и false в противном случае. Такую функцию называют «компаратор» (англ. compare, «сравнивать»).
Сравнение элементов при помощи компаратора позволяет более гибко задавать порядок элементов, чем сравнение по ключу. Например, сортировку по любому ключу легко переписать в виде сортировки с таким компаратором:
функция less(object_1, object_2):
return key(object_1) < key(object_2)
А вот, например, сконструировать индекс по компаратору не всегда возможно. И, как мы ещё увидим, не все компараторы работают корректно. Поэтому обычно намного проще использовать функцию вычисления ключа сортировки.
Обязательно изучите документацию функции сортировки вашего любимого языка, чтобы научиться передавать в алгоритм сортировки компаратор либо функцию вычисления ключа.
Сортировка слиянием
Cортировка, которая работает всего за $O(n \log n)$. Она называется сортировка слиянием (англ. merge sort).
Принцип работы сортировки слиянием
Cоставные части алгоритма сортировки слиянием:
- Массив разбивается на две части примерно одинакового размера.
- Если в каком-то из получившихся подмассивов больше одного элемента, то для него рекурсивно запускается сортировка по этому же алгоритму, начиная с пункта 1.
- Два упорядоченных массива соединяются в один.
Условие остановки рекурсии — массив из одного элемента. Он не нуждается в сортировке, поэтому это базовый случай.

Дерево алгоритма сортировки слиянием: массив разбивается на части примерно равной длины. Каждая часть рекурсивно сортируется. После этого отсортированные части объединяются в единый массив
Сложность алгоритма
Сортировка слиянием даже в худшем случае работает за $O(n \log n)$. Давайте разберёмся почему.
На каждом шаге прямого хода рекурсии массив разбивается на две примерно равные по размеру части. Разбиение продолжается до тех пор, пока длина массива не станет равной 1. Таким образом, каждый элемент массива будет задействован примерно в $\log_2 n$ вызовах рекурсивной функции.
Иначе можно сказать, что глубина рекурсии составляет $O(\log_2n)$. Глубиной рекурсии называют максимальную глубину стека вызовов, которая достигается во время рекурсии.
На каждом шаге обратного хода рекурсии выполняется операция слияния двух отсортированных массивов. Как мы уже выяснили, для этого потребуется $O(n)$ операций, ведь на каждом уровне рекурсии нужно обработать $n$ чисел.
Таким образом, общая сложность этого алгоритма $O(n \cdot \log_2 n)$.
Пространственная сложность алгоритма
На каждом уровне рекурсии для проведения операций слияния требуется выделить $O(n)$ дополнительной памяти — в неё будут копироваться элементы объединяемых блоков в правильном порядке. Если выделять такое количество памяти на каждом уровне рекурсии, суммарно придётся затратить $O(n\log{n})$ дополнительной памяти.
Но вспомогательный массив требуется лишь временно. После объединения блоков мы можем перенести элементы из вспомогательного массива обратно в исходный, освободив выделенную память. Таким образом, в каждый момент времени будет использоваться вспомогательное пространство лишь для одного, текущего уровня рекурсии. Значит, нам будет достаточно использовать лишь $O(n)$ дополнительной памяти.
Устойчивость алгоритма
Сортировка слиянием является устойчивой сортировкой. В случае равенства элементов в двух отсортированных массивах, приоритет отдаётся элементу, который находился в левой половине массива. Так происходит на каждом уровне сортировки вплоть до объединения двух массивов длины в один. Таким образом, равные элементы в отсортированном массиве будут расположены друг относительно друга так же, как и в исходном.
Быстрая сортировка
В этом уроке мы рассмотрим ещё один популярный алгоритм сортировки, который называется быстрой сортировкой (англ. quick sort) и использует стратегию «разделяй и властвуй».
Встроенные функции сортировки во многих языках программирования используют модификации именно алгоритма быстрой сортировки, поскольку на практике она нередко работает даже быстрее сортировки слиянием. Автор этого алгоритма — Чарльз Хоар. Поэтому в честь него quick sort иногда называют сортировкой Хоара.
Принцип работы алгоритма
Алгоритм быстрой сортировки использует стратегию «разделяй и властвуй». Любой такой алгоритм состоит из трёх шагов:
- разделение данных на части меньшего размера;
- рекурсивный вызов алгоритма для этих частей;
- объединение результатов.
В алгоритме merge sort у нас был очень простой шаг разделения и нетривиальный шаг объединения данных. В алгоритме быстрой сортировки всё будет наоборот: мы сначала хитрым способом разделим данные на части, зато объединение произойдёт очень просто, нам достаточно будет дописать один отсортированный массив после другого.
- Возьмём исходный массив.

- Выберем какое-нибудь число. Все элементы, меньшие, чем это число, переложим в один массив. Все элементы, большие или равные этому числу, — в другой. Тогда элементы слева будут меньше элементов справа.

- Отсортируем каждую из частей рекурсивно.
- Склеим левую часть с правой.
Готово! Получился отсортированный массив:

У этого алгоритма очень простая идея. Но есть несколько моментов, которые в алгоритме придётся прояснить. Мы должны выбрать какое-нибудь число. А какое именно число мы выбираем?
Выбор опорного элемента
Если мы выберем слишком большое число, то мы получим очень несбалансированное разбиение. Например, если мы выберем максимальный элемент, то получим два пустых массива и один массив с одним элементом. В этом случае мы получим очень неэффективный алгоритм, который будет работать за $O(n^2)$. Поэтому мы должны выбирать опорный элемент так, чтобы получить сбалансированное разбиение. Например, можно выбирать средний элемент. Но это не всегда работает. Например, если массив отсортирован, то мы получим сбалансированное разбиение, но неэффективный алгоритм. Поэтому мы будем выбирать случайный элемент. Это позволит нам получить сбалансированное разбиение и эффективный алгоритм. Но в этом случае мы не сможем гарантировать, что алгоритм будет работать за $O(n log n)$. В худшем случае он будет работать за $O(n^2)$. Но в среднем он будет работать за $O(n log n)$.
Сложность быстрой сортировки
... и почему она нестабильна
Сортировка подсчётом
В начале спринта мы разобрали алгоритм, который в худшем случае имеет квадратичную сложность — сортировка вставками. Потом поговорили о быстрой сортировке, которая на практике работает быстрее и имеет сложность в среднем $O(n \log n)$, но в худшем случае работает за $O(n^2)$. А ещё разобрали сортировку слиянием, сложность которой даже в худшем случае — $O(n \log n)$.
Можно ли решить задачу сортировки быстрее чем за $O(n \log n)$? - Можно, но лишь для узкого класса задач.
Принцип работы алгоритма
Рассмотрим, как работает алгоритм сортировки подсчётом. Допустим, дан массив чисел:
nums = [5, 7, 1, 0, 1, 5, 11, 1]
Нужно отсортировать его по неубыванию. При этом мы знаем, что числа в нём обозначают номера месяцев. То есть значения в массиве находятся в диапазоне от 0 до 11.
Заведём массив из 12 элементов, заполненный нулями.
months = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Теперь пройдёмся по массиву nums и увеличим на 1 соответствующий элемент в массиве months:
months[5] += 1
months[7] += 1
months[1] += 1
months[0] += 1
months[1] += 1
months[5] += 1
months[11] += 1
months[1] += 1
Получим:
months = [1, 3, 0, 0, 0, 2, 0, 1, 0, 0, 0, 1]
Теперь пройдёмся по массиву months и добавим в массив nums столько элементов, сколько встречается в months:
nums = []
for i in range(len(months)):
for j in range(months[i]):
nums.append(i)
Получим:
nums = [0, 1, 1, 1, 5, 5, 7, 11]
Так работает алгоритм сортировки подсчётом. Закрепим знания кодом. Этот код будет работать, если значения элементов массива лежат в полуинтервале от 0 до k:
def counting_sort(nums, k):
# Создаём массив из k элементов, заполненный нулями
counts = [0] * k
# Проходим по массиву nums и увеличиваем соответствующий элемент в массиве counts
for num in nums:
counts[num] += 1
# Проходим по массиву counts и добавляем в массив nums столько элементов, сколько встречается в counts
nums = []
for i in range(len(counts)):
for j in range(counts[i]):
nums.append(i)
return nums
Алгоритм сортировки подсчётом использует $O(k)$ дополнительной памяти, где $k$ — мощность множества значений (количество различных значений, которые могут встретиться в массиве). Эта память используется для хранения вспомогательного массива. Чтобы создать вспомогательный массив, нужно знать диапазон возможных значений. В примере нам понадобился дополнительный массив всего из 12 элементов.
Хеш-функции
Что такое отображение
О массивах мы говорили в самом начале курса, и сейчас они нам очень пригодятся. Напомним, что в интерфейсе массива есть две основные операции:
get(index: int) -> value— получить значениеvalueиз ячейки с индексомindex;set(index: int, value: ValueType)— записать значениеvalueв ячейку с индексомindex.
Каждая из этих операций выполняется за $O(1)$. Это очень быстро! Однако у массивов есть одно серьёзное ограничение: хотя в ячейках массива можно расположить объекты любого типа, индексы этих ячеек могут быть исключительно целыми числами.
Но в программе часто возникает необходимость получить объект не по его порядковому номеру, то есть индексу ячейки в массиве, а по какому-то другому признаку, например по названию. Или, как говорят программисты, получить значение (англ. value) по ключу (англ. key).
Давайте представим, что у нас есть множество городов и множество стран. Одному городу может быть сопоставлена одна страна — та, в которой этот город находится.

Нужно написать такую программу-справочник, которая по городу будет узнавать страну, где тот расположен. А ещё нам пригодится функция добавления новой пары «город»: «страна», если справочник будет пополняться.
В этой задаче город является ключом, а страна — значением. Каждому городу сопоставлена ровно одна страна ни больше ни меньше. А вот на страну может указывать любое количество городов.
Такое сопоставление, когда каждому объекту первого множества (множество городов) соответствует ровно один объект второго множества (множество стран), называется «отображением» (англ. map).
На самом деле отображение — это другое название математического термина «функция», или «функциональная зависимость». Чаще всего функции отображают числа (расположенные на оси X) в другие числа (расположенные на оси Y). Для каждого числа из области определения функции можно выписать другое число — значение функции в этой точке.
Массивы — это тоже частный случай отображения: они умеют сопоставлять целому числу любое значение. Например, массив ["яблоко", "груша", "яблоко"] сопоставляет числам 0 и 2 строку яблоко, а числу 1 — строку груша.
Чтобы работать с отображениями, нам требуется похожая на массив структура данных, которая умеет получать и сохранять значения:
get(key: KeyType) -> value— получить значениеvalueпо ключуkey;set(key: KeyType, value: ValueType)— записать значениеvalueпо ключуkey.
Но вместо целочисленного индекса она должна допускать ключ произвольного типа.
Интерфейс, описывающий две этих операции, называют Map. А любую структуру, которая реализует этот интерфейс, называют «ассоциативным массивом» (англ. associative array).
Ассоциативные массивы
В большинстве языков программирования ассоциативные массивы встроены в язык.
Чаще всего их называют так же, как интерфейс — Map, «отображение», или используют производные от слова «хеш-таблица»: Hash, HashMap, HashTable и даже просто Table. Эти названия подчёркивают, каким именно способом был реализован интерфейс отображения. Встречаются и другие наименования. Например, в Python ассоциативные массивы называют «словарями» (англ. dictionary).
Есть два популярных способа реализовать или, как говорят программисты, имплементировать отображение. Первый способ, хеш-таблицы, мы рассмотрим в этом спринте. Другой способ основан на деревьях поиска. В некоторых языках встречаются сразу обе реализации. Например, в Java отображения имплементированы двумя отдельными классами: HashMap и TreeMap. В языке C++ им соответствуют классы std::unordered_map и std::map.
Ассоциативный массив — настолько полезная структура, что во многих языках есть встроенный синтаксис для её создания. К примеру, в Python отображение реализовано типом dict.
Наивная реализация ассоциативного массива
В этом спринте мы будем изучать универсальные и часто используемые ассоциативные массивы, а именно хеш-таблицы. Узнаем, как они устроены и как ими пользуются разработчики.
Но сначала давайте рассмотрим простейший способ реализации ассоциативного массива. Заведём обыкновенный массив или список, в котором записаны пары (key, value).
Если нужно получить элемент по ключу, достаточно пройти по всем элементам списка, выбрать пару с подходящим значением ключа и вернуть значение, записанное в этой паре. Если значение нужно записать, ищем пару с указанным ключом. Если находим, то изменяем её. А если такая пара не нашлась, создаём её и добавляем в конец массива.
структура Map:
pairs = []
метод get(key):
for pair in pairs:
if pair.key == key: # пара с указанным ключом найдена
return pair.value
return None
метод set(key, value):
for pair in pairs:
if pair.key == key: # пара с указанным ключом найдена
# обновить значение в найденной паре
pair.value = value
return
# пара с заданным ключом не найдена
добавить пару (key, value) в pairs
У нас получилась очень медленная реализация: на поиск элемента в таком массиве в среднем требуется $O(n)$ операций. В следующем уроке мы поговорим о том, как реализовать отображение более эффективным способом — при помощи хеш-таблиц.
Что такое хеш-таблица и хеш-функция
Хеш-таблица (англ. hash table) — это один из способов реализовать ассоциативный массив, при котором все данные записываются и хранятся в виде пар (key, value) в ячейках обыкновенного массива. Эти ячейки называются корзинами (англ. bucket). Как и в любом массиве, ячейки-корзины пронумерованы. Индекс, или номер корзины, в которую отправляются данные, зависит от ключа. Можно завести специальную функцию, которая по ключу будет вычислять номер корзины.
Как работают хеш-функция и хеш-таблица
Но как сделать такую функцию? Если у нас всего три ключа, мы можем написать несколько условных операторов, чтобы определить номер корзины. Но если ключей много, функция разрастётся и будет медленно работать.
Эта проблема решается с помощью специальной техники, которая называется «хеширование». Для этого нам понадобится хеш-функция.
Хеш-функция (англ. hash function) — функция, которая обеспечивает преобразование входных данных в целое число. Для разных типов объектов применяются разные хеш-функции. Результат вычисления хеш-функции называется «хешем» или «хеш-суммой» (англ. hash, hash code или digest).
Представим, что у каждой буквы алфавита есть свой индекс, равный её порядковому номеру. Хеш-функция может возвращать значение, равное индексу первой буквы в названии ключа. Тогда, например, для яблока функция вернёт 33, для груши — 4, а для сливы — 19.

Так как хеш — целое число, его можно использовать как номер корзины. Например, информация про груши хранится в корзине 4. Это значит, что когда нам нужно получить или обновить информацию про число груш, достаточно заглянуть в эту ячейку. При этом нам не требуется запоминать номера ячеек, ведь при помощи хеш-функции их всегда легко вычислить.

Другой пример хеш-функции: мы можем возвращать сумму всех номеров букв, входящих в название фрукта. Тогда для «яблоко» значение функции будет 92, для «груша» — 70, а для «слива» — 46.
Многие хеш-функции выдают огромные числа: миллионы, миллиарды, а иногда и ещё больше. Поэтому хеш редко используется напрямую как номер ячейки. Чаще всего хеш — это промежуточная стадия вычисления. Сначала по ключу мы определяем хеш, а затем по хешу — номер корзины.

Отображение из ключа в значение разделилось на три независимых отображения. 1. Сначала хеш-функция отображает ключ в число, то есть в хеш. 2. Затем этот хеш преобразуется в индекс корзины. 3. И, наконец, из массива корзин мы находим нужную корзину по её индексу. В ней-то и хранится значение, которое возвращается пользователю.
Что такое коллизии
Ситуация, когда хеш-функция для разных входных данных выдаёт одно и то же значение, называется «коллизией».
Например, и у «арбуза», и у «абрикоса» значение хеша будет равно 1. Получается, что оба ключа указывают на одну и ту же корзину хеш-таблицы.
Коллизии могут случаться у всех без исключения хеш-функций, поэтому в реализации хеш-таблицы обязательно должна быть заложена логика их разрешения.
Выбор размера хеш-таблицы и вычисление номера корзины
Вычисление номера корзины методом деления
Самый простой способ получить номер корзины $\mathrm{bucket}(k)$ для целого ключа $k$ — взять остаток от деления ключа $k$ на число корзин $M$. Остаток от деления обозначается $k \bmod M$ и произносится «$k$ по модулю $M$». В языках программирования остаток от деления вычисляется оператором %.
Любое целое число $k$ может быть представлено в форме $k = j\cdot M + r$, где все числа — целые, а $r \in[0,M)$. Число $r$ и называется остатком от деления.
Такое определение нам удобно, поскольку остатки от деления целого числа на $M$ могут принимать целые значения в диапазоне от $0$ до $(M-1)$, и это ровно те же числа, которые могут служить номерами корзин в хеш-таблице длины $M$.
Будьте аккуратны! В разных языках программирования остаток от деления по-разному работает с отрицательными числами (см. подробности). Не всегда это происходит так же, как математическая операция взятия по модулю. Например, выражение $-13 % 5$ в одних языках даст $2$, в других $-3$. Если не учесть эти нюансы, можно получить отрицательный номер корзины.
Выбор числа корзин
В качестве $M$ нужно брать простое число. То есть такое, которое делится без остатка только на себя и на 1.
Дело в том, что ключи могут быть неравномерно распределены не только в двоичной и десятичной системах счисления. Есть много других закономерностей, которым ключи могут подчиняться.
Чем больше делителей у $M$, тем чаще такие закономерности будут приводить к коллизиям. И наоборот, простое значение $M$ уменьшает число коллизий, ведь у простого числа всего два делителя.
Для любого числа корзин можно придумать такую киллер-последовательность из ключей, из-за которой случится много коллизий. Но если делителей у M много, велик шанс наткнуться на такую последовательность случайно. А когда M — большое простое число, это маловероятно.
Вычисление номера корзины методом умножения
Ещё один популярный способ, применяемый для вычисления номера ячейки — метод умножения. Для вычисления нам снова потребуется целое число. На этот раз мы его сразу обозначим буквой $h$, чтобы подчеркнуть, что это хеш ключа. Пусть количество корзин равно $M$. Также зададим константу $\alpha \in (0,1)$.
Тогда $\mathrm{bucket}(h) = \left [ M \cdot \left { h \cdot \alpha \right } \right ]$ , где $\left [ x \right ]$ — обозначает целую часть числа $x$, $\left { x \right }$ — его дробную часть.
Алгоритм построения хеш-функции с использованием метода умножения:
- Домножаем хеш ключа $h$ на выбранную константу $\alpha$.
- Берём от результата дробную часть. Получается некоторое значение из диапазона $[0,1)$. Важно, что эти значения для разных ключей будут равномерно рассеяны.
- Домножаем полученное значение на размер таблицы $M$. Числа получаются распределёнными в диапазоне $[0, M)$
- Берём от результата целую часть. С равными вероятностями получаются числа от $0$ до $(M−1)$ — это и будут номера корзин. Корзины будут заполняться равномерно, это поможет нам уменьшить число коллизий.
Дональд Кнут провёл исследования и выяснил, что хеш-функция получается хорошей, если в качестве $\alpha$ брать число, обратное золотому сечению. $$ \displaystyle \alpha = \phi^{-1} = \left ( \frac{\sqrt 5 -1}{2} \right ) = 0.6180339887... $$
Свойства хеш-функций
Не любая функция подходит на роль хеш-функции. Как мы выяснили, нам нужна такая функция, которая принимает на вход данные и выдаёт число, соответствующее индексу корзины. Чтобы сформулировать основные свойства хеш-функций, давайте вспомним, зачем эти функции нужны.
При работе с разными объектами нам важно быстро находить подходящее место для них в хеш-таблице. Благодаря быстрому вычислению хеш-функции ключа мы можем эффективно обновлять информацию об объектах: искать их, добавлять или удалять.
Например, пусть нам нужно выяснить стоимость товара в магазине. Если функция потратит на вычисление позиции элемента в таблице больше времени, чем мы затратим, если будем искать его последовательным перебором всех товаров, то смысла в применении такой функции нет.
Функция, преобразующая ключ в индекс корзины в хеш-таблице, должна обладать такими свойствами:
- Детерминизм. Для одного и того же ключа функция всегда должна возвращать одинаковое значение. Если в функции будет браться случайное значение, то повторное её применение может выдать новый индекс ячейки, а значит, мы не сможем получить искомые данные из хеш-таблицы. Хорошая функция при повторном вызове выполняет те же действия, что и при первичном. Например, взятие числа по модулю другого числа — детерминированная функция, так как результат всегда будет одинаковым.
- Эффективность. Хеш-функция должна вычисляться достаточно быстро. Сложность операции поиска в хеш-таблице складывается из сложности вычисления хеша и сложности поиска данных по хешу. Важно, чтобы оба процесса выполнялись эффективно.
- Ограниченность. Результат вычисления функции должен принадлежать определённому диапазону, который соответствует размеру хеш-таблицы. Поэтому обычно сначала вычисляют хеш-функцию, которая возвращает произвольное число. А потом этот результат берут по модулю $M$ (размер хеш-таблицы). Таким образом, любой ключ будет находиться в интервале от $0$ до $M-1$, а значит, мы никогда не обратимся к индексу, который не соответствует ни одной из корзин.
- Равномерность. Данные должны быть распределены по хеш-таблице равномерно. То есть каждое выходное значение — равновероятно. Равновероятно — это значит, что если мы запустим функцию для каждого элемента из большого списка разных объектов, то в результате получим примерно равное число ответов функции для каждого значения от $0$ до $M-1$. В противном случае в какие-то ячейки мы будем пытаться записать значение чаще, чем в другие. И это замедлит обращение к хеш-таблице. Пример неравномерной функции — получение среднесуточной температуры по городу и дате, так как большую часть времени температура держится на одном и том же уровне, а аномальные морозы или жара случаются редко.
Мы рассмотрели 4 свойства функции, которые важны при реализации хеш-таблиц. Но хеширование используется и в других задачах. Например, для хранения паролей, проверки неизменности файла в процессе передачи, шифрования сообщений при передаче по сети. Для этих задач выделяют ещё несколько свойств, которые могут быть полезны хеш-функциям.
- Лавинность. При незначительном изменении входных данных выходное значение должно меняться значительно. При хешировании паролей нелавинная функция проще взламывается. Если злоумышленник знает, что $h(aa) = 22$, а $h(bb) = 33$, то он может предположить такой $password$, что $h(password) = 44$. Перебрав небольшое число вариантов, злоумышленник сможет подобрать пароль по его хешу.
- Необратимость. Невозможно восстановить ключ по значению функции. Например, при регистрации на сайте пользователь вводит свой пароль, к которому применяется хеш-функция. Полученный хеш записывается в базу данных — в ячейку, соответствующую данному пользователю. Каждый раз, когда пользователь вводит пароль, к нему применяется та же функция. Так как алгоритм получения хеша от строки пароля в обоих случаях одинаковый, новый хеш совпадёт с записью в базе данных, если пользователь ввёл свой исходный пароль. Даже если злоумышленник получит доступ к данным в базе, у него не должно быть возможности восстановить пароль.
Построение хеш-функций для строк
Теперь давайте рассмотрим, как вычисляются хеш-функций для строк. Для этого есть специальный алгоритм, который называется «полиномиальным хешированием» (от слова «полином» — многочлен). Хеш строки $s$ вычисляется по формуле: $$ h(s)=\left(s_{1} q^{n-1}+s_{2} q^{n-2}+\cdots+s_{n-1} q+s_{n}\right) \bmod R $$ Где $s_i$ — код $i$-го символа (например, ASCII-код), $n$ — длина строки, а $R$ и $q$ — выбранные константы.
Все вычисления производятся по модулю некоторого большого числа $R$, поскольку для длинных строк сумма в скобках может оказаться слишком большой. В большинстве языков программирования при этом произойдёт переполнение типа целых чисел. В языках, где реализована так называемая «длинная арифметика», переполнения не случится, но с ростом значений складываемых и перемножаемых чисел вычисления будут становиться всё медленнее и медленнее.
Выбор числа $R$ зависит от типа переменной, в которой хранятся хеши. Например, для беззнаковых 4-байтовых целых чисел удобно выбрать $R=2^{32}$. Для 8-байтовых чисел можно взять $R=2^{64}$.
Если строки длинные, выбор величины $q$ не так важен — в сумму будут входить значения $q$ в достаточно больших степенях. Но ради универсальности лучше и в этом случае взять большое число. Число $q$ должно быть не только большим, но и простым.
Помните, мы говорили, что индекс корзины вычисляется взятием остатка от деления значения хеша на число корзин? Чем меньше общих делителей у $q$, $M$ и $R$, тем реже будут возникать коллизии. В качестве $R$ мы уже договорились использовать $2^{32}$, поэтому любое нечётное число не будет иметь с $R$ общих делителей.
Число $M$ будет меняться в зависимости от размера хеш-таблицы. При вычислении хеш-функции этот размер ещё не известен. Из-за этого мы не можем гарантировать, что параметр вычисления хеш-функции $q$ и число корзин $M$ будут взаимно простыми. Но выбор большого простого числа в качестве $q$ делает вероятность наличия нетривиальных общих делителей очень небольшой, ведь у простого числа нет делителей, кроме самого этого числа и единицы. Как мы говорили, $M$ обычно тоже делают простым, поэтому общие делители могут получиться, только когда $M=q$.
Поисковый индекс
Напомним основной принцип хеш-таблиц: если вы знаете, куда был положен элемент, то искать его нужно там же. Это правило часто применяют для быстрого поиска по данным.
Представьте, что вы пишете программу для чтения, и одной из её функций должен быть поиск по тексту. Пользователь вводит слово или строку, а программа находит и показывает их позиции в тексте.
Можно реализовать эту программу с помощью хеш-таблицы, в которой ключами будут строки, а значениями — массивы позиций, где эта строка встречается.
Отображение, которое каждому объекту ставит в соответствие его расположение, называют «поисковым индексом».
Если пользователь введёт любую подстроку, хеш-таблица должна найти её позиции. Значит, нужно предварительно добавить туда все возможные подстроки. А если подстроки в хеш-таблице не оказалось, получается, и в тексте её нет.
Этот способ позволит нам сразу получить нужную позицию — это, конечно, хорошо. Но он очень неэффективный. Ведь подстрок в тексте может быть столько, сколько существует способов выбрать две границы: $N\cdot(N-1)/ 2$, где $N$ — длина текста. Значит, в хеш-таблицу нужно добавить $O(N^2)$ пар (key, value). Поскольку ключами являются подстроки, каждая такая пара займёт в среднем $O(N)$ памяти. Получается, что всего при такой реализации придётся потратить $O(N^3)$ памяти.
Поэтому с большими текстами такая реализация не сработает.
...
Введение в вычислительную физику
Понятия сходимости, аппроксимации и устойчивости
Python Tutorial
Introduction
Python is a great general-purpose programming language on its own, but with the help of a few popular libraries (numpy, scipy, matplotlib and holoviews) it becomes a powerful environment for scientific computing.
We expect that many of you will have some experience with Python and Numpy; for the rest of you, this section will serve as a quick crash course both on the Python programming language and on the use of Python for scientific computing.
In this tutorial, we will cover:
- Basic Python: Basic data types, Functions, Classes
- Numpy: Arrays, Array indexing, Datatypes, Array math, Broadcasting
- Matplotlib: Plotting, Subplots, Images
- IPython: Creating notebooks, Typical workflows
Basics of Python
Python is a high-level, dynamically typed multiparadigm programming language. Python code is often said to be almost like pseudocode, since it allows you to express very powerful ideas in very few lines of code while being very readable.
We recommend to read PEP 8.
Python versions and Zen of Python
There are currently supported versions of Python 3.X. Support for Python 2.7 ended in 2020. For this class all code will use Python 3.7.
You can check your Python version at the command line by running python --version.
!python --version
Python 3.7.4
import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
Basic data types
Numbers
Integers and floats work as you would expect from other languages:
x = 3
print(x, type(x))
3 <class 'int'>
print(x + 1) # Addition;
print(x - 1) # Subtraction;
print(x * 2) # Multiplication;
print(x ** 2) # Exponentiation;
4
2
6
9
x += 1
print(x) # Prints "4"
x *= 2
print(x) # Prints "8"
4
8
y = 2.5
print(type(y)) # Prints "<type 'float'>"
print(y, y + 1, y * 2, y ** 2) # Prints "2.5 3.5 5.0 6.25"
<class 'float'>
2.5 3.5 5.0 6.25
Note that unlike many languages, Python does not have unary increment (x++) or decrement (x--) operators.
Python also has built-in types for long integers and complex numbers; you can find all of the details in the documentation.
Booleans
Python implements all of the usual operators for Boolean logic, but uses English words rather than symbols (&&, ||, etc.):
T, F = True, False
print(type(T)) # Prints "<type 'bool'>"
<class 'bool'>
Now we let's look at the operations:
print(T and F) # Logical AND;
print(T or F) # Logical OR;
print(not T) # Logical NOT;
print(T != F) # Logical XOR;
False
True
False
True
Strings
hello = 'hello' # String literals can use single quotes
world = "world" # or double quotes; it does not matter.
print(hello, len(hello))
hello 5
hw = hello + ' ' + world # String concatenation
print(hw) # prints "hello world"
hello world
hw12 = '%s %s %d' % (hello, world, 12) # sprintf style string formatting
print(hw12) # prints "hello world 12"
hello world 12
String objects have a bunch of useful methods; for example:
s = "hello"
print(s.capitalize()) # Capitalize a string; prints "Hello"
print(s.upper()) # Convert a string to uppercase; prints "HELLO"
print(s.rjust(7)) # Right-justify a string, padding with spaces; prints " hello"
print(s.center(7)) # Center a string, padding with spaces; prints " hello "
print(s.replace('l', '(ell)')) # Replace all instances of one substring with another;
# prints "he(ell)(ell)o"
print(' world '.strip()) # Strip leading and trailing whitespace; prints "world"
Hello
HELLO
hello
hello
he(ell)(ell)o
world
You can find a list of all string methods in the documentation.
Containers
Python includes several built-in container types: lists, dictionaries, sets, and tuples.
Lists
A list is the Python equivalent of an array, but is resizeable and can contain elements of different types:
xs = [3, 1, 2] # Create a list
print(xs, xs[2])
print(xs[-1]) # Negative indices count from the end of the list; prints "2"
[3, 1, 2] 2
2
xs[2] = 'foo' # Lists can contain elements of different types
print(xs)
[3, 1, 'foo']
xs.append('bar') # Add a new element to the end of the list
print(xs)
[3, 1, 'foo', 'bar']
x = xs.pop() # Remove and return the last element of the list
print(x, xs)
bar [3, 1, 'foo']
As usual, you can find all the gory details about lists in the documentation.
Slicing
In addition to accessing list elements one at a time, Python provides concise syntax to access sublists; this is known as slicing:
nums = range(5) # range is a built-in function that creates a list of integers
print(nums) # Prints "[0, 1, 2, 3, 4]"
print(nums[2:4]) # Get a slice from index 2 to 4 (exclusive); prints "[2, 3]"
print(nums[2:]) # Get a slice from index 2 to the end; prints "[2, 3, 4]"
print(nums[:2]) # Get a slice from the start to index 2 (exclusive); prints "[0, 1]"
print(nums[:]) # Get a slice of the whole list; prints ["0, 1, 2, 3, 4]"
print(nums[:-1]) # Slice indices can be negative; prints ["0, 1, 2, 3]"
range(0, 5)
range(2, 4)
range(2, 5)
range(0, 2)
range(0, 5)
range(0, 4)
Loops
You can loop over the elements of a list like this:
animals = ['cat', 'dog', 'monkey']
for animal in animals:
print(animal)
cat
dog
monkey
If you want access to the index of each element within the body of a loop, use the built-in enumerate function:
animals = ['cat', 'dog', 'monkey']
for idx, animal in enumerate(animals):
print('#%d: %s' % (idx + 1, animal))
#1: cat
#2: dog
#3: monkey
List comprehensions:
When programming, frequently we want to transform one type of data into another. As a simple example, consider the following code that computes square numbers:
nums = [0, 1, 2, 3, 4]
squares = []
for x in nums:
squares.append(x ** 2)
print(squares)
[0, 1, 4, 9, 16]
You can make this code simpler using a list comprehension:
nums = [0, 1, 2, 3, 4]
squares = [x ** 2 for x in nums]
print(squares)
[0, 1, 4, 9, 16]
List comprehensions can also contain conditions:
nums = [0, 1, 2, 3, 4]
even_squares = [x ** 2 for x in nums if x % 2 == 0]
print(even_squares)
[0, 4, 16]
Dictionaries
A dictionary stores (key, value) pairs, similar to a Map in Java or an object in Javascript. You can use it like this:
d = {'cat': 'cute', 'dog': 'furry'} # Create a new dictionary with some data
print(d['cat']) # Get an entry from a dictionary; prints "cute"
print('cat' in d) # Check if a dictionary has a given key; prints "True"
cute
True
d['fish'] = 'wet' # Set an entry in a dictionary
print(d['fish']) # Prints "wet"
wet
print(d.get('monkey', 'N/A')) # Get an element with a default; prints "N/A"
print(d.get('fish', 'N/A')) # Get an element with a default; prints "wet"
N/A
wet
del d['fish'] # Remove an element from a dictionary
print(d.get('fish', 'N/A')) # "fish" is no longer a key; prints "N/A"
N/A
You can find all you need to know about dictionaries in the documentation.
It is easy to iterate over the keys in a dictionary:
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal in d:
legs = d[animal]
print('A %s has %d legs' % (animal, legs))
A person has 2 legs
A cat has 4 legs
A spider has 8 legs
Dictionary comprehensions: These are similar to list comprehensions, but allow you to easily construct dictionaries. For example:
nums = [0, 1, 2, 3, 4]
even_num_to_square = {x: x ** 2 for x in nums if x % 2 == 0}
print(even_num_to_square)
{0: 0, 2: 4, 4: 16}
Sets
A set is an unordered collection of distinct elements. As a simple example, consider the following:
animals = {'cat', 'dog'}
print('cat' in animals) # Check if an element is in a set; prints "True"
print('fish' in animals) # prints "False"
True
False
animals.add('fish') # Add an element to a set
print('fish' in animals)
print(len(animals)) # Number of elements in a set;
True
3
animals.add('cat') # Adding an element that is already in the set does nothing
print(len(animals))
animals.remove('cat') # Remove an element from a set
print(len(animals))
3
2
Loops: Iterating over a set has the same syntax as iterating over a list; however since sets are unordered, you cannot make assumptions about the order in which you visit the elements of the set:
animals = {'cat', 'dog', 'fish'}
for idx, animal in enumerate(animals):
print('#%d: %s' % (idx + 1, animal))
# Prints "#1: fish", "#2: dog", "#3: cat"
#1: fish
#2: dog
#3: cat
Set comprehensions: Like lists and dictionaries, we can easily construct sets using set comprehensions:
from math import sqrt
print({int(sqrt(x)) for x in range(30)})
{0, 1, 2, 3, 4, 5}
Tuples
A tuple is an (immutable) ordered list of values. A tuple is in many ways similar to a list; one of the most important differences is that tuples can be used as keys in dictionaries and as elements of sets, while lists cannot. Here is a trivial example:
d = {(x, x + 1): x for x in range(10)} # Create a dictionary with tuple keys
t = (5, 6) # Create a tuple
print(type(t))
print(d[t])
print(d[(1, 2)])
<class 'tuple'>
5
1
Functions
Python functions are defined using the def keyword. For example:
def sign(x: float) -> str:
'''Function sign''' # document line
if x > 0:
return 'positive'
elif x < 0:
return 'negative'
else:
return 'zero'
for x in [-1, 0, 1]:
print(sign(x))
negative
zero
positive
help(sign)
Help on function sign in module __main__:
sign(x: float) -> str
Function sign
We will often define functions to take optional keyword arguments, like this:
def hello(name: str, loud: bool=False) -> None:
'''Function hello
If loud is True,
then the name is printed in capital letters.
'''
if loud:
print('HELLO, %s' % name.upper())
else:
print('Hello, %s!' % name)
hello('Bob')
hello('Fred', loud=True)
Hello, Bob!
HELLO, FRED
help(hello)
Help on function hello in module __main__:
hello(name: str, loud: bool = False) -> None
Function hello
If loud is True,
then the name is printed in capital letters.
Classes
The syntax for defining classes in Python is straightforward:
class Greeter:
'''Class Greeter
method greet:
If loud is True,
then the name is printed in capital letters.
'''
# Constructor
def __init__(self, name):
self.name = name # Create an instance variable
# Instance method
def greet(self, loud: bool=False) ->None:
if loud:
print('HELLO, %s!' % self.name.upper())
else:
print('Hello, %s' % self.name)
g = Greeter('Fred') # Construct an instance of the Greeter class
g.greet() # Call an instance method; prints "Hello, Fred"
g.greet(loud=True) # Call an instance method; prints "HELLO, FRED!"
Hello, Fred
HELLO, FRED!
help(Greeter)
Help on class Greeter in module __main__:
class Greeter(builtins.object)
| Greeter(name)
|
| Class Greeter
|
| method greet:
| If loud is True,
| then the name is printed in capital letters.
|
| Methods defined here:
|
| __init__(self, name)
| Initialize self. See help(type(self)) for accurate signature.
|
| greet(self, loud: bool = False) -> None
| # Instance method
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
Numpy
Numpy is the core library for scientific computing in Python. It provides a high-performance multidimensional array object, and tools for working with these arrays.
To use Numpy, we first need to import the numpy package:
import numpy as np
Arrays
A numpy array is a grid of values, all of the same type, and is indexed by a tuple of nonnegative integers. The number of dimensions is the rank of the array; the shape of an array is a tuple of integers giving the size of the array along each dimension.
We can initialize numpy arrays from nested Python lists, and access elements using square brackets:
a = np.array([1, 2, 3]) # Create a rank 1 array
print(type(a), a.shape, a[0], a[1], a[2])
a[0] = 5 # Change an element of the array
print(a)
<class 'numpy.ndarray'> (3,) 1 2 3
[5 2 3]
b = np.array([[1,2,3],[4,5,6]]) # Create a rank 2 array
print(b)
[[1 2 3]
[4 5 6]]
print(b.shape)
print(b[0, 0], b[0, 1], b[1, 0])
(2, 3)
1 2 4
Numpy also provides many functions to create arrays:
a = np.zeros((2,2)) # Create an array of all zeros
print(a)
[[0. 0.]
[0. 0.]]
b = np.ones((1,2)) # Create an array of all ones
print(b)
[[1. 1.]]
c = np.full((2,2), 7) # Create a constant array
print(c)
[[7 7]
[7 7]]
d = np.eye(2) # Create a 2x2 identity matrix
print(d)
[[1. 0.]
[0. 1.]]
e = np.random.random((2,2)) # Create an array filled with random values
print(e)
[[0.57584699 0.0757792 ]
[0.18793454 0.78004389]]
Array indexing
Numpy offers several ways to index into arrays.
Slicing: Similar to Python lists, numpy arrays can be sliced. Since arrays may be multidimensional, you must specify a slice for each dimension of the array:
import numpy as np
# Create the following rank 2 array with shape (3, 4)
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
# Use slicing to pull out the subarray consisting of the first 2 rows
# and columns 1 and 2; b is the following array of shape (2, 2):
# [[2 3]
# [6 7]]
b = a[:2, 1:3]
print(b)
[[2 3]
[6 7]]
A slice of an array is a view into the same data, so modifying it will modify the original array.
print(a[0, 1])
b[0, 0] = 77 # b[0, 0] is the same piece of data as a[0, 1]
print(a[0, 1])
2
77
You can also mix integer indexing with slice indexing. However, doing so will yield an array of lower rank than the original array.
# Create the following rank 2 array with shape (3, 4)
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
print(a)
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
Two ways of accessing the data in the middle row of the array. Mixing integer indexing with slices yields an array of lower rank, while using only slices yields an array of the same rank as the original array:
row_r1 = a[1, :] # Rank 1 view of the second row of a
row_r2 = a[1:2, :] # Rank 2 view of the second row of a
row_r3 = a[[1], :] # Rank 2 view of the second row of a
print(row_r1, row_r1.shape)
print(row_r2, row_r2.shape)
print(row_r3, row_r3.shape)
[5 6 7 8] (4,)
[[5 6 7 8]] (1, 4)
[[5 6 7 8]] (1, 4)
# We can make the same distinction when accessing columns of an array:
col_r1 = a[:, 1]
col_r2 = a[:, 1:2]
print(col_r1, col_r1.shape)
print(col_r2, col_r2.shape)
[ 2 6 10] (3,)
[[ 2]
[ 6]
[10]] (3, 1)
Integer array indexing: When you index into numpy arrays using slicing, the resulting array view will always be a subarray of the original array. In contrast, integer array indexing allows you to construct arbitrary arrays using the data from another array. Here is an example:
a = np.array([[1,2], [3, 4], [5, 6]])
# An example of integer array indexing.
# The returned array will have shape (3,) and
print(a[[0, 1, 2], [0, 1, 0]])
# The above example of integer array indexing is equivalent to this:
print(np.array([a[0, 0], a[1, 1], a[2, 0]]))
[1 4 5]
[1 4 5]
# When using integer array indexing, you can reuse the same
# element from the source array:
print(a[[0, 0], [1, 1]])
# Equivalent to the previous integer array indexing example
print(np.array([a[0, 1], a[0, 1]]))
[2 2]
[2 2]
One useful trick with integer array indexing is selecting or mutating one element from each row of a matrix:
# Create a new array from which we will select elements
a = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
print(a)
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
# Create an array of indices
b = np.array([0, 2, 0, 1])
# Select one element from each row of a using the indices in b
print(a[np.arange(4), b]) # Prints "[ 1 6 7 11]"
[ 1 6 7 11]
# Mutate one element from each row of a using the indices in b
a[np.arange(4), b] += 10
print(a)
[[11 2 3]
[ 4 5 16]
[17 8 9]
[10 21 12]]
Boolean array indexing: Boolean array indexing lets you pick out arbitrary elements of an array. Frequently this type of indexing is used to select the elements of an array that satisfy some condition. Here is an example:
import numpy as np
a = np.array([[1,2], [3, 4], [5, 6]])
bool_idx = (a > 2) # Find the elements of a that are bigger than 2;
# this returns a numpy array of Booleans of the same
# shape as a, where each slot of bool_idx tells
# whether that element of a is > 2.
print(bool_idx)
[[False False]
[ True True]
[ True True]]
# We use boolean array indexing to construct a rank 1 array
# consisting of the elements of a corresponding to the True values
# of bool_idx
print(a[bool_idx])
# We can do all of the above in a single concise statement:
print(a[a > 2])
[3 4 5 6]
[3 4 5 6]
For brevity we have left out a lot of details about numpy array indexing; if you want to know more you should read the documentation.
Datatypes
Every numpy array is a grid of elements of the same type. Numpy provides a large set of numeric datatypes that you can use to construct arrays. Numpy tries to guess a datatype when you create an array, but functions that construct arrays usually also include an optional argument to explicitly specify the datatype. Here is an example:
x = np.array([1, 2]) # Let numpy choose the datatype
y = np.array([1.0, 2.0]) # Let numpy choose the datatype
z = np.array([1, 2], dtype=np.int64) # Force a particular datatype
print(x.dtype, y.dtype, z.dtype)
int64 float64 int64
You can read all about numpy datatypes in the documentation.
Array math
Basic mathematical functions operate elementwise on arrays, and are available both as operator overloads and as functions in the numpy module:
x = np.array([[1,2],[3,4]], dtype=np.float64)
y = np.array([[5,6],[7,8]], dtype=np.float64)
# Elementwise sum; both produce the array
print(x + y)
print(np.add(x, y))
[[ 6. 8.]
[10. 12.]]
[[ 6. 8.]
[10. 12.]]
# Elementwise difference; both produce the array
print(x - y)
print(np.subtract(x, y))
[[-4. -4.]
[-4. -4.]]
[[-4. -4.]
[-4. -4.]]
# Elementwise product; both produce the array
print(x * y)
print(np.multiply(x, y))
[[ 5. 12.]
[21. 32.]]
[[ 5. 12.]
[21. 32.]]
# Elementwise division; both produce the array
# [[ 0.2 0.33333333]
# [ 0.42857143 0.5 ]]
print(x / y)
print(np.divide(x, y))
[[0.2 0.33333333]
[0.42857143 0.5 ]]
[[0.2 0.33333333]
[0.42857143 0.5 ]]
# Elementwise square root; produces the array
# [[ 1. 1.41421356]
# [ 1.73205081 2. ]]
print(np.sqrt(x))
[[1. 1.41421356]
[1.73205081 2. ]]
Note that unlike MATLAB, * is elementwise multiplication, not matrix multiplication. We instead use the dot function to compute inner products of vectors, to multiply a vector by a matrix, and to multiply matrices. dot is available both as a function in the numpy module and as an instance method of array objects:
x = np.array([[1,2],[3,4]])
y = np.array([[5,6],[7,8]])
v = np.array([9,10])
w = np.array([11, 12])
# Inner product of vectors; both produce 219
print(v.dot(w))
print(np.dot(v, w))
219
219
# Matrix / vector product; both produce the rank 1 array [29 67]
print(x.dot(v))
print(np.dot(x, v))
[29 67]
[29 67]
# Matrix / matrix product; both produce the rank 2 array
# [[19 22]
# [43 50]]
print(x.dot(y))
print(np.dot(x, y))
[[19 22]
[43 50]]
[[19 22]
[43 50]]
Numpy provides many useful functions for performing computations on arrays; one of the most useful is sum:
x = np.array([[1,2],[3,4]])
print(np.sum(x)) # Compute sum of all elements; prints "10"
print(np.sum(x, axis=0)) # Compute sum of each column; prints "[4 6]"
print(np.sum(x, axis=1)) # Compute sum of each row; prints "[3 7]"
10
[4 6]
[3 7]
You can find the full list of mathematical functions provided by numpy in the documentation.
Apart from computing mathematical functions using arrays, we frequently need to reshape or otherwise manipulate data in arrays. The simplest example of this type of operation is transposing a matrix; to transpose a matrix, simply use the T attribute of an array object:
print(x)
print(x.T)
[[1 2]
[3 4]]
[[1 3]
[2 4]]
v = np.array([[1,2,3]])
print(v)
print(v.T)
[[1 2 3]]
[[1]
[2]
[3]]
Broadcasting
Broadcasting is a powerful mechanism that allows numpy to work with arrays of different shapes when performing arithmetic operations. Frequently we have a smaller array and a larger array, and we want to use the smaller array multiple times to perform some operation on the larger array.
For example, suppose that we want to add a constant vector to each row of a matrix. We could do it like this:
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = np.empty_like(x) # Create an empty matrix with the same shape as x
# Add the vector v to each row of the matrix x with an explicit loop
for i in range(4):
y[i, :] = x[i, :] + v
print(y)
[[ 2 2 4]
[ 5 5 7]
[ 8 8 10]
[11 11 13]]
This works; however when the matrix x is very large, computing an explicit loop in Python could be slow. Note that adding the vector v to each row of the matrix x is equivalent to forming a matrix vv by stacking multiple copies of v vertically, then performing elementwise summation of x and vv. We could implement this approach like this:
vv = np.tile(v, (4, 1)) # Stack 4 copies of v on top of each other
print(vv) # Prints "[[1 0 1]
# [1 0 1]
# [1 0 1]
# [1 0 1]]"
[[1 0 1]
[1 0 1]
[1 0 1]
[1 0 1]]
y = x + vv # Add x and vv elementwise
print(y)
[[ 2 2 4]
[ 5 5 7]
[ 8 8 10]
[11 11 13]]
Numpy broadcasting allows us to perform this computation without actually creating multiple copies of v. Consider this version, using broadcasting:
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = x + v # Add v to each row of x using broadcasting
print(y)
[[ 2 2 4]
[ 5 5 7]
[ 8 8 10]
[11 11 13]]
The line y = x + v works even though x has shape (4, 3) and v has shape (3,) due to broadcasting; this line works as if v actually had shape (4, 3), where each row was a copy of v, and the sum was performed elementwise.
Broadcasting two arrays together follows these rules:
- If the arrays do not have the same rank, prepend the shape of the lower rank array with 1s until both shapes have the same length.
- The two arrays are said to be compatible in a dimension if they have the same size in the dimension, or if one of the arrays has size 1 in that dimension.
- The arrays can be broadcast together if they are compatible in all dimensions.
- After broadcasting, each array behaves as if it had shape equal to the elementwise maximum of shapes of the two input arrays.
- In any dimension where one array had size 1 and the other array had size greater than 1, the first array behaves as if it were copied along that dimension
If this explanation does not make sense, try reading the explanation from the documentation.
Functions that support broadcasting are known as universal functions. You can find the list of all universal functions in the documentation.
Here are some applications of broadcasting:
# Compute outer product of vectors
v = np.array([1,2,3]) # v has shape (3,)
w = np.array([4,5]) # w has shape (2,)
# To compute an outer product, we first reshape v to be a column
# vector of shape (3, 1); we can then broadcast it against w to yield
# an output of shape (3, 2), which is the outer product of v and w:
print(np.reshape(v, (3, 1)) * w)
[[ 4 5]
[ 8 10]
[12 15]]
# Add a vector to each row of a matrix
x = np.array([[1,2,3], [4,5,6]])
# x has shape (2, 3) and v has shape (3,) so they broadcast to (2, 3),
# giving the following matrix:
print(x + v)
[[2 4 6]
[5 7 9]]
# Add a vector to each column of a matrix
# x has shape (2, 3) and w has shape (2,).
# If we transpose x then it has shape (3, 2) and can be broadcast
# against w to yield a result of shape (3, 2); transposing this result
# yields the final result of shape (2, 3) which is the matrix x with
# the vector w added to each column. Gives the following matrix:
print((x.T + w).T)
[[ 5 6 7]
[ 9 10 11]]
# Another solution is to reshape w to be a row vector of shape (2, 1);
# we can then broadcast it directly against x to produce the same
# output.
print(x + np.reshape(w, (2, 1)))
[[ 5 6 7]
[ 9 10 11]]
# Multiply a matrix by a constant:
# x has shape (2, 3). Numpy treats scalars as arrays of shape ();
# these can be broadcast together to shape (2, 3), producing the
# following array:
print(x * 2)
[[ 2 4 6]
[ 8 10 12]]
Broadcasting typically makes your code more concise and faster, so you should strive to use it where possible.
This brief overview has touched on many of the important things that you need to know about numpy, but is far from complete. Check out the numpy reference to find out much more about numpy.
Scipy
To be continued...
Matplotlib
Matplotlib is a plotting library. In this section give a brief introduction to the matplotlib.pyplot module, which provides a plotting system similar to that of MATLAB.
import matplotlib.pyplot as plt
By running this special iPython command, we will be displaying plots inline:
%matplotlib inline
Plotting
The most important function in matplotlib is plot, which allows you to plot 2D data. Here is a simple example:
# Compute the x and y coordinates for points on a sine curve
x = np.arange(0, 3 * np.pi, 0.1)
y = np.sin(x)
# Plot the points using matplotlib
plt.plot(x, y)
[<matplotlib.lines.Line2D at 0x1142b94d0>]
With just a little bit of extra work we can easily plot multiple lines at once, and add a title, legend, and axis labels:
y_sin = np.sin(x)
y_cos = np.cos(x)
# Plot the points using matplotlib
plt.plot(x, y_sin)
plt.plot(x, y_cos)
plt.xlabel('x axis label')
plt.ylabel('y axis label')
plt.title('Sine and Cosine')
plt.legend(['Sine', 'Cosine'])
<matplotlib.legend.Legend at 0x114390a50>
Subplots
You can plot different things in the same figure using the subplot function. Here is an example:
# Compute the x and y coordinates for points on sine and cosine curves
x = np.arange(0, 3 * np.pi, 0.1)
y_sin = np.sin(x)
y_cos = np.cos(x)
# Set up a subplot grid that has height 2 and width 1,
# and set the first such subplot as active.
plt.subplot(2, 1, 1)
# Make the first plot
plt.plot(x, y_sin)
plt.title('Sine')
# Set the second subplot as active, and make the second plot.
plt.subplot(2, 1, 2)
plt.plot(x, y_cos)
plt.title('Cosine')
# Show the figure.
plt.show()
You can read much more about the subplot function in the documentation.
Holoviews
To be continued...
Performance
Class Matrix
import random
class Matrix(list):
@classmethod
def zeros(cls, shape):
n_rows, n_cols = shape
return cls([[0] * n_cols for i in range(n_rows)])
@classmethod
def random(cls, shape):
M, (n_rows, n_cols) = cls(), shape
for i in range(n_rows):
M.append([random.randint(-255, 255)
for j in range(n_cols)])
return M
def transpose(self):
n_rows, n_cols = self.shape
return self.__class__(zip(*self))
@property
def shape(self):
return ((0, 0) if not self else
(len(self), len(self[0])))
def matrix_product(X, Y):
"""Computes the matrix product of X and Y.
>>> X = Matrix([[1], [2], [3]])
>>> Y = Matrix([[4, 5, 6]])
>>> matrix_product(X, Y)
[[4, 5, 6], [8, 10, 12], [12, 15, 18]]
>>> matrix_product(Y, X)
[[32]]
"""
n_xrows, n_xcols = X.shape
n_yrows, n_ycols = Y.shape
# верим, что с размерностями всё хорошо
Z = Matrix.zeros((n_xrows, n_ycols))
for i in range(n_xrows):
for j in range(n_xcols):
for k in range(n_ycols):
Z[i][k] += X[i][j] * Y[j][k]
return Z
%doctest_mode
Exception reporting mode: Plain
Doctest mode is: ON
>>> X = Matrix([[1], [2], [3]])
>>> Y = Matrix([[4, 5, 6]])
>>> matrix_product(X, Y)
[[4, 5, 6], [8, 10, 12], [12, 15, 18]]
>>> matrix_product(Y, X)
[[32]]
[[32]]
%doctest_mode
Exception reporting mode: Context
Doctest mode is: OFF
Runtime measurement
Everything seems to work, but how fast? Use the magic timeit command to check.
%%timeit shape = 64, 64; X = Matrix.random(shape); Y = Matrix.random(shape)
matrix_product(X, Y)
86.6 ms ± 1.52 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
Total: Multiplying two 64x64 matrices takes near 0.1 seconds. Y U SO SLOW?
We define an auxiliary function bench, which generates random matrices of the specified size, and then n_iter times multiplies them in a loop.
def bench(shape=(64, 64), n_iter=16):
X = Matrix.random(shape)
Y = Matrix.random(shape)
for iter in range(n_iter):
matrix_product(X, Y)
Let's try to look at it more closely with the help of the line_profiler module.
#!pip install line_profiler
%load_ext line_profiler
%lprun -f matrix_product bench()
Note that the operation list .__ getitem__ is not free. Swap the for loops so that the code does less index lookups.
def matrix_product(X, Y):
n_xrows, n_xcols = X.shape
n_yrows, n_ycols = Y.shape
Z = Matrix.zeros((n_xrows, n_ycols))
for i in range(n_xrows):
Xi = X[i]
for k in range(n_ycols):
acc = 0
for j in range(n_xcols):
acc += Xi[j] * Y[j][k]
Z[i][k] = acc
return Z
%lprun -f matrix_product bench()
2 seconds faster, but still too slow:> 30% of the time goes exclusively to iteration! Fix it.
def matrix_product(X, Y):
n_xrows, n_xcols = X.shape
n_yrows, n_ycols = Y.shape
Z = Matrix.zeros((n_xrows, n_ycols))
for i in range(n_xrows):
Xi, Zi = X[i], Z[i]
for k in range(n_ycols):
Zi[k] = sum(Xi[j] * Y[j][k] for j in range(n_xcols))
return Z
%lprun -f matrix_product bench()
The matrix_product functions are pretty prettier. But, it seems, this is not the limit. Let’s try again to remove unnecessary index calls from the innermost cycle.
def matrix_product(X, Y):
n_xrows, n_xcols = X.shape
n_yrows, n_ycols = Y.shape
Z = Matrix.zeros((n_xrows, n_ycols))
Yt = Y.transpose() # <--
for i, (Xi, Zi) in enumerate(zip(X, Z)):
for k, Ytk in enumerate(Yt):
Zi[k] = sum(Xi[j] * Ytk[j] for j in range(n_xcols))
return Z
Numba
Numba does not work with inline lists. Rewrite the matrix_product function using ndarray.
import numba
import numpy as np
@numba.jit
def jit_matrix_product(X, Y):
n_xrows, n_xcols = X.shape
n_yrows, n_ycols = Y.shape
Z = np.zeros((n_xrows, n_ycols), dtype=X.dtype)
for i in range(n_xrows):
for k in range(n_ycols):
for j in range(n_xcols):
Z[i, k] += X[i, j] * Y[j, k]
return Z
Let's see what happened.
shape = 64, 64
X = np.random.randint(-255, 255, shape)
Y = np.random.randint(-255, 255, shape)
%timeit -n100 jit_matrix_product(X, Y)
The slowest run took 21.46 times longer than the fastest. This could mean that an intermediate result is being cached.
495 µs ± 900 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Cython
%load_ext cython
%%capture
%%cython -a
import random
class Matrix(list):
@classmethod
def zeros(cls, shape):
n_rows, n_cols = shape
return cls([[0] * n_cols for i in range(n_rows)])
@classmethod
def random(cls, shape):
M, (n_rows, n_cols) = cls(), shape
for i in range(n_rows):
M.append([random.randint(-255, 255)
for j in range(n_cols)])
return M
def transpose(self):
n_rows, n_cols = self.shape
return self.__class__(zip(*self))
@property
def shape(self):
return ((0, 0) if not self else
(int(len(self)), int(len(self[0]))))
def cy_matrix_product(X, Y):
n_xrows, n_xcols = X.shape
n_yrows, n_ycols = Y.shape
Z = Matrix.zeros((n_xrows, n_ycols))
Yt = Y.transpose()
for i, Xi in enumerate(X):
for k, Ytk in enumerate(Yt):
Z[i][k] = sum(Xi[j] * Ytk[j] for j in range(n_xcols))
return Z
X = Matrix.random(shape)
Y = Matrix.random(shape)
%timeit -n100 cy_matrix_product(X, Y)
21.4 ms ± 1.36 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)
The problem is that Cython cannot efficiently optimize work with lists that can contain elements of various types, so we rewrite matrix_product using ndarray.
X = np.random.randint(-255, 255, size=shape)
Y = np.random.randint(-255, 255, size=shape)
%%capture
%%cython -a
import numpy as np
def cy_matrix_product(X, Y):
n_xrows, n_xcols = X.shape
n_yrows, n_ycols = Y.shape
Z = np.zeros((n_xrows, n_ycols), dtype=X.dtype)
for i in range(n_xrows):
for k in range(n_ycols):
for j in range(n_xcols):
Z[i, k] += X[i, j] * Y[j, k]
return Z
%timeit -n100 cy_matrix_product(X, Y)
176 ms ± 4.65 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)
How so! It just got worse, with most of the code still using Python calls. Let's get rid of them by annotating the code with types.
%%capture
%%cython -a
import numpy as np
cimport numpy as np
def cy_matrix_product(np.ndarray X, np.ndarray Y):
cdef int n_xrows = X.shape[0]
cdef int n_xcols = X.shape[1]
cdef int n_yrows = Y.shape[0]
cdef int n_ycols = Y.shape[1]
cdef np.ndarray Z
Z = np.zeros((n_xrows, n_ycols), dtype=X.dtype)
for i in range(n_xrows):
for k in range(n_ycols):
for j in range(n_xcols):
Z[i, k] += X[i, j] * Y[j, k]
return Z
%timeit -n100 cy_matrix_product(X, Y)
173 ms ± 4 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)
Unfortunately, typical annotations did not change the run time, because the body of the nested Cython itself could not optimize. Fatality-time: indicate the type of elements in ndarray.
%%capture
%%cython -a
import numpy as np
cimport numpy as np
def cy_matrix_product(np.ndarray[np.int64_t, ndim=2] X,
np.ndarray[np.int64_t, ndim=2] Y):
cdef int n_xrows = X.shape[0]
cdef int n_xcols = X.shape[1]
cdef int n_yrows = Y.shape[0]
cdef int n_ycols = Y.shape[1]
cdef np.ndarray[np.int64_t, ndim=2] Z = \
np.zeros((n_xrows, n_ycols), dtype=np.int64)
for i in range(n_xrows):
for k in range(n_ycols):
for j in range(n_xcols):
Z[i, k] += X[i, j] * Y[j, k]
return Z
%timeit -n100 cy_matrix_product(X, Y)
541 µs ± 5.14 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Let's try to go further and disable checks for going beyond the boundaries of the array and overflow of integer types.
%%capture
%%cython -a
import numpy as np
cimport cython
cimport numpy as np
@cython.boundscheck(False)
@cython.overflowcheck(False)
def cy_matrix_product(np.ndarray[np.int64_t, ndim=2] X,
np.ndarray[np.int64_t, ndim=2] Y):
cdef int n_xrows = X.shape[0]
cdef int n_xcols = X.shape[1]
cdef int n_yrows = Y.shape[0]
cdef int n_ycols = Y.shape[1]
cdef np.ndarray[np.int64_t, ndim=2] Z = \
np.zeros((n_xrows, n_ycols), dtype=np.int64)
for i in range(n_xrows):
for k in range(n_ycols):
for j in range(n_xcols):
Z[i, k] += X[i, j] * Y[j, k]
return Z
%timeit -n100 cy_matrix_product(X, Y)
226 µs ± 2.84 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Numpy
import numpy as np
X = np.random.randint(-255, 255, shape)
Y = np.random.randint(-255, 255, shape)
%timeit -n100 X.dot(Y)
151 µs ± 4.01 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit -n100 X*Y
6.02 µs ± 1.54 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Profit.
Multithreading and GIL
|| minimum
Process
- Process - running program.
- Each process has a state isolated from other processes:
-
- virtual address space,
-
- pointer to executable instruction,
-
- call stack,
-
- system resources, such as open file descriptors.
- Processes are convenient for simultaneously performing multiple tasks.
- Alternative way: delegate each task to a thread.
Thread
- A thread is similar to a process in that its execution occurs independently of other threads (and processes).
- Unlike a process, a thread executes within a process and shares the address space and system resources with it.
- Threads are convenient for simultaneously performing several tasks that require access to a shared state.
- The joint execution of several processes and threads is controlled by the operating system, sequentially allowing each process or thread to use some processor cycles.
threading module
- A thread in Python is a system thread, that is, it is not the interpreter that controls its execution, but the operating system.
- You can create a thread using the
Threadclass from the module of the standardthreadinglibrary.
import time
from threading import Thread
def countdown(n):
for i in range(n):
print(n - i - 1, "left")
time.sleep(1)
t = Thread(target=countdown, args=(3,))
t.start()
2 left
An alternative way to create a stream is inheritance:
class CountdownThread(Thread):
def __init__(self, n):
super().__init__()
self.n = n
def run(self): # start method.
for i in range(self.n):
print(self.n - i - 1, "left")
time.sleep(1)
t = CountdownThread(3)
t.start()
2 left
The disadvantage of this approach is that it limits the reuse of code: the functionality of the CountdownThread class can be used only in a separate thread.
- When creating a stream, you can specify a name. By default it is 'Thread-N':
Thread().name
'Thread-6'
Thread(name="NumberCruncher").name
'NumberCruncher'
- Each active thread has an id - a non-negative number unique to all active threads.
t = Thread()
t.start()
t.ident
123145519448064
- The
joinmethod allows you to wait until the stream finishes. -
- The execution of the calling thread will pause until thread t ends.
-
- Repeated calls to the
joinmethod have no effect.
- Repeated calls to the
t = Thread(target=time.sleep, args=(5, ))
t.start()
t.join() # locks for 5 seconds
t.join() # performed instantly
1 left
1 left
0 left
0 left
- You can check if the thread is running using the
is_alivemethod:
t = Thread(target=time.sleep, args=(5, ))
t.start()
t.is_alive() # False after 5 seconds
True
-
A daemon is a thread created with the
daemon=Trueargument: -
The difference between a daemon thread and a regular thread is that daemon threads are automatically destroyed when exiting the interpreter.
t = Thread(target=time.sleep, args=(5,), daemon=True)
t.start()
t.daemon
True
- In Python, there is no built-in mechanism for terminating threads - this is not an accident, but an informed decision of the language developers.
- Correct termination of the flow is often associated with the release of resources, for example:
-
- a stream can work with a file whose descriptor needs to be closed,
-
- or capture a synchronization primitive.
- To end a stream, a flag is usually used:
class Task:
def __init__(self):
self._running = True
def terminate(self):
self._running = False
def run(self, n):
while self._running:
...
The set of synchronization primitives in the threading module is standard:
Lock- a regular mutex, used to provide exclusive access to a shared state.RLock- a recursive mutex that allows a thread that owns a mutex to capture the mutex more than once.Semaphore- a variation of the mutex that allows you to capture yourself no more than a fixed number of times.BoundedSemaphore- a semaphore that makes sure that it is captured and released the same number of times.
All synchronization primitives implement a single interface:
- the acquire method captures the synchronization primitive,
- and the release method releases it.
class SharedCounter:
def __init__(self, value):
self._value = value
self._lock = Lock()
def increment(self, delta=1):
self._lock.acquire()
self._value += delta
self._lock.release()
def get(self):
return self._value
queue module
The queue module implements several thread-safe queues:
Queue- FIFO queue,LifoQueue— LIFO queue of stacks,PriorityQueue— a queue of elements — a parse (priority, item).- There are no special frills in the implementation of queues: all state-changing methods work “inside” the mutex.
- The
Queueclass usesdequeas the container, and theLifoQueueandPriorityQueueclasses use the list.
def worker(q):
while True:
item = q.get() # blocking expects next
do_something(item) # element
q.task_done() # notifies the execution queue
def master(q):
for item in source():
q.put(item)
# blocking waits until all elements of the queue
# will not be processed
q.join()
futures module
- The
concurrent.futuresmodule contains the abstract classExecutorand its implementation as a thread pool -ThreadPoolExecutor. - The executor’s interface consists of only three methods:
from concurrent.futures import *
executor = ThreadPoolExecutor(max_workers=4)
executor.submit(print, "Hello, world!")
Hello, world!
<Future at 0x1043b1d90 state=running>
list(executor.map(print, ["Knock?", "Knock!"]))
Knock?
Knock!
[None, None]
executor.shutdown()
- Contractors support the context manager protocol:
with ThreadPoolExecutor(max_workers=4) as executor:
...
- The
Executor.submitmethod returns an instance of theFutureclass that encapsulates asynchronous calculations.
What can be done with Future?
with ThreadPoolExecutor(max_workers=4) as executor:
f = executor.submit(sorted, [4, 3, 1, 2])
- Ask about the calculation status:
f.running(), f.done(), f.cancelled()
(False, True, False)
- Wait for the blocking result of the calculation:
print(f.result())
[1, 2, 3, 4]
print(f.exception())
None
- Add a function that will be called after the calculation is completed:
f.add_done_callback(print)
<Future at 0x1043b7f10 state=finished returned list>
futures module example: integrate
import math
def integrate(f, a, b, *, n_iter=1000):
acc = 0
step = (b - a) / n_iter
for i in range(n_iter):
acc += f(a + i * step) * step
return acc
integrate(math.cos, 0, math.pi / 2)
1.0007851925466296
from functools import partial
def integrate_async(f, a, b, *, n_jobs, n_iter=1000):
executor = ThreadPoolExecutor(max_workers=n_jobs)
spawn = partial(executor.submit, integrate, f,
n_iter=n_iter // n_jobs)
step = (b-a)/n_jobs
fs=[spawn(a+i*step,a+(i+1)*step)
for i in range(n_jobs)]
return sum(f.result() for f in as_completed(fs))
integrate_async(math.cos, 0, math.pi / 2, n_jobs=2)
1.0007851925466305
Concurrency and Competition
Compare the performance of the serial and parallel versions of the integrate function using the “magic” timeit command:
%%timeit -n100
integrate(math.cos, 0, math.pi / 2, n_iter=10**6)
154 ms ± 2.28 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)
%%timeit -n100
integrate_async(math.cos, 0, math.pi / 2, n_iter=10**6, n_jobs=2)
142 ms ± 2.11 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)
GIL
- GIL (global interpreter lock) is a mutex that ensures that only one thread at a time has access to the internal state of the interpreter.
- The Python C API allows you to release the GIL, but it is only safe when working with objects that are not dependent on the Python interpreter.
Is GIL Bad?
- The answer depends on the task.
- The presence of GIL makes it impossible to use threads in Python for parallelism: several threads do not speed up, and sometimes even slow down the program.
- GIL does not interfere with the use of threads for competition when working with I/O.
C and Cython - GIL Remedy
%load_ext Cython
%%cython
from libc.math cimport cos
def integrate(f, double a, double b, long n_iter):
cdef double acc = 0
cdef double step=(b-a)/n_iter
cdef long i
with nogil:
for i in range(n_iter):
acc += cos(a + i * step) * step
return acc
%%timeit -n100
integrate_async(math.cos, 0, math.pi / 2, n_iter=10**6, n_jobs=2)
5.88 ms ± 126 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
multiprocessing module
Processes Another GIL Remedy
- You can use processes instead of threads.
- Each process will have its own GIL, but it will not prevent them from working in parallel.
- The
multiprocessingmodule is responsible for working with processes in Python:
import multiprocessing as mp
p = mp.Process(target=countdown, args=(5, ))
p.start()
4 left
3 left
2 left
1 left
0 left
- The module implements basic synchronization primitives: mutexes, semaphores, conditional variables.
- To organize the interaction between processes, you can use
Pipe- a socket-based connection between two processes:
def ponger(conn):
conn.send("pong")
parent_conn, child_conn = mp.Pipe()
p = mp.Process(target=ponger, args=(child_conn, ))
p.start()
parent_conn.recv()
'pong'
p.join()
Process and performance
The implementation of the integrate_async function based on the thread pool worked for a long time, let's try to use the process pool:
from concurrent.futures import ProcessPoolExecutor
def integrate_async(f, a, b, *, n_jobs, n_iter=1000):
executor = ProcessPoolExecutor(max_workers=n_jobs)
spawn = partial(executor.submit, integrate, f,
n_iter=n_iter // n_jobs)
step = (b - a) / n_jobs
fs=[spawn(a + i * step, a + (i + 1) * step)
for i in range(n_jobs)]
return sum(f.result() for f in as_completed(fs))
%%timeit -n100
integrate_async(math.cos, 0, math.pi / 2, n_iter=10**6, n_jobs=2)
16.6 ms ± 144 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
joblib package
The joblib package implements a parallel analogue of the for loop, which is convenient for parallel execution of independent tasks.
from joblib import Parallel, delayed
def integrate_async(f, a, b, *, n_jobs, n_iter=1000, backend=None):
step = (b - a) / n_jobs
with Parallel(n_jobs=n_jobs, backend=backend) as parallel:
fs = (delayed(integrate)(f, a + i * step,
a + (i + 1) * step,
n_iter=n_iter // n_jobs)
for i in range(n_jobs))
return sum(parallel(fs))
%%timeit -n100
integrate_async(math.cos, 0, math.pi / 2, n_iter=10**6, n_jobs=2, backend="threading")
104 ms ± 280 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%%timeit -n100
integrate_async(math.cos, 0, math.pi / 2, n_iter=10**6, n_jobs=2, backend="multiprocessing")
290 ms ± 1.13 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)
Summary
- GIL is a global mutex that limits the use of threads for parallelism in programs in Python.
- For programs that use mainly I / O, GIL is not scary: in CPython, these operations release the GIL.
- For programs that need parallelism, there are options for increasing productivity:
-
- write critical functionality in C or Cython;
-
- or use the multiprocessing module.
numba JIT compiler
import math
from numba import jit, prange
@jit(nopython=True, parallel=True, fastmath=True, cache=True)
def integrate(a, b, *, n_iter=1000):
acc = 0
step = (b - a) / n_iter
for i in prange(n_iter):
acc += math.cos(a + i * step) * step
return acc
%%timeit -n100
integrate(0, math.pi / 2, n_iter=10**6)
5.11 ms ± 983 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Profit.
Async python
Нам предстоит погрузиться в мир асинхронного программирования. Сейчас уже сложно представить Python без асинхронного подхода — он только набирает популярность среди веб-разработчиков.
Итераторы
Разработчики используют итераторы в коде настолько часто, что даже не задумываются, в чём они помогают. Итераторы в Python — это списки, словари, множества, строки, файлы и другие коллекции. Везде, где вы пишете цикл for, используется итератор. Итераторы помогают перемещаться по объектам любого контейнера в коде. При этом вам не нужно задумываться о том, как хранятся и обрабатываются эти элементы: итератор инкапсулирует их. Проще говоря, это способ вычитывать элементы из объекта по одному.
Перейдём сразу к практике. Представим, что на собеседовании вас попросили реализовать аналог функции range.
class Range:
def __init__(self, stop_value: int):
self.current = -1
self.stop_value = stop_value - 1
def __iter__(self):
return RangeIterator(self)
class RangeIterator:
def __init__(self, container):
self.container = container
def __next__(self):
if self.container.current < self.container.stop_value:
self.container.current += 1
return self.container.current
raise StopIteration
Получили первую версию работающего кода. Запустим код и убедимся в этом.
_range = Range(5)
for i in _range:
print(i)
0
1
2
3
4
«А как это работает? Расскажите подробнее»
Начнём с класса Range. У него внутри реализован магический метод __iter__. Он обозначает, что объект этого класса итерабельный, то есть с ним можно работать в цикле for. Ещё говорят, что __iter__ отдаёт итерируемый объект.
Ограничимся понятиями итератора и итерабельного объекта. Чтобы код действительно отдавал новые данные из range, нужно реализовать соответствующую функцию. Она как раз и называется итератор. RangeIterator — итератор для класса range. Любой итератор должен реализовывать магическую функцию __next__, в которой он должен отдавать новые значения для объектов класса Range. Если вы дошли до конца множества значений, то появляется исключение StopIteration.
Для тех, кто привык читать первоисточники, существует PEP-234 (на английском). Там подробно изложена работа итераторов и итерабельных объектов.
Но можно ли как-то упростить написанный выше код? Да, можно.
class Range2:
def __init__(self, stop_value: int):
self.current = -1
self.stop_value = stop_value - 1
def __iter__(self):
return self
def __next__(self):
if self.current < self.stop_value:
self.current += 1
return self.current
raise StopIteration
В Python есть возможность объявить объекты класса и итерабельными, и итераторами. Это удобно, но с точки зрения принципов проектирования приложения, у такого объекта есть две ответственности: он является итератором и при этом выполняет какую-то свою логику. В мире Python это допустимо, но в некоторых других языках вас могут понять неправильно. Будьте бдительны!
Ещё стоит рассмотреть, как работает цикл for под капотом.
iterable = Range2(5)
iterator = iter(iterable)
while True:
try:
value = next(iterator)
print(value)
except StopIteration:
break
0
1
2
3
4
Генераторы
Работа генераторов построена на принципе запоминания контекста выполнения функции. Если не вдаваться в подробности работы Python-интерпретатора, то функция-генератор «запоминает», на каком месте она остановилась, и может продолжить своё выполнение после ключевого слова yield.
Рассмотрим простой пример.
def simple_generator():
yield 1
yield 2
return 3
Посмотрим, что будет, если вызвать такой код:
gen = simple_generator()
print(next(gen))
print(next(gen))
print(next(gen))
1
2
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
Cell In[7], line 4
2 print(next(gen))
3 print(next(gen))
----> 4 print(next(gen))
StopIteration: 3
То есть функция действительно запоминает, где она остановилась после каждого вызова функции next.
Генераторы удобны и для создания генераторных выражений — generator expressions. Особенно это полезно, если нужно сгенерировать много объектов, а память расходовать жалко. Код выглядит так:
gen_exp = (x for x in range(100000))
print(gen_exp)
<generator object <genexpr> at 0x7dbe33f1dfc0>
Есть ещё небольшой синтаксический сахар, связанный с генераторами. Представим функцию, внутри которой есть цикл по элементам списка, и они выводятся один за другим.
numbers = [1, 2, 3]
def func():
for item in numbers:
yield item
for item in func():
print(item)
1
2
3
За счёт генератора конструкция сокращается до такой:
def func():
yield from numbers
Бывает очень полезно, но на практике используется довольно редко.
Корутины
Затронем тему корутин — основных строительных блоков асинхронного программирования на Python. Они появились в ответ на невозможность использования полноценного распараллеливания программы с помощью тредов (потоков) из-за работы GIL. Для тех, кому интересно узнать подробнее про Global Interpreter Lock, есть хорошая обзорная статья.
Корутина — это генератор. Однако в PEP-342 предложили расширить возможности генераторов, добавив туда несколько конструкций, о которых сейчас пойдёт речь.
Представьте себе метод, который на вход получает какое-то значение, как-то его обрабатывает и отдаёт результат. Пусть это будет функция, рассчитывающая количество денег на вашем счете через $N$ лет при определённом проценте. На вход функция принимает процент по депозиту в годовых и сумму на счёте.
import math
def cash_return(deposit: int, percent: float, years: int) -> float:
value = math.pow(1 + percent / 100, years)
return round(deposit * value, 2)
Теперь узнаем, сколько вы получите денег через $5$ лет, если сумма на депозите — $1 000 000$ рублей, а ставка по депозиту — $5%%$ годовых.
cash_return(1_000_000, 5, 5)
1276281.56
Теперь вы хотите посмотреть на то, как будет меняться итоговая сумма в зависимости от депозита. Тут приходит на помощь корутина.
import math
def cash_return_coro(percent: float, years: int) -> float:
value = math.pow(1 + percent / 100, years)
while True:
try:
deposit = (yield)
yield round(deposit * value, 2)
except GeneratorExit:
print('Выход из корутины')
raise
Запустим корутину с теми же условиями — $5$ лет и $5%%$ годовых.
coro = cash_return_coro(5, 5)
next(coro)
values = [1000, 2000, 5000, 10000, 100000]
for item in values:
print(coro.send(item))
next(coro)
coro.close()
1276.28
2552.56
6381.41
12762.82
127628.16
Выход из корутины
Разберёмся, что произошло. В коде видно четыре новых конструкции: (yield), send(...), close() и GeneratorExit. Корутины могут не только отдавать значения и запоминать место, где остановился код, но и ждать новых значений. Для этого ввели конструкцию (yield), которая позволяет принимать набор параметров. Так как приём параметров в корутине происходит необычным способом, то и отправка параметров сделана с помощью специальной функции send(...), через которую можно передать в функцию необходимые параметры. В конце ещё можно вызвать метод close(), который прекратит выполнение корутины. Когда вы вызываете метод close(), выбрасывается исключение GeneratorExit, которое можно перехватить и грамотно обработать.
Ещё одно преимущество — возможность запомнить контекст выполнения. В функции cash_return_coro нет необходимости вычислять переменную value каждый раз, когда вы хотите посчитать сумму. Недостатком такого подхода можно назвать большее количество кода, который надо написать, чтобы всё могло грамотно работать.
Асинхронное программирование
Асинхронное программирование в мире Python-разработки на пике популярности. Про него пишут статьи и делают доклады на конференциях. Концепция уже прижилась и во многих других популярных языках. Давайте восполним пробелы и погрузимся в работу с асинхронным кодом на Python.
Работа с разными типами задач
Раньше разработчики не сильно заостряли своё внимание на типе выполняемых задач внутри приложения — это было не нужно для индустрии в целом. Все писали достаточно большие монолитные приложения, а проблемы с производительностью обычно решались на уровне горизонтального масштабирования: через потоки, процессы или даже через несколько приложений на разных виртуальных машинах.
Сейчас использование только процессов и потоков не даёт нужной производительности. Рассмотрим три основных типа задач, с которыми сталкивается большинство разработчиков:
-
CPU bound-задачи. Задачи, для которых необходимо интенсивное использование процессора. К ним относят использование сложных математических моделей, обучение нейронных сетей, рендеринг графики и вычисление хэшей.
-
I/O bound-задачи (non-RAM I/O bound). Задачи, в которых основная часть работы приходится на ввод/вывод информации I/O или input/output. В основном такие задачи относятся к работе с файловой системой и с сетью.
-
Memory bound-задачи (RAM I/O bound). Задачи, в которых происходит интенсивная работа с оперативной памятью. Как правило, такие задачи появляются в сложных математических моделях. Из-за медленной работы с оперативной памятью всё больше моделей обрабатывают с помощью видеокарт, в которых работа с памятью устроена по-другому. Другой пример — обработка огромного объёма данных в Map-Reduce-системах, например, таких как Spark. Обработка будет идти быстрее, если оперативной памяти будет больше.
Подробнее об этом можно прочитать в англоязычных статьях: - о значении терминов CPU bound и I/O bound, - о производительности.
Из-за массового перехода на микросервисы количество сетевого взаимодействия между системами многократно возросло, как и нагрузка на базы данных. Проблемы работы с сетью или с доступом к БД относятся к I/O bound-задачам. То есть их основная работа — ожидание обработки запроса к внешней системе. Такой класс задач в монолитных системах решался пулом потоков — thread pool. Однако, его стало не хватать из-за достаточно интенсивной нагрузки на сеть между множеством сервисов.
Классический метод решения I/O bound задач — добавление ресурсов к существующим системам. Однако, многие компании не могут позволить себе «заливать всё железом» — докупать новые железные серверы, вместо оптимизации кода. Например, Instagram может себе такое позволить, поэтому они до сих пор используют Django даже с учётом всей нагрузки.
Перейдём к практике. Представьте приложение, которое ходит на некий сайт-агрегатор, достаёт данные по фильмам и сохраняет в БД. Код будет выглядеть так (ссылка на сайт выдуманная):
import requests
def do_some_logic(data):
pass
def save_to_database(data):
pass
data = requests.get('https://data.aggregator.com/films')
processed_data = do_some_logic(data)
save_to_database(data)
Этот код достаточно линейный. Если вместо загрузки фильмов в БД такой код будет выполнять отдачу данных о фильмах с этого же сайта, то при достаточной нагрузке приложение начнёт сильно проседать по скорости ответа клиентам. При этом бо́льшую часть времени код будет просто ждать запроса от клиента, делать запрос к сайту https://data.aggregator.com/films и отдавать данные. То есть в эти моменты интерпретатор не будет делать никаких полезных действий, а клиенты будут ждать.
Схематично изобразить выполнение программы можно вот так:
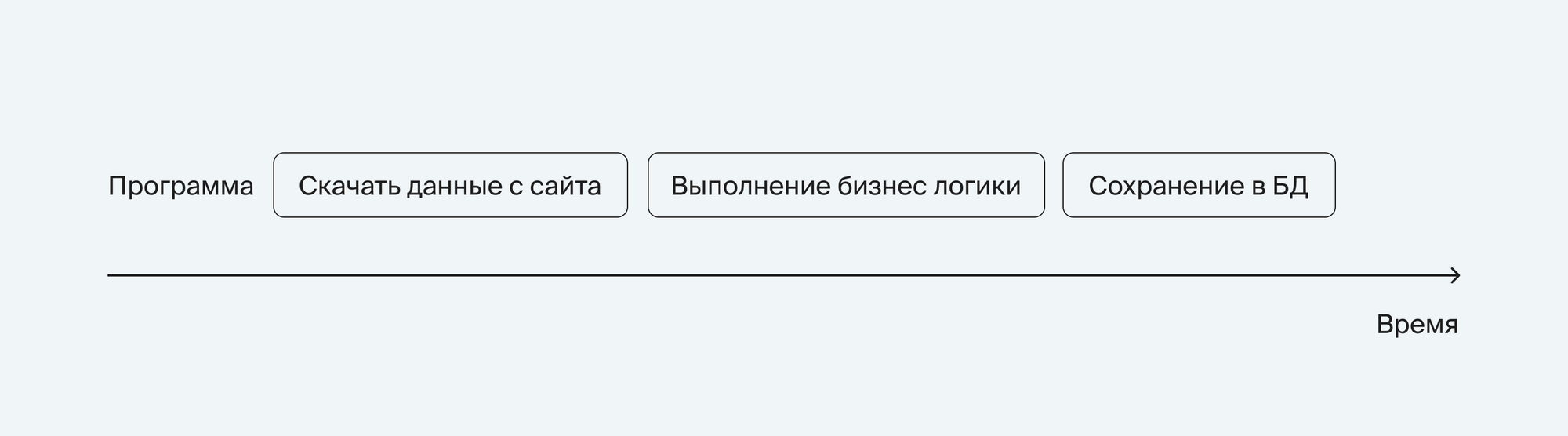
Теперь определим тип задачи в каждой ячейке:
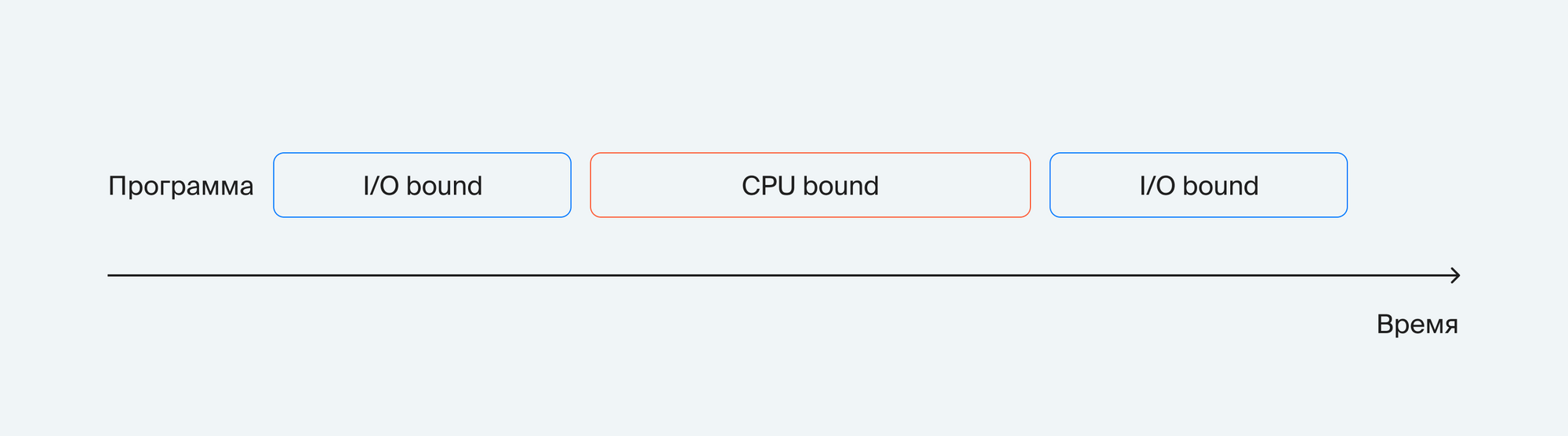
Интуитивно выполнение программы кажется примерно таким, как указано на картинке выше.
Однако, если привести картинку в соответствие с реальностью, получим следующий результат:
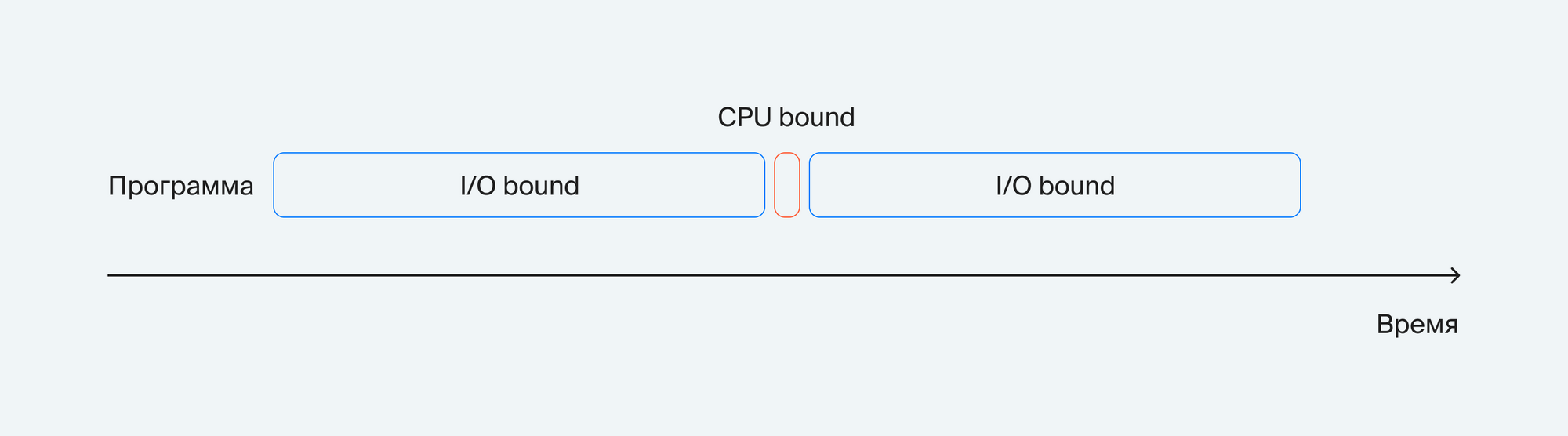
То есть бо́льшую часть времени программа ждёт ввода/вывода, а меньшая часть времени отводится на выполнение полезной работы.
Эту проблему можно решить, распараллелив код на процессы и потоки. Такой вариант поможет, но на короткое время — при таком подходе сильно увеличатся расходы ресурсов сервера. Плюс количество допустимых процессов и потоков ограничено. То есть либо закончится оперативная память под потоки, либо закончатся ядра под процессы. Вишенкой на торте становится GIL, который даёт работать только одному потоку в единицу времени. Это не позволяет эффективно использовать массовый параллелизм на потоках и добавляет свои накладные расходы, хоть и не очень заметные.
Посмотрим, как применение потоков сказывается на выполнении программы:
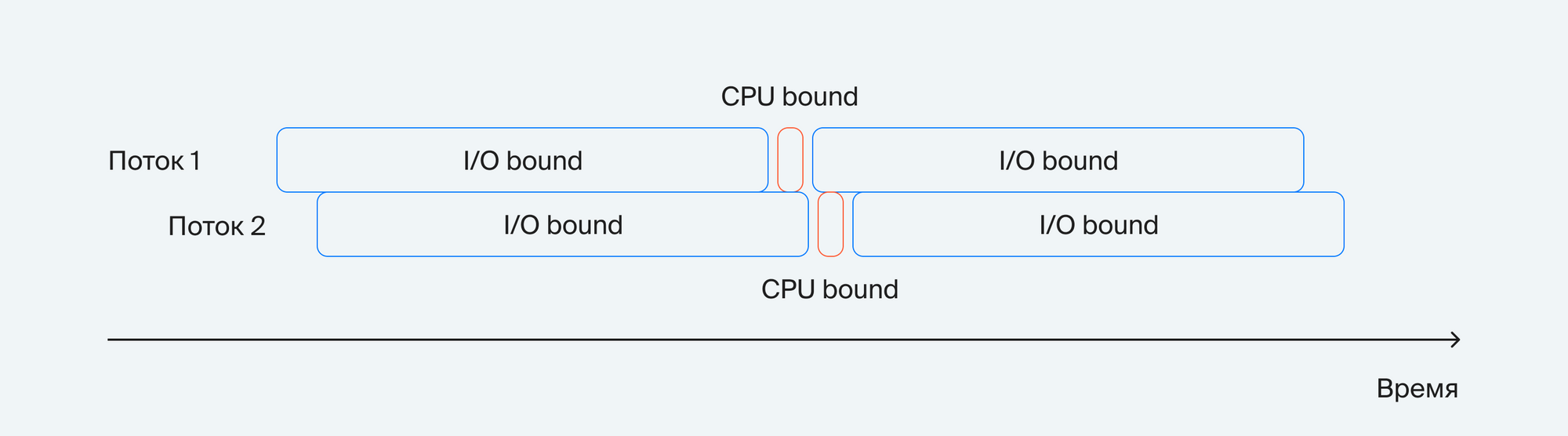
Действительно, два потока почти в два раза лучше отрабатывают I/O bound задачи. Но к сожалению, при таком подходе очень просто ошибиться и столкнуться с проблемой «состояния гонок». Можно попробовать вариант с корутинами, но его сложнее реализовать. И при таком способе не получится создать много потоков, так как они потребляют гораздо больше ОЗУ, чем корутины. Также написание многопоточного кода требует от разработчика большей внимательности, чем при написании линейного.
Стоит внимательнее присмотреться к проблеме. Всё ещё бо́льшую часть времени интерпретатор не совершает активных действий, а только ждёт ответа от ОС, завершилась ли та или иная операция ввода/вывода. В целом процессы и потоки не сильно помогут, ведь интерпретатор будет по-прежнему простаивать на каждом из них. При этом появится много накладных расходов на переключение контекста между процессами или на потребление оперативной памяти потоками, что может только ухудшить положение.
Все эти проблемы необходимо решать эффективно. С этим может помочь использование асинхронного кода.
Event-loop
Итак, вы добрались до сердца асинхронных программ в Python — цикла событий. Чтобы понять, как он работает, обратимся к простой реализации, которую предложил Девид Бизли (David Beazley) в 2009 году. Она хороша тем, что не содержит сложных конструкций, которыми сейчас обросли популярные реализации цикла событий на Python. Эта часть будет построена на разборе кода и практик, которые применяются для разработки цикла событий на основе кода Бизли, и как учитывать эти знания при разработке асинхронных приложений на Python. Код уже приведён к современной версии Python.
Начнём с архитектуры цикла событий.
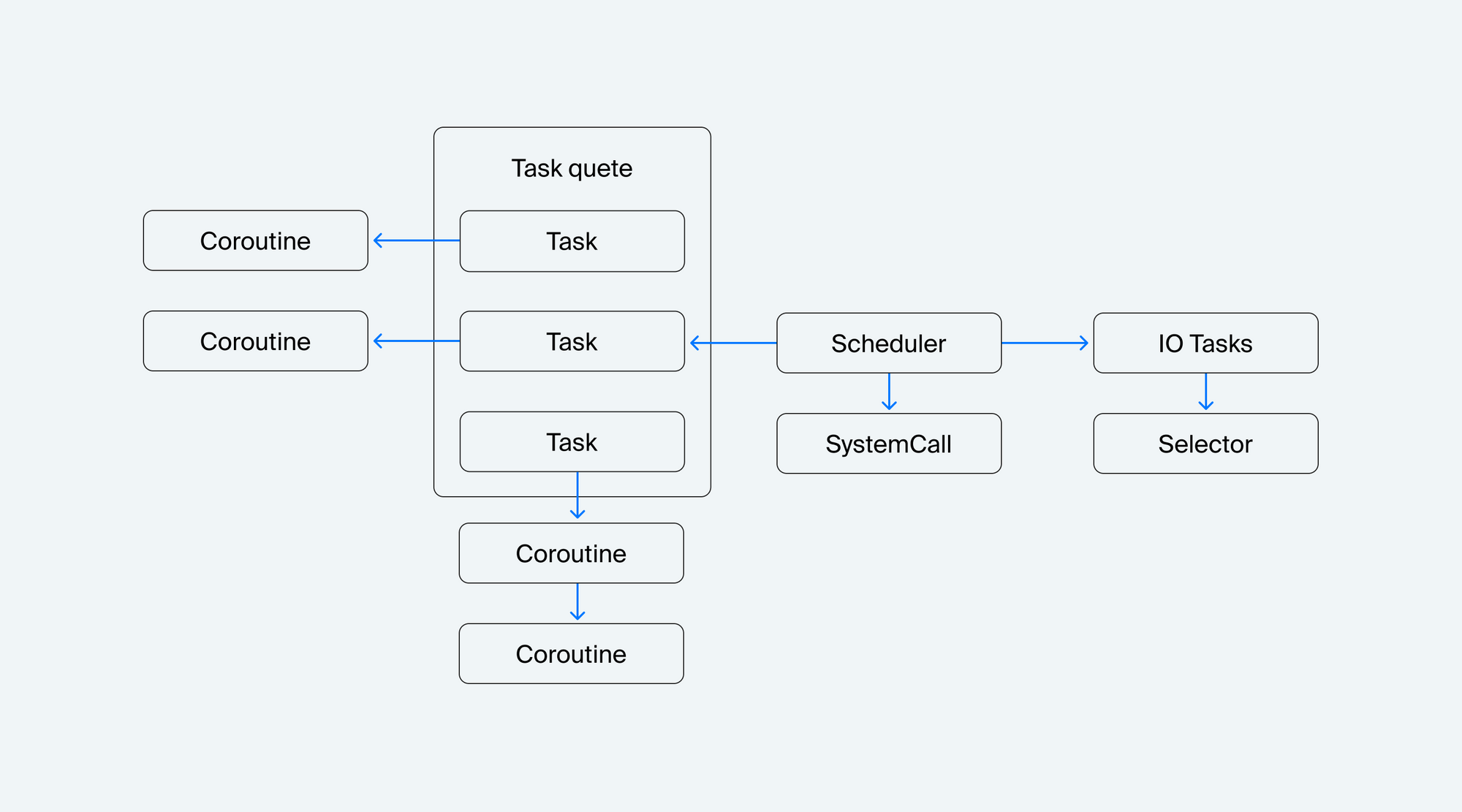
Расмотрим блоки:
- Планировщик (Scheduler). Корень всей программы. Обрабатывает задачи в очереди задач и следит за их правильным переключением между собой.
- Очередь задач (Task queue). Здесь собираются новые задачи на исполнение.
- Задача (Task). Основной блок работы цикла событий. В задачах хранится информация о выполняемой корутине. Умеет обрабатывать цепочку вложенных корутин.
- Корутина (Coroutine). Исполняемый код, которым оперирует планировщик задач.
- Системный вызов (SystemCall). Блоки кода, которые расширяют функциональность планировщика.
- Корутина для выполнения работы с I/O (I/O-tasks). В планировщик добавляется специальная задача (Task) для обработки I/O-событий от ОС.
- Селектор (Selector). Он слушает события от ОС и передаёт работу корутинам, которые ждут обработки I/O-сообщений.
Первым стоит рассмотреть работу планировщика. Его основные функции — приём и справедливая обработка списка задач.
import logging
from typing import Generator
from queue import Queue
class Scheduler:
def __init__(self):
self.ready = Queue()
self.task_map = {}
def add_task(self, coroutine: Generator) -> int:
new_task = Task(coroutine)
self.task_map[new_task.tid] = new_task
self.schedule(new_task)
return new_task.tid
def exit(self, task: Task):
del self.task_map[task.tid]
def schedule(self, task: Task):
self.ready.put(task)
def _run_once(self):
task = self.ready.get()
try:
result = task.run()
except StopIteration:
self.exit(task)
return
self.schedule(task)
def event_loop(self):
while self.task_map:
self._run_once()
Вся работа происходит в функции event_loop(), которая просто достаёт задачи одну за другой. В функции _run_once() идёт обработка итерации цикла событий, в которой поочерёдно берутся и запускаются задачи для обработки. Если задача не завершилась, то она ставится заново в очередь задач self.ready. Выполненные задачи нужно убрать из планировщика функцией exit().
Для добавления задачи используйте функцию add_task(). Она принимает корутину для выполнения и создаёт с ней задачу в планировщике. Чтобы поставить задачу напрямую в планировщик, необходимо вызвать функцию schedule().
Далее разберёмся с устройством задачи.
import types
from typing import Generator, Union
class Task:
task_id = 0
def __init__(self, target: Generator):
Task.task_id += 1
self.tid = Task.task_id # Task ID
self.target = target # Target coroutine
self.sendval = None # Value to send
self.stack = [] # Call stack
# Run a task until it hits the next yield statement
def run(self):
while True:
try:
result = self.target.send(self.sendval)
if isinstance(result, types.GeneratorType):
self.stack.append(self.target)
self.sendval = None
self.target = result
else:
if not self.stack:
return
self.sendval = result
self.target = self.stack.pop()
except StopIteration:
if not self.stack:
raise
self.sendval = None
self.target = self.stack.pop()
Сама по себе задача — обёртка над корутиной. У каждой задачи есть свой id, который учитывается в планировщике в словаре task_map. На его заполненность смотрит планировщик при выполнении задач.
Другая особенность задач — возможность выполнения корутин методом run(). Давайте посмотрим, как они выполняются в рамках задачи. Предположим, что есть корутина, которая вызывает другую корутину, а та — третью. Например, вот такой код:
def double(x):
yield x * x
def add(x, y):
yield from double(x + y)
def main():
result = yield add(1, 2)
print(result)
yield
Код является небольшой модификацией кода Бизли из его выступления. Теперь попробуем выполнить эту цепочку корутин в рамках Task.
task = Task(main())
task.run()
9
Таким же образом будут выполняться и остальные корутины в рамках планировщика. Осталось только расширить планировщик для работы с I/O-операциями.
В рамках планировщика добавляем специальную бесконечную задачу io_task перед стартом цикла событий. Эта функция имеет бесконечный цикл внутри и передаёт управление планировщику после вызова выполненных событий из селектора.
import logging
from typing import Generator, Union
from queue import Queue
from selectors import DefaultSelector, EVENT_READ, EVENT_WRITE
logger = logging.getLogger(__name__)
class Scheduler:
def __init__(self):
self.ready = Queue()
self.selector = DefaultSelector()
self.task_map = {}
def add_task(self, coroutine: Generator) -> int:
new_task = Task(coroutine)
self.task_map[new_task.tid] = new_task
self.schedule(new_task)
return new_task.tid
def exit(self, task: Task):
logger.info('Task %d terminated', task.tid)
del self.task_map[task.tid]
# I/O waiting
def wait_for_read(self, task: Task, fd: int):
try:
key = self.selector.get_key(fd)
except KeyError:
self.selector.register(fd, EVENT_READ, (task, None))
else:
mask, (reader, writer) = key.events, key.data
self.selector.modify(fd, mask | EVENT_READ, (task, writer))
def wait_for_write(self, task: Task, fd: int):
try:
key = self.selector.get_key(fd)
except KeyError:
self.selector.register(fd, EVENT_WRITE, (None, task))
else:
mask, (reader, writer) = key.events, key.data
self.selector.modify(fd, mask | EVENT_WRITE, (reader, task))
def _remove_reader(self, fd: int):
try:
key = self.selector.get_key(fd)
except KeyError:
pass
else:
mask, (reader, writer) = key.events, key.data
mask &= ~EVENT_READ
if not mask:
self.selector.unregister(fd)
else:
self.selector.modify(fd, mask, (None, writer))
def _remove_writer(self, fd: int):
try:
key = self.selector.get_key(fd)
except KeyError:
pass
else:
mask, (reader, writer) = key.events, key.data
mask &= ~EVENT_WRITE
if not mask:
self.selector.unregister(fd)
else:
self.selector.modify(fd, mask, (reader, None))
def io_poll(self, timeout: Union[None, float]):
events = self.selector.select(timeout)
for key, mask in events:
fileobj, (reader, writer) = key.fileobj, key.data
if mask & EVENT_READ and reader is not None:
self.schedule(reader)
self._remove_reader(fileobj)
if mask & EVENT_WRITE and writer is not None:
self.schedule(writer)
self._remove_writer(fileobj)
def io_task(self) -> Generator:
while True:
if self.ready.empty():
self.io_poll(None)
else:
self.io_poll(0)
yield
def schedule(self, task: Task):
self.ready.put(task)
def _run_once(self):
task = self.ready.get()
try:
result = task.run()
except StopIteration:
self.exit(task)
return
self.schedule(task)
def event_loop(self):
self.add_task(self.io_task())
while self.task_map:
self._run_once()
Код значительно разросся, но на самом деле ничего страшного не произошло. Рассмотрим изменения в порядке вызовов. В рамках планировщика добавляем специальную бесконечную задачу io_task перед стартом цикла событий. Эта функция имеет бесконечный цикл внутри и передаёт управление планировщику после вызова выполненных событий из селектора.
Рассмотрим подробнее устройство io_task. Если очередь задач пустая, то timeout для ожидания событий из селектора ставится в режим «до тех пор, пока не будет новых событий». В остальных случаях ставим таймаут 0, чтобы получить все события от ОС сразу же. Такую особенность работы этого метода рассмотрим чуть позже.
Если из селектора пришли новые события, то обрабатываем их и убираем из обработки файловые дескрипторы. Важный момент — хранение данных о задачах в селекторе. Одна и та же задача может ожидать чтения данных и пытаться записать новые данные. Именно поэтому в поле data хранится кортеж (reader, writer).
По сути, event_loop должен предоставлять интерфейс для работы с сокетами. Таких метода всего четыре:
wait_for_read,wait_for_write,_remove_reader,_remove_writer.
Эти методы позволяют работать с циклом событий, встроенным в ОС.
Работа с I/O для цикла событий — «пристройка сбоку» для обработки сетевых запросов. То есть основное назначение цикла событий в Python — обработка функций корутин, которые могут никуда не ходить по сети, а работать только с файловой системой.
Осталось разобраться с конструкцией SystemCall. Так как изначально цикл событий больше напоминает работу ОС, должен быть механизм прерываний, чтобы передать управление ОС. В асинхронном коде прерывание обеспечивается с помощью yield. После переключения контекста может вызываться системная функция для исполнения. Например, для создания новых задач можно использовать вот такой код:
class SystemCall:
def handle(self, sched: Scheduler, task: Task):
pass
class NewTask(SystemCall):
def __init__(self, target: Generator):
self.target = target
def handle(self, sched: Scheduler, task: Task):
tid = sched.add_task(self.target)
task.sendval = tid
sched.schedule(task)
В Scheduler достаточно добавить небольшой фрагмент кода:
class Scheduler:
...
def _run_once(self):
task = self.ready.get()
try:
result = task.run()
if isinstance(result, SystemCall):
result.handle(self, task)
return
except StopIteration:
self.exit(task)
return
self.schedule(task)
А в Task добавляем небольшое условие при выполнении корутин:
import types
from typing import Generator, Union
class Task:
...
def run(self):
while True:
try:
result = self.target.send(self.sendval)
if isinstance(result, SystemCall):
return result
...
Что всё это значит? Разберёмся на примере NewTask. Этот класс предоставляет интерфейс для создания новых задач в цикле событий. Такой интерфейс позволяет абстрагировать клиентский код. Это эмуляция защищённой среды ОС, когда последняя предоставляет безопасные методы для работы с ядром. Такие методы не дают клиентскому коду мешать другим программам в ОС. Таким же образом можно сделать KillTask или WaitTask.
Осталась последняя проблема — блокирующие операции. Из-за них код не может асинхронно обрабатывать события и цикл событий ждёт выполнения на каждой функции. Есть вариант решения проблемы:
- Сделать неблокирующими сокеты через
socket.setblocking(False).
Asyncio
Теперь у нас достаточно знаний, чтобы без труда освоить основную встроенную библиотеку для асинхронного программирования — asyncio.
С версии Python 3.5 в язык добавили специальный синтаксис — async/await. Он позволяет использовать «нативные» корутины, которые теперь являются частью языка. Они разделяют генераторы от асинхронного кода, что позволяет создавать асинхронные генераторы и ускорять работу асинхронного кода.
Посмотрим, как выглядит простая программа с использованием async/await.
import random
import asyncio
async def func():
r = random.random()
await asyncio.sleep(r)
return r
async def value():
result = await func()
print(result)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(value())
loop.close()
В целом изменений немного. Переменная loop — это не что иное, как планировщик задач. Он работает по схожим принципам с тем, что рассматривался ранее. Теперь все функции переключаются с помощью await.
Познакомимся с основными функциями asyncio, которые часто встречаются на практике:
gather— выполняет список корутин одновременно и дожидается результата выполнения всех корутин.sleep— заставляет корутину уснуть на определённое количество секунд.wait/wait_for— удобные функции, чтобы дождаться выполнения уже запущенной корутины.
Также стоит ознакомиться с основными функциями event_loop:
get_event_loop— получить новый объектevent_loopили тот, что уже существует. При этом одновременно может существовать только один объектevent_loop.run_until_complete/run— удобные функции для запуска и проверки асинхронных функций.shutdown_asyncgens— одна из самых недооценённых функций цикла событий, которая позволяет правильно завершить выполнение цикла событий и всех корутин.call_soon— позволяет запланировать выполнение корутины, но не ждать её выполнения. Таким образом можно вечно ставить на выполнение одну и ту же функцию.
Теперь стоит поговорить про ключевые различия между asyncio и предложенной реализацией цикла событий. Asyncio работает на функциях обратного вызова или колбэках (callback). Этот механизм запускает задачи «честнее», чем текущий планировщик. Каждая корутина по-честному ставится в очередь и исполняется. В простом планировщике переключения не произойдёт, пока вся цепочка корутин не выполнится, что блокирует выполнение остальных задач. Однако, у колбэков есть и свой недостаток — callback hell. Это состояние, когда после вызова каждой функции нужно вызвать ещё одну функцию и ещё одну функцию... Получаются интересные фрагменты кода:
func1.add_callback(
func2.add_callback(
func3.add_callback(func4)
)
)
К счастью, этого удаётся избежать через синтаксис async/await.
await func4()
await func3()
await func2()
await func1()
Такое поведение возможно благодаря введению класса Future. По сути, такие объекты спасают от колбэков и делают код более линейным. В современных версиях Python Future-объекты для нативных корутин не нужны.
Коды и скрипты
Уравнение огибающей Капчинского-Владимирского для пучка заряженных частиц
Сначала разберем теорию, а затем расчитаем огибающую электронного пучка в линейном ускорителе с помощью Python.
Уравнения Максвелла
Объемная плотность тока пучка \(\jmath = \rho\upsilon\), где \(\rho\) - объемная плотность заряда, \(\upsilon\) - скорость пучка. Запишем дифференциальные уравнения Максвелла: $$ \nabla \vec{D} = 4\pi\rho, $$ $$ \nabla\times \vec{H} = \frac{4\pi\vec{\jmath}}{c}, $$ где \(\vec{D}\) - индукция электрического поля, \(\vec{H}\) - напряженность магнитного поля, \(с\) - скорость света. Используем теорему Стокса об интегрировании дифференциальных форм, чтобы получить уравнения Максвелла в интегральной форме: $$ \oint\limits_{\eth V} \vec{D}\vec{dS} = 4\pi\int\limits_V\rho{dV}, $$ $$ \oint\limits_{\eth S} \vec{H}\vec{dl} = \frac{4\pi}{c}\int\limits_S\vec{\jmath}\vec{dS}. $$
Найдем \(D_r\) для цилиндрического пучка радиуса \(a\) с постоянной плотностью \(\rho_0\): $$ D_r = \frac{4\pi}{r}\int\limits^r_0\rho(\xi)\xi d\xi = \begin{equation*} \begin{cases} \displaystyle 2\pi\rho_0 r, r < a, \ \displaystyle \frac{2\pi\rho_0 a^2}{r}, r > a. \end{cases} \end{equation*} $$
Учитывая, что в вакууме \(D = E\), \(H = B\), \(E\) - напряженность электрического поля, \(B\) - индукция магнитного поля, и в плоском пространстве в декартовой системе координат \(H_\alpha = \beta D_r\), где \(\displaystyle\beta = \frac{\upsilon}{c}\), радиальная компонента силы \(F_r\) из силы Лоренца \(\vec{F} = e\vec{E} + \displaystyle\frac{e}{c}\vec{\upsilon}\times\vec{B}\) : $$ F_r = eE_r - \frac{e\upsilon_z B_\alpha}{c} = eE_r(1-\displaystyle \frac{\upsilon^2}{c^2}) = \displaystyle \frac{eE_r}{\gamma^2}. $$ Полезно выразить поле через ток $$ I = \rho_0\upsilon\pi a^2, $$ тогда: $$ E_r = \begin{equation*} \begin{cases} \displaystyle \frac{2 I r}{a^2\upsilon}, r < a, \ \displaystyle \frac{2 I}{r\upsilon}, r > a. \end{cases} \end{equation*} $$
Уравнения движения
Второй закон Ньютона \(\dot p_r = F_r\), используем параксиальное приближение и считаем \(\gamma = const\): $$ \gamma m \ddot r = \displaystyle \frac{eE_r}{\gamma^2} = \displaystyle \frac{2 I e}{\gamma^2 a^2 \upsilon} r, $$ получилось линейное уравнение, но так как все частицы движутся нужно учесть, что \(a = a(t)\). Решение линейного уравнения можно представить как линейное преобразование фазовой плоскости. Так как отрезок на фазовой плоскости при невырожденном линейном преобразовании переходит в отрезок, то его можно охарактеризовать одной точкой. Следовательно, выберем крайнюю точку \(r = a\), которая будет характеризовать крайнюю траекторию: $$ \gamma m \ddot r = \displaystyle \frac{2 I e}{\gamma^2 a \upsilon}. $$ Перейдем к дифференцированию по \(z\), учтем, что \(\displaystyle dt = \frac{dz}{v}\), тогда: $$ a'' = \displaystyle \frac{e}{a}\frac{2I}{m\gamma^3\upsilon^3}. $$ Введем характерный альфвеновский ток \(I_a = \displaystyle \frac{mc^3}{e} \approx\) 17 kA, следовательно: $$ a'' = \displaystyle \frac{2I}{I_a (\beta\gamma)^3} \frac{1}{a}. $$ Учтем внешнюю фокусировку, предполагая суперпозицию полей (верно не всегда, например, в нелинейных средах это не выполняется), получим: $$ a'' + k(z)a - \displaystyle \frac{2I}{I_a (\beta\gamma)^3} \frac{1}{a} = 0, $$ что напоминает уравнение огибающей: $$ w'' + kw - \displaystyle \frac{1}{w^3} = 0 ,$$ где \( w =\displaystyle \sqrt \beta .\)
Уравнения огибающей для эллиптического пучка с распределением Капчинского-Владимирского с внешней фокусировкой линейными полями
Распределение Капчинского-Владимирского: $$ f = A\delta(1 - \displaystyle\frac{\beta_x x'^2 + 2\alpha_x x x' + \gamma_x x^2}{\epsilon_x} - \displaystyle\frac{\beta_y y'^2 + 2\alpha_y y y' + \gamma_y y^2}{\epsilon_y} ), $$ где \(А\) - инвариант Куранта-Снайдера. Полуоси эллипса: $$ a = \sqrt{\epsilon_x \beta_x}, b = \sqrt{\epsilon_y \beta_y}. $$ Поле получается линейно внутри заряженного эллиптического цилиндра: $$ E_x = \displaystyle \frac{4I}{\upsilon}\frac{x}{a(a+b)}, $$ $$ E_y = \displaystyle \frac{4I}{\upsilon}\frac{y}{b(a+b)}. $$ Проверим, что \(\nabla \vec{E} = 4\pi\rho:\) $$ \displaystyle I = \rho \upsilon \pi ab, $$ $$ \nabla \vec{E} = \displaystyle \frac{4I(a+b)}{\pi(a+b)ab} = \displaystyle \frac{4I}{\pi ab} = 4\pi\rho. $$ Так как поля линейные, они добавятся к полям фокусирующей линзы. Подставим в уравнение огибающей \(\displaystyle a = \sqrt \epsilon_x w_x, b = \sqrt \epsilon_y w_y:\) $$ a'' + k_{xt} a - \frac{\epsilon_x^2}{a^3} = 0, $$ где \(k_{xt} = k_x + k_{xsc}\) - полная жесткость, \(k_x\) - жесткость линзы, а \(\displaystyle k_{xsc} = \frac{4I}{I_a (\beta\gamma)^3}\frac{1}{a(a+b)}.\) В итоге получаем систему уравнений, связанных через пространственный заряд: $$ \begin{equation*} \begin{cases} \displaystyle a'' + k_xa - \frac{4I}{I_a (\beta\gamma)^3}\frac{1}{(a+b)} - \frac{\epsilon_x^2}{a^3} = 0 , \\ \displaystyle b'' + k_yb - \frac{4I}{I_a (\beta\gamma)^3}\frac{1}{(a+b)} - \frac{\epsilon_y^2}{b^3} = 0. \end{cases} \end{equation*} $$
Количественный критерий применимости приближения ламинарности течения
Данная система уравнений позволяет учесть 2 эффекта, мешающих сфокусировать пучок в точку - конечность эммитанса и пространственный заряд. Работают члены одинаково, поэтому можно сравнить эти величины. Когда ток \(I\) малый - слабое отталкивание, если ток \(I\) большой - сильное отталкивание, следовательно, эммитанс можно откинуть и считать течение ламинарным. Очевидно, количественный критерий применимости ламинарности течения выглядит так: $$ \displaystyle \sqrt{\frac{2I}{I_a(\beta\gamma)^3}} \gg \sqrt{\frac{\epsilon}{\beta}}. $$ Видно, что пространственный заряд влияет на огибающую больше там, где \(\beta\)-функция больше, а в вблизи фокуса влиянием пространственного заряда можно пренебречь.
Теорема Буша
В качестве дополнения к выводу уравнения огибающей пучка докажем важную вспомогательную теорему, которая называется теоремой Буша. Она связывает угловую скорость заряженной частицы, движущейся в аксиально-симметричном магнитном поле, с магнитным потоком, охваченным окружностью с центром на оси и проходящим через точку, в которой расположена частица.
Рассмотрим заряд \(q\), движущийся в магнитном поле \(\vec B = (B_r,0,B_z)\). Приравняем \(\theta\) - составляющую силы Лоренца к производной момента импульса по времени, деленной на \(r\): $$ F_\theta = -q(\ddot r B_z - \dot z B_r) = \frac{d}{rdt}(\gamma m r^2 \dot \theta). $$ Поток, пронизывающий площадь, охваченную окружностью радиуса $r$, центр которой расположен на оси, а сама она проходит через точку, в которой расположен заряд, записывается в виде \(\psi = \int\limits^r_0 2\pi r B_z dr\). Когда частица перемещается на \(\vec{dl} = (dr,dz)\), скорость изменения потока, охваченного этой окружностью, можно найти из второго уравнения Максвелла \(\nabla \vec{B} = 0.\) Таким образом, $$ \dot\psi = 2\pi r (-B_r \dot z + B_z \dot r). $$ После интегрирования по времени из приведенных уравнений получаем следующее выражение: $$ \dot \theta = (-\frac{q}{2\pi \gamma m r^2})(\psi - \psi_0). $$
Уравнение параксиального луча
Здесь мы запишем уравнение параксиального луча в виде, соответсвующем системе с аксиальнорй симметрией при принятых ранее допущениях. Чтобы вывести уравнение параксиального луча, приравняем силу радиального ускорения силам электрическим и магнитным со стороны внешних полей. Нужно помнить, что величина \(\gamma = \gamma(t).\) $$ \frac{d}{dt}(\gamma m \dot r) - \gamma m r (\dot \theta)^2 = q(E_r + r\dot \theta B_z). $$ Применим теорему Буша и независимость \(B_z\) от \(r:\) $$ -\dot \theta = \frac{q}{2\gamma m}(B_z - \frac{\psi_0}{\pi r}). $$ Исключим $\dot \theta$ и подставим $\displaystyle \dot \gamma \approx \frac {\beta q E_z }{mc}:$ $$ \ddot r + \frac{\beta q E_z}{\gamma m c} \dot r + \frac{q^2 B^2_z}{4\gamma ^2 m^2} r - \frac{ q^2 \psi^2_0}{4\pi^2\gamma^2 m^2} (\frac{1}{r^3}) - \frac{q E_r}{\gamma m } = 0. $$
Уравнение огибающей для круглого и эллиптического пучка
Учитывая, что: $$ \dot r = \beta c r', $$ $$ \ddot r = r'' (\dot z)^2 + r'\ddot z \approx r'' \beta^2 c^2 + r' \beta' \beta c^2. $$ А также, если в области пучка нет никаких зарядов, то, разлагая в ряд Тейлора в окрестности оси и оставляя только первый член, с учетом $$\nabla \vec{E} = 0$$ получаем $$ E_r = -0.5 r E'_z \approx - 0.5 r \gamma'' mc^2/q. $$ Тогда окончательно можем записать уравнение огибающей для круглого пучка радиуса \(r\) с распределением Капчинского-Владимирского с внешней фокусировкой линейными полями: $$ \displaystyle r'' + \frac{1}{\beta^2\gamma} \gamma' r' + \frac{1}{2\beta^2\gamma}\gamma''r + kr - \frac{2I}{I_a (\beta\gamma)^3}\frac{1}{r} - \frac{\epsilon^2}{r^3} = 0 ; $$ и для эллиптического пучка: $$ \begin{equation*} \begin{cases} \displaystyle a'' + \frac{1}{\beta^2\gamma} \gamma' a' + \frac{1}{2\beta^2\gamma}\gamma''a + k_xa - \frac{4I}{I_a (\beta\gamma)^3}\frac{1}{(a+b)} - \frac{\epsilon_x^2}{a^3} = 0 , \\ \displaystyle b'' + \frac{1}{\beta^2\gamma} \gamma' b' + \frac{1}{2\beta^2\gamma}\gamma''b + k_yb - \frac{4I}{I_a (\beta\gamma)^3}\frac{1}{(a+b)} - \frac{\epsilon_y^2}{b^3} = 0. \end{cases} \end{equation*} $$
Магнитные линзы
Фокусирующими элементами могут являться: соленоиды и магнитные квадрупольные линзы.
Соленоиды
\(k_x = k_y = k_s\) - жесткость соленоида: $$ k_s = \left ( \frac{eB_z}{2m_ec\beta\gamma} \right )^2 = \left ( \frac{e B_z}{2\beta\gamma\cdot 0.511\cdot 10^6 e \cdot \mathrm{volt}/c} \right )^2 = \left ( \frac{cB_z[\mathrm{T}]}{2\beta\gamma\cdot 0.511\cdot 10^6 \cdot \mathrm{volt}} \right )^2. $$
Квадруполи
\(k_q = \displaystyle\frac{eG}{pc}\) - жесткость квадруполя, где \(G = \displaystyle\frac{\partial B_x}{\partial y} = \displaystyle\frac{\partial B_y}{\partial x}\) - градиент магнитного поля, причем \(k_x = k_q, k_y = -k_q.\) $$ k_q = \left ( \frac{eG}{m_ec\beta\gamma} \right ) = \left ( \frac{eG}{\beta\gamma\cdot 0.511\cdot 10^6 e \cdot \mathrm{volt}/c} \right ) = \left ( \frac{cG}{\beta\gamma\cdot 0.511\cdot 10^6 \cdot \mathrm{volt}} \right ). $$
Продольная динамика пучка
Уравнение на продольную динамику пучка можно решить независимо от уравнения на огибающую, чтобы в уравнении на огибающую уже использовать готовую функцию энергии пучка от \(z\). Считая, что скорость электрона достаточно близка к скорости света и следовательно его продольная координата \(z \approx ct\), а импульс \(p_z \approx \gamma mc\)
$$ \frac{d\gamma}{dz} \approx \frac{eE_z}{mc^2}, $$
Тогда достаточно один раз проинтегрировать функцию \(E_z(z)\):
Решение уравнения огибающей для эллиптического пучка с фокусирующими элементами
Уравнение огибающей для эллиптического пучка с полуосями \(a, b\) с распределением Капчинского-Владимирского с внешней фокусировкой линейными полями: $$ \begin{equation*} \begin{cases} \displaystyle a'' + \frac{1}{\beta^2\gamma} \gamma' a' + \frac{1}{2\beta^2\gamma}\gamma''a + k_qa - \frac{2P}{(a+b)} - \frac{\epsilon_x^2}{a^3} = 0 , \\ \displaystyle b'' + \frac{1}{\beta^2\gamma} \gamma' b' + \frac{1}{2\beta^2\gamma}\gamma''b - k_qb - \frac{2P}{(a+b)} - \frac{\epsilon_y^2}{b^3} = 0. \end{cases} \end{equation*} $$
Пусть \(\displaystyle x = \frac{da}{dz}, y = \frac{db}{dz}, \displaystyle \frac{d\gamma }{dz}\approx \frac{e E_z}{m c^2}, k = \frac{1}{R} - \) кривизна, тогда $$ \begin{matrix} \displaystyle \frac{dx}{dz}= - \frac{1}{\beta^2\gamma} \gamma' a' - \frac{1}{2\beta^2\gamma}\gamma''a - k_qa + \frac{2P}{(a+b)} + \frac{\epsilon_x^2}{a^3}\\ \displaystyle\frac{da}{dz} = x\\ \displaystyle \frac{dy}{dz}= - \frac{1}{\beta^2\gamma} \gamma' b' - \frac{1}{2\beta^2\gamma}\gamma''b + k_qb + \frac{2P}{(a+b)} + \frac{\epsilon_x^2}{b^3}\\ \displaystyle\frac{db}{dz} = y \end{matrix}. $$ Пусть \(\vec X = \begin{bmatrix} x \\ a \\ y \\ b \end{bmatrix} \), теперь составим дифференциальное уравнение \(X' = F(X).\)
Уравнение траектории для одной частицы
Векторный потенциал в соленоиде имеет только одну компоненту и легко выражается через \(B_z(z)\): $$ A_\phi (z,r)=\sum_0^{inf} \dfrac{(-1)^n}{n!(n+1)!} B_z^{2n}(\dfrac{r}{2})^{2n+1/2}. $$ Следовательно Лагранжиан в цилиндрической системе координат имеет вид: $$ L = -mc^2(1-\beta^2)^{1/2} + \dfrac{e}{c}A_\phi r \dot\phi. $$ Из аксиальной симметрии следует существование интеграла движения: $$ P_\phi = \gamma mr^2\dot\phi + \dfrac{e}{c} r A_\phi = \gamma mr^2\dot\phi_0. $$ Продифференцировав по $z$ получим: $$ \phi' - \phi_0' = -\dfrac{e}{pc}\dfrac{A_\phi}{r}. $$ И в параксиальном приближении: $$ \phi' - \phi_0' = -\dfrac{e}{pc}B_z(z). $$ Откуда: $$ \delta \phi = \int\dfrac{e}{2pc}B_z(z)dz. $$ Тогда и уравнения траектории в приведенных координатах выглядят так: $$ \begin{equation*} \begin{cases} \displaystyle \tilde x'' + \frac{1}{\beta^2\gamma} \gamma'\tilde x' + \frac{1}{2\beta^2\gamma}\gamma''\tilde x + k_s \tilde x = 0 , \\ \displaystyle \tilde y'' + \frac{1}{\beta^2\gamma} \gamma'\tilde y' + \frac{1}{2\beta^2\gamma}\gamma''\tilde y +k_s \tilde y = 0, \end{cases} \end{equation*} $$
Расчет в Python
Сначала подключим необходимые библиотеки и настроим параметры графики
import numpy as np
import holoviews as hv
hv.extension('matplotlib')
%output size=200 backend='matplotlib' fig='svg'
%opts Curve Scatter Area [fontsize={'title':14, 'xlabel':14, 'ylabel':14, 'ticks':14, 'legend': 14}]
%opts Area Curve [aspect=3 show_grid=True]
%opts Area (linewidth=1 alpha=0.25)
%opts Curve (linewidth=2 alpha=0.5)
import warnings
warnings.filterwarnings('ignore')


Настроим область и шаг счета
dz = 0.005 # m
z_min = 0.7
z_max = 15
z = np.arange(z_min,z_max,dz) # m
Определим элемент ускорителя (напр. соленоид, или ускоряющий зазор). Ускоритель будем представлять в виде последовательности таких элементов.
class Element:
def __init__(self, z0, MaxField, filename, name):
self.z0 = z0
self.MaxField = MaxField
self.filename = filename
self.name = name
Фокусирующие соленоиды:
Bz_beamline = {}
for z0, B0, filename, name in [
# m T Unique name
[ 0.95, 0.001, 'input/fields/B_z(z).dat', 'Sol. 1' ],
[ 2.1, 0.03, 'input/fields/B_z(z).dat', 'Sol. 2' ],
[ 2.9077, 0.001, 'input/fields/B_z(z).dat', 'Sol. 3' ],
[ 4.0024, 0.03, 'input/fields/B_z(z).dat', 'Sol. 4' ],
[ 5.642, 0.03, 'input/fields/B_z(z).dat', 'Sol. 5' ],
[ 6.760, 0.001, 'input/fields/B_z(z).dat', 'Sol. 6' ],
]:
Bz_beamline[name] = Element(z0, B0, filename, name)
Bz_beamline['Sol. 3'].z0
2.9077
Ускоряющие элементы:
Ez_beamline = {}
for z0, E0, filename, name in [
# m MV/m Unique name
[ 7.456, -0.9, 'input/fields/E_z(z).dat', 'Cavity 3'],
[ 8.838, -0.9, 'input/fields/E_z(z).dat', 'Cavity 4'],
[ 10.220, -0.9, 'input/fields/E_z(z).dat', 'Cavity 5'],
[ 11.602, -0.9, 'input/fields/E_z(z).dat', 'Cavity 6'],
[ 12.984, -0.9, 'input/fields/E_z(z).dat', 'Cavity 7'],
[ 14.366, -0.9, 'input/fields/E_z(z).dat', 'Cavity 8'],
]:
Ez_beamline[name] = Element(z0, E0, filename, name)
Считывание профилей фокусирующего и ускоряющего поля
Сперва мы просто считываем поля из файлов и сшиваем их в один массив:
from scipy import interpolate
FieldFiles = {} # buffer for field files
def read_field(beamline, z):
global FieldFiles
F = 0
for element in beamline.values():
if not (element.filename in FieldFiles):
print('Reading ' + element.filename)
FieldFiles[element.filename] = np.loadtxt(element.filename)
M = FieldFiles[element.filename]
z_data = M[:,0]
F_data = M[:,1]
f = interpolate.interp1d(
element.z0+z_data, element.MaxField*F_data,
fill_value=(0, 0), bounds_error=False
)
F = F + f(z)
return F
Bz = read_field(Bz_beamline, z)
Reading input/fields/B_z(z).dat
Для интегрирования уравнения на огибающую необходимо сконвертировать массив Bz в функцию Bz(z)
Bz = interpolate.interp1d(z, Bz, fill_value=(0, 0), bounds_error=False)
Теперь Bz уже функция, которая быстро может вывести поле в любых точках вдоль ускорителя.
Bz(2.11111)
array(0.02984419)
Построим поле \(Bz(z)\)
dim_z = hv.Dimension('z', unit='m', range=(0,z_max))
dim_Bz = hv.Dimension('Bz', unit='T', label='$B_z$')
z_Bz = hv.Area((z,Bz(z)), kdims=dim_z, vdims=dim_Bz)
z_Bz

Аналогично для ускоряющего электрического поля:
Ez = 1*read_field(Ez_beamline, z)
Ez = interpolate.interp1d(z, Ez, fill_value=(0, 0), bounds_error=False)
dim_Ez = hv.Dimension('Ez', unit='MV/m', label=r'$E_z$')
z_Ez = hv.Area((z,Ez(z)), kdims=dim_z, vdims=dim_Ez)
z_Ez

Продольная динамика пучка
Уравнение на продольную динамику пучка можно решить независимо от уравнения на огибающую, чтобы в уравнении на огибающую уже использовать готовую функцию энергии пучка от \(z\). Считая, что скорость электрона достаточно близка к скорости света и следовательно его продольная координата \(z \approx ct\), а импульс \(p_z \approx \gamma mc\)
$$ \frac{d\gamma}{dz} \approx \frac{eE_z}{mc^2}, $$
Тогда достаточно один раз проинтегрировать функцию \(E_z(z)\):
mc = 0.511 # MeV/c
#p_z = 2.459 # MeV/c
E_0 = 2.000 # MeV
gamma_0 = E_0/mc + 1 # Начальный релятивистский фактор пучка
#gamma_0 = p_z/mc
from scipy import integrate
gamma = gamma_0 + integrate.cumtrapz(-Ez(z)/mc, z)
dim_gamma = hv.Dimension('gamma', label=r'$\gamma$', range=(0,None))
z_gamma = hv.Curve((z,gamma), kdims=dim_z, vdims=dim_gamma)
(z_gamma + z_Ez).cols(1)
IuNzI3MjMgNDM4LjQ0Mjg1IA0KTCA2NTIuNzI3MjMgLTAgDQpMIDAgLTAgDQp6DQoiIHN0eWxlPSJmaWxsOiNmZmZmZmY7Ii8+DQogIDwvZz4NCiAgPGcgaWQ9ImF4ZXNfMSI+DQogICA8ZyBpZD0icGF0Y2hfMiI+DQogICAgPHBhdGggZD0iTSAxNjYuMDI1NTc4IDE4NC40NTg4MDEgDQpMIDY0NS41MjcyMyAxODQuNDU4ODAxIA0KTCA2NDUuNTI3MjMgMjQuNjI0OTE3IA0KTCAxNjYuMDI1NTc4IDI0LjYyNDkxNyANCnoNCiIgc3R5bGU9ImZpbGw6I2ZmZmZmZjsiLz4NCiAgIDwvZz4NCiAgIDxnIGlkPSJsaW5lMmRfMSI+DQogICAgPHBhdGggY2xpcC1wYXRoPSJ1cmwoI3A5NmM3MjQxODUzKSIgZD0iTSAxODguNDgyMjM5IDkyLjgxNTk3OCANCkwgMzk2LjQyNjEyMiA5Mi43MTMyNTUgDQpMIDM5Ny43MDQ3OTMgOTIuNDc0MDYzIA0KTCAzOTguNjYzNzk2IDkyLjA4MDQ1MiANCkwgMzk5Ljc4MjYzMyA5MS4zNTA0NjcgDQpMIDQwMS4yMjExMzggOTAuMTA2MTI2IA0KTCA0MDMuOTM4MzE0IDg3LjM5MDA1OCANCkwgNDA4LjA5Mzk5NSA4My4yNjkwMjUgDQpMIDQwOS4zNzI2NjYgODIuMzA0NzE1IA0KTCA0MTAuMzMxNjcgODEuODQ4NTI0IA0KTCA0MTEuNDUwNTA3IDgxLjU5MTQ3NyANCkwgNDEzLjIwODY4IDgxLjQ3NDgzNCANCkwgNDE4Ljk2MjY5OSA4MS40NTA2MzQgDQpMIDQ0MC41NDAyNzQgODEuMzU0MDgxIA0KTCA0NDEuODE4OTQ1IDgxLjEyNzI0OCANCkwgNDQyLjc3Nzk0OCA4MC43NDgxNjQgDQpMIDQ0My44OTY3ODUgODAuMDMzNTUzIA0KTCA0NDUuMzM1MjkgNzguODAwNzQxIA0KTCA0NDguMDUyNDY2IDc2LjA5MDI1MyANCkwgNDUyLjIwODE0NyA3MS45NTk2NDMgDQpMIDQ1My40ODY4MTggNzAuOTc4NzQ4IA0KTCA0NTQuNDQ1ODIyIDcwLjUwNTg4NyANCkwgNDU1LjU2NDY1OSA3MC4yMzUxNjYgDQpMIDQ1Ny4xNjI5OTggNzAuMTE1ODI5IA0KTCA0NjEuOTU4MDE0IDcwLjA4NTQzNiANCkwgNDg0LjgxNDI2IDY5Ljk3OTU0MyANCkwgNDg2LjA5MjkzMSA2OS43MzQwMzkgDQpMIDQ4Ny4wNTE5MzQgNjkuMzMzMTM0IA0KTCA0ODguMTcwNzcxIDY4LjU5NTU3NiANCkwgNDg5LjYwOTI3NiA2Ny4zNDU3MDMgDQpMIDQ5Mi40ODYyODYgNjQuNDYyODM1IA0KTCA0OTYuNDgyMTMzIDYwLjUxMDk4NiANCkwgNDk3Ljc2MDgwNCA1OS41NTUyNjEgDQpMIDQ5OC43MTk4MDcgNTkuMTA3Mzg0IA0KTCA0OTkuODM4NjQ1IDU4Ljg1NzAzMiANCkwgNTAxLjU5NjgxNyA1OC43NDM5NTUgDQpMIDUwNy41MTA2NzEgNTguNzIwNTIgDQpMIDUyOC45Mjg0MTIgNTguNjIwOTEgDQpMIDUzMC4yMDcwODMgNTguMzg4MDMxIA0KTCA1MzEuMTY2MDg2IDU4LjAwMTcxMSANCkwgNTMyLjI4NDkyMyA1Ny4yNzkzNzEgDQpMIDUzMy43MjM0MjggNTYuMDQwNzcgDQpMIDUzNi40NDA2MDQgNTMuMzI3NDg4IA0KTCA1NDAuNTk2Mjg1IDQ5LjIwMTU2IA0KTCA1NDEuODc0OTU2IDQ4LjIyODk0MyANCkwgNTQyLjgzMzk1OSA0Ny43NjQ0MTcgDQpMIDU0My45NTI3OTcgNDcuNTAwNTQ1IA0KTCA1NDUuNzEwOTY5IDQ3LjM4MDMyMyANCkwgNTUxLjMwNTE1NSA0Ny4zNTUzNSANCkwgNTczLjIwMjM5NyA0Ny4yNDYwOSANCkwgNTc0LjQ4MTA2OCA0Ni45OTQwNzEgDQpMIDU3NS40NDAwNzIgNDYuNTg1ODQyIA0KTCA1NzYuNTU4OTA5IDQ1Ljg0MDcxOSANCkwgNTc3Ljk5NzQxNCA0NC41ODUzMTUgDQpMIDU4MC44NzQ0MjQgNDEuNjk5ODQgDQpMIDU4NC44NzAyNzEgMzcuNzUzMTI5IA0KTCA1ODYuMTQ4OTQyIDM2LjgwNTk5NCANCkwgNTg3LjEwNzk0NSAzNi4zNjY0MDQgDQpMIDU4OC4yMjY3ODIgMzYuMTIyNTM3IA0KTCA1ODkuOTg0OTU1IDM2LjAxMjgyNSANCkwgNTk2LjA1ODY0MyAzNS45OTAyNjEgDQpMIDYxNy4zMTY1NDkgMzUuODg3NTM3IA0KTCA2MTguNTk1MjIgMzUuNjQ4MzQ2IA0KTCA2MTkuNTU0MjI0IDM1LjI1NDczNSANCkwgNjIwLjY3MzA2MSAzNC41MjQ3NSANCkwgNjIyLjExMTU2NiAzMy4yODA0MDkgDQpMIDYyNC44Mjg3NDIgMzAuNTY0MzQxIA0KTCA2MjguOTg0NDIzIDI2LjQ0MzMwOCANCkwgNjMwLjI2MzA5NCAyNS40Nzg5OTggDQpMIDYzMS4yMjIwOTcgMjUuMDIyODA3IA0KTCA2MzIuMzQwOTM0IDI0Ljc2NTc2IA0KTCA2MzQuMDk5MTA3IDI0LjY0OTExNyANCkwgNjM5Ljg1MzEyNyAyNC42MjQ5MTcgDQpMIDY0NS4yODc0NzkgMjQuNjI0OTE3IA0KTCA2NDUuMjg3NDc5IDI0LjYyNDkxNyANCiIgc3R5bGU9ImZpbGw6bm9uZTtzdHJva2U6IzMwYTJkYTtzdHJva2UtbGluZWNhcDpzcXVhcmU7c3Ryb2tlLW9wYWNpdHk6MC41O3N0cm9rZS13aWR0aDoyOyIvPg0KICAgPC9nPg0KICAgPGcgaWQ9Im1hdHBsb3RsaWIuYXhpc18xIj4NCiAgICA8ZyBpZD0ieHRpY2tfMSI+DQogICAgIDxnIGlkPSJsaW5lMmRfMiI+DQogICAgICA8cGF0aCBjbGlwLXBhdGg9InVybCgjcDk2YzcyNDE4NTMpIiBkPSJNIDE2Ni4wMjU1NzggMTg0LjQ1ODgwMSANCkwgMTY2LjAyNTU3OCAyNC42MjQ5MTcgDQoiIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlOiNiMGIwYjA7c3Ryb2tlLWxpbmVjYXA6c3F1YXJlO3N0cm9rZS13aWR0aDowLjg7Ii8+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9ImxpbmUyZF8zIj4NCiAgICAgIDxkZWZzPg0KICAgICAgIDxwYXRoIGQ9Ik0gMCAwIA0KTCAwIDMuNSANCiIgaWQ9Im0xOTJiN2RiNzc0IiBzdHlsZT0ic3Ryb2tlOiMwMDAwMDA7c3Ryb2tlLXdpZHRoOjAuODsiLz4NCiAgICAgIDwvZGVmcz4NCiAgICAgIDxnPg0KICAgICAgIDx1c2Ugc3R5bGU9InN0cm9rZTojMDAwMDAwO3N0cm9rZS13aWR0aDowLjg7IiB4PSIxNjYuMDI1NTc4IiB4bGluazpocmVmPSIjbTE5MmI3ZGI3NzQiIHk9IjE4NC40NTg4MDEiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0idGV4dF8xIj4NCiAgICAgIDwhLS0gMCAtLT4NCiAgICAgIDxkZWZzPg0KICAgICAgIDxwYXRoIGQ9Ik0gMzEuNzgxMjUgNjYuNDA2MjUgDQpRIDI0LjE3MTg3NSA2Ni40MDYyNSAyMC4zMjgxMjUgNTguOTA2MjUgDQpRIDE2LjUgNTEuNDIxODc1IDE2LjUgMzYuMzc1IA0KUSAxNi41IDIxLjM5MDYyNSAyMC4zMjgxMjUgMTMuODkwNjI1IA0KUSAyNC4xNzE4NzUgNi4zOTA2MjUgMzEuNzgxMjUgNi4zOTA2MjUgDQpRIDM5LjQ1MzEyNSA2LjM5MDYyNSA0My4yODEyNSAxMy44OTA2MjUgDQpRIDQ3LjEyNSAyMS4zOTA2MjUgNDcuMTI1IDM2LjM3NSANClEgNDcuMTI1IDUxLjQyMTg3NSA0My4yODEyNSA1OC45MDYyNSANClEgMzkuNDUzMTI1IDY2LjQwNjI1IDMxLjc4MTI1IDY2LjQwNjI1IA0Keg0KTSAzMS43ODEyNSA3NC4yMTg3NSANClEgNDQuMDQ2ODc1IDc0LjIxODc1IDUwLjUxNTYyNSA2NC41MTU2MjUgDQpRIDU2Ljk4NDM3NSA1NC44MjgxMjUgNTYuOTg0Mzc1IDM2LjM3NSANClEgNTYuOTg0Mzc1IDE3Ljk2ODc1IDUwLjUxNTYyNSA4LjI2NTYyNSANClEgNDQuMDQ2ODc1IC0xLjQyMTg3NSAzMS43ODEyNSAtMS40MjE4NzUgDQpRIDE5LjUzMTI1IC0xLjQyMTg3NSAxMy4wNjI1IDguMjY1NjI1IA0KUSA2LjU5Mzc1IDE3Ljk2ODc1IDYuNTkzNzUgMzYuMzc1IA0KUSA2LjU5Mzc1IDU0LjgyODEyNSAxMy4wNjI1IDY0LjUxNTYyNSANClEgMTkuNTMxMjUgNzQuMjE4NzUgMzEuNzgxMjUgNzQuMjE4NzUgDQp6DQoiIGlkPSJEZWphVnVTYW5zLTQ4Ii8+DQogICAgICA8L2RlZnM+DQogICAgICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjEuNTcxODI4IDIwMi4wOTY2MTQpc2NhbGUoMC4xNCAtMC4xNCkiPg0KICAgICAgIDx1c2UgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNDgiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgIDwvZz4NCiAgICA8ZyBpZD0ieHRpY2tfMiI+DQogICAgIDxnIGlkPSJsaW5lMmRfNCI+DQogICAgICA8cGF0aCBjbGlwLXBhdGg9InVybCgjcDk2YzcyNDE4NTMpIiBkPSJNIDIyOS45NTkxMzIgMTg0LjQ1ODgwMSANCkwgMjI5Ljk1OTEzMiAyNC42MjQ5MTcgDQoiIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlOiNiMGIwYjA7c3Ryb2tlLWxpbmVjYXA6c3F1YXJlO3N0cm9rZS13aWR0aDowLjg7Ii8+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9ImxpbmUyZF81Ij4NCiAgICAgIDxnPg0KICAgICAgIDx1c2Ugc3R5bGU9InN0cm9rZTojMDAwMDAwO3N0cm9rZS13aWR0aDowLjg7IiB4PSIyMjkuOTU5MTMyIiB4bGluazpocmVmPSIjbTE5MmI3ZGI3NzQiIHk9IjE4NC40NTg4MDEiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0idGV4dF8yIj4NCiAgICAgIDwhLS0gMiAtLT4NCiAgICAgIDxkZWZzPg0KICAgICAgIDxwYXRoIGQ9Ik0gMTkuMTg3NSA4LjI5Njg3NSANCkwgNTMuNjA5Mzc1IDguMjk2ODc1IA0KTCA1My42MDkzNzUgMCANCkwgNy4zMjgxMjUgMCANCkwgNy4zMjgxMjUgOC4yOTY4NzUgDQpRIDEyLjkzNzUgMTQuMTA5Mzc1IDIyLjYyNSAyMy44OTA2MjUgDQpRIDMyLjMyODEyNSAzMy42ODc1IDM0LjgxMjUgMzYuNTMxMjUgDQpRIDM5LjU0Njg3NSA0MS44NDM3NSA0MS40MjE4NzUgNDUuNTMxMjUgDQpRIDQzLjMxMjUgNDkuMjE4NzUgNDMuMzEyNSA1Mi43ODEyNSANClEgNDMuMzEyNSA1OC41OTM3NSAzOS4yMzQzNzUgNjIuMjUgDQpRIDM1LjE1NjI1IDY1LjkyMTg3NSAyOC42MDkzNzUgNjUuOTIxODc1IA0KUSAyMy45Njg3NSA2NS45MjE4NzUgMTguODEyNSA2NC4zMTI1IA0KUSAxMy42NzE4NzUgNjIuNzAzMTI1IDcuODEyNSA1OS40MjE4NzUgDQpMIDcuODEyNSA2OS4zOTA2MjUgDQpRIDEzLjc2NTYyNSA3MS43ODEyNSAxOC45Mzc1IDczIA0KUSAyNC4xMjUgNzQuMjE4NzUgMjguNDIxODc1IDc0LjIxODc1IA0KUSAzOS43NSA3NC4yMTg3NSA0Ni40ODQzNzUgNjguNTQ2ODc1IA0KUSA1My4yMTg3NSA2Mi44OTA2MjUgNTMuMjE4NzUgNTMuNDIxODc1IA0KUSA1My4yMTg3NSA0OC45MjE4NzUgNTEuNTMxMjUgNDQuODkwNjI1IA0KUSA0OS44NTkzNzUgNDAuODc1IDQ1LjQwNjI1IDM1LjQwNjI1IA0KUSA0NC4xODc1IDMzLjk4NDM3NSAzNy42NDA2MjUgMjcuMjE4NzUgDQpRIDMxLjEwOTM3NSAyMC40NTMxMjUgMTkuMTg3NSA4LjI5Njg3NSANCnoNCiIgaWQ9IkRlamFWdVNhbnMtNTAiLz4NCiAgICAgIDwvZGVmcz4NCiAgICAgIDxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIyNS41MDUzODIgMjAyLjA5NjYxNClzY2FsZSgwLjE0IC0wLjE0KSI+DQogICAgICAgPHVzZSB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy01MCIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgPC9nPg0KICAgIDxnIGlkPSJ4dGlja18zIj4NCiAgICAgPGcgaWQ9ImxpbmUyZF82Ij4NCiAgICAgIDxwYXRoIGNsaXAtcGF0aD0idXJsKCNwOTZjNzI0MTg1MykiIGQ9Ik0gMjkzLjg5MjY4NSAxODQuNDU4ODAxIA0KTCAyOTMuODkyNjg1IDI0LjYyNDkxNyANCiIgc3R5bGU9ImZpbGw6bm9uZTtzdHJva2U6I2IwYjBiMDtzdHJva2UtbGluZWNhcDpzcXVhcmU7c3Ryb2tlLXdpZHRoOjAuODsiLz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0ibGluZTJkXzciPg0KICAgICAgPGc+DQogICAgICAgPHVzZSBzdHlsZT0ic3Ryb2tlOiMwMDAwMDA7c3Ryb2tlLXdpZHRoOjAuODsiIHg9IjI5My44OTI2ODUiIHhsaW5rOmhyZWY9IiNtMTkyYjdkYjc3NCIgeT0iMTg0LjQ1ODgwMSIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJ0ZXh0XzMiPg0KICAgICAgPCEtLSA0IC0tPg0KICAgICAgPGRlZnM+DQogICAgICAgPHBhdGggZD0iTSAzNy43OTY4NzUgNjQuMzEyNSANCkwgMTIuODkwNjI1IDI1LjM5MDYyNSANCkwgMzcuNzk2ODc1IDI1LjM5MDYyNSANCnoNCk0gMzUuMjAzMTI1IDcyLjkwNjI1IA0KTCA0Ny42MDkzNzUgNzIuOTA2MjUgDQpMIDQ3LjYwOTM3NSAyNS4zOTA2MjUgDQpMIDU4LjAxNTYyNSAyNS4zOTA2MjUgDQpMIDU4LjAxNTYyNSAxNy4xODc1IA0KTCA0Ny42MDkzNzUgMTcuMTg3NSANCkwgNDcuNjA5Mzc1IDAgDQpMIDM3Ljc5Njg3NSAwIA0KTCAzNy43OTY4NzUgMTcuMTg3NSANCkwgNC44OTA2MjUgMTcuMTg3NSANCkwgNC44OTA2MjUgMjYuNzAzMTI1IA0Keg0KIiBpZD0iRGVqYVZ1U2Fucy01MiIvPg0KICAgICAgPC9kZWZzPg0KICAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjg5LjQzODkzNSAyMDIuMDk2NjE0KXNjYWxlKDAuMTQgLTAuMTQpIj4NCiAgICAgICA8dXNlIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTUyIi8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICA8L2c+DQogICAgPGcgaWQ9Inh0aWNrXzQiPg0KICAgICA8ZyBpZD0ibGluZTJkXzgiPg0KICAgICAgPHBhdGggY2xpcC1wYXRoPSJ1cmwoI3A5NmM3MjQxODUzKSIgZD0iTSAzNTcuODI2MjM5IDE4NC40NTg4MDEgDQpMIDM1Ny44MjYyMzkgMjQuNjI0OTE3IA0KIiBzdHlsZT0iZmlsbDpub25lO3N0cm9rZTojYjBiMGIwO3N0cm9rZS1saW5lY2FwOnNxdWFyZTtzdHJva2Utd2lkdGg6MC44OyIvPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJsaW5lMmRfOSI+DQogICAgICA8Zz4NCiAgICAgICA8dXNlIHN0eWxlPSJzdHJva2U6IzAwMDAwMDtzdHJva2Utd2lkdGg6MC44OyIgeD0iMzU3LjgyNjIzOSIgeGxpbms6aHJlZj0iI20xOTJiN2RiNzc0IiB5PSIxODQuNDU4ODAxIi8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9InRleHRfNCI+DQogICAgICA8IS0tIDYgLS0+DQogICAgICA8ZGVmcz4NCiAgICAgICA8cGF0aCBkPSJNIDMzLjAxNTYyNSA0MC4zNzUgDQpRIDI2LjM3NSA0MC4zNzUgMjIuNDg0Mzc1IDM1LjgyODEyNSANClEgMTguNjA5Mzc1IDMxLjI5Njg3NSAxOC42MDkzNzUgMjMuMzkwNjI1IA0KUSAxOC42MDkzNzUgMTUuNTMxMjUgMjIuNDg0Mzc1IDEwLjk1MzEyNSANClEgMjYuMzc1IDYuMzkwNjI1IDMzLjAxNTYyNSA2LjM5MDYyNSANClEgMzkuNjU2MjUgNi4zOTA2MjUgNDMuNTMxMjUgMTAuOTUzMTI1IA0KUSA0Ny40MDYyNSAxNS41MzEyNSA0Ny40MDYyNSAyMy4zOTA2MjUgDQpRIDQ3LjQwNjI1IDMxLjI5Njg3NSA0My41MzEyNSAzNS44MjgxMjUgDQpRIDM5LjY1NjI1IDQwLjM3NSAzMy4wMTU2MjUgNDAuMzc1IA0Keg0KTSA1Mi41OTM3NSA3MS4yOTY4NzUgDQpMIDUyLjU5Mzc1IDYyLjMxMjUgDQpRIDQ4Ljg3NSA2NC4wNjI1IDQ1LjA5Mzc1IDY0Ljk4NDM3NSANClEgNDEuMzEyNSA2NS45MjE4NzUgMzcuNTkzNzUgNjUuOTIxODc1IA0KUSAyNy44MjgxMjUgNjUuOTIxODc1IDIyLjY3MTg3NSA1OS4zMjgxMjUgDQpRIDE3LjUzMTI1IDUyLjczNDM3NSAxNi43OTY4NzUgMzkuNDA2MjUgDQpRIDE5LjY3MTg3NSA0My42NTYyNSAyNC4wMTU2MjUgNDUuOTIxODc1IA0KUSAyOC4zNzUgNDguMTg3NSAzMy41OTM3NSA0OC4xODc1IA0KUSA0NC41NzgxMjUgNDguMTg3NSA1MC45NTMxMjUgNDEuNTE1NjI1IA0KUSA1Ny4zMjgxMjUgMzQuODU5Mzc1IDU3LjMyODEyNSAyMy4zOTA2MjUgDQpRIDU3LjMyODEyNSAxMi4xNTYyNSA1MC42ODc1IDUuMzU5Mzc1IA0KUSA0NC4wNDY4NzUgLTEuNDIxODc1IDMzLjAxNTYyNSAtMS40MjE4NzUgDQpRIDIwLjM1OTM3NSAtMS40MjE4NzUgMTMuNjcxODc1IDguMjY1NjI1IA0KUSA2Ljk4NDM3NSAxNy45Njg3NSA2Ljk4NDM3NSAzNi4zNzUgDQpRIDYuOTg0Mzc1IDUzLjY1NjI1IDE1LjE4NzUgNjMuOTM3NSANClEgMjMuMzkwNjI1IDc0LjIxODc1IDM3LjIwMzEyNSA3NC4yMTg3NSANClEgNDAuOTIxODc1IDc0LjIxODc1IDQ0LjcwMzEyNSA3My40ODQzNzUgDQpRIDQ4LjQ4NDM3NSA3Mi43NSA1Mi41OTM3NSA3MS4yOTY4NzUgDQp6DQoiIGlkPSJEZWphVnVTYW5zLTU0Ii8+DQogICAgICA8L2RlZnM+DQogICAgICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNTMuMzcyNDg5IDIwMi4wOTY2MTQpc2NhbGUoMC4xNCAtMC4xNCkiPg0KICAgICAgIDx1c2UgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNTQiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgIDwvZz4NCiAgICA8ZyBpZD0ieHRpY2tfNSI+DQogICAgIDxnIGlkPSJsaW5lMmRfMTAiPg0KICAgICAgPHBhdGggY2xpcC1wYXRoPSJ1cmwoI3A5NmM3MjQxODUzKSIgZD0iTSA0MjEuNzU5NzkyIDE4NC40NTg4MDEgDQpMIDQyMS43NTk3OTIgMjQuNjI0OTE3IA0KIiBzdHlsZT0iZmlsbDpub25lO3N0cm9rZTojYjBiMGIwO3N0cm9rZS1saW5lY2FwOnNxdWFyZTtzdHJva2Utd2lkdGg6MC44OyIvPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJsaW5lMmRfMTEiPg0KICAgICAgPGc+DQogICAgICAgPHVzZSBzdHlsZT0ic3Ryb2tlOiMwMDAwMDA7c3Ryb2tlLXdpZHRoOjAuODsiIHg9IjQyMS43NTk3OTIiIHhsaW5rOmhyZWY9IiNtMTkyYjdkYjc3NCIgeT0iMTg0LjQ1ODgwMSIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJ0ZXh0XzUiPg0KICAgICAgPCEtLSA4IC0tPg0KICAgICAgPGRlZnM+DQogICAgICAgPHBhdGggZD0iTSAzMS43ODEyNSAzNC42MjUgDQpRIDI0Ljc1IDM0LjYyNSAyMC43MTg3NSAzMC44NTkzNzUgDQpRIDE2LjcwMzEyNSAyNy4wOTM3NSAxNi43MDMxMjUgMjAuNTE1NjI1IA0KUSAxNi43MDMxMjUgMTMuOTIxODc1IDIwLjcxODc1IDEwLjE1NjI1IA0KUSAyNC43NSA2LjM5MDYyNSAzMS43ODEyNSA2LjM5MDYyNSANClEgMzguODEyNSA2LjM5MDYyNSA0Mi44NTkzNzUgMTAuMTcxODc1IA0KUSA0Ni45MjE4NzUgMTMuOTY4NzUgNDYuOTIxODc1IDIwLjUxNTYyNSANClEgNDYuOTIxODc1IDI3LjA5Mzc1IDQyLjg5MDYyNSAzMC44NTkzNzUgDQpRIDM4Ljg3NSAzNC42MjUgMzEuNzgxMjUgMzQuNjI1IA0Keg0KTSAyMS45MjE4NzUgMzguODEyNSANClEgMTUuNTc4MTI1IDQwLjM3NSAxMi4wMzEyNSA0NC43MTg3NSANClEgOC41IDQ5LjA3ODEyNSA4LjUgNTUuMzI4MTI1IA0KUSA4LjUgNjQuMDYyNSAxNC43MTg3NSA2OS4xNDA2MjUgDQpRIDIwLjk1MzEyNSA3NC4yMTg3NSAzMS43ODEyNSA3NC4yMTg3NSANClEgNDIuNjcxODc1IDc0LjIxODc1IDQ4Ljg3NSA2OS4xNDA2MjUgDQpRIDU1LjA3ODEyNSA2NC4wNjI1IDU1LjA3ODEyNSA1NS4zMjgxMjUgDQpRIDU1LjA3ODEyNSA0OS4wNzgxMjUgNTEuNTMxMjUgNDQuNzE4NzUgDQpRIDQ4IDQwLjM3NSA0MS43MDMxMjUgMzguODEyNSANClEgNDguODI4MTI1IDM3LjE1NjI1IDUyLjc5Njg3NSAzMi4zMTI1IA0KUSA1Ni43ODEyNSAyNy40ODQzNzUgNTYuNzgxMjUgMjAuNTE1NjI1IA0KUSA1Ni43ODEyNSA5LjkwNjI1IDUwLjMxMjUgNC4yMzQzNzUgDQpRIDQzLjg0Mzc1IC0xLjQyMTg3NSAzMS43ODEyNSAtMS40MjE4NzUgDQpRIDE5LjczNDM3NSAtMS40MjE4NzUgMTMuMjUgNC4yMzQzNzUgDQpRIDYuNzgxMjUgOS45MDYyNSA2Ljc4MTI1IDIwLjUxNTYyNSANClEgNi43ODEyNSAyNy40ODQzNzUgMTAuNzgxMjUgMzIuMzEyNSANClEgMTQuNzk2ODc1IDM3LjE1NjI1IDIxLjkyMTg3NSAzOC44MTI1IA0Keg0KTSAxOC4zMTI1IDU0LjM5MDYyNSANClEgMTguMzEyNSA0OC43MzQzNzUgMjEuODQzNzUgNDUuNTYyNSANClEgMjUuMzkwNjI1IDQyLjM5MDYyNSAzMS43ODEyNSA0Mi4zOTA2MjUgDQpRIDM4LjE0MDYyNSA0Mi4zOTA2MjUgNDEuNzE4NzUgNDUuNTYyNSANClEgNDUuMzEyNSA0OC43MzQzNzUgNDUuMzEyNSA1NC4zOTA2MjUgDQpRIDQ1LjMxMjUgNjAuMDYyNSA0MS43MTg3NSA2My4yMzQzNzUgDQpRIDM4LjE0MDYyNSA2Ni40MDYyNSAzMS43ODEyNSA2Ni40MDYyNSANClEgMjUuMzkwNjI1IDY2LjQwNjI1IDIxLjg0Mzc1IDYzLjIzNDM3NSANClEgMTguMzEyNSA2MC4wNjI1IDE4LjMxMjUgNTQuMzkwNjI1IA0Keg0KIiBpZD0iRGVqYVZ1U2Fucy01NiIvPg0KICAgICAgPC9kZWZzPg0KICAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDE3LjMwNjA0MiAyMDIuMDk2NjE0KXNjYWxlKDAuMTQgLTAuMTQpIj4NCiAgICAgICA8dXNlIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTU2Ii8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICA8L2c+DQogICAgPGcgaWQ9Inh0aWNrXzYiPg0KICAgICA8ZyBpZD0ibGluZTJkXzEyIj4NCiAgICAgIDxwYXRoIGNsaXAtcGF0aD0idXJsKCNwOTZjNzI0MTg1MykiIGQ9Ik0gNDg1LjY5MzM0NiAxODQuNDU4ODAxIA0KTCA0ODUuNjkzMzQ2IDI0LjYyNDkxNyANCiIgc3R5bGU9ImZpbGw6bm9uZTtzdHJva2U6I2IwYjBiMDtzdHJva2UtbGluZWNhcDpzcXVhcmU7c3Ryb2tlLXdpZHRoOjAuODsiLz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0ibGluZTJkXzEzIj4NCiAgICAgIDxnPg0KICAgICAgIDx1c2Ugc3R5bGU9InN0cm9rZTojMDAwMDAwO3N0cm9rZS13aWR0aDowLjg7IiB4PSI0ODUuNjkzMzQ2IiB4bGluazpocmVmPSIjbTE5MmI3ZGI3NzQiIHk9IjE4NC40NTg4MDEiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0idGV4dF82Ij4NCiAgICAgIDwhLS0gMTAgLS0+DQogICAgICA8ZGVmcz4NCiAgICAgICA8cGF0aCBkPSJNIDEyLjQwNjI1IDguMjk2ODc1IA0KTCAyOC41MTU2MjUgOC4yOTY4NzUgDQpMIDI4LjUxNTYyNSA2My45MjE4NzUgDQpMIDEwLjk4NDM3NSA2MC40MDYyNSANCkwgMTAuOTg0Mzc1IDY5LjM5MDYyNSANCkwgMjguNDIxODc1IDcyLjkwNjI1IA0KTCAzOC4yODEyNSA3Mi45MDYyNSANCkwgMzguMjgxMjUgOC4yOTY4NzUgDQpMIDU0LjM5MDYyNSA4LjI5Njg3NSANCkwgNTQuMzkwNjI1IDAgDQpMIDEyLjQwNjI1IDAgDQp6DQoiIGlkPSJEZWphVnVTYW5zLTQ5Ii8+DQogICAgICA8L2RlZnM+DQogICAgICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NzYuNzg1ODQ2IDIwMi4wOTY2MTQpc2NhbGUoMC4xNCAtMC4xNCkiPg0KICAgICAgIDx1c2UgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNDkiLz4NCiAgICAgICA8dXNlIHg9IjYzLjYyMzA0NyIgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNDgiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgIDwvZz4NCiAgICA8ZyBpZD0ieHRpY2tfNyI+DQogICAgIDxnIGlkPSJsaW5lMmRfMTQiPg0KICAgICAgPHBhdGggY2xpcC1wYXRoPSJ1cmwoI3A5NmM3MjQxODUzKSIgZD0iTSA1NDkuNjI2ODk5IDE4NC40NTg4MDEgDQpMIDU0OS42MjY4OTkgMjQuNjI0OTE3IA0KIiBzdHlsZT0iZmlsbDpub25lO3N0cm9rZTojYjBiMGIwO3N0cm9rZS1saW5lY2FwOnNxdWFyZTtzdHJva2Utd2lkdGg6MC44OyIvPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJsaW5lMmRfMTUiPg0KICAgICAgPGc+DQogICAgICAgPHVzZSBzdHlsZT0ic3Ryb2tlOiMwMDAwMDA7c3Ryb2tlLXdpZHRoOjAuODsiIHg9IjU0OS42MjY4OTkiIHhsaW5rOmhyZWY9IiNtMTkyYjdkYjc3NCIgeT0iMTg0LjQ1ODgwMSIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJ0ZXh0XzciPg0KICAgICAgPCEtLSAxMiAtLT4NCiAgICAgIDxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU0MC43MTkzOTkgMjAyLjA5NjYxNClzY2FsZSgwLjE0IC0wLjE0KSI+DQogICAgICAgPHVzZSB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy00OSIvPg0KICAgICAgIDx1c2UgeD0iNjMuNjIzMDQ3IiB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy01MCIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgPC9nPg0KICAgIDxnIGlkPSJ4dGlja184Ij4NCiAgICAgPGcgaWQ9ImxpbmUyZF8xNiI+DQogICAgICA8cGF0aCBjbGlwLXBhdGg9InVybCgjcDk2YzcyNDE4NTMpIiBkPSJNIDYxMy41NjA0NTMgMTg0LjQ1ODgwMSANCkwgNjEzLjU2MDQ1MyAyNC42MjQ5MTcgDQoiIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlOiNiMGIwYjA7c3Ryb2tlLWxpbmVjYXA6c3F1YXJlO3N0cm9rZS13aWR0aDowLjg7Ii8+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9ImxpbmUyZF8xNyI+DQogICAgICA8Zz4NCiAgICAgICA8dXNlIHN0eWxlPSJzdHJva2U6IzAwMDAwMDtzdHJva2Utd2lkdGg6MC44OyIgeD0iNjEzLjU2MDQ1MyIgeGxpbms6aHJlZj0iI20xOTJiN2RiNzc0IiB5PSIxODQuNDU4ODAxIi8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9InRleHRfOCI+DQogICAgICA8IS0tIDE0IC0tPg0KICAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjA0LjY1Mjk1MyAyMDIuMDk2NjE0KXNjYWxlKDAuMTQgLTAuMTQpIj4NCiAgICAgICA8dXNlIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTQ5Ii8+DQogICAgICAgPHVzZSB4PSI2My42MjMwNDciIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTUyIi8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICA8L2c+DQogICAgPGcgaWQ9InRleHRfOSI+DQogICAgIDwhLS0geiAobSkgLS0+DQogICAgIDxkZWZzPg0KICAgICAgPHBhdGggZD0iTSA1LjUxNTYyNSA1NC42ODc1IA0KTCA0OC4xODc1IDU0LjY4NzUgDQpMIDQ4LjE4NzUgNDYuNDg0Mzc1IA0KTCAxNC40MDYyNSA3LjE3MTg3NSANCkwgNDguMTg3NSA3LjE3MTg3NSANCkwgNDguMTg3NSAwIA0KTCA0LjI5Njg3NSAwIA0KTCA0LjI5Njg3NSA4LjIwMzEyNSANCkwgMzguMDkzNzUgNDcuNTE1NjI1IA0KTCA1LjUxNTYyNSA0Ny41MTU2MjUgDQp6DQoiIGlkPSJEZWphVnVTYW5zLTEyMiIvPg0KICAgICAgPHBhdGggaWQ9IkRlamFWdVNhbnMtMzIiLz4NCiAgICAgIDxwYXRoIGQ9Ik0gMzEgNzUuODc1IA0KUSAyNC40Njg3NSA2NC42NTYyNSAyMS4yODEyNSA1My42NTYyNSANClEgMTguMTA5Mzc1IDQyLjY3MTg3NSAxOC4xMDkzNzUgMzEuMzkwNjI1IA0KUSAxOC4xMDkzNzUgMjAuMTI1IDIxLjMxMjUgOS4wNjI1IA0KUSAyNC41MTU2MjUgLTIgMzEgLTEzLjE4NzUgDQpMIDIzLjE4NzUgLTEzLjE4NzUgDQpRIDE1Ljg3NSAtMS43MDMxMjUgMTIuMjM0Mzc1IDkuMzc1IA0KUSA4LjU5Mzc1IDIwLjQ1MzEyNSA4LjU5Mzc1IDMxLjM5MDYyNSANClEgOC41OTM3NSA0Mi4yODEyNSAxMi4yMDMxMjUgNTMuMzEyNSANClEgMTUuODI4MTI1IDY0LjM1OTM3NSAyMy4xODc1IDc1Ljg3NSANCnoNCiIgaWQ9IkRlamFWdVNhbnMtNDAiLz4NCiAgICAgIDxwYXRoIGQ9Ik0gNTIgNDQuMTg3NSANClEgNTUuMzc1IDUwLjI1IDYwLjA2MjUgNTMuMTI1IA0KUSA2NC43NSA1NiA3MS4wOTM3NSA1NiANClEgNzkuNjQwNjI1IDU2IDg0LjI4MTI1IDUwLjAxNTYyNSANClEgODguOTIxODc1IDQ0LjA0Njg3NSA4OC45MjE4NzUgMzMuMDE1NjI1IA0KTCA4OC45MjE4NzUgMCANCkwgNzkuODkwNjI1IDAgDQpMIDc5Ljg5MDYyNSAzMi43MTg3NSANClEgNzkuODkwNjI1IDQwLjU3ODEyNSA3Ny4wOTM3NSA0NC4zNzUgDQpRIDc0LjMxMjUgNDguMTg3NSA2OC42MDkzNzUgNDguMTg3NSANClEgNjEuNjI1IDQ4LjE4NzUgNTcuNTYyNSA0My41NDY4NzUgDQpRIDUzLjUxNTYyNSAzOC45MjE4NzUgNTMuNTE1NjI1IDMwLjkwNjI1IA0KTCA1My41MTU2MjUgMCANCkwgNDQuNDg0Mzc1IDAgDQpMIDQ0LjQ4NDM3NSAzMi43MTg3NSANClEgNDQuNDg0Mzc1IDQwLjYyNSA0MS43MDMxMjUgNDQuNDA2MjUgDQpRIDM4LjkyMTg3NSA0OC4xODc1IDMzLjEwOTM3NSA0OC4xODc1IA0KUSAyNi4yMTg3NSA0OC4xODc1IDIyLjE1NjI1IDQzLjUzMTI1IA0KUSAxOC4xMDkzNzUgMzguODc1IDE4LjEwOTM3NSAzMC45MDYyNSANCkwgMTguMTA5Mzc1IDAgDQpMIDkuMDc4MTI1IDAgDQpMIDkuMDc4MTI1IDU0LjY4NzUgDQpMIDE4LjEwOTM3NSA1NC42ODc1IA0KTCAxOC4xMDkzNzUgNDYuMTg3NSANClEgMjEuMTg3NSA1MS4yMTg3NSAyNS40ODQzNzUgNTMuNjA5Mzc1IA0KUSAyOS43ODEyNSA1NiAzNS42ODc1IDU2IA0KUSA0MS42NTYyNSA1NiA0NS44MjgxMjUgNTIuOTY4NzUgDQpRIDUwIDQ5Ljk1MzEyNSA1MiA0NC4xODc1IA0Keg0KIiBpZD0iRGVqYVZ1U2Fucy0xMDkiLz4NCiAgICAgIDxwYXRoIGQ9Ik0gOC4wMTU2MjUgNzUuODc1IA0KTCAxNS44MjgxMjUgNzUuODc1IA0KUSAyMy4xNDA2MjUgNjQuMzU5Mzc1IDI2Ljc4MTI1IDUzLjMxMjUgDQpRIDMwLjQyMTg3NSA0Mi4yODEyNSAzMC40MjE4NzUgMzEuMzkwNjI1IA0KUSAzMC40MjE4NzUgMjAuNDUzMTI1IDI2Ljc4MTI1IDkuMzc1IA0KUSAyMy4xNDA2MjUgLTEuNzAzMTI1IDE1LjgyODEyNSAtMTMuMTg3NSANCkwgOC4wMTU2MjUgLTEzLjE4NzUgDQpRIDE0LjUgLTIgMTcuNzAzMTI1IDkuMDYyNSANClEgMjAuOTA2MjUgMjAuMTI1IDIwLjkwNjI1IDMxLjM5MDYyNSANClEgMjAuOTA2MjUgNDIuNjcxODc1IDE3LjcwMzEyNSA1My42NTYyNSANClEgMTQuNSA2NC42NTYyNSA4LjAxNTYyNSA3NS44NzUgDQp6DQoiIGlkPSJEZWphVnVTYW5zLTQxIi8+DQogICAgIDwvZGVmcz4NCiAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg3LjU5NzE4NSAyMTkuNjQ1OTg5KXNjYWxlKDAuMTQgLTAuMTQpIj4NCiAgICAgIDx1c2UgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtMTIyIi8+DQogICAgICA8dXNlIHg9IjUyLjQ5MDIzNCIgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtMzIiLz4NCiAgICAgIDx1c2UgeD0iODQuMjc3MzQ0IiB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy00MCIvPg0KICAgICAgPHVzZSB4PSIxMjMuMjkxMDE2IiB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy0xMDkiLz4NCiAgICAgIDx1c2UgeD0iMjIwLjcwMzEyNSIgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNDEiLz4NCiAgICAgPC9nPg0KICAgIDwvZz4NCiAgIDwvZz4NCiAgIDxnIGlkPSJtYXRwbG90bGliLmF4aXNfMiI+DQogICAgPGcgaWQ9Inl0aWNrXzEiPg0KICAgICA8ZyBpZD0ibGluZTJkXzE4Ij4NCiAgICAgIDxwYXRoIGNsaXAtcGF0aD0idXJsKCNwOTZjNzI0MTg1MykiIGQ9Ik0gMTY2LjAyNTU3OCAxODQuNDU4ODAxIA0KTCA2NDUuNTI3MjMgMTg0LjQ1ODgwMSANCiIgc3R5bGU9ImZpbGw6bm9uZTtzdHJva2U6I2IwYjBiMDtzdHJva2UtbGluZWNhcDpzcXVhcmU7c3Ryb2tlLXdpZHRoOjAuODsiLz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0ibGluZTJkXzE5Ij4NCiAgICAgIDxkZWZzPg0KICAgICAgIDxwYXRoIGQ9Ik0gMCAwIA0KTCAtMy41IDAgDQoiIGlkPSJtZTE4NDliNDA1MCIgc3R5bGU9InN0cm9rZTojMDAwMDAwO3N0cm9rZS13aWR0aDowLjg7Ii8+DQogICAgICA8L2RlZnM+DQogICAgICA8Zz4NCiAgICAgICA8dXNlIHN0eWxlPSJzdHJva2U6IzAwMDAwMDtzdHJva2Utd2lkdGg6MC44OyIgeD0iMTY2LjAyNTU3OCIgeGxpbms6aHJlZj0iI21lMTg0OWI0MDUwIiB5PSIxODQuNDU4ODAxIi8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9InRleHRfMTAiPg0KICAgICAgPCEtLSAwIC0tPg0KICAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTUwLjExODA3OCAxODkuNzc3NzA4KXNjYWxlKDAuMTQgLTAuMTQpIj4NCiAgICAgICA8dXNlIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTQ4Ii8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICA8L2c+DQogICAgPGcgaWQ9Inl0aWNrXzIiPg0KICAgICA8ZyBpZD0ibGluZTJkXzIwIj4NCiAgICAgIDxwYXRoIGNsaXAtcGF0aD0idXJsKCNwOTZjNzI0MTg1MykiIGQ9Ik0gMTY2LjAyNTU3OCAxNDcuMTU5MzMzIA0KTCA2NDUuNTI3MjMgMTQ3LjE1OTMzMyANCiIgc3R5bGU9ImZpbGw6bm9uZTtzdHJva2U6I2IwYjBiMDtzdHJva2UtbGluZWNhcDpzcXVhcmU7c3Ryb2tlLXdpZHRoOjAuODsiLz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0ibGluZTJkXzIxIj4NCiAgICAgIDxnPg0KICAgICAgIDx1c2Ugc3R5bGU9InN0cm9rZTojMDAwMDAwO3N0cm9rZS13aWR0aDowLjg7IiB4PSIxNjYuMDI1NTc4IiB4bGluazpocmVmPSIjbWUxODQ5YjQwNTAiIHk9IjE0Ny4xNTkzMzMiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0idGV4dF8xMSI+DQogICAgICA8IS0tIDIgLS0+DQogICAgICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNTAuMTE4MDc4IDE1Mi40NzgyMzkpc2NhbGUoMC4xNCAtMC4xNCkiPg0KICAgICAgIDx1c2UgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNTAiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgIDwvZz4NCiAgICA8ZyBpZD0ieXRpY2tfMyI+DQogICAgIDxnIGlkPSJsaW5lMmRfMjIiPg0KICAgICAgPHBhdGggY2xpcC1wYXRoPSJ1cmwoI3A5NmM3MjQxODUzKSIgZD0iTSAxNjYuMDI1NTc4IDEwOS44NTk4NjQgDQpMIDY0NS41MjcyMyAxMDkuODU5ODY0IA0KIiBzdHlsZT0iZmlsbDpub25lO3N0cm9rZTojYjBiMGIwO3N0cm9rZS1saW5lY2FwOnNxdWFyZTtzdHJva2Utd2lkdGg6MC44OyIvPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJsaW5lMmRfMjMiPg0KICAgICAgPGc+DQogICAgICAgPHVzZSBzdHlsZT0ic3Ryb2tlOiMwMDAwMDA7c3Ryb2tlLXdpZHRoOjAuODsiIHg9IjE2Ni4wMjU1NzgiIHhsaW5rOmhyZWY9IiNtZTE4NDliNDA1MCIgeT0iMTA5Ljg1OTg2NCIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJ0ZXh0XzEyIj4NCiAgICAgIDwhLS0gNCAtLT4NCiAgICAgIDxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1MC4xMTgwNzggMTE1LjE3ODc3MSlzY2FsZSgwLjE0IC0wLjE0KSI+DQogICAgICAgPHVzZSB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy01MiIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgPC9nPg0KICAgIDxnIGlkPSJ5dGlja180Ij4NCiAgICAgPGcgaWQ9ImxpbmUyZF8yNCI+DQogICAgICA8cGF0aCBjbGlwLXBhdGg9InVybCgjcDk2YzcyNDE4NTMpIiBkPSJNIDE2Ni4wMjU1NzggNzIuNTYwMzk2IA0KTCA2NDUuNTI3MjMgNzIuNTYwMzk2IA0KIiBzdHlsZT0iZmlsbDpub25lO3N0cm9rZTojYjBiMGIwO3N0cm9rZS1saW5lY2FwOnNxdWFyZTtzdHJva2Utd2lkdGg6MC44OyIvPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJsaW5lMmRfMjUiPg0KICAgICAgPGc+DQogICAgICAgPHVzZSBzdHlsZT0ic3Ryb2tlOiMwMDAwMDA7c3Ryb2tlLXdpZHRoOjAuODsiIHg9IjE2Ni4wMjU1NzgiIHhsaW5rOmhyZWY9IiNtZTE4NDliNDA1MCIgeT0iNzIuNTYwMzk2Ii8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9InRleHRfMTMiPg0KICAgICAgPCEtLSA2IC0tPg0KICAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTUwLjExODA3OCA3Ny44NzkzMDIpc2NhbGUoMC4xNCAtMC4xNCkiPg0KICAgICAgIDx1c2UgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNTQiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgIDwvZz4NCiAgICA8ZyBpZD0ieXRpY2tfNSI+DQogICAgIDxnIGlkPSJsaW5lMmRfMjYiPg0KICAgICAgPHBhdGggY2xpcC1wYXRoPSJ1cmwoI3A5NmM3MjQxODUzKSIgZD0iTSAxNjYuMDI1NTc4IDM1LjI2MDkyOCANCkwgNjQ1LjUyNzIzIDM1LjI2MDkyOCANCiIgc3R5bGU9ImZpbGw6bm9uZTtzdHJva2U6I2IwYjBiMDtzdHJva2UtbGluZWNhcDpzcXVhcmU7c3Ryb2tlLXdpZHRoOjAuODsiLz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0ibGluZTJkXzI3Ij4NCiAgICAgIDxnPg0KICAgICAgIDx1c2Ugc3R5bGU9InN0cm9rZTojMDAwMDAwO3N0cm9rZS13aWR0aDowLjg7IiB4PSIxNjYuMDI1NTc4IiB4bGluazpocmVmPSIjbWUxODQ5YjQwNTAiIHk9IjM1LjI2MDkyOCIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJ0ZXh0XzE0Ij4NCiAgICAgIDwhLS0gOCAtLT4NCiAgICAgIDxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1MC4xMTgwNzggNDAuNTc5ODM0KXNjYWxlKDAuMTQgLTAuMTQpIj4NCiAgICAgICA8dXNlIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTU2Ii8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICA8L2c+DQogICAgPGcgaWQ9InRleHRfMTUiPg0KICAgICA8IS0tICRcZ2FtbWEkIC0tPg0KICAgICA8ZGVmcz4NCiAgICAgIDxwYXRoIGQ9Ik0gMjMuMjk2ODc1IDQ2LjA5Mzc1IA0KTCAyOC43MTg3NSAxMi4zMTI1IA0KTCA1NCA1NC42ODc1IA0KTCA2My41MzEyNSA1NC42ODc1IA0KTCAzMC44MTI1IDAgDQpMIDI2Ljc2NTYyNSAtMjAuNzk2ODc1IA0KTCAxNy43ODEyNSAtMjAuNzk2ODc1IA0KTCAyMS44MjgxMjUgMCANCkwgMTUuNDM3NSA0MC44MjgxMjUgDQpRIDE0LjQ1MzEyNSA0Ni45Njg3NSA5LjgxMjUgNDYuOTY4NzUgDQpMIDcuNDIxODc1IDQ2Ljk2ODc1IA0KTCA4Ljg5MDYyNSA1NC42ODc1IA0KTCAxMi4zMTI1IDU0LjY4NzUgDQpRIDIxLjkyMTg3NSA1NC42ODc1IDIzLjI5Njg3NSA0Ni4wOTM3NSANCnoNCiIgaWQ9IkRlamFWdVNhbnMtT2JsaXF1ZS05NDciLz4NCiAgICAgPC9kZWZzPg0KICAgICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMuMTc4MDc4IDEwOC43NDE4NTkpcm90YXRlKC05MClzY2FsZSgwLjE0IC0wLjE0KSI+DQogICAgICA8dXNlIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAgMC4zMTI1KSIgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtT2JsaXF1ZS05NDciLz4NCiAgICAgPC9nPg0KICAgIDwvZz4NCiAgIDwvZz4NCiAgIDxnIGlkPSJwYXRjaF8zIj4NCiAgICA8cGF0aCBkPSJNIDE2Ni4wMjU1NzggMTg0LjQ1ODgwMSANCkwgMTY2LjAyNTU3OCAyNC42MjQ5MTcgDQoiIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlOiMwMDAwMDA7c3Ryb2tlLWxpbmVjYXA6c3F1YXJlO3N0cm9rZS1saW5lam9pbjptaXRlcjtzdHJva2Utd2lkdGg6MC44OyIvPg0KICAgPC9nPg0KICAgPGcgaWQ9InBhdGNoXzQiPg0KICAgIDxwYXRoIGQ9Ik0gMTY2LjAyNTU3OCAxODQuNDU4ODAxIA0KTCA2NDUuNTI3MjMgMTg0LjQ1ODgwMSANCiIgc3R5bGU9ImZpbGw6bm9uZTtzdHJva2U6IzAwMDAwMDtzdHJva2UtbGluZWNhcDpzcXVhcmU7c3Ryb2tlLWxpbmVqb2luOm1pdGVyO3N0cm9rZS13aWR0aDowLjg7Ii8+DQogICA8L2c+DQogICA8ZyBpZD0idGV4dF8xNiI+DQogICAgPCEtLSBBIC0tPg0KICAgIDxkZWZzPg0KICAgICA8cGF0aCBkPSJNIDUzLjQyMTg3NSAxMy4yODEyNSANCkwgMjQuMDMxMjUgMTMuMjgxMjUgDQpMIDE5LjM5MDYyNSAwIA0KTCAwLjQ4NDM3NSAwIA0KTCAyNy40ODQzNzUgNzIuOTA2MjUgDQpMIDQ5LjkwNjI1IDcyLjkwNjI1IA0KTCA3Ni45MDYyNSAwIA0KTCA1OC4wMTU2MjUgMCANCnoNCk0gMjguNzE4NzUgMjYuODEyNSANCkwgNDguNjg3NSAyNi44MTI1IA0KTCAzOC43MTg3NSA1NS44MTI1IA0Keg0KIiBpZD0iRGVqYVZ1U2Fucy1Cb2xkLTY1Ii8+DQogICAgPC9kZWZzPg0KICAgIDxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0LjQgMjguNjU2NTYzKXNjYWxlKDAuMTggLTAuMTgpIj4NCiAgICAgPHVzZSB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy1Cb2xkLTY1Ii8+DQogICAgPC9nPg0KICAgPC9nPg0KICA8L2c+DQogIDxnIGlkPSJheGVzXzIiPg0KICAgPGcgaWQ9InBhdGNoXzUiPg0KICAgIDxwYXRoIGQ9Ik0gMTY2LjAyNTU3OCAzOTIuMjQyODUgDQpMIDY0NS41MjcyMyAzOTIuMjQyODUgDQpMIDY0NS41MjcyMyAyMzIuNDA4OTY2IA0KTCAxNjYuMDI1NTc4IDIzMi40MDg5NjYgDQp6DQoiIHN0eWxlPSJmaWxsOiNmZmZmZmY7Ii8+DQogICA8L2c+DQogICA8ZyBpZD0iUG9seUNvbGxlY3Rpb25fMSI+DQogICAgPGRlZnM+DQogICAgIDxwYXRoIGQ9Ik0gMTg4LjQwMjMyMiAtMjA2LjAzMzg4NCANCkwgMTg4LjQwMjMyMiAtMjA2LjAzMzg4NCANCkwgMTg4LjU2MjE1NiAtMjA2LjAzMzg4NCANCkwgMTg4LjcyMTk5IC0yMDYuMDMzODg0IA0KTCAxODguODgxODI0IC0yMDYuMDMzODg0IA0KTCAxODkuMDQxNjU3IC0yMDYuMDMzODg0IA0KTCAxODkuMjAxNDkxIC0yMDYuMDMzODg0IA0KTCAxODkuMzYxMzI1IC0yMDYuMDMzODg0IA0KTCAxODkuNTIxMTU5IC0yMDYuMDMzODg0IA0KTCAxODkuNjgwOTkzIC0yMDYuMDMzODg0IA0KTCAxODkuODQwODI3IC0yMDYuMDMzODg0IA0KTCAxOTAuMDAwNjYxIC0yMDYuMDMzODg0IA0KTCAxOTAuMTYwNDk1IC0yMDYuMDMzODg0IA0KTCAxOTAuMzIwMzI4IC0yMDYuMDMzODg0IA0KTCAxOTAuNDgwMTYyIC0yMDYuMDMzODg0IA0KTCAxOTAuNjM5OTk2IC0yMDYuMDMzODg0IA0KTCAxOTAuNzk5ODMgLTIwNi4wMzM4ODQgDQpMIDE5MC45NTk2NjQgLTIwNi4wMzM4ODQgDQpMIDE5MS4xMTk0OTggLTIwNi4wMzM4ODQgDQpMIDE5MS4yNzkzMzIgLTIwNi4wMzM4ODQgDQpMIDE5MS40MzkxNjYgLTIwNi4wMzM4ODQgDQpMIDE5MS41OTkgLTIwNi4wMzM4ODQgDQpMIDE5MS43NTg4MzMgLTIwNi4wMzM4ODQgDQpMIDE5MS45MTg2NjcgLTIwNi4wMzM4ODQgDQpMIDE5Mi4wNzg1MDEgLTIwNi4wMzM4ODQgDQpMIDE5Mi4yMzgzMzUgLTIwNi4wMzM4ODQgDQpMIDE5Mi4zOTgxNjkgLTIwNi4wMzM4ODQgDQpMIDE5Mi41NTgwMDMgLTIwNi4wMzM4ODQgDQpMIDE5Mi43MTc4MzcgLTIwNi4wMzM4ODQgDQpMIDE5Mi44Nzc2NzEgLTIwNi4wMzM4ODQgDQpMIDE5My4wMzc1MDQgLTIwNi4wMzM4ODQgDQpMIDE5My4xOTczMzggLTIwNi4wMzM4ODQgDQpMIDE5My4zNTcxNzIgLTIwNi4wMzM4ODQgDQpMIDE5My41MTcwMDYgLTIwNi4wMzM4ODQgDQpMIDE5My42NzY4NCAtMjA2LjAzMzg4NCANCkwgMTkzLjgzNjY3NCAtMjA2LjAzMzg4NCANCkwgMTkzLjk5NjUwOCAtMjA2LjAzMzg4NCANCkwgMTk0LjE1NjM0MiAtMjA2LjAzMzg4NCANCkwgMTk0LjMxNjE3NiAtMjA2LjAzMzg4NCANCkwgMTk0LjQ3NjAwOSAtMjA2LjAzMzg4NCANCkwgMTk0LjYzNTg0MyAtMjA2LjAzMzg4NCANCkwgMTk0Ljc5NTY3NyAtMjA2LjAzMzg4NCANCkwgMTk0Ljk1NTUxMSAtMjA2LjAzMzg4NCANCkwgMTk1LjExNTM0NSAtMjA2LjAzMzg4NCANCkwgMTk1LjI3NTE3OSAtMjA2LjAzMzg4NCANCkwgMTk1LjQzNTAxMyAtMjA2LjAzMzg4NCANCkwgMTk1LjU5NDg0NyAtMjA2LjAzMzg4NCANCkwgMTk1Ljc1NDY4MSAtMjA2LjAzMzg4NCANCkwgMTk1LjkxNDUxNCAtMjA2LjAzMzg4NCANCkwgMTk2LjA3NDM0OCAtMjA2LjAzMzg4NCANCkwgMTk2LjIzNDE4MiAtMjA2LjAzMzg4NCANCkwgMTk2LjM5NDAxNiAtMjA2LjAzMzg4NCANCkwgMTk2LjU1Mzg1IC0yMDYuMDMzODg0IA0KTCAxOTYuNzEzNjg0IC0yMDYuMDMzODg0IA0KTCAxOTYuODczNTE4IC0yMDYuMDMzODg0IA0KTCAxOTcuMDMzMzUyIC0yMDYuMDMzODg0IA0KTCAxOTcuMTkzMTg1IC0yMDYuMDMzODg0IA0KTCAxOTcuMzUzMDE5IC0yMDYuMDMzODg0IA0KTCAxOTcuNTEyODUzIC0yMDYuMDMzODg0IA0KTCAxOTcuNjcyNjg3IC0yMDYuMDMzODg0IA0KTCAxOTcuODMyNTIxIC0yMDYuMDMzODg0IA0KTCAxOTcuOTkyMzU1IC0yMDYuMDMzODg0IA0KTCAxOTguMTUyMTg5IC0yMDYuMDMzODg0IA0KTCAxOTguMzEyMDIzIC0yMDYuMDMzODg0IA0KTCAxOTguNDcxODU3IC0yMDYuMDMzODg0IA0KTCAxOTguNjMxNjkgLTIwNi4wMzM4ODQgDQpMIDE5OC43OTE1MjQgLTIwNi4wMzM4ODQgDQpMIDE5OC45NTEzNTggLTIwNi4wMzM4ODQgDQpMIDE5OS4xMTExOTIgLTIwNi4wMzM4ODQgDQpMIDE5OS4yNzEwMjYgLTIwNi4wMzM4ODQgDQpMIDE5OS40MzA4NiAtMjA2LjAzMzg4NCANCkwgMTk5LjU5MDY5NCAtMjA2LjAzMzg4NCANCkwgMTk5Ljc1MDUyOCAtMjA2LjAzMzg4NCANCkwgMTk5LjkxMDM2MSAtMjA2LjAzMzg4NCANCkwgMjAwLjA3MDE5NSAtMjA2LjAzMzg4NCANCkwgMjAwLjIzMDAyOSAtMjA2LjAzMzg4NCANCkwgMjAwLjM4OTg2MyAtMjA2LjAzMzg4NCANCkwgMjAwLjU0OTY5NyAtMjA2LjAzMzg4NCANCkwgMjAwLjcwOTUzMSAtMjA2LjAzMzg4NCANCkwgMjAwLjg2OTM2NSAtMjA2LjAzMzg4NCANCkwgMjAxLjAyOTE5OSAtMjA2LjAzMzg4NCANCkwgMjAxLjE4OTAzMyAtMjA2LjAzMzg4NCANCkwgMjAxLjM0ODg2NiAtMjA2LjAzMzg4NCANCkwgMjAxLjUwODcgLTIwNi4wMzM4ODQgDQpMIDIwMS42Njg1MzQgLTIwNi4wMzM4ODQgDQpMIDIwMS44MjgzNjggLTIwNi4wMzM4ODQgDQpMIDIwMS45ODgyMDIgLTIwNi4wMzM4ODQgDQpMIDIwMi4xNDgwMzYgLTIwNi4wMzM4ODQgDQpMIDIwMi4zMDc4NyAtMjA2LjAzMzg4NCANCkwgMjAyLjQ2NzcwNCAtMjA2LjAzMzg4NCANCkwgMjAyLjYyNzUzOCAtMjA2LjAzMzg4NCANCkwgMjAyLjc4NzM3MSAtMjA2LjAzMzg4NCANCkwgMjAyLjk0NzIwNSAtMjA2LjAzMzg4NCANCkwgMjAzLjEwNzAzOSAtMjA2LjAzMzg4NCANCkwgMjAzLjI2Njg3MyAtMjA2LjAzMzg4NCANCkwgMjAzLjQyNjcwNyAtMjA2LjAzMzg4NCANCkwgMjAzLjU4NjU0MSAtMjA2LjAzMzg4NCANCkwgMjAzLjc0NjM3NSAtMjA2LjAzMzg4NCANCkwgMjAzLjkwNjIwOSAtMjA2LjAzMzg4NCANCkwgMjA0LjA2NjA0MiAtMjA2LjAzMzg4NCANCkwgMjA0LjIyNTg3NiAtMjA2LjAzMzg4NCANCkwgMjA0LjM4NTcxIC0yMDYuMDMzODg0IA0KTCAyMDQuNTQ1NTQ0IC0yMDYuMDMzODg0IA0KTCAyMDQuNzA1Mzc4IC0yMDYuMDMzODg0IA0KTCAyMDQuODY1MjEyIC0yMDYuMDMzODg0IA0KTCAyMDUuMDI1MDQ2IC0yMDYuMDMzODg0IA0KTCAyMDUuMTg0ODggLTIwNi4wMzM4ODQgDQpMIDIwNS4zNDQ3MTQgLTIwNi4wMzM4ODQgDQpMIDIwNS41MDQ1NDcgLTIwNi4wMzM4ODQgDQpMIDIwNS42NjQzODEgLTIwNi4wMzM4ODQgDQpMIDIwNS44MjQyMTUgLTIwNi4wMzM4ODQgDQpMIDIwNS45ODQwNDkgLTIwNi4wMzM4ODQgDQpMIDIwNi4xNDM4ODMgLTIwNi4wMzM4ODQgDQpMIDIwNi4zMDM3MTcgLTIwNi4wMzM4ODQgDQpMIDIwNi40NjM1NTEgLTIwNi4wMzM4ODQgDQpMIDIwNi42MjMzODUgLTIwNi4wMzM4ODQgDQpMIDIwNi43ODMyMTggLTIwNi4wMzM4ODQgDQpMIDIwNi45NDMwNTIgLTIwNi4wMzM4ODQgDQpMIDIwNy4xMDI4ODYgLTIwNi4wMzM4ODQgDQpMIDIwNy4yNjI3MiAtMjA2LjAzMzg4NCANCkwgMjA3LjQyMjU1NCAtMjA2LjAzMzg4NCANCkwgMjA3LjU4MjM4OCAtMjA2LjAzMzg4NCANCkwgMjA3Ljc0MjIyMiAtMjA2LjAzMzg4NCANCkwgMjA3LjkwMjA1NiAtMjA2LjAzMzg4NCANCkwgMjA4LjA2MTg5IC0yMDYuMDMzODg0IA0KTCAyMDguMjIxNzIzIC0yMDYuMDMzODg0IA0KTCAyMDguMzgxNTU3IC0yMDYuMDMzODg0IA0KTCAyMDguNTQxMzkxIC0yMDYuMDMzODg0IA0KTCAyMDguNzAxMjI1IC0yMDYuMDMzODg0IA0KTCAyMDguODYxMDU5IC0yMDYuMDMzODg0IA0KTCAyMDkuMDIwODkzIC0yMDYuMDMzODg0IA0KTCAyMDkuMTgwNzI3IC0yMDYuMDMzODg0IA0KTCAyMDkuMzQwNTYxIC0yMDYuMDMzODg0IA0KTCAyMDkuNTAwMzk1IC0yMDYuMDMzODg0IA0KTCAyMDkuNjYwMjI4IC0yMDYuMDMzODg0IA0KTCAyMDkuODIwMDYyIC0yMDYuMDMzODg0IA0KTCAyMDkuOTc5ODk2IC0yMDYuMDMzODg0IA0KTCAyMTAuMTM5NzMgLTIwNi4wMzM4ODQgDQpMIDIxMC4yOTk1NjQgLTIwNi4wMzM4ODQgDQpMIDIxMC40NTkzOTggLTIwNi4wMzM4ODQgDQpMIDIxMC42MTkyMzIgLTIwNi4wMzM4ODQgDQpMIDIxMC43NzkwNjYgLTIwNi4wMzM4ODQgDQpMIDIxMC45Mzg4OTkgLTIwNi4wMzM4ODQgDQpMIDIxMS4wOTg3MzMgLTIwNi4wMzM4ODQgDQpMIDIxMS4yNTg1NjcgLTIwNi4wMzM4ODQgDQpMIDIxMS40MTg0MDEgLTIwNi4wMzM4ODQgDQpMIDIxMS41NzgyMzUgLTIwNi4wMzM4ODQgDQpMIDIxMS43MzgwNjkgLTIwNi4wMzM4ODQgDQpMIDIxMS44OTc5MDMgLTIwNi4wMzM4ODQgDQpMIDIxMi4wNTc3MzcgLTIwNi4wMzM4ODQgDQpMIDIxMi4yMTc1NzEgLTIwNi4wMzM4ODQgDQpMIDIxMi4zNzc0MDQgLTIwNi4wMzM4ODQgDQpMIDIxMi41MzcyMzggLTIwNi4wMzM4ODQgDQpMIDIxMi42OTcwNzIgLTIwNi4wMzM4ODQgDQpMIDIxMi44NTY5MDYgLTIwNi4wMzM4ODQgDQpMIDIxMy4wMTY3NCAtMjA2LjAzMzg4NCANCkwgMjEzLjE3NjU3NCAtMjA2LjAzMzg4NCANCkwgMjEzLjMzNjQwOCAtMjA2LjAzMzg4NCANCkwgMjEzLjQ5NjI0MiAtMjA2LjAzMzg4NCANCkwgMjEzLjY1NjA3NiAtMjA2LjAzMzg4NCANCkwgMjEzLjgxNTkwOSAtMjA2LjAzMzg4NCANCkwgMjEzLjk3NTc0MyAtMjA2LjAzMzg4NCANCkwgMjE0LjEzNTU3NyAtMjA2LjAzMzg4NCANCkwgMjE0LjI5NTQxMSAtMjA2LjAzMzg4NCANCkwgMjE0LjQ1NTI0NSAtMjA2LjAzMzg4NCANCkwgMjE0LjYxNTA3OSAtMjA2LjAzMzg4NCANCkwgMjE0Ljc3NDkxMyAtMjA2LjAzMzg4NCANCkwgMjE0LjkzNDc0NyAtMjA2LjAzMzg4NCANCkwgMjE1LjA5NDU4IC0yMDYuMDMzODg0IA0KTCAyMTUuMjU0NDE0IC0yMDYuMDMzODg0IA0KTCAyMTUuNDE0MjQ4IC0yMDYuMDMzODg0IA0KTCAyMTUuNTc0MDgyIC0yMDYuMDMzODg0IA0KTCAyMTUuNzMzOTE2IC0yMDYuMDMzODg0IA0KTCAyMTUuODkzNzUgLTIwNi4wMzM4ODQgDQpMIDIxNi4wNTM1ODQgLTIwNi4wMzM4ODQgDQpMIDIxNi4yMTM0MTggLTIwNi4wMzM4ODQgDQpMIDIxNi4zNzMyNTIgLTIwNi4wMzM4ODQgDQpMIDIxNi41MzMwODUgLTIwNi4wMzM4ODQgDQpMIDIxNi42OTI5MTkgLTIwNi4wMzM4ODQgDQpMIDIxNi44NTI3NTMgLTIwNi4wMzM4ODQgDQpMIDIxNy4wMTI1ODcgLTIwNi4wMzM4ODQgDQpMIDIxNy4xNzI0MjEgLTIwNi4wMzM4ODQgDQpMIDIxNy4zMzIyNTUgLTIwNi4wMzM4ODQgDQpMIDIxNy40OTIwODkgLTIwNi4wMzM4ODQgDQpMIDIxNy42NTE5MjMgLTIwNi4wMzM4ODQgDQpMIDIxNy44MTE3NTYgLTIwNi4wMzM4ODQgDQpMIDIxNy45NzE1OSAtMjA2LjAzMzg4NCANCkwgMjE4LjEzMTQyNCAtMjA2LjAzMzg4NCANCkwgMjE4LjI5MTI1OCAtMjA2LjAzMzg4NCANCkwgMjE4LjQ1MTA5MiAtMjA2LjAzMzg4NCANCkwgMjE4LjYxMDkyNiAtMjA2LjAzMzg4NCANCkwgMjE4Ljc3MDc2IC0yMDYuMDMzODg0IA0KTCAyMTguOTMwNTk0IC0yMDYuMDMzODg0IA0KTCAyMTkuMDkwNDI4IC0yMDYuMDMzODg0IA0KTCAyMTkuMjUwMjYxIC0yMDYuMDMzODg0IA0KTCAyMTkuNDEwMDk1IC0yMDYuMDMzODg0IA0KTCAyMTkuNTY5OTI5IC0yMDYuMDMzODg0IA0KTCAyMTkuNzI5NzYzIC0yMDYuMDMzODg0IA0KTCAyMTkuODg5NTk3IC0yMDYuMDMzODg0IA0KTCAyMjAuMDQ5NDMxIC0yMDYuMDMzODg0IA0KTCAyMjAuMjA5MjY1IC0yMDYuMDMzODg0IA0KTCAyMjAuMzY5MDk5IC0yMDYuMDMzODg0IA0KTCAyMjAuNTI4OTMzIC0yMDYuMDMzODg0IA0KTCAyMjAuNjg4NzY2IC0yMDYuMDMzODg0IA0KTCAyMjAuODQ4NiAtMjA2LjAzMzg4NCANCkwgMjIxLjAwODQzNCAtMjA2LjAzMzg4NCANCkwgMjIxLjE2ODI2OCAtMjA2LjAzMzg4NCANCkwgMjIxLjMyODEwMiAtMjA2LjAzMzg4NCANCkwgMjIxLjQ4NzkzNiAtMjA2LjAzMzg4NCANCkwgMjIxLjY0Nzc3IC0yMDYuMDMzODg0IA0KTCAyMjEuODA3NjA0IC0yMDYuMDMzODg0IA0KTCAyMjEuOTY3NDM3IC0yMDYuMDMzODg0IA0KTCAyMjIuMTI3MjcxIC0yMDYuMDMzODg0IA0KTCAyMjIuMjg3MTA1IC0yMDYuMDMzODg0IA0KTCAyMjIuNDQ2OTM5IC0yMDYuMDMzODg0IA0KTCAyMjIuNjA2NzczIC0yMDYuMDMzODg0IA0KTCAyMjIuNzY2NjA3IC0yMDYuMDMzODg0IA0KTCAyMjIuOTI2NDQxIC0yMDYuMDMzODg0IA0KTCAyMjMuMDg2Mjc1IC0yMDYuMDMzODg0IA0KTCAyMjMuMjQ2MTA5IC0yMDYuMDMzODg0IA0KTCAyMjMuNDA1OTQyIC0yMDYuMDMzODg0IA0KTCAyMjMuNTY1Nzc2IC0yMDYuMDMzODg0IA0KTCAyMjMuNzI1NjEgLTIwNi4wMzM4ODQgDQpMIDIyMy44ODU0NDQgLTIwNi4wMzM4ODQgDQpMIDIyNC4wNDUyNzggLTIwNi4wMzM4ODQgDQpMIDIyNC4yMDUxMTIgLTIwNi4wMzM4ODQgDQpMIDIyNC4zNjQ5NDYgLTIwNi4wMzM4ODQgDQpMIDIyNC41MjQ3OCAtMjA2LjAzMzg4NCANCkwgMjI0LjY4NDYxMyAtMjA2LjAzMzg4NCANCkwgMjI0Ljg0NDQ0NyAtMjA2LjAzMzg4NCANCkwgMjI1LjAwNDI4MSAtMjA2LjAzMzg4NCANCkwgMjI1LjE2NDExNSAtMjA2LjAzMzg4NCANCkwgMjI1LjMyMzk0OSAtMjA2LjAzMzg4NCANCkwgMjI1LjQ4Mzc4MyAtMjA2LjAzMzg4NCANCkwgMjI1LjY0MzYxNyAtMjA2LjAzMzg4NCANCkwgMjI1LjgwMzQ1MSAtMjA2LjAzMzg4NCANCkwgMjI1Ljk2MzI4NSAtMjA2LjAzMzg4NCANCkwgMjI2LjEyMzExOCAtMjA2LjAzMzg4NCANCkwgMjI2LjI4Mjk1MiAtMjA2LjAzMzg4NCANCkwgMjI2LjQ0Mjc4NiAtMjA2LjAzMzg4NCANCkwgMjI2LjYwMjYyIC0yMDYuMDMzODg0IA0KTCAyMjYuNzYyNDU0IC0yMDYuMDMzODg0IA0KTCAyMjYuOTIyMjg4IC0yMDYuMDMzODg0IA0KTCAyMjcuMDgyMTIyIC0yMDYuMDMzODg0IA0KTCAyMjcuMjQxOTU2IC0yMDYuMDMzODg0IA0KTCAyMjcuNDAxNzkgLTIwNi4wMzM4ODQgDQpMIDIyNy41NjE2MjMgLTIwNi4wMzM4ODQgDQpMIDIyNy43MjE0NTcgLTIwNi4wMzM4ODQgDQpMIDIyNy44ODEyOTEgLTIwNi4wMzM4ODQgDQpMIDIyOC4wNDExMjUgLTIwNi4wMzM4ODQgDQpMIDIyOC4yMDA5NTkgLTIwNi4wMzM4ODQgDQpMIDIyOC4zNjA3OTMgLTIwNi4wMzM4ODQgDQpMIDIyOC41MjA2MjcgLTIwNi4wMzM4ODQgDQpMIDIyOC42ODA0NjEgLTIwNi4wMzM4ODQgDQpMIDIyOC44NDAyOTQgLTIwNi4wMzM4ODQgDQpMIDIyOS4wMDAxMjggLTIwNi4wMzM4ODQgDQpMIDIyOS4xNTk5NjIgLTIwNi4wMzM4ODQgDQpMIDIyOS4zMTk3OTYgLTIwNi4wMzM4ODQgDQpMIDIyOS40Nzk2MyAtMjA2LjAzMzg4NCANCkwgMjI5LjYzOTQ2NCAtMjA2LjAzMzg4NCANCkwgMjI5Ljc5OTI5OCAtMjA2LjAzMzg4NCANCkwgMjI5Ljk1OTEzMiAtMjA2LjAzMzg4NCANCkwgMjMwLjExODk2NiAtMjA2LjAzMzg4NCANCkwgMjMwLjI3ODc5OSAtMjA2LjAzMzg4NCANCkwgMjMwLjQzODYzMyAtMjA2LjAzMzg4NCANCkwgMjMwLjU5ODQ2NyAtMjA2LjAzMzg4NCANCkwgMjMwLjc1ODMwMSAtMjA2LjAzMzg4NCANCkwgMjMwLjkxODEzNSAtMjA2LjAzMzg4NCANCkwgMjMxLjA3Nzk2OSAtMjA2LjAzMzg4NCANCkwgMjMxLjIzNzgwMyAtMjA2LjAzMzg4NCANCkwgMjMxLjM5NzYzNyAtMjA2LjAzMzg4NCANCkwgMjMxLjU1NzQ3MSAtMjA2LjAzMzg4NCANCkwgMjMxLjcxNzMwNCAtMjA2LjAzMzg4NCANCkwgMjMxLjg3NzEzOCAtMjA2LjAzMzg4NCANCkwgMjMyLjAzNjk3MiAtMjA2LjAzMzg4NCANCkwgMjMyLjE5NjgwNiAtMjA2LjAzMzg4NCANCkwgMjMyLjM1NjY0IC0yMDYuMDMzODg0IA0KTCAyMzIuNTE2NDc0IC0yMDYuMDMzODg0IA0KTCAyMzIuNjc2MzA4IC0yMDYuMDMzODg0IA0KTCAyMzIuODM2MTQyIC0yMDYuMDMzODg0IA0KTCAyMzIuOTk1OTc1IC0yMDYuMDMzODg0IA0KTCAyMzMuMTU1ODA5IC0yMDYuMDMzODg0IA0KTCAyMzMuMzE1NjQzIC0yMDYuMDMzODg0IA0KTCAyMzMuNDc1NDc3IC0yMDYuMDMzODg0IA0KTCAyMzMuNjM1MzExIC0yMDYuMDMzODg0IA0KTCAyMzMuNzk1MTQ1IC0yMDYuMDMzODg0IA0KTCAyMzMuOTU0OTc5IC0yMDYuMDMzODg0IA0KTCAyMzQuMTE0ODEzIC0yMDYuMDMzODg0IA0KTCAyMzQuMjc0NjQ3IC0yMDYuMDMzODg0IA0KTCAyMzQuNDM0NDggLTIwNi4wMzM4ODQgDQpMIDIzNC41OTQzMTQgLTIwNi4wMzM4ODQgDQpMIDIzNC43NTQxNDggLTIwNi4wMzM4ODQgDQpMIDIzNC45MTM5ODIgLTIwNi4wMzM4ODQgDQpMIDIzNS4wNzM4MTYgLTIwNi4wMzM4ODQgDQpMIDIzNS4yMzM2NSAtMjA2LjAzMzg4NCANCkwgMjM1LjM5MzQ4NCAtMjA2LjAzMzg4NCANCkwgMjM1LjU1MzMxOCAtMjA2LjAzMzg4NCANCkwgMjM1LjcxMzE1MSAtMjA2LjAzMzg4NCANCkwgMjM1Ljg3Mjk4NSAtMjA2LjAzMzg4NCANCkwgMjM2LjAzMjgxOSAtMjA2LjAzMzg4NCANCkwgMjM2LjE5MjY1MyAtMjA2LjAzMzg4NCANCkwgMjM2LjM1MjQ4NyAtMjA2LjAzMzg4NCANCkwgMjM2LjUxMjMyMSAtMjA2LjAzMzg4NCANCkwgMjM2LjY3MjE1NSAtMjA2LjAzMzg4NCANCkwgMjM2LjgzMTk4OSAtMjA2LjAzMzg4NCANCkwgMjM2Ljk5MTgyMyAtMjA2LjAzMzg4NCANCkwgMjM3LjE1MTY1NiAtMjA2LjAzMzg4NCANCkwgMjM3LjMxMTQ5IC0yMDYuMDMzODg0IA0KTCAyMzcuNDcxMzI0IC0yMDYuMDMzODg0IA0KTCAyMzcuNjMxMTU4IC0yMDYuMDMzODg0IA0KTCAyMzcuNzkwOTkyIC0yMDYuMDMzODg0IA0KTCAyMzcuOTUwODI2IC0yMDYuMDMzODg0IA0KTCAyMzguMTEwNjYgLTIwNi4wMzM4ODQgDQpMIDIzOC4yNzA0OTQgLTIwNi4wMzM4ODQgDQpMIDIzOC40MzAzMjggLTIwNi4wMzM4ODQgDQpMIDIzOC41OTAxNjEgLTIwNi4wMzM4ODQgDQpMIDIzOC43NDk5OTUgLTIwNi4wMzM4ODQgDQpMIDIzOC45MDk4MjkgLTIwNi4wMzM4ODQgDQpMIDIzOS4wNjk2NjMgLTIwNi4wMzM4ODQgDQpMIDIzOS4yMjk0OTcgLTIwNi4wMzM4ODQgDQpMIDIzOS4zODkzMzEgLTIwNi4wMzM4ODQgDQpMIDIzOS41NDkxNjUgLTIwNi4wMzM4ODQgDQpMIDIzOS43MDg5OTkgLTIwNi4wMzM4ODQgDQpMIDIzOS44Njg4MzIgLTIwNi4wMzM4ODQgDQpMIDI0MC4wMjg2NjYgLTIwNi4wMzM4ODQgDQpMIDI0MC4xODg1IC0yMDYuMDMzODg0IA0KTCAyNDAuMzQ4MzM0IC0yMDYuMDMzODg0IA0KTCAyNDAuNTA4MTY4IC0yMDYuMDMzODg0IA0KTCAyNDAuNjY4MDAyIC0yMDYuMDMzODg0IA0KTCAyNDAuODI3ODM2IC0yMDYuMDMzODg0IA0KTCAyNDAuOTg3NjcgLTIwNi4wMzM4ODQgDQpMIDI0MS4xNDc1MDQgLTIwNi4wMzM4ODQgDQpMIDI0MS4zMDczMzcgLTIwNi4wMzM4ODQgDQpMIDI0MS40NjcxNzEgLTIwNi4wMzM4ODQgDQpMIDI0MS42MjcwMDUgLTIwNi4wMzM4ODQgDQpMIDI0MS43ODY4MzkgLTIwNi4wMzM4ODQgDQpMIDI0MS45NDY2NzMgLTIwNi4wMzM4ODQgDQpMIDI0Mi4xMDY1MDcgLTIwNi4wMzM4ODQgDQpMIDI0Mi4yNjYzNDEgLTIwNi4wMzM4ODQgDQpMIDI0Mi40MjYxNzUgLTIwNi4wMzM4ODQgDQpMIDI0Mi41ODYwMDggLTIwNi4wMzM4ODQgDQpMIDI0Mi43NDU4NDIgLTIwNi4wMzM4ODQgDQpMIDI0Mi45MDU2NzYgLTIwNi4wMzM4ODQgDQpMIDI0My4wNjU1MSAtMjA2LjAzMzg4NCANCkwgMjQzLjIyNTM0NCAtMjA2LjAzMzg4NCANCkwgMjQzLjM4NTE3OCAtMjA2LjAzMzg4NCANCkwgMjQzLjU0NTAxMiAtMjA2LjAzMzg4NCANCkwgMjQzLjcwNDg0NiAtMjA2LjAzMzg4NCANCkwgMjQzLjg2NDY4IC0yMDYuMDMzODg0IA0KTCAyNDQuMDI0NTEzIC0yMDYuMDMzODg0IA0KTCAyNDQuMTg0MzQ3IC0yMDYuMDMzODg0IA0KTCAyNDQuMzQ0MTgxIC0yMDYuMDMzODg0IA0KTCAyNDQuNTA0MDE1IC0yMDYuMDMzODg0IA0KTCAyNDQuNjYzODQ5IC0yMDYuMDMzODg0IA0KTCAyNDQuODIzNjgzIC0yMDYuMDMzODg0IA0KTCAyNDQuOTgzNTE3IC0yMDYuMDMzODg0IA0KTCAyNDUuMTQzMzUxIC0yMDYuMDMzODg0IA0KTCAyNDUuMzAzMTg1IC0yMDYuMDMzODg0IA0KTCAyNDUuNDYzMDE4IC0yMDYuMDMzODg0IA0KTCAyNDUuNjIyODUyIC0yMDYuMDMzODg0IA0KTCAyNDUuNzgyNjg2IC0yMDYuMDMzODg0IA0KTCAyNDUuOTQyNTIgLTIwNi4wMzM4ODQgDQpMIDI0Ni4xMDIzNTQgLTIwNi4wMzM4ODQgDQpMIDI0Ni4yNjIxODggLTIwNi4wMzM4ODQgDQpMIDI0Ni40MjIwMjIgLTIwNi4wMzM4ODQgDQpMIDI0Ni41ODE4NTYgLTIwNi4wMzM4ODQgDQpMIDI0Ni43NDE2ODkgLTIwNi4wMzM4ODQgDQpMIDI0Ni45MDE1MjMgLTIwNi4wMzM4ODQgDQpMIDI0Ny4wNjEzNTcgLTIwNi4wMzM4ODQgDQpMIDI0Ny4yMjExOTEgLTIwNi4wMzM4ODQgDQpMIDI0Ny4zODEwMjUgLTIwNi4wMzM4ODQgDQpMIDI0Ny41NDA4NTkgLTIwNi4wMzM4ODQgDQpMIDI0Ny43MDA2OTMgLTIwNi4wMzM4ODQgDQpMIDI0Ny44NjA1MjcgLTIwNi4wMzM4ODQgDQpMIDI0OC4wMjAzNjEgLTIwNi4wMzM4ODQgDQpMIDI0OC4xODAxOTQgLTIwNi4wMzM4ODQgDQpMIDI0OC4zNDAwMjggLTIwNi4wMzM4ODQgDQpMIDI0OC40OTk4NjIgLTIwNi4wMzM4ODQgDQpMIDI0OC42NTk2OTYgLTIwNi4wMzM4ODQgDQpMIDI0OC44MTk1MyAtMjA2LjAzMzg4NCANCkwgMjQ4Ljk3OTM2NCAtMjA2LjAzMzg4NCANCkwgMjQ5LjEzOTE5OCAtMjA2LjAzMzg4NCANCkwgMjQ5LjI5OTAzMiAtMjA2LjAzMzg4NCANCkwgMjQ5LjQ1ODg2NiAtMjA2LjAzMzg4NCANCkwgMjQ5LjYxODY5OSAtMjA2LjAzMzg4NCANCkwgMjQ5Ljc3ODUzMyAtMjA2LjAzMzg4NCANCkwgMjQ5LjkzODM2NyAtMjA2LjAzMzg4NCANCkwgMjUwLjA5ODIwMSAtMjA2LjAzMzg4NCANCkwgMjUwLjI1ODAzNSAtMjA2LjAzMzg4NCANCkwgMjUwLjQxNzg2OSAtMjA2LjAzMzg4NCANCkwgMjUwLjU3NzcwMyAtMjA2LjAzMzg4NCANCkwgMjUwLjczNzUzNyAtMjA2LjAzMzg4NCANCkwgMjUwLjg5NzM3IC0yMDYuMDMzODg0IA0KTCAyNTEuMDU3MjA0IC0yMDYuMDMzODg0IA0KTCAyNTEuMjE3MDM4IC0yMDYuMDMzODg0IA0KTCAyNTEuMzc2ODcyIC0yMDYuMDMzODg0IA0KTCAyNTEuNTM2NzA2IC0yMDYuMDMzODg0IA0KTCAyNTEuNjk2NTQgLTIwNi4wMzM4ODQgDQpMIDI1MS44NTYzNzQgLTIwNi4wMzM4ODQgDQpMIDI1Mi4wMTYyMDggLTIwNi4wMzM4ODQgDQpMIDI1Mi4xNzYwNDIgLTIwNi4wMzM4ODQgDQpMIDI1Mi4zMzU4NzUgLTIwNi4wMzM4ODQgDQpMIDI1Mi40OTU3MDkgLTIwNi4wMzM4ODQgDQpMIDI1Mi42NTU1NDMgLTIwNi4wMzM4ODQgDQpMIDI1Mi44MTUzNzcgLTIwNi4wMzM4ODQgDQpMIDI1Mi45NzUyMTEgLTIwNi4wMzM4ODQgDQpMIDI1My4xMzUwNDUgLTIwNi4wMzM4ODQgDQpMIDI1My4yOTQ4NzkgLTIwNi4wMzM4ODQgDQpMIDI1My40NTQ3MTMgLTIwNi4wMzM4ODQgDQpMIDI1My42MTQ1NDYgLTIwNi4wMzM4ODQgDQpMIDI1My43NzQzOCAtMjA2LjAzMzg4NCANCkwgMjUzLjkzNDIxNCAtMjA2LjAzMzg4NCANCkwgMjU0LjA5NDA0OCAtMjA2LjAzMzg4NCANCkwgMjU0LjI1Mzg4MiAtMjA2LjAzMzg4NCANCkwgMjU0LjQxMzcxNiAtMjA2LjAzMzg4NCANCkwgMjU0LjU3MzU1IC0yMDYuMDMzODg0IA0KTCAyNTQuNzMzMzg0IC0yMDYuMDMzODg0IA0KTCAyNTQuODkzMjE4IC0yMDYuMDMzODg0IA0KTCAyNTUuMDUzMDUxIC0yMDYuMDMzODg0IA0KTCAyNTUuMjEyODg1IC0yMDYuMDMzODg0IA0KTCAyNTUuMzcyNzE5IC0yMDYuMDMzODg0IA0KTCAyNTUuNTMyNTUzIC0yMDYuMDMzODg0IA0KTCAyNTUuNjkyMzg3IC0yMDYuMDMzODg0IA0KTCAyNTUuODUyMjIxIC0yMDYuMDMzODg0IA0KTCAyNTYuMDEyMDU1IC0yMDYuMDMzODg0IA0KTCAyNTYuMTcxODg5IC0yMDYuMDMzODg0IA0KTCAyNTYuMzMxNzIzIC0yMDYuMDMzODg0IA0KTCAyNTYuNDkxNTU2IC0yMDYuMDMzODg0IA0KTCAyNTYuNjUxMzkgLTIwNi4wMzM4ODQgDQpMIDI1Ni44MTEyMjQgLTIwNi4wMzM4ODQgDQpMIDI1Ni45NzEwNTggLTIwNi4wMzM4ODQgDQpMIDI1Ny4xMzA4OTIgLTIwNi4wMzM4ODQgDQpMIDI1Ny4yOTA3MjYgLTIwNi4wMzM4ODQgDQpMIDI1Ny40NTA1NiAtMjA2LjAzMzg4NCANCkwgMjU3LjYxMDM5NCAtMjA2LjAzMzg4NCANCkwgMjU3Ljc3MDIyNyAtMjA2LjAzMzg4NCANCkwgMjU3LjkzMDA2MSAtMjA2LjAzMzg4NCANCkwgMjU4LjA4OTg5NSAtMjA2LjAzMzg4NCANCkwgMjU4LjI0OTcyOSAtMjA2LjAzMzg4NCANCkwgMjU4LjQwOTU2MyAtMjA2LjAzMzg4NCANCkwgMjU4LjU2OTM5NyAtMjA2LjAzMzg4NCANCkwgMjU4LjcyOTIzMSAtMjA2LjAzMzg4NCANCkwgMjU4Ljg4OTA2NSAtMjA2LjAzMzg4NCANCkwgMjU5LjA0ODg5OSAtMjA2LjAzMzg4NCANCkwgMjU5LjIwODczMiAtMjA2LjAzMzg4NCANCkwgMjU5LjM2ODU2NiAtMjA2LjAzMzg4NCANCkwgMjU5LjUyODQgLTIwNi4wMzM4ODQgDQpMIDI1OS42ODgyMzQgLTIwNi4wMzM4ODQgDQpMIDI1OS44NDgwNjggLTIwNi4wMzM4ODQgDQpMIDI2MC4wMDc5MDIgLTIwNi4wMzM4ODQgDQpMIDI2MC4xNjc3MzYgLTIwNi4wMzM4ODQgDQpMIDI2MC4zMjc1NyAtMjA2LjAzMzg4NCANCkwgMjYwLjQ4NzQwMyAtMjA2LjAzMzg4NCANCkwgMjYwLjY0NzIzNyAtMjA2LjAzMzg4NCANCkwgMjYwLjgwNzA3MSAtMjA2LjAzMzg4NCANCkwgMjYwLjk2NjkwNSAtMjA2LjAzMzg4NCANCkwgMjYxLjEyNjczOSAtMjA2LjAzMzg4NCANCkwgMjYxLjI4NjU3MyAtMjA2LjAzMzg4NCANCkwgMjYxLjQ0NjQwNyAtMjA2LjAzMzg4NCANCkwgMjYxLjYwNjI0MSAtMjA2LjAzMzg4NCANCkwgMjYxLjc2NjA3NSAtMjA2LjAzMzg4NCANCkwgMjYxLjkyNTkwOCAtMjA2LjAzMzg4NCANCkwgMjYyLjA4NTc0MiAtMjA2LjAzMzg4NCANCkwgMjYyLjI0NTU3NiAtMjA2LjAzMzg4NCANCkwgMjYyLjQwNTQxIC0yMDYuMDMzODg0IA0KTCAyNjIuNTY1MjQ0IC0yMDYuMDMzODg0IA0KTCAyNjIuNzI1MDc4IC0yMDYuMDMzODg0IA0KTCAyNjIuODg0OTEyIC0yMDYuMDMzODg0IA0KTCAyNjMuMDQ0NzQ2IC0yMDYuMDMzODg0IA0KTCAyNjMuMjA0NTggLTIwNi4wMzM4ODQgDQpMIDI2My4zNjQ0MTMgLTIwNi4wMzM4ODQgDQpMIDI2My41MjQyNDcgLTIwNi4wMzM4ODQgDQpMIDI2My42ODQwODEgLTIwNi4wMzM4ODQgDQpMIDI2My44NDM5MTUgLTIwNi4wMzM4ODQgDQpMIDI2NC4wMDM3NDkgLTIwNi4wMzM4ODQgDQpMIDI2NC4xNjM1ODMgLTIwNi4wMzM4ODQgDQpMIDI2NC4zMjM0MTcgLTIwNi4wMzM4ODQgDQpMIDI2NC40ODMyNTEgLTIwNi4wMzM4ODQgDQpMIDI2NC42NDMwODQgLTIwNi4wMzM4ODQgDQpMIDI2NC44MDI5MTggLTIwNi4wMzM4ODQgDQpMIDI2NC45NjI3NTIgLTIwNi4wMzM4ODQgDQpMIDI2NS4xMjI1ODYgLTIwNi4wMzM4ODQgDQpMIDI2NS4yODI0MiAtMjA2LjAzMzg4NCANCkwgMjY1LjQ0MjI1NCAtMjA2LjAzMzg4NCANCkwgMjY1LjYwMjA4OCAtMjA2LjAzMzg4NCANCkwgMjY1Ljc2MTkyMiAtMjA2LjAzMzg4NCANCkwgMjY1LjkyMTc1NiAtMjA2LjAzMzg4NCANCkwgMjY2LjA4MTU4OSAtMjA2LjAzMzg4NCANCkwgMjY2LjI0MTQyMyAtMjA2LjAzMzg4NCANCkwgMjY2LjQwMTI1NyAtMjA2LjAzMzg4NCANCkwgMjY2LjU2MTA5MSAtMjA2LjAzMzg4NCANCkwgMjY2LjcyMDkyNSAtMjA2LjAzMzg4NCANCkwgMjY2Ljg4MDc1OSAtMjA2LjAzMzg4NCANCkwgMjY3LjA0MDU5MyAtMjA2LjAzMzg4NCANCkwgMjY3LjIwMDQyNyAtMjA2LjAzMzg4NCANCkwgMjY3LjM2MDI2MSAtMjA2LjAzMzg4NCANCkwgMjY3LjUyMDA5NCAtMjA2LjAzMzg4NCANCkwgMjY3LjY3OTkyOCAtMjA2LjAzMzg4NCANCkwgMjY3LjgzOTc2MiAtMjA2LjAzMzg4NCANCkwgMjY3Ljk5OTU5NiAtMjA2LjAzMzg4NCANCkwgMjY4LjE1OTQzIC0yMDYuMDMzODg0IA0KTCAyNjguMzE5MjY0IC0yMDYuMDMzODg0IA0KTCAyNjguNDc5MDk4IC0yMDYuMDMzODg0IA0KTCAyNjguNjM4OTMyIC0yMDYuMDMzODg0IA0KTCAyNjguNzk4NzY1IC0yMDYuMDMzODg0IA0KTCAyNjguOTU4NTk5IC0yMDYuMDMzODg0IA0KTCAyNjkuMTE4NDMzIC0yMDYuMDMzODg0IA0KTCAyNjkuMjc4MjY3IC0yMDYuMDMzODg0IA0KTCAyNjkuNDM4MTAxIC0yMDYuMDMzODg0IA0KTCAyNjkuNTk3OTM1IC0yMDYuMDMzODg0IA0KTCAyNjkuNzU3NzY5IC0yMDYuMDMzODg0IA0KTCAyNjkuOTE3NjAzIC0yMDYuMDMzODg0IA0KTCAyNzAuMDc3NDM3IC0yMDYuMDMzODg0IA0KTCAyNzAuMjM3MjcgLTIwNi4wMzM4ODQgDQpMIDI3MC4zOTcxMDQgLTIwNi4wMzM4ODQgDQpMIDI3MC41NTY5MzggLTIwNi4wMzM4ODQgDQpMIDI3MC43MTY3NzIgLTIwNi4wMzM4ODQgDQpMIDI3MC44NzY2MDYgLTIwNi4wMzM4ODQgDQpMIDI3MS4wMzY0NCAtMjA2LjAzMzg4NCANCkwgMjcxLjE5NjI3NCAtMjA2LjAzMzg4NCANCkwgMjcxLjM1NjEwOCAtMjA2LjAzMzg4NCANCkwgMjcxLjUxNTk0MSAtMjA2LjAzMzg4NCANCkwgMjcxLjY3NTc3NSAtMjA2LjAzMzg4NCANCkwgMjcxLjgzNTYwOSAtMjA2LjAzMzg4NCANCkwgMjcxLjk5NTQ0MyAtMjA2LjAzMzg4NCANCkwgMjcyLjE1NTI3NyAtMjA2LjAzMzg4NCANCkwgMjcyLjMxNTExMSAtMjA2LjAzMzg4NCANCkwgMjcyLjQ3NDk0NSAtMjA2LjAzMzg4NCANCkwgMjcyLjYzNDc3OSAtMjA2LjAzMzg4NCANCkwgMjcyLjc5NDYxMyAtMjA2LjAzMzg4NCANCkwgMjcyLjk1NDQ0NiAtMjA2LjAzMzg4NCANCkwgMjczLjExNDI4IC0yMDYuMDMzODg0IA0KTCAyNzMuMjc0MTE0IC0yMDYuMDMzODg0IA0KTCAyNzMuNDMzOTQ4IC0yMDYuMDMzODg0IA0KTCAyNzMuNTkzNzgyIC0yMDYuMDMzODg0IA0KTCAyNzMuNzUzNjE2IC0yMDYuMDMzODg0IA0KTCAyNzMuOTEzNDUgLTIwNi4wMzM4ODQgDQpMIDI3NC4wNzMyODQgLTIwNi4wMzM4ODQgDQpMIDI3NC4yMzMxMTggLTIwNi4wMzM4ODQgDQpMIDI3NC4zOTI5NTEgLTIwNi4wMzM4ODQgDQpMIDI3NC41NTI3ODUgLTIwNi4wMzM4ODQgDQpMIDI3NC43MTI2MTkgLTIwNi4wMzM4ODQgDQpMIDI3NC44NzI0NTMgLTIwNi4wMzM4ODQgDQpMIDI3NS4wMzIyODcgLTIwNi4wMzM4ODQgDQpMIDI3NS4xOTIxMjEgLTIwNi4wMzM4ODQgDQpMIDI3NS4zNTE5NTUgLTIwNi4wMzM4ODQgDQpMIDI3NS41MTE3ODkgLTIwNi4wMzM4ODQgDQpMIDI3NS42NzE2MjIgLTIwNi4wMzM4ODQgDQpMIDI3NS44MzE0NTYgLTIwNi4wMzM4ODQgDQpMIDI3NS45OTEyOSAtMjA2LjAzMzg4NCANCkwgMjc2LjE1MTEyNCAtMjA2LjAzMzg4NCANCkwgMjc2LjMxMDk1OCAtMjA2LjAzMzg4NCANCkwgMjc2LjQ3MDc5MiAtMjA2LjAzMzg4NCANCkwgMjc2LjYzMDYyNiAtMjA2LjAzMzg4NCANCkwgMjc2Ljc5MDQ2IC0yMDYuMDMzODg0IA0KTCAyNzYuOTUwMjk0IC0yMDYuMDMzODg0IA0KTCAyNzcuMTEwMTI3IC0yMDYuMDMzODg0IA0KTCAyNzcuMjY5OTYxIC0yMDYuMDMzODg0IA0KTCAyNzcuNDI5Nzk1IC0yMDYuMDMzODg0IA0KTCAyNzcuNTg5NjI5IC0yMDYuMDMzODg0IA0KTCAyNzcuNzQ5NDYzIC0yMDYuMDMzODg0IA0KTCAyNzcuOTA5Mjk3IC0yMDYuMDMzODg0IA0KTCAyNzguMDY5MTMxIC0yMDYuMDMzODg0IA0KTCAyNzguMjI4OTY1IC0yMDYuMDMzODg0IA0KTCAyNzguMzg4Nzk4IC0yMDYuMDMzODg0IA0KTCAyNzguNTQ4NjMyIC0yMDYuMDMzODg0IA0KTCAyNzguNzA4NDY2IC0yMDYuMDMzODg0IA0KTCAyNzguODY4MyAtMjA2LjAzMzg4NCANCkwgMjc5LjAyODEzNCAtMjA2LjAzMzg4NCANCkwgMjc5LjE4Nzk2OCAtMjA2LjAzMzg4NCANCkwgMjc5LjM0NzgwMiAtMjA2LjAzMzg4NCANCkwgMjc5LjUwNzYzNiAtMjA2LjAzMzg4NCANCkwgMjc5LjY2NzQ3IC0yMDYuMDMzODg0IA0KTCAyNzkuODI3MzAzIC0yMDYuMDMzODg0IA0KTCAyNzkuOTg3MTM3IC0yMDYuMDMzODg0IA0KTCAyODAuMTQ2OTcxIC0yMDYuMDMzODg0IA0KTCAyODAuMzA2ODA1IC0yMDYuMDMzODg0IA0KTCAyODAuNDY2NjM5IC0yMDYuMDMzODg0IA0KTCAyODAuNjI2NDczIC0yMDYuMDMzODg0IA0KTCAyODAuNzg2MzA3IC0yMDYuMDMzODg0IA0KTCAyODAuOTQ2MTQxIC0yMDYuMDMzODg0IA0KTCAyODEuMTA1OTc1IC0yMDYuMDMzODg0IA0KTCAyODEuMjY1ODA4IC0yMDYuMDMzODg0IA0KTCAyODEuNDI1NjQyIC0yMDYuMDMzODg0IA0KTCAyODEuNTg1NDc2IC0yMDYuMDMzODg0IA0KTCAyODEuNzQ1MzEgLTIwNi4wMzM4ODQgDQpMIDI4MS45MDUxNDQgLTIwNi4wMzM4ODQgDQpMIDI4Mi4wNjQ5NzggLTIwNi4wMzM4ODQgDQpMIDI4Mi4yMjQ4MTIgLTIwNi4wMzM4ODQgDQpMIDI4Mi4zODQ2NDYgLTIwNi4wMzM4ODQgDQpMIDI4Mi41NDQ0NzkgLTIwNi4wMzM4ODQgDQpMIDI4Mi43MDQzMTMgLTIwNi4wMzM4ODQgDQpMIDI4Mi44NjQxNDcgLTIwNi4wMzM4ODQgDQpMIDI4My4wMjM5ODEgLTIwNi4wMzM4ODQgDQpMIDI4My4xODM4MTUgLTIwNi4wMzM4ODQgDQpMIDI4My4zNDM2NDkgLTIwNi4wMzM4ODQgDQpMIDI4My41MDM0ODMgLTIwNi4wMzM4ODQgDQpMIDI4My42NjMzMTcgLTIwNi4wMzM4ODQgDQpMIDI4My44MjMxNTEgLTIwNi4wMzM4ODQgDQpMIDI4My45ODI5ODQgLTIwNi4wMzM4ODQgDQpMIDI4NC4xNDI4MTggLTIwNi4wMzM4ODQgDQpMIDI4NC4zMDI2NTIgLTIwNi4wMzM4ODQgDQpMIDI4NC40NjI0ODYgLTIwNi4wMzM4ODQgDQpMIDI4NC42MjIzMiAtMjA2LjAzMzg4NCANCkwgMjg0Ljc4MjE1NCAtMjA2LjAzMzg4NCANCkwgMjg0Ljk0MTk4OCAtMjA2LjAzMzg4NCANCkwgMjg1LjEwMTgyMiAtMjA2LjAzMzg4NCANCkwgMjg1LjI2MTY1NSAtMjA2LjAzMzg4NCANCkwgMjg1LjQyMTQ4OSAtMjA2LjAzMzg4NCANCkwgMjg1LjU4MTMyMyAtMjA2LjAzMzg4NCANCkwgMjg1Ljc0MTE1NyAtMjA2LjAzMzg4NCANCkwgMjg1LjkwMDk5MSAtMjA2LjAzMzg4NCANCkwgMjg2LjA2MDgyNSAtMjA2LjAzMzg4NCANCkwgMjg2LjIyMDY1OSAtMjA2LjAzMzg4NCANCkwgMjg2LjM4MDQ5MyAtMjA2LjAzMzg4NCANCkwgMjg2LjU0MDMyNyAtMjA2LjAzMzg4NCANCkwgMjg2LjcwMDE2IC0yMDYuMDMzODg0IA0KTCAyODYuODU5OTk0IC0yMDYuMDMzODg0IA0KTCAyODcuMDE5ODI4IC0yMDYuMDMzODg0IA0KTCAyODcuMTc5NjYyIC0yMDYuMDMzODg0IA0KTCAyODcuMzM5NDk2IC0yMDYuMDMzODg0IA0KTCAyODcuNDk5MzMgLTIwNi4wMzM4ODQgDQpMIDI4Ny42NTkxNjQgLTIwNi4wMzM4ODQgDQpMIDI4Ny44MTg5OTggLTIwNi4wMzM4ODQgDQpMIDI4Ny45Nzg4MzIgLTIwNi4wMzM4ODQgDQpMIDI4OC4xMzg2NjUgLTIwNi4wMzM4ODQgDQpMIDI4OC4yOTg0OTkgLTIwNi4wMzM4ODQgDQpMIDI4OC40NTgzMzMgLTIwNi4wMzM4ODQgDQpMIDI4OC42MTgxNjcgLTIwNi4wMzM4ODQgDQpMIDI4OC43NzgwMDEgLTIwNi4wMzM4ODQgDQpMIDI4OC45Mzc4MzUgLTIwNi4wMzM4ODQgDQpMIDI4OS4wOTc2NjkgLTIwNi4wMzM4ODQgDQpMIDI4OS4yNTc1MDMgLTIwNi4wMzM4ODQgDQpMIDI4OS40MTczMzYgLTIwNi4wMzM4ODQgDQpMIDI4OS41NzcxNyAtMjA2LjAzMzg4NCANCkwgMjg5LjczNzAwNCAtMjA2LjAzMzg4NCANCkwgMjg5Ljg5NjgzOCAtMjA2LjAzMzg4NCANCkwgMjkwLjA1NjY3MiAtMjA2LjAzMzg4NCANCkwgMjkwLjIxNjUwNiAtMjA2LjAzMzg4NCANCkwgMjkwLjM3NjM0IC0yMDYuMDMzODg0IA0KTCAyOTAuNTM2MTc0IC0yMDYuMDMzODg0IA0KTCAyOTAuNjk2MDA4IC0yMDYuMDMzODg0IA0KTCAyOTAuODU1ODQxIC0yMDYuMDMzODg0IA0KTCAyOTEuMDE1Njc1IC0yMDYuMDMzODg0IA0KTCAyOTEuMTc1NTA5IC0yMDYuMDMzODg0IA0KTCAyOTEuMzM1MzQzIC0yMDYuMDMzODg0IA0KTCAyOTEuNDk1MTc3IC0yMDYuMDMzODg0IA0KTCAyOTEuNjU1MDExIC0yMDYuMDMzODg0IA0KTCAyOTEuODE0ODQ1IC0yMDYuMDMzODg0IA0KTCAyOTEuOTc0Njc5IC0yMDYuMDMzODg0IA0KTCAyOTIuMTM0NTEzIC0yMDYuMDMzODg0IA0KTCAyOTIuMjk0MzQ2IC0yMDYuMDMzODg0IA0KTCAyOTIuNDU0MTggLTIwNi4wMzM4ODQgDQpMIDI5Mi42MTQwMTQgLTIwNi4wMzM4ODQgDQpMIDI5Mi43NzM4NDggLTIwNi4wMzM4ODQgDQpMIDI5Mi45MzM2ODIgLTIwNi4wMzM4ODQgDQpMIDI5My4wOTM1MTYgLTIwNi4wMzM4ODQgDQpMIDI5My4yNTMzNSAtMjA2LjAzMzg4NCANCkwgMjkzLjQxMzE4NCAtMjA2LjAzMzg4NCANCkwgMjkzLjU3MzAxNyAtMjA2LjAzMzg4NCANCkwgMjkzLjczMjg1MSAtMjA2LjAzMzg4NCANCkwgMjkzLjg5MjY4NSAtMjA2LjAzMzg4NCANCkwgMjk0LjA1MjUxOSAtMjA2LjAzMzg4NCANCkwgMjk0LjIxMjM1MyAtMjA2LjAzMzg4NCANCkwgMjk0LjM3MjE4NyAtMjA2LjAzMzg4NCANCkwgMjk0LjUzMjAyMSAtMjA2LjAzMzg4NCANCkwgMjk0LjY5MTg1NSAtMjA2LjAzMzg4NCANCkwgMjk0Ljg1MTY4OSAtMjA2LjAzMzg4NCANCkwgMjk1LjAxMTUyMiAtMjA2LjAzMzg4NCANCkwgMjk1LjE3MTM1NiAtMjA2LjAzMzg4NCANCkwgMjk1LjMzMTE5IC0yMDYuMDMzODg0IA0KTCAyOTUuNDkxMDI0IC0yMDYuMDMzODg0IA0KTCAyOTUuNjUwODU4IC0yMDYuMDMzODg0IA0KTCAyOTUuODEwNjkyIC0yMDYuMDMzODg0IA0KTCAyOTUuOTcwNTI2IC0yMDYuMDMzODg0IA0KTCAyOTYuMTMwMzYgLTIwNi4wMzM4ODQgDQpMIDI5Ni4yOTAxOTMgLTIwNi4wMzM4ODQgDQpMIDI5Ni40NTAwMjcgLTIwNi4wMzM4ODQgDQpMIDI5Ni42MDk4NjEgLTIwNi4wMzM4ODQgDQpMIDI5Ni43Njk2OTUgLTIwNi4wMzM4ODQgDQpMIDI5Ni45Mjk1MjkgLTIwNi4wMzM4ODQgDQpMIDI5Ny4wODkzNjMgLTIwNi4wMzM4ODQgDQpMIDI5Ny4yNDkxOTcgLTIwNi4wMzM4ODQgDQpMIDI5Ny40MDkwMzEgLTIwNi4wMzM4ODQgDQpMIDI5Ny41Njg4NjUgLTIwNi4wMzM4ODQgDQpMIDI5Ny43Mjg2OTggLTIwNi4wMzM4ODQgDQpMIDI5Ny44ODg1MzIgLTIwNi4wMzM4ODQgDQpMIDI5OC4wNDgzNjYgLTIwNi4wMzM4ODQgDQpMIDI5OC4yMDgyIC0yMDYuMDMzODg0IA0KTCAyOTguMzY4MDM0IC0yMDYuMDMzODg0IA0KTCAyOTguNTI3ODY4IC0yMDYuMDMzODg0IA0KTCAyOTguNjg3NzAyIC0yMDYuMDMzODg0IA0KTCAyOTguODQ3NTM2IC0yMDYuMDMzODg0IA0KTCAyOTkuMDA3MzcgLTIwNi4wMzM4ODQgDQpMIDI5OS4xNjcyMDMgLTIwNi4wMzM4ODQgDQpMIDI5OS4zMjcwMzcgLTIwNi4wMzM4ODQgDQpMIDI5OS40ODY4NzEgLTIwNi4wMzM4ODQgDQpMIDI5OS42NDY3MDUgLTIwNi4wMzM4ODQgDQpMIDI5OS44MDY1MzkgLTIwNi4wMzM4ODQgDQpMIDI5OS45NjYzNzMgLTIwNi4wMzM4ODQgDQpMIDMwMC4xMjYyMDcgLTIwNi4wMzM4ODQgDQpMIDMwMC4yODYwNDEgLTIwNi4wMzM4ODQgDQpMIDMwMC40NDU4NzQgLTIwNi4wMzM4ODQgDQpMIDMwMC42MDU3MDggLTIwNi4wMzM4ODQgDQpMIDMwMC43NjU1NDIgLTIwNi4wMzM4ODQgDQpMIDMwMC45MjUzNzYgLTIwNi4wMzM4ODQgDQpMIDMwMS4wODUyMSAtMjA2LjAzMzg4NCANCkwgMzAxLjI0NTA0NCAtMjA2LjAzMzg4NCANCkwgMzAxLjQwNDg3OCAtMjA2LjAzMzg4NCANCkwgMzAxLjU2NDcxMiAtMjA2LjAzMzg4NCANCkwgMzAxLjcyNDU0NiAtMjA2LjAzMzg4NCANCkwgMzAxLjg4NDM3OSAtMjA2LjAzMzg4NCANCkwgMzAyLjA0NDIxMyAtMjA2LjAzMzg4NCANCkwgMzAyLjIwNDA0NyAtMjA2LjAzMzg4NCANCkwgMzAyLjM2Mzg4MSAtMjA2LjAzMzg4NCANCkwgMzAyLjUyMzcxNSAtMjA2LjAzMzg4NCANCkwgMzAyLjY4MzU0OSAtMjA2LjAzMzg4NCANCkwgMzAyLjg0MzM4MyAtMjA2LjAzMzg4NCANCkwgMzAzLjAwMzIxNyAtMjA2LjAzMzg4NCANCkwgMzAzLjE2MzA1IC0yMDYuMDMzODg0IA0KTCAzMDMuMzIyODg0IC0yMDYuMDMzODg0IA0KTCAzMDMuNDgyNzE4IC0yMDYuMDMzODg0IA0KTCAzMDMuNjQyNTUyIC0yMDYuMDMzODg0IA0KTCAzMDMuODAyMzg2IC0yMDYuMDMzODg0IA0KTCAzMDMuOTYyMjIgLTIwNi4wMzM4ODQgDQpMIDMwNC4xMjIwNTQgLTIwNi4wMzM4ODQgDQpMIDMwNC4yODE4ODggLTIwNi4wMzM4ODQgDQpMIDMwNC40NDE3MjIgLTIwNi4wMzM4ODQgDQpMIDMwNC42MDE1NTUgLTIwNi4wMzM4ODQgDQpMIDMwNC43NjEzODkgLTIwNi4wMzM4ODQgDQpMIDMwNC45MjEyMjMgLTIwNi4wMzM4ODQgDQpMIDMwNS4wODEwNTcgLTIwNi4wMzM4ODQgDQpMIDMwNS4yNDA4OTEgLTIwNi4wMzM4ODQgDQpMIDMwNS40MDA3MjUgLTIwNi4wMzM4ODQgDQpMIDMwNS41NjA1NTkgLTIwNi4wMzM4ODQgDQpMIDMwNS43MjAzOTMgLTIwNi4wMzM4ODQgDQpMIDMwNS44ODAyMjcgLTIwNi4wMzM4ODQgDQpMIDMwNi4wNDAwNiAtMjA2LjAzMzg4NCANCkwgMzA2LjE5OTg5NCAtMjA2LjAzMzg4NCANCkwgMzA2LjM1OTcyOCAtMjA2LjAzMzg4NCANCkwgMzA2LjUxOTU2MiAtMjA2LjAzMzg4NCANCkwgMzA2LjY3OTM5NiAtMjA2LjAzMzg4NCANCkwgMzA2LjgzOTIzIC0yMDYuMDMzODg0IA0KTCAzMDYuOTk5MDY0IC0yMDYuMDMzODg0IA0KTCAzMDcuMTU4ODk4IC0yMDYuMDMzODg0IA0KTCAzMDcuMzE4NzMxIC0yMDYuMDMzODg0IA0KTCAzMDcuNDc4NTY1IC0yMDYuMDMzODg0IA0KTCAzMDcuNjM4Mzk5IC0yMDYuMDMzODg0IA0KTCAzMDcuNzk4MjMzIC0yMDYuMDMzODg0IA0KTCAzMDcuOTU4MDY3IC0yMDYuMDMzODg0IA0KTCAzMDguMTE3OTAxIC0yMDYuMDMzODg0IA0KTCAzMDguMjc3NzM1IC0yMDYuMDMzODg0IA0KTCAzMDguNDM3NTY5IC0yMDYuMDMzODg0IA0KTCAzMDguNTk3NDAzIC0yMDYuMDMzODg0IA0KTCAzMDguNzU3MjM2IC0yMDYuMDMzODg0IA0KTCAzMDguOTE3MDcgLTIwNi4wMzM4ODQgDQpMIDMwOS4wNzY5MDQgLTIwNi4wMzM4ODQgDQpMIDMwOS4yMzY3MzggLTIwNi4wMzM4ODQgDQpMIDMwOS4zOTY1NzIgLTIwNi4wMzM4ODQgDQpMIDMwOS41NTY0MDYgLTIwNi4wMzM4ODQgDQpMIDMwOS43MTYyNCAtMjA2LjAzMzg4NCANCkwgMzA5Ljg3NjA3NCAtMjA2LjAzMzg4NCANCkwgMzEwLjAzNTkwOCAtMjA2LjAzMzg4NCANCkwgMzEwLjE5NTc0MSAtMjA2LjAzMzg4NCANCkwgMzEwLjM1NTU3NSAtMjA2LjAzMzg4NCANCkwgMzEwLjUxNTQwOSAtMjA2LjAzMzg4NCANCkwgMzEwLjY3NTI0MyAtMjA2LjAzMzg4NCANCkwgMzEwLjgzNTA3NyAtMjA2LjAzMzg4NCANCkwgMzEwLjk5NDkxMSAtMjA2LjAzMzg4NCANCkwgMzExLjE1NDc0NSAtMjA2LjAzMzg4NCANCkwgMzExLjMxNDU3OSAtMjA2LjAzMzg4NCANCkwgMzExLjQ3NDQxMiAtMjA2LjAzMzg4NCANCkwgMzExLjYzNDI0NiAtMjA2LjAzMzg4NCANCkwgMzExLjc5NDA4IC0yMDYuMDMzODg0IA0KTCAzMTEuOTUzOTE0IC0yMDYuMDMzODg0IA0KTCAzMTIuMTEzNzQ4IC0yMDYuMDMzODg0IA0KTCAzMTIuMjczNTgyIC0yMDYuMDMzODg0IA0KTCAzMTIuNDMzNDE2IC0yMDYuMDMzODg0IA0KTCAzMTIuNTkzMjUgLTIwNi4wMzM4ODQgDQpMIDMxMi43NTMwODQgLTIwNi4wMzM4ODQgDQpMIDMxMi45MTI5MTcgLTIwNi4wMzM4ODQgDQpMIDMxMy4wNzI3NTEgLTIwNi4wMzM4ODQgDQpMIDMxMy4yMzI1ODUgLTIwNi4wMzM4ODQgDQpMIDMxMy4zOTI0MTkgLTIwNi4wMzM4ODQgDQpMIDMxMy41NTIyNTMgLTIwNi4wMzM4ODQgDQpMIDMxMy43MTIwODcgLTIwNi4wMzM4ODQgDQpMIDMxMy44NzE5MjEgLTIwNi4wMzM4ODQgDQpMIDMxNC4wMzE3NTUgLTIwNi4wMzM4ODQgDQpMIDMxNC4xOTE1ODggLTIwNi4wMzM4ODQgDQpMIDMxNC4zNTE0MjIgLTIwNi4wMzM4ODQgDQpMIDMxNC41MTEyNTYgLTIwNi4wMzM4ODQgDQpMIDMxNC42NzEwOSAtMjA2LjAzMzg4NCANCkwgMzE0LjgzMDkyNCAtMjA2LjAzMzg4NCANCkwgMzE0Ljk5MDc1OCAtMjA2LjAzMzg4NCANCkwgMzE1LjE1MDU5MiAtMjA2LjAzMzg4NCANCkwgMzE1LjMxMDQyNiAtMjA2LjAzMzg4NCANCkwgMzE1LjQ3MDI2IC0yMDYuMDMzODg0IA0KTCAzMTUuNjMwMDkzIC0yMDYuMDMzODg0IA0KTCAzMTUuNzg5OTI3IC0yMDYuMDMzODg0IA0KTCAzMTUuOTQ5NzYxIC0yMDYuMDMzODg0IA0KTCAzMTYuMTA5NTk1IC0yMDYuMDMzODg0IA0KTCAzMTYuMjY5NDI5IC0yMDYuMDMzODg0IA0KTCAzMTYuNDI5MjYzIC0yMDYuMDMzODg0IA0KTCAzMTYuNTg5MDk3IC0yMDYuMDMzODg0IA0KTCAzMTYuNzQ4OTMxIC0yMDYuMDMzODg0IA0KTCAzMTYuOTA4NzY1IC0yMDYuMDMzODg0IA0KTCAzMTcuMDY4NTk4IC0yMDYuMDMzODg0IA0KTCAzMTcuMjI4NDMyIC0yMDYuMDMzODg0IA0KTCAzMTcuMzg4MjY2IC0yMDYuMDMzODg0IA0KTCAzMTcuNTQ4MSAtMjA2LjAzMzg4NCANCkwgMzE3LjcwNzkzNCAtMjA2LjAzMzg4NCANCkwgMzE3Ljg2Nzc2OCAtMjA2LjAzMzg4NCANCkwgMzE4LjAyNzYwMiAtMjA2LjAzMzg4NCANCkwgMzE4LjE4NzQzNiAtMjA2LjAzMzg4NCANCkwgMzE4LjM0NzI2OSAtMjA2LjAzMzg4NCANCkwgMzE4LjUwNzEwMyAtMjA2LjAzMzg4NCANCkwgMzE4LjY2NjkzNyAtMjA2LjAzMzg4NCANCkwgMzE4LjgyNjc3MSAtMjA2LjAzMzg4NCANCkwgMzE4Ljk4NjYwNSAtMjA2LjAzMzg4NCANCkwgMzE5LjE0NjQzOSAtMjA2LjAzMzg4NCANCkwgMzE5LjMwNjI3MyAtMjA2LjAzMzg4NCANCkwgMzE5LjQ2NjEwNyAtMjA2LjAzMzg4NCANCkwgMzE5LjYyNTk0MSAtMjA2LjAzMzg4NCANCkwgMzE5Ljc4NTc3NCAtMjA2LjAzMzg4NCANCkwgMzE5Ljk0NTYwOCAtMjA2LjAzMzg4NCANCkwgMzIwLjEwNTQ0MiAtMjA2LjAzMzg4NCANCkwgMzIwLjI2NTI3NiAtMjA2LjAzMzg4NCANCkwgMzIwLjQyNTExIC0yMDYuMDMzODg0IA0KTCAzMjAuNTg0OTQ0IC0yMDYuMDMzODg0IA0KTCAzMjAuNzQ0Nzc4IC0yMDYuMDMzODg0IA0KTCAzMjAuOTA0NjEyIC0yMDYuMDMzODg0IA0KTCAzMjEuMDY0NDQ1IC0yMDYuMDMzODg0IA0KTCAzMjEuMjI0Mjc5IC0yMDYuMDMzODg0IA0KTCAzMjEuMzg0MTEzIC0yMDYuMDMzODg0IA0KTCAzMjEuNTQzOTQ3IC0yMDYuMDMzODg0IA0KTCAzMjEuNzAzNzgxIC0yMDYuMDMzODg0IA0KTCAzMjEuODYzNjE1IC0yMDYuMDMzODg0IA0KTCAzMjIuMDIzNDQ5IC0yMDYuMDMzODg0IA0KTCAzMjIuMTgzMjgzIC0yMDYuMDMzODg0IA0KTCAzMjIuMzQzMTE3IC0yMDYuMDMzODg0IA0KTCAzMjIuNTAyOTUgLTIwNi4wMzM4ODQgDQpMIDMyMi42NjI3ODQgLTIwNi4wMzM4ODQgDQpMIDMyMi44MjI2MTggLTIwNi4wMzM4ODQgDQpMIDMyMi45ODI0NTIgLTIwNi4wMzM4ODQgDQpMIDMyMy4xNDIyODYgLTIwNi4wMzM4ODQgDQpMIDMyMy4zMDIxMiAtMjA2LjAzMzg4NCANCkwgMzIzLjQ2MTk1NCAtMjA2LjAzMzg4NCANCkwgMzIzLjYyMTc4OCAtMjA2LjAzMzg4NCANCkwgMzIzLjc4MTYyMiAtMjA2LjAzMzg4NCANCkwgMzIzLjk0MTQ1NSAtMjA2LjAzMzg4NCANCkwgMzI0LjEwMTI4OSAtMjA2LjAzMzg4NCANCkwgMzI0LjI2MTEyMyAtMjA2LjAzMzg4NCANCkwgMzI0LjQyMDk1NyAtMjA2LjAzMzg4NCANCkwgMzI0LjU4MDc5MSAtMjA2LjAzMzg4NCANCkwgMzI0Ljc0MDYyNSAtMjA2LjAzMzg4NCANCkwgMzI0LjkwMDQ1OSAtMjA2LjAzMzg4NCANCkwgMzI1LjA2MDI5MyAtMjA2LjAzMzg4NCANCkwgMzI1LjIyMDEyNiAtMjA2LjAzMzg4NCANCkwgMzI1LjM3OTk2IC0yMDYuMDMzODg0IA0KTCAzMjUuNTM5Nzk0IC0yMDYuMDMzODg0IA0KTCAzMjUuNjk5NjI4IC0yMDYuMDMzODg0IA0KTCAzMjUuODU5NDYyIC0yMDYuMDMzODg0IA0KTCAzMjYuMDE5Mjk2IC0yMDYuMDMzODg0IA0KTCAzMjYuMTc5MTMgLTIwNi4wMzM4ODQgDQpMIDMyNi4zMzg5NjQgLTIwNi4wMzM4ODQgDQpMIDMyNi40OTg3OTggLTIwNi4wMzM4ODQgDQpMIDMyNi42NTg2MzEgLTIwNi4wMzM4ODQgDQpMIDMyNi44MTg0NjUgLTIwNi4wMzM4ODQgDQpMIDMyNi45NzgyOTkgLTIwNi4wMzM4ODQgDQpMIDMyNy4xMzgxMzMgLTIwNi4wMzM4ODQgDQpMIDMyNy4yOTc5NjcgLTIwNi4wMzM4ODQgDQpMIDMyNy40NTc4MDEgLTIwNi4wMzM4ODQgDQpMIDMyNy42MTc2MzUgLTIwNi4wMzM4ODQgDQpMIDMyNy43Nzc0NjkgLTIwNi4wMzM4ODQgDQpMIDMyNy45MzczMDMgLTIwNi4wMzM4ODQgDQpMIDMyOC4wOTcxMzYgLTIwNi4wMzM4ODQgDQpMIDMyOC4yNTY5NyAtMjA2LjAzMzg4NCANCkwgMzI4LjQxNjgwNCAtMjA2LjAzMzg4NCANCkwgMzI4LjU3NjYzOCAtMjA2LjAzMzg4NCANCkwgMzI4LjczNjQ3MiAtMjA2LjAzMzg4NCANCkwgMzI4Ljg5NjMwNiAtMjA2LjAzMzg4NCANCkwgMzI5LjA1NjE0IC0yMDYuMDMzODg0IA0KTCAzMjkuMjE1OTc0IC0yMDYuMDMzODg0IA0KTCAzMjkuMzc1ODA3IC0yMDYuMDMzODg0IA0KTCAzMjkuNTM1NjQxIC0yMDYuMDMzODg0IA0KTCAzMjkuNjk1NDc1IC0yMDYuMDMzODg0IA0KTCAzMjkuODU1MzA5IC0yMDYuMDMzODg0IA0KTCAzMzAuMDE1MTQzIC0yMDYuMDMzODg0IA0KTCAzMzAuMTc0OTc3IC0yMDYuMDMzODg0IA0KTCAzMzAuMzM0ODExIC0yMDYuMDMzODg0IA0KTCAzMzAuNDk0NjQ1IC0yMDYuMDMzODg0IA0KTCAzMzAuNjU0NDc5IC0yMDYuMDMzODg0IA0KTCAzMzAuODE0MzEyIC0yMDYuMDMzODg0IA0KTCAzMzAuOTc0MTQ2IC0yMDYuMDMzODg0IA0KTCAzMzEuMTMzOTggLTIwNi4wMzM4ODQgDQpMIDMzMS4yOTM4MTQgLTIwNi4wMzM4ODQgDQpMIDMzMS40NTM2NDggLTIwNi4wMzM4ODQgDQpMIDMzMS42MTM0ODIgLTIwNi4wMzM4ODQgDQpMIDMzMS43NzMzMTYgLTIwNi4wMzM4ODQgDQpMIDMzMS45MzMxNSAtMjA2LjAzMzg4NCANCkwgMzMyLjA5Mjk4MyAtMjA2LjAzMzg4NCANCkwgMzMyLjI1MjgxNyAtMjA2LjAzMzg4NCANCkwgMzMyLjQxMjY1MSAtMjA2LjAzMzg4NCANCkwgMzMyLjU3MjQ4NSAtMjA2LjAzMzg4NCANCkwgMzMyLjczMjMxOSAtMjA2LjAzMzg4NCANCkwgMzMyLjg5MjE1MyAtMjA2LjAzMzg4NCANCkwgMzMzLjA1MTk4NyAtMjA2LjAzMzg4NCANCkwgMzMzLjIxMTgyMSAtMjA2LjAzMzg4NCANCkwgMzMzLjM3MTY1NSAtMjA2LjAzMzg4NCANCkwgMzMzLjUzMTQ4OCAtMjA2LjAzMzg4NCANCkwgMzMzLjY5MTMyMiAtMjA2LjAzMzg4NCANCkwgMzMzLjg1MTE1NiAtMjA2LjAzMzg4NCANCkwgMzM0LjAxMDk5IC0yMDYuMDMzODg0IA0KTCAzMzQuMTcwODI0IC0yMDYuMDMzODg0IA0KTCAzMzQuMzMwNjU4IC0yMDYuMDMzODg0IA0KTCAzMzQuNDkwNDkyIC0yMDYuMDMzODg0IA0KTCAzMzQuNjUwMzI2IC0yMDYuMDMzODg0IA0KTCAzMzQuODEwMTYgLTIwNi4wMzM4ODQgDQpMIDMzNC45Njk5OTMgLTIwNi4wMzM4ODQgDQpMIDMzNS4xMjk4MjcgLTIwNi4wMzM4ODQgDQpMIDMzNS4yODk2NjEgLTIwNi4wMzM4ODQgDQpMIDMzNS40NDk0OTUgLTIwNi4wMzM4ODQgDQpMIDMzNS42MDkzMjkgLTIwNi4wMzM4ODQgDQpMIDMzNS43NjkxNjMgLTIwNi4wMzM4ODQgDQpMIDMzNS45Mjg5OTcgLTIwNi4wMzM4ODQgDQpMIDMzNi4wODg4MzEgLTIwNi4wMzM4ODQgDQpMIDMzNi4yNDg2NjQgLTIwNi4wMzM4ODQgDQpMIDMzNi40MDg0OTggLTIwNi4wMzM4ODQgDQpMIDMzNi41NjgzMzIgLTIwNi4wMzM4ODQgDQpMIDMzNi43MjgxNjYgLTIwNi4wMzM4ODQgDQpMIDMzNi44ODggLTIwNi4wMzM4ODQgDQpMIDMzNy4wNDc4MzQgLTIwNi4wMzM4ODQgDQpMIDMzNy4yMDc2NjggLTIwNi4wMzM4ODQgDQpMIDMzNy4zNjc1MDIgLTIwNi4wMzM4ODQgDQpMIDMzNy41MjczMzYgLTIwNi4wMzM4ODQgDQpMIDMzNy42ODcxNjkgLTIwNi4wMzM4ODQgDQpMIDMzNy44NDcwMDMgLTIwNi4wMzM4ODQgDQpMIDMzOC4wMDY4MzcgLTIwNi4wMzM4ODQgDQpMIDMzOC4xNjY2NzEgLTIwNi4wMzM4ODQgDQpMIDMzOC4zMjY1MDUgLTIwNi4wMzM4ODQgDQpMIDMzOC40ODYzMzkgLTIwNi4wMzM4ODQgDQpMIDMzOC42NDYxNzMgLTIwNi4wMzM4ODQgDQpMIDMzOC44MDYwMDcgLTIwNi4wMzM4ODQgDQpMIDMzOC45NjU4NCAtMjA2LjAzMzg4NCANCkwgMzM5LjEyNTY3NCAtMjA2LjAzMzg4NCANCkwgMzM5LjI4NTUwOCAtMjA2LjAzMzg4NCANCkwgMzM5LjQ0NTM0MiAtMjA2LjAzMzg4NCANCkwgMzM5LjYwNTE3NiAtMjA2LjAzMzg4NCANCkwgMzM5Ljc2NTAxIC0yMDYuMDMzODg0IA0KTCAzMzkuOTI0ODQ0IC0yMDYuMDMzODg0IA0KTCAzNDAuMDg0Njc4IC0yMDYuMDMzODg0IA0KTCAzNDAuMjQ0NTEyIC0yMDYuMDMzODg0IA0KTCAzNDAuNDA0MzQ1IC0yMDYuMDMzODg0IA0KTCAzNDAuNTY0MTc5IC0yMDYuMDMzODg0IA0KTCAzNDAuNzI0MDEzIC0yMDYuMDMzODg0IA0KTCAzNDAuODgzODQ3IC0yMDYuMDMzODg0IA0KTCAzNDEuMDQzNjgxIC0yMDYuMDMzODg0IA0KTCAzNDEuMjAzNTE1IC0yMDYuMDMzODg0IA0KTCAzNDEuMzYzMzQ5IC0yMDYuMDMzODg0IA0KTCAzNDEuNTIzMTgzIC0yMDYuMDMzODg0IA0KTCAzNDEuNjgzMDE3IC0yMDYuMDMzODg0IA0KTCAzNDEuODQyODUgLTIwNi4wMzM4ODQgDQpMIDM0Mi4wMDI2ODQgLTIwNi4wMzM4ODQgDQpMIDM0Mi4xNjI1MTggLTIwNi4wMzM4ODQgDQpMIDM0Mi4zMjIzNTIgLTIwNi4wMzM4ODQgDQpMIDM0Mi40ODIxODYgLTIwNi4wMzM4ODQgDQpMIDM0Mi42NDIwMiAtMjA2LjAzMzg4NCANCkwgMzQyLjgwMTg1NCAtMjA2LjAzMzg4NCANCkwgMzQyLjk2MTY4OCAtMjA2LjAzMzg4NCANCkwgMzQzLjEyMTUyMSAtMjA2LjAzMzg4NCANCkwgMzQzLjI4MTM1NSAtMjA2LjAzMzg4NCANCkwgMzQzLjQ0MTE4OSAtMjA2LjAzMzg4NCANCkwgMzQzLjYwMTAyMyAtMjA2LjAzMzg4NCANCkwgMzQzLjc2MDg1NyAtMjA2LjAzMzg4NCANCkwgMzQzLjkyMDY5MSAtMjA2LjAzMzg4NCANCkwgMzQ0LjA4MDUyNSAtMjA2LjAzMzg4NCANCkwgMzQ0LjI0MDM1OSAtMjA2LjAzMzg4NCANCkwgMzQ0LjQwMDE5MyAtMjA2LjAzMzg4NCANCkwgMzQ0LjU2MDAyNiAtMjA2LjAzMzg4NCANCkwgMzQ0LjcxOTg2IC0yMDYuMDMzODg0IA0KTCAzNDQuODc5Njk0IC0yMDYuMDMzODg0IA0KTCAzNDUuMDM5NTI4IC0yMDYuMDMzODg0IA0KTCAzNDUuMTk5MzYyIC0yMDYuMDMzODg0IA0KTCAzNDUuMzU5MTk2IC0yMDYuMDMzODg0IA0KTCAzNDUuNTE5MDMgLTIwNi4wMzM4ODQgDQpMIDM0NS42Nzg4NjQgLTIwNi4wMzM4ODQgDQpMIDM0NS44Mzg2OTcgLTIwNi4wMzM4ODQgDQpMIDM0NS45OTg1MzEgLTIwNi4wMzM4ODQgDQpMIDM0Ni4xNTgzNjUgLTIwNi4wMzM4ODQgDQpMIDM0Ni4zMTgxOTkgLTIwNi4wMzM4ODQgDQpMIDM0Ni40NzgwMzMgLTIwNi4wMzM4ODQgDQpMIDM0Ni42Mzc4NjcgLTIwNi4wMzM4ODQgDQpMIDM0Ni43OTc3MDEgLTIwNi4wMzM4ODQgDQpMIDM0Ni45NTc1MzUgLTIwNi4wMzM4ODQgDQpMIDM0Ny4xMTczNjkgLTIwNi4wMzM4ODQgDQpMIDM0Ny4yNzcyMDIgLTIwNi4wMzM4ODQgDQpMIDM0Ny40MzcwMzYgLTIwNi4wMzM4ODQgDQpMIDM0Ny41OTY4NyAtMjA2LjAzMzg4NCANCkwgMzQ3Ljc1NjcwNCAtMjA2LjAzMzg4NCANCkwgMzQ3LjkxNjUzOCAtMjA2LjAzMzg4NCANCkwgMzQ4LjA3NjM3MiAtMjA2LjAzMzg4NCANCkwgMzQ4LjIzNjIwNiAtMjA2LjAzMzg4NCANCkwgMzQ4LjM5NjA0IC0yMDYuMDMzODg0IA0KTCAzNDguNTU1ODc0IC0yMDYuMDMzODg0IA0KTCAzNDguNzE1NzA3IC0yMDYuMDMzODg0IA0KTCAzNDguODc1NTQxIC0yMDYuMDMzODg0IA0KTCAzNDkuMDM1Mzc1IC0yMDYuMDMzODg0IA0KTCAzNDkuMTk1MjA5IC0yMDYuMDMzODg0IA0KTCAzNDkuMzU1MDQzIC0yMDYuMDMzODg0IA0KTCAzNDkuNTE0ODc3IC0yMDYuMDMzODg0IA0KTCAzNDkuNjc0NzExIC0yMDYuMDMzODg0IA0KTCAzNDkuODM0NTQ1IC0yMDYuMDMzODg0IA0KTCAzNDkuOTk0Mzc4IC0yMDYuMDMzODg0IA0KTCAzNTAuMTU0MjEyIC0yMDYuMDMzODg0IA0KTCAzNTAuMzE0MDQ2IC0yMDYuMDMzODg0IA0KTCAzNTAuNDczODggLTIwNi4wMzM4ODQgDQpMIDM1MC42MzM3MTQgLTIwNi4wMzM4ODQgDQpMIDM1MC43OTM1NDggLTIwNi4wMzM4ODQgDQpMIDM1MC45NTMzODIgLTIwNi4wMzM4ODQgDQpMIDM1MS4xMTMyMTYgLTIwNi4wMzM4ODQgDQpMIDM1MS4yNzMwNSAtMjA2LjAzMzg4NCANCkwgMzUxLjQzMjg4MyAtMjA2LjAzMzg4NCANCkwgMzUxLjU5MjcxNyAtMjA2LjAzMzg4NCANCkwgMzUxLjc1MjU1MSAtMjA2LjAzMzg4NCANCkwgMzUxLjkxMjM4NSAtMjA2LjAzMzg4NCANCkwgMzUyLjA3MjIxOSAtMjA2LjAzMzg4NCANCkwgMzUyLjIzMjA1MyAtMjA2LjAzMzg4NCANCkwgMzUyLjM5MTg4NyAtMjA2LjAzMzg4NCANCkwgMzUyLjU1MTcyMSAtMjA2LjAzMzg4NCANCkwgMzUyLjcxMTU1NSAtMjA2LjAzMzg4NCANCkwgMzUyLjg3MTM4OCAtMjA2LjAzMzg4NCANCkwgMzUzLjAzMTIyMiAtMjA2LjAzMzg4NCANCkwgMzUzLjE5MTA1NiAtMjA2LjAzMzg4NCANCkwgMzUzLjM1MDg5IC0yMDYuMDMzODg0IA0KTCAzNTMuNTEwNzI0IC0yMDYuMDMzODg0IA0KTCAzNTMuNjcwNTU4IC0yMDYuMDMzODg0IA0KTCAzNTMuODMwMzkyIC0yMDYuMDMzODg0IA0KTCAzNTMuOTkwMjI2IC0yMDYuMDMzODg0IA0KTCAzNTQuMTUwMDU5IC0yMDYuMDMzODg0IA0KTCAzNTQuMzA5ODkzIC0yMDYuMDMzODg0IA0KTCAzNTQuNDY5NzI3IC0yMDYuMDMzODg0IA0KTCAzNTQuNjI5NTYxIC0yMDYuMDMzODg0IA0KTCAzNTQuNzg5Mzk1IC0yMDYuMDMzODg0IA0KTCAzNTQuOTQ5MjI5IC0yMDYuMDMzODg0IA0KTCAzNTUuMTA5MDYzIC0yMDYuMDMzODg0IA0KTCAzNTUuMjY4ODk3IC0yMDYuMDMzODg0IA0KTCAzNTUuNDI4NzMxIC0yMDYuMDMzODg0IA0KTCAzNTUuNTg4NTY0IC0yMDYuMDMzODg0IA0KTCAzNTUuNzQ4Mzk4IC0yMDYuMDMzODg0IA0KTCAzNTUuOTA4MjMyIC0yMDYuMDMzODg0IA0KTCAzNTYuMDY4MDY2IC0yMDYuMDMzODg0IA0KTCAzNTYuMjI3OSAtMjA2LjAzMzg4NCANCkwgMzU2LjM4NzczNCAtMjA2LjAzMzg4NCANCkwgMzU2LjU0NzU2OCAtMjA2LjAzMzg4NCANCkwgMzU2LjcwNzQwMiAtMjA2LjAzMzg4NCANCkwgMzU2Ljg2NzIzNSAtMjA2LjAzMzg4NCANCkwgMzU3LjAyNzA2OSAtMjA2LjAzMzg4NCANCkwgMzU3LjE4NjkwMyAtMjA2LjAzMzg4NCANCkwgMzU3LjM0NjczNyAtMjA2LjAzMzg4NCANCkwgMzU3LjUwNjU3MSAtMjA2LjAzMzg4NCANCkwgMzU3LjY2NjQwNSAtMjA2LjAzMzg4NCANCkwgMzU3LjgyNjIzOSAtMjA2LjAzMzg4NCANCkwgMzU3Ljk4NjA3MyAtMjA2LjAzMzg4NCANCkwgMzU4LjE0NTkwNyAtMjA2LjAzMzg4NCANCkwgMzU4LjMwNTc0IC0yMDYuMDMzODg0IA0KTCAzNTguNDY1NTc0IC0yMDYuMDMzODg0IA0KTCAzNTguNjI1NDA4IC0yMDYuMDMzODg0IA0KTCAzNTguNzg1MjQyIC0yMDYuMDMzODg0IA0KTCAzNTguOTQ1MDc2IC0yMDYuMDMzODg0IA0KTCAzNTkuMTA0OTEgLTIwNi4wMzM4ODQgDQpMIDM1OS4yNjQ3NDQgLTIwNi4wMzM4ODQgDQpMIDM1OS40MjQ1NzggLTIwNi4wMzM4ODQgDQpMIDM1OS41ODQ0MTIgLTIwNi4wMzM4ODQgDQpMIDM1OS43NDQyNDUgLTIwNi4wMzM4ODQgDQpMIDM1OS45MDQwNzkgLTIwNi4wMzM4ODQgDQpMIDM2MC4wNjM5MTMgLTIwNi4wMzM4ODQgDQpMIDM2MC4yMjM3NDcgLTIwNi4wMzM4ODQgDQpMIDM2MC4zODM1ODEgLTIwNi4wMzM4ODQgDQpMIDM2MC41NDM0MTUgLTIwNi4wMzM4ODQgDQpMIDM2MC43MDMyNDkgLTIwNi4wMzM4ODQgDQpMIDM2MC44NjMwODMgLTIwNi4wMzM4ODQgDQpMIDM2MS4wMjI5MTYgLTIwNi4wMzM4ODQgDQpMIDM2MS4xODI3NSAtMjA2LjAzMzg4NCANCkwgMzYxLjM0MjU4NCAtMjA2LjAzMzg4NCANCkwgMzYxLjUwMjQxOCAtMjA2LjAzMzg4NCANCkwgMzYxLjY2MjI1MiAtMjA2LjAzMzg4NCANCkwgMzYxLjgyMjA4NiAtMjA2LjAzMzg4NCANCkwgMzYxLjk4MTkyIC0yMDYuMDMzODg0IA0KTCAzNjIuMTQxNzU0IC0yMDYuMDMzODg0IA0KTCAzNjIuMzAxNTg4IC0yMDYuMDMzODg0IA0KTCAzNjIuNDYxNDIxIC0yMDYuMDMzODg0IA0KTCAzNjIuNjIxMjU1IC0yMDYuMDMzODg0IA0KTCAzNjIuNzgxMDg5IC0yMDYuMDMzODg0IA0KTCAzNjIuOTQwOTIzIC0yMDYuMDMzODg0IA0KTCAzNjMuMTAwNzU3IC0yMDYuMDMzODg0IA0KTCAzNjMuMjYwNTkxIC0yMDYuMDMzODg0IA0KTCAzNjMuNDIwNDI1IC0yMDYuMDMzODg0IA0KTCAzNjMuNTgwMjU5IC0yMDYuMDMzODg0IA0KTCAzNjMuNzQwMDkyIC0yMDYuMDMzODg0IA0KTCAzNjMuODk5OTI2IC0yMDYuMDMzODg0IA0KTCAzNjQuMDU5NzYgLTIwNi4wMzM4ODQgDQpMIDM2NC4yMTk1OTQgLTIwNi4wMzM4ODQgDQpMIDM2NC4zNzk0MjggLTIwNi4wMzM4ODQgDQpMIDM2NC41MzkyNjIgLTIwNi4wMzM4ODQgDQpMIDM2NC42OTkwOTYgLTIwNi4wMzM4ODQgDQpMIDM2NC44NTg5MyAtMjA2LjAzMzg4NCANCkwgMzY1LjAxODc2NCAtMjA2LjAzMzg4NCANCkwgMzY1LjE3ODU5NyAtMjA2LjAzMzg4NCANCkwgMzY1LjMzODQzMSAtMjA2LjAzMzg4NCANCkwgMzY1LjQ5ODI2NSAtMjA2LjAzMzg4NCANCkwgMzY1LjY1ODA5OSAtMjA2LjAzMzg4NCANCkwgMzY1LjgxNzkzMyAtMjA2LjAzMzg4NCANCkwgMzY1Ljk3Nzc2NyAtMjA2LjAzMzg4NCANCkwgMzY2LjEzNzYwMSAtMjA2LjAzMzg4NCANCkwgMzY2LjI5NzQzNSAtMjA2LjAzMzg4NCANCkwgMzY2LjQ1NzI2OSAtMjA2LjAzMzg4NCANCkwgMzY2LjYxNzEwMiAtMjA2LjAzMzg4NCANCkwgMzY2Ljc3NjkzNiAtMjA2LjAzMzg4NCANCkwgMzY2LjkzNjc3IC0yMDYuMDMzODg0IA0KTCAzNjcuMDk2NjA0IC0yMDYuMDMzODg0IA0KTCAzNjcuMjU2NDM4IC0yMDYuMDMzODg0IA0KTCAzNjcuNDE2MjcyIC0yMDYuMDMzODg0IA0KTCAzNjcuNTc2MTA2IC0yMDYuMDMzODg0IA0KTCAzNjcuNzM1OTQgLTIwNi4wMzM4ODQgDQpMIDM2Ny44OTU3NzMgLTIwNi4wMzM4ODQgDQpMIDM2OC4wNTU2MDcgLTIwNi4wMzM4ODQgDQpMIDM2OC4yMTU0NDEgLTIwNi4wMzM4ODQgDQpMIDM2OC4zNzUyNzUgLTIwNi4wMzM4ODQgDQpMIDM2OC41MzUxMDkgLTIwNi4wMzM4ODQgDQpMIDM2OC42OTQ5NDMgLTIwNi4wMzM4ODQgDQpMIDM2OC44NTQ3NzcgLTIwNi4wMzM4ODQgDQpMIDM2OS4wMTQ2MTEgLTIwNi4wMzM4ODQgDQpMIDM2OS4xNzQ0NDUgLTIwNi4wMzM4ODQgDQpMIDM2OS4zMzQyNzggLTIwNi4wMzM4ODQgDQpMIDM2OS40OTQxMTIgLTIwNi4wMzM4ODQgDQpMIDM2OS42NTM5NDYgLTIwNi4wMzM4ODQgDQpMIDM2OS44MTM3OCAtMjA2LjAzMzg4NCANCkwgMzY5Ljk3MzYxNCAtMjA2LjAzMzg4NCANCkwgMzcwLjEzMzQ0OCAtMjA2LjAzMzg4NCANCkwgMzcwLjI5MzI4MiAtMjA2LjAzMzg4NCANCkwgMzcwLjQ1MzExNiAtMjA2LjAzMzg4NCANCkwgMzcwLjYxMjk1IC0yMDYuMDMzODg0IA0KTCAzNzAuNzcyNzgzIC0yMDYuMDMzODg0IA0KTCAzNzAuOTMyNjE3IC0yMDYuMDMzODg0IA0KTCAzNzEuMDkyNDUxIC0yMDYuMDMzODg0IA0KTCAzNzEuMjUyMjg1IC0yMDYuMDMzODg0IA0KTCAzNzEuNDEyMTE5IC0yMDYuMDMzODg0IA0KTCAzNzEuNTcxOTUzIC0yMDYuMDMzODg0IA0KTCAzNzEuNzMxNzg3IC0yMDYuMDMzODg0IA0KTCAzNzEuODkxNjIxIC0yMDYuMDMzODg0IA0KTCAzNzIuMDUxNDU0IC0yMDYuMDMzODg0IA0KTCAzNzIuMjExMjg4IC0yMDYuMDMzODg0IA0KTCAzNzIuMzcxMTIyIC0yMDYuMDMzODg0IA0KTCAzNzIuNTMwOTU2IC0yMDYuMDMzODg0IA0KTCAzNzIuNjkwNzkgLTIwNi4wMzM4ODQgDQpMIDM3Mi44NTA2MjQgLTIwNi4wMzM4ODQgDQpMIDM3My4wMTA0NTggLTIwNi4wMzM4ODQgDQpMIDM3My4xNzAyOTIgLTIwNi4wMzM4ODQgDQpMIDM3My4zMzAxMjYgLTIwNi4wMzM4ODQgDQpMIDM3My40ODk5NTkgLTIwNi4wMzM4ODQgDQpMIDM3My42NDk3OTMgLTIwNi4wMzM4ODQgDQpMIDM3My44MDk2MjcgLTIwNi4wMzM4ODQgDQpMIDM3My45Njk0NjEgLTIwNi4wMzM4ODQgDQpMIDM3NC4xMjkyOTUgLTIwNi4wMzM4ODQgDQpMIDM3NC4yODkxMjkgLTIwNi4wMzM4ODQgDQpMIDM3NC40NDg5NjMgLTIwNi4wMzM4ODQgDQpMIDM3NC42MDg3OTcgLTIwNi4wMzM4ODQgDQpMIDM3NC43Njg2MyAtMjA2LjAzMzg4NCANCkwgMzc0LjkyODQ2NCAtMjA2LjAzMzg4NCANCkwgMzc1LjA4ODI5OCAtMjA2LjAzMzg4NCANCkwgMzc1LjI0ODEzMiAtMjA2LjAzMzg4NCANCkwgMzc1LjQwNzk2NiAtMjA2LjAzMzg4NCANCkwgMzc1LjU2NzggLTIwNi4wMzM4ODQgDQpMIDM3NS43Mjc2MzQgLTIwNi4wMzM4ODQgDQpMIDM3NS44ODc0NjggLTIwNi4wMzM4ODQgDQpMIDM3Ni4wNDczMDIgLTIwNi4wMzM4ODQgDQpMIDM3Ni4yMDcxMzUgLTIwNi4wMzM4ODQgDQpMIDM3Ni4zNjY5NjkgLTIwNi4wMzM4ODQgDQpMIDM3Ni41MjY4MDMgLTIwNi4wMzM4ODQgDQpMIDM3Ni42ODY2MzcgLTIwNi4wMzM4ODQgDQpMIDM3Ni44NDY0NzEgLTIwNi4wMzM4ODQgDQpMIDM3Ny4wMDYzMDUgLTIwNi4wMzM4ODQgDQpMIDM3Ny4xNjYxMzkgLTIwNi4wMzM4ODQgDQpMIDM3Ny4zMjU5NzMgLTIwNi4wMzM4ODQgDQpMIDM3Ny40ODU4MDcgLTIwNi4wMzM4ODQgDQpMIDM3Ny42NDU2NCAtMjA2LjAzMzg4NCANCkwgMzc3LjgwNTQ3NCAtMjA2LjAzMzg4NCANCkwgMzc3Ljk2NTMwOCAtMjA2LjAzMzg4NCANCkwgMzc4LjEyNTE0MiAtMjA2LjAzMzg4NCANCkwgMzc4LjI4NDk3NiAtMjA2LjAzMzg4NCANCkwgMzc4LjQ0NDgxIC0yMDYuMDMzODg0IA0KTCAzNzguNjA0NjQ0IC0yMDYuMDMzODg0IA0KTCAzNzguNzY0NDc4IC0yMDYuMDMzODg0IA0KTCAzNzguOTI0MzExIC0yMDYuMDMzODg0IA0KTCAzNzkuMDg0MTQ1IC0yMDYuMDMzODg0IA0KTCAzNzkuMjQzOTc5IC0yMDYuMDMzODg0IA0KTCAzNzkuNDAzODEzIC0yMDYuMDMzODg0IA0KTCAzNzkuNTYzNjQ3IC0yMDYuMDMzODg0IA0KTCAzNzkuNzIzNDgxIC0yMDYuMDMzODg0IA0KTCAzNzkuODgzMzE1IC0yMDYuMDMzODg0IA0KTCAzODAuMDQzMTQ5IC0yMDYuMDMzODg0IA0KTCAzODAuMjAyOTgzIC0yMDYuMDMzODg0IA0KTCAzODAuMzYyODE2IC0yMDYuMDMzODg0IA0KTCAzODAuNTIyNjUgLTIwNi4wMzM4ODQgDQpMIDM4MC42ODI0ODQgLTIwNi4wMzM4ODQgDQpMIDM4MC44NDIzMTggLTIwNi4wMzM4ODQgDQpMIDM4MS4wMDIxNTIgLTIwNi4wMzM4ODQgDQpMIDM4MS4xNjE5ODYgLTIwNi4wMzM4ODQgDQpMIDM4MS4zMjE4MiAtMjA2LjAzMzg4NCANCkwgMzgxLjQ4MTY1NCAtMjA2LjAzMzg4NCANCkwgMzgxLjY0MTQ4NyAtMjA2LjAzMzg4NCANCkwgMzgxLjgwMTMyMSAtMjA2LjAzMzg4NCANCkwgMzgxLjk2MTE1NSAtMjA2LjAzMzg4NCANCkwgMzgyLjEyMDk4OSAtMjA2LjAzMzg4NCANCkwgMzgyLjI4MDgyMyAtMjA2LjAzMzg4NCANCkwgMzgyLjQ0MDY1NyAtMjA2LjAzMzg4NCANCkwgMzgyLjYwMDQ5MSAtMjA2LjAzMzg4NCANCkwgMzgyLjc2MDMyNSAtMjA2LjAzMzg4NCANCkwgMzgyLjkyMDE1OSAtMjA2LjAzMzg4NCANCkwgMzgzLjA3OTk5MiAtMjA2LjAzMzg4NCANCkwgMzgzLjIzOTgyNiAtMjA2LjAzMzg4NCANCkwgMzgzLjM5OTY2IC0yMDYuMDMzODg0IA0KTCAzODMuNTU5NDk0IC0yMDYuMDMzODg0IA0KTCAzODMuNzE5MzI4IC0yMDYuMDMzODg0IA0KTCAzODMuODc5MTYyIC0yMDYuMDMzODg0IA0KTCAzODQuMDM4OTk2IC0yMDYuMDMzODg0IA0KTCAzODQuMTk4ODMgLTIwNi4wMzM4ODQgDQpMIDM4NC4zNTg2NjQgLTIwNi4wMzM4ODQgDQpMIDM4NC41MTg0OTcgLTIwNi4wMzM4ODQgDQpMIDM4NC42NzgzMzEgLTIwNi4wMzM4ODQgDQpMIDM4NC44MzgxNjUgLTIwNi4wMzM4ODQgDQpMIDM4NC45OTc5OTkgLTIwNi4wMzM4ODQgDQpMIDM4NS4xNTc4MzMgLTIwNi4wMzM4ODQgDQpMIDM4NS4zMTc2NjcgLTIwNi4wMzM4ODQgDQpMIDM4NS40Nzc1MDEgLTIwNi4wMzM4ODQgDQpMIDM4NS42MzczMzUgLTIwNi4wMzM4ODQgDQpMIDM4NS43OTcxNjggLTIwNi4wMzM4ODQgDQpMIDM4NS45NTcwMDIgLTIwNi4wMzM4ODQgDQpMIDM4Ni4xMTY4MzYgLTIwNi4wMzM4ODQgDQpMIDM4Ni4yNzY2NyAtMjA2LjAzMzg4NCANCkwgMzg2LjQzNjUwNCAtMjA2LjAzMzg4NCANCkwgMzg2LjU5NjMzOCAtMjA2LjAzMzg4NCANCkwgMzg2Ljc1NjE3MiAtMjA2LjAzMzg4NCANCkwgMzg2LjkxNjAwNiAtMjA2LjAzMzg4NCANCkwgMzg3LjA3NTg0IC0yMDYuMDMzODg0IA0KTCAzODcuMjM1NjczIC0yMDYuMDMzODg0IA0KTCAzODcuMzk1NTA3IC0yMDYuMDMzODg0IA0KTCAzODcuNTU1MzQxIC0yMDYuMDMzODg0IA0KTCAzODcuNzE1MTc1IC0yMDYuMDMzODg0IA0KTCAzODcuODc1MDA5IC0yMDYuMDMzODg0IA0KTCAzODguMDM0ODQzIC0yMDYuMDMzODg0IA0KTCAzODguMTk0Njc3IC0yMDYuMDMzODg0IA0KTCAzODguMzU0NTExIC0yMDYuMDMzODg0IA0KTCAzODguNTE0MzQ1IC0yMDYuMDMzODg0IA0KTCAzODguNjc0MTc4IC0yMDYuMDMzODg0IA0KTCAzODguODM0MDEyIC0yMDYuMDMzODg0IA0KTCAzODguOTkzODQ2IC0yMDYuMDMzODg0IA0KTCAzODkuMTUzNjggLTIwNi4wMzM4ODQgDQpMIDM4OS4zMTM1MTQgLTIwNi4wMzM4ODQgDQpMIDM4OS40NzMzNDggLTIwNi4wMzM4ODQgDQpMIDM4OS42MzMxODIgLTIwNi4wMzM4ODQgDQpMIDM4OS43OTMwMTYgLTIwNi4wMzM4ODQgDQpMIDM4OS45NTI4NDkgLTIwNi4wMzM4ODQgDQpMIDM5MC4xMTI2ODMgLTIwNi4wMzM4ODQgDQpMIDM5MC4yNzI1MTcgLTIwNi4wMzM4ODQgDQpMIDM5MC40MzIzNTEgLTIwNi4wMzM4ODQgDQpMIDM5MC41OTIxODUgLTIwNi4wMzM4ODQgDQpMIDM5MC43NTIwMTkgLTIwNi4wMzM4ODQgDQpMIDM5MC45MTE4NTMgLTIwNi4wMzM4ODQgDQpMIDM5MS4wNzE2ODcgLTIwNi4wMzM4ODQgDQpMIDM5MS4yMzE1MjEgLTIwNi4wMzM4ODQgDQpMIDM5MS4zOTEzNTQgLTIwNi4wMzM4ODQgDQpMIDM5MS41NTExODggLTIwNi4wMzM4ODQgDQpMIDM5MS43MTEwMjIgLTIwNi4wMzM4ODQgDQpMIDM5MS44NzA4NTYgLTIwNi4wMzM4ODQgDQpMIDM5Mi4wMzA2OSAtMjA2LjAzMzg4NCANCkwgMzkyLjE5MDUyNCAtMjA2LjAzMzg4NCANCkwgMzkyLjM1MDM1OCAtMjA2LjAzMzg4NCANCkwgMzkyLjUxMDE5MiAtMjA2LjAzMzg4NCANCkwgMzkyLjY3MDAyNSAtMjA2LjAzMzg4NCANCkwgMzkyLjgyOTg1OSAtMjA1LjU4MjcxNCANCkwgMzkyLjk4OTY5MyAtMjA1LjUxNjM2NyANCkwgMzkzLjE0OTUyNyAtMjA1LjQzMDg3NCANCkwgMzkzLjMwOTM2MSAtMjA1LjMzMzA4NCANCkwgMzkzLjQ2OTE5NSAtMjA1LjIyMjQ3NSANCkwgMzkzLjYyOTAyOSAtMjA1LjA4MTcwOSANCkwgMzkzLjc4ODg2MyAtMjA0LjkyMTc3MiANCkwgMzkzLjk0ODY5NyAtMjA0Ljc0MDIwMyANCkwgMzk0LjEwODUzIC0yMDQuNTEwNzcyIA0KTCAzOTQuMjY4MzY0IC0yMDQuMjUxMjIgDQpMIDM5NC40MjgxOTggLTIwMy45NTUzNDEgDQpMIDM5NC41ODgwMzIgLTIwMy41ODU1MTUgDQpMIDM5NC43NDc4NjYgLTIwMy4xNjc5MjYgDQpMIDM5NC45MDc3IC0yMDIuNjg4ODI0IA0KTCAzOTUuMDY3NTM0IC0yMDIuMDk2MDE0IA0KTCAzOTUuMjI3MzY4IC0yMDEuNDI4NzIyIA0KTCAzOTUuMzg3MjAyIC0yMDAuNjU5NDIgDQpMIDM5NS41NDcwMzUgLTE5OS43MTgyNTkgDQpMIDM5NS43MDY4NjkgLTE5OC42NjMxMzEgDQpMIDM5NS44NjY3MDMgLTE5Ny40NDI3NiANCkwgMzk2LjAyNjUzNyAtMTk1Ljk3MDYyNiANCkwgMzk2LjE4NjM3MSAtMTk0LjMzMDM1OCANCkwgMzk2LjM0NjIwNSAtMTkyLjQzMzc0NyANCkwgMzk2LjUwNjAzOSAtMTkwLjE4OTQyIA0KTCAzOTYuNjY1ODczIC0xODcuNzEzMzkyIA0KTCAzOTYuODI1NzA2IC0xODQuODcwOSANCkwgMzk2Ljk4NTU0IC0xODEuNTk1Njk4IA0KTCAzOTcuMTQ1Mzc0IC0xNzguMDM1NTk1IA0KTCAzOTcuMzA1MjA4IC0xNzQuMDE4NTUgDQpMIDM5Ny40NjUwNDIgLTE2OS41NTQ1MzcgDQpMIDM5Ny42MjQ4NzYgLTE2NC44MDM5NzcgDQpMIDM5Ny43ODQ3MSAtMTU5LjYwOTQzOCANCkwgMzk3Ljk0NDU0NCAtMTU0LjA4NTg1NCANCkwgMzk4LjEwNDM3OCAtMTQ4LjM2MjQgDQpMIDM5OC4yNjQyMTEgLTE0Mi4zNzcwMTUgDQpMIDM5OC40MjQwNDUgLTEzNi4yOTYxOTQgDQpMIDM5OC41ODM4NzkgLTEzMC4xNzQ4NCANCkwgMzk4Ljc0MzcxMyAtMTI0LjA4NjY1MSANCkwgMzk4LjkwMzU0NyAtMTE4LjEyNjE5OSANCkwgMzk5LjA2MzM4MSAtMTEyLjI3NzM3MyANCkwgMzk5LjIyMzIxNSAtMTA2LjcwNjk0MiANCkwgMzk5LjM4MzA0OSAtMTAxLjM3OTg1NSANCkwgMzk5LjU0Mjg4MiAtOTYuMjQ5Njk2IA0KTCAzOTkuNzAyNzE2IC05MS41MTYxNzQgDQpMIDM5OS44NjI1NSAtODcuMDQ2OTM0IA0KTCA0MDAuMDIyMzg0IC04Mi43OTgzNTggDQpMIDQwMC4xODIyMTggLTc4Ljk3NTA3NyANCkwgNDAwLjM0MjA1MiAtNzUuMzk2ODAxIA0KTCA0MDAuNTAxODg2IC03Mi4wMzM2NDMgDQpMIDQwMC42NjE3MiAtNjkuMDgxNTA4IA0KTCA0MDAuODIxNTU0IC02Ni4zMzcxMzcgDQpMIDQwMC45ODEzODcgLTYzLjc4NjMwNiANCkwgNDAxLjE0MTIyMSAtNjEuNjAxNDU4IA0KTCA0MDEuMzAxMDU1IC01OS41NzkwNDYgDQpMIDQwMS40NjA4ODkgLTU3LjcyNTk0NSANCkwgNDAxLjYyMDcyMyAtNTYuMTYwODg5IA0KTCA0MDEuNzgwNTU3IC01NC43MjIxMDMgDQpMIDQwMS45NDAzOTEgLTUzLjQyMzA3MyANCkwgNDAyLjEwMDIyNSAtNTIuMzM0OTM5IA0KTCA0MDIuMjYwMDU5IC01MS4zNDE0NDMgDQpMIDQwMi40MTk4OTIgLTUwLjQ1NzMwMyANCkwgNDAyLjU3OTcyNiAtNDkuNzIzMjYxIA0KTCA0MDIuNzM5NTYgLTQ5LjA1ODc3OCANCkwgNDAyLjg5OTM5NCAtNDguNDc3OTAyIA0KTCA0MDMuMDU5MjI4IC00OC4wMDIyOTIgDQpMIDQwMy4yMTkwNjIgLTQ3LjU3ODI0MyANCkwgNDAzLjM3ODg5NiAtNDcuMjE4ODQ2IA0KTCA0MDMuNTM4NzMgLTQ2LjkzNTE5MyANCkwgNDAzLjY5ODU2MyAtNDYuNjkxMTk0IA0KTCA0MDMuODU4Mzk3IC00Ni40OTkyMiANCkwgNDA0LjAxODIzMSAtNDYuMzY1NjMzIA0KTCA0MDQuMTc4MDY1IC00Ni4yNjUxNDcgDQpMIDQwNC4zMzc4OTkgLTQ2LjIxMDkwMSANCkwgNDA0LjQ5NzczMyAtNDYuMjA4MDcxIA0KTCA0MDQuNjU3NTY3IC00Ni4yMzY3OTMgDQpMIDQwNC44MTc0MDEgLTQ2LjMxMjYwMSANCkwgNDA0Ljk3NzIzNSAtNDYuNDQwNjEgDQpMIDQwNS4xMzcwNjggLTQ2LjYwMzI4NyANCkwgNDA1LjI5NjkwMiAtNDYuODIyMDggDQpMIDQwNS40NTY3MzYgLTQ3LjEwMjMxMyANCkwgNDA1LjYxNjU3IC00Ny40MjU5NTUgDQpMIDQwNS43NzY0MDQgLTQ3LjgyNTA1NSANCkwgNDA1LjkzNjIzOCAtNDguMzAzMDMxIA0KTCA0MDYuMDk2MDcyIC00OC44Mzk1NTMgDQpMIDQwNi4yNTU5MDYgLTQ5LjQ4NTAxNyANCkwgNDA2LjQxNTczOSAtNTAuMjM4MDMgDQpMIDQwNi41NzU1NzMgLTUxLjA3Mzc5IA0KTCA0MDYuNzM1NDA3IC01Mi4wNzIyNDEgDQpMIDQwNi44OTUyNDEgLTUzLjIxOTk5IA0KTCA0MDcuMDU1MDc1IC01NC40ODY2ODcgDQpMIDQwNy4yMTQ5MDkgLTU1Ljk5OTM4IA0KTCA0MDcuMzc0NzQzIC01Ny43MTg3NTMgDQpMIDQwNy41MzQ1NzcgLTU5LjYwODQwOCANCkwgNDA3LjY5NDQxMSAtNjEuODYzMjQ2IA0KTCA0MDcuODU0MjQ0IC02NC4zOTU0ODggDQpMIDQwOC4wMTQwNzggLTY3LjE2NDI4MSANCkwgNDA4LjE3MzkxMiAtNzAuNDUwNTkyIA0KTCA0MDguMzMzNzQ2IC03NC4wODA2MzcgDQpMIDQwOC40OTM1OCAtNzguMDE1MzIgDQpMIDQwOC42NTM0MTQgLTgyLjYwMzgxMSANCkwgNDA4LjgxMzI0OCAtODcuNTUzMzYgDQpMIDQwOC45NzMwODIgLTkyLjgzOTMzOSANCkwgNDA5LjEzMjkxNiAtOTguNzc3NTI2IA0KTCA0MDkuMjkyNzQ5IC0xMDQuOTgzNDE1IA0KTCA0MDkuNDUyNTgzIC0xMTEuNDY4MzcgDQpMIDQwOS42MTI0MTcgLTExOC4zMDY3MTIgDQpMIDQwOS43NzIyNTEgLTEyNS4yMTEzODUgDQpMIDQwOS45MzIwODUgLTEzMi4xODMyODIgDQpMIDQxMC4wOTE5MTkgLTEzOS4wMjY1MTUgDQpMIDQxMC4yNTE3NTMgLTE0NS43MDA1MTkgDQpMIDQxMC40MTE1ODcgLTE1Mi4xNTk0MzcgDQpMIDQxMC41NzE0MiAtMTU4LjEwMjExNSANCkwgNDEwLjczMTI1NCAtMTYzLjcyNTg1IA0KTCA0MTAuODkxMDg4IC0xNjguOTQyMDQ3IA0KTCA0MTEuMDUwOTIyIC0xNzMuNTIyNDAxIA0KTCA0MTEuMjEwNzU2IC0xNzcuNzU5OTY2IA0KTCA0MTEuMzcwNTkgLTE4MS41NTMzOSANCkwgNDExLjUzMDQyNCAtMTg0Ljc5MjQ3MSANCkwgNDExLjY5MDI1OCAtMTg3Ljc0MjQ5NyANCkwgNDExLjg1MDA5MiAtMTkwLjMxMzI2NiANCkwgNDEyLjAwOTkyNSAtMTkyLjQ4MDMzNCANCkwgNDEyLjE2OTc1OSAtMTk0LjQzNDI1NiANCkwgNDEyLjMyOTU5MyAtMTk2LjEwNDA5NyANCkwgNDEyLjQ4OTQyNyAtMTk3LjUwNjEyNSANCkwgNDEyLjY0OTI2MSAtMTk4Ljc2MjEzNyANCkwgNDEyLjgwOTA5NSAtMTk5LjgyMDMxOCANCkwgNDEyLjk2ODkyOSAtMjAwLjcxMDIxNiANCkwgNDEzLjEyODc2MyAtMjAxLjUwNDE3NSANCkwgNDEzLjI4ODU5NyAtMjAyLjE2NTY4MiANCkwgNDEzLjQ0ODQzIC0yMDIuNzI0NzE3IA0KTCA0MTMuNjA4MjY0IC0yMDMuMjIyMjMgDQpMIDQxMy43NjgwOTggLTIwMy42MzI5OTUgDQpMIDQxMy45Mjc5MzIgLTIwMy45ODE4NjggDQpMIDQxNC4wODc3NjYgLTIwNC4yOTE1OTcgDQpMIDQxNC4yNDc2IC0yMDQuNTQ1MzI4IA0KTCA0MTQuNDA3NDM0IC0yMDQuNzYyNjQ1IA0KTCA0MTQuNTY3MjY4IC0yMDQuOTU1NDQ5IA0KTCA0MTQuNzI3MTAxIC0yMDUuMTEyMDggDQpMIDQxNC44ODY5MzUgLTIwNS4yNDY5NjcgDQpMIDQxNS4wNDY3NjkgLTIwNS4zNjYzNjQgDQpMIDQxNS4yMDY2MDMgLTIwNS40NjI3MTkgDQpMIDQxNS4zNjY0MzcgLTIwNS41NDY1NTQgDQpMIDQxNS41MjYyNzEgLTIwNS42MjA4MjggDQpMIDQxNS42ODYxMDUgLTIwNS42ODAxMDkgDQpMIDQxNS44NDU5MzkgLTIwNS43MzE5NDQgDQpMIDQxNi4wMDU3NzMgLTIwNS43Nzc3NDUgDQpMIDQxNi4xNjU2MDYgLTIwNS44MTQxOTMgDQpMIDQxNi4zMjU0NCAtMjA1Ljg0NjQyNyANCkwgNDE2LjQ4NTI3NCAtMjA1Ljg3NDk5NyANCkwgNDE2LjY0NTEwOCAtMjA1Ljg5NzQ1MyANCkwgNDE2LjgwNDk0MiAtMjA2LjAzMzg4NCANCkwgNDE2Ljk2NDc3NiAtMjA2LjAzMzg4NCANCkwgNDE3LjEyNDYxIC0yMDYuMDMzODg0IA0KTCA0MTcuMjg0NDQ0IC0yMDYuMDMzODg0IA0KTCA0MTcuNDQ0Mjc3IC0yMDYuMDMzODg0IA0KTCA0MTcuNjA0MTExIC0yMDYuMDMzODg0IA0KTCA0MTcuNzYzOTQ1IC0yMDYuMDMzODg0IA0KTCA0MTcuOTIzNzc5IC0yMDYuMDMzODg0IA0KTCA0MTguMDgzNjEzIC0yMDYuMDMzODg0IA0KTCA0MTguMjQzNDQ3IC0yMDYuMDMzODg0IA0KTCA0MTguNDAzMjgxIC0yMDYuMDMzODg0IA0KTCA0MTguNTYzMTE1IC0yMDYuMDMzODg0IA0KTCA0MTguNzIyOTQ5IC0yMDYuMDMzODg0IA0KTCA0MTguODgyNzgyIC0yMDYuMDMzODg0IA0KTCA0MTkuMDQyNjE2IC0yMDYuMDMzODg0IA0KTCA0MTkuMjAyNDUgLTIwNi4wMzM4ODQgDQpMIDQxOS4zNjIyODQgLTIwNi4wMzM4ODQgDQpMIDQxOS41MjIxMTggLTIwNi4wMzM4ODQgDQpMIDQxOS42ODE5NTIgLTIwNi4wMzM4ODQgDQpMIDQxOS44NDE3ODYgLTIwNi4wMzM4ODQgDQpMIDQyMC4wMDE2MiAtMjA2LjAzMzg4NCANCkwgNDIwLjE2MTQ1NCAtMjA2LjAzMzg4NCANCkwgNDIwLjMyMTI4NyAtMjA2LjAzMzg4NCANCkwgNDIwLjQ4MTEyMSAtMjA2LjAzMzg4NCANCkwgNDIwLjY0MDk1NSAtMjA2LjAzMzg4NCANCkwgNDIwLjgwMDc4OSAtMjA2LjAzMzg4NCANCkwgNDIwLjk2MDYyMyAtMjA2LjAzMzg4NCANCkwgNDIxLjEyMDQ1NyAtMjA2LjAzMzg4NCANCkwgNDIxLjI4MDI5MSAtMjA2LjAzMzg4NCANCkwgNDIxLjQ0MDEyNSAtMjA2LjAzMzg4NCANCkwgNDIxLjU5OTk1OCAtMjA2LjAzMzg4NCANCkwgNDIxLjc1OTc5MiAtMjA2LjAzMzg4NCANCkwgNDIxLjkxOTYyNiAtMjA2LjAzMzg4NCANCkwgNDIyLjA3OTQ2IC0yMDYuMDMzODg0IA0KTCA0MjIuMjM5Mjk0IC0yMDYuMDMzODg0IA0KTCA0MjIuMzk5MTI4IC0yMDYuMDMzODg0IA0KTCA0MjIuNTU4OTYyIC0yMDYuMDMzODg0IA0KTCA0MjIuNzE4Nzk2IC0yMDYuMDMzODg0IA0KTCA0MjIuODc4NjMgLTIwNi4wMzM4ODQgDQpMIDQyMy4wMzg0NjMgLTIwNi4wMzM4ODQgDQpMIDQyMy4xOTgyOTcgLTIwNi4wMzM4ODQgDQpMIDQyMy4zNTgxMzEgLTIwNi4wMzM4ODQgDQpMIDQyMy41MTc5NjUgLTIwNi4wMzM4ODQgDQpMIDQyMy42Nzc3OTkgLTIwNi4wMzM4ODQgDQpMIDQyMy44Mzc2MzMgLTIwNi4wMzM4ODQgDQpMIDQyMy45OTc0NjcgLTIwNi4wMzM4ODQgDQpMIDQyNC4xNTczMDEgLTIwNi4wMzM4ODQgDQpMIDQyNC4zMTcxMzQgLTIwNi4wMzM4ODQgDQpMIDQyNC40NzY5NjggLTIwNi4wMzM4ODQgDQpMIDQyNC42MzY4MDIgLTIwNi4wMzM4ODQgDQpMIDQyNC43OTY2MzYgLTIwNi4wMzM4ODQgDQpMIDQyNC45NTY0NyAtMjA2LjAzMzg4NCANCkwgNDI1LjExNjMwNCAtMjA2LjAzMzg4NCANCkwgNDI1LjI3NjEzOCAtMjA2LjAzMzg4NCANCkwgNDI1LjQzNTk3MiAtMjA2LjAzMzg4NCANCkwgNDI1LjU5NTgwNiAtMjA2LjAzMzg4NCANCkwgNDI1Ljc1NTYzOSAtMjA2LjAzMzg4NCANCkwgNDI1LjkxNTQ3MyAtMjA2LjAzMzg4NCANCkwgNDI2LjA3NTMwNyAtMjA2LjAzMzg4NCANCkwgNDI2LjIzNTE0MSAtMjA2LjAzMzg4NCANCkwgNDI2LjM5NDk3NSAtMjA2LjAzMzg4NCANCkwgNDI2LjU1NDgwOSAtMjA2LjAzMzg4NCANCkwgNDI2LjcxNDY0MyAtMjA2LjAzMzg4NCANCkwgNDI2Ljg3NDQ3NyAtMjA2LjAzMzg4NCANCkwgNDI3LjAzNDMxMSAtMjA2LjAzMzg4NCANCkwgNDI3LjE5NDE0NCAtMjA2LjAzMzg4NCANCkwgNDI3LjM1Mzk3OCAtMjA2LjAzMzg4NCANCkwgNDI3LjUxMzgxMiAtMjA2LjAzMzg4NCANCkwgNDI3LjY3MzY0NiAtMjA2LjAzMzg4NCANCkwgNDI3LjgzMzQ4IC0yMDYuMDMzODg0IA0KTCA0MjcuOTkzMzE0IC0yMDYuMDMzODg0IA0KTCA0MjguMTUzMTQ4IC0yMDYuMDMzODg0IA0KTCA0MjguMzEyOTgyIC0yMDYuMDMzODg0IA0KTCA0MjguNDcyODE1IC0yMDYuMDMzODg0IA0KTCA0MjguNjMyNjQ5IC0yMDYuMDMzODg0IA0KTCA0MjguNzkyNDgzIC0yMDYuMDMzODg0IA0KTCA0MjguOTUyMzE3IC0yMDYuMDMzODg0IA0KTCA0MjkuMTEyMTUxIC0yMDYuMDMzODg0IA0KTCA0MjkuMjcxOTg1IC0yMDYuMDMzODg0IA0KTCA0MjkuNDMxODE5IC0yMDYuMDMzODg0IA0KTCA0MjkuNTkxNjUzIC0yMDYuMDMzODg0IA0KTCA0MjkuNzUxNDg3IC0yMDYuMDMzODg0IA0KTCA0MjkuOTExMzIgLTIwNi4wMzM4ODQgDQpMIDQzMC4wNzExNTQgLTIwNi4wMzM4ODQgDQpMIDQzMC4yMzA5ODggLTIwNi4wMzM4ODQgDQpMIDQzMC4zOTA4MjIgLTIwNi4wMzM4ODQgDQpMIDQzMC41NTA2NTYgLTIwNi4wMzM4ODQgDQpMIDQzMC43MTA0OSAtMjA2LjAzMzg4NCANCkwgNDMwLjg3MDMyNCAtMjA2LjAzMzg4NCANCkwgNDMxLjAzMDE1OCAtMjA2LjAzMzg4NCANCkwgNDMxLjE4OTk5MiAtMjA2LjAzMzg4NCANCkwgNDMxLjM0OTgyNSAtMjA2LjAzMzg4NCANCkwgNDMxLjUwOTY1OSAtMjA2LjAzMzg4NCANCkwgNDMxLjY2OTQ5MyAtMjA2LjAzMzg4NCANCkwgNDMxLjgyOTMyNyAtMjA2LjAzMzg4NCANCkwgNDMxLjk4OTE2MSAtMjA2LjAzMzg4NCANCkwgNDMyLjE0ODk5NSAtMjA2LjAzMzg4NCANCkwgNDMyLjMwODgyOSAtMjA2LjAzMzg4NCANCkwgNDMyLjQ2ODY2MyAtMjA2LjAzMzg4NCANCkwgNDMyLjYyODQ5NiAtMjA2LjAzMzg4NCANCkwgNDMyLjc4ODMzIC0yMDYuMDMzODg0IA0KTCA0MzIuOTQ4MTY0IC0yMDYuMDMzODg0IA0KTCA0MzMuMTA3OTk4IC0yMDYuMDMzODg0IA0KTCA0MzMuMjY3ODMyIC0yMDYuMDMzODg0IA0KTCA0MzMuNDI3NjY2IC0yMDYuMDMzODg0IA0KTCA0MzMuNTg3NSAtMjA2LjAzMzg4NCANCkwgNDMzLjc0NzMzNCAtMjA2LjAzMzg4NCANCkwgNDMzLjkwNzE2OCAtMjA2LjAzMzg4NCANCkwgNDM0LjA2NzAwMSAtMjA2LjAzMzg4NCANCkwgNDM0LjIyNjgzNSAtMjA2LjAzMzg4NCANCkwgNDM0LjM4NjY2OSAtMjA2LjAzMzg4NCANCkwgNDM0LjU0NjUwMyAtMjA2LjAzMzg4NCANCkwgNDM0LjcwNjMzNyAtMjA2LjAzMzg4NCANCkwgNDM0Ljg2NjE3MSAtMjA2LjAzMzg4NCANCkwgNDM1LjAyNjAwNSAtMjA2LjAzMzg4NCANCkwgNDM1LjE4NTgzOSAtMjA2LjAzMzg4NCANCkwgNDM1LjM0NTY3MiAtMjA2LjAzMzg4NCANCkwgNDM1LjUwNTUwNiAtMjA2LjAzMzg4NCANCkwgNDM1LjY2NTM0IC0yMDYuMDMzODg0IA0KTCA0MzUuODI1MTc0IC0yMDYuMDMzODg0IA0KTCA0MzUuOTg1MDA4IC0yMDYuMDMzODg0IA0KTCA0MzYuMTQ0ODQyIC0yMDYuMDMzODg0IA0KTCA0MzYuMzA0Njc2IC0yMDYuMDMzODg0IA0KTCA0MzYuNDY0NTEgLTIwNi4wMzM4ODQgDQpMIDQzNi42MjQzNDQgLTIwNi4wMzM4ODQgDQpMIDQzNi43ODQxNzcgLTIwNi4wMzM4ODQgDQpMIDQzNi45NDQwMTEgLTIwNS42MDkyMTcgDQpMIDQzNy4xMDM4NDUgLTIwNS41NDI5NjEgDQpMIDQzNy4yNjM2NzkgLTIwNS40NjUwNzEgDQpMIDQzNy40MjM1MTMgLTIwNS4zNzczMjcgDQpMIDQzNy41ODMzNDcgLTIwNS4yNjY3MTkgDQpMIDQzNy43NDMxODEgLTIwNS4xMzgzMyANCkwgNDM3LjkwMzAxNSAtMjA0Ljk5NDQgDQpMIDQzOC4wNjI4NDkgLTIwNC44MTI4MzEgDQpMIDQzOC4yMjI2ODIgLTIwNC42MDM2NzYgDQpMIDQzOC4zODI1MTYgLTIwNC4zNjk1NzEgDQpMIDQzOC41NDIzNSAtMjA0LjA3MzY5MyANCkwgNDM4LjcwMjE4NCAtMjAzLjczNjIyOCANCkwgNDM4Ljg2MjAxOCAtMjAzLjM1OTQ0NCANCkwgNDM5LjAyMTg1MiAtMjAyLjg4MDQ2NSANCkwgNDM5LjE4MTY4NiAtMjAyLjMzOTEzIA0KTCA0MzkuMzQxNTIgLTIwMS43MzEzNCANCkwgNDM5LjUwMTM1MyAtMjAwLjk2NzE0MSANCkwgNDM5LjY2MTE4NyAtMjAwLjEwNjUzMiANCkwgNDM5LjgyMTAyMSAtMTk5LjEzNTg0OSANCkwgNDM5Ljk4MDg1NSAtMTk3LjkzMDkwOSANCkwgNDQwLjE0MDY4OSAtMTk2LjU4MTEzOCANCkwgNDQwLjMwMDUyMyAtMTk1LjA1NDg1OCANCkwgNDQwLjQ2MDM1NyAtMTkzLjE5MjM5MSANCkwgNDQwLjYyMDE5MSAtMTkxLjEyMzUwMSANCkwgNDQwLjc4MDAyNSAtMTg4Ljc4ODMwNiANCkwgNDQwLjkzOTg1OCAtMTg2LjAwNzg5NCANCkwgNDQxLjA5OTY5MiAtMTgyLjk1OTcxNSANCkwgNDQxLjI1OTUyNiAtMTc5LjU0OTY2MyANCkwgNDQxLjQxOTM2IC0xNzUuNjI1MzY4IA0KTCA0NDEuNTc5MTk0IC0xNzEuNDA1NTI5IA0KTCA0NDEuNzM5MDI4IC0xNjYuNzc4MDI0IA0KTCA0NDEuODk4ODYyIC0xNjEuNjg3MjQ3IA0KTCA0NDIuMDU4Njk2IC0xNTYuMzUxMjA5IA0KTCA0NDIuMjE4NTI5IC0xNTAuNjg3ODM2IA0KTCA0NDIuMzc4MzYzIC0xNDQuNzcxMTYyIA0KTCA0NDIuNTM4MTk3IC0xMzguNzQ3MTk0IA0KTCA0NDIuNjk4MDMxIC0xMzIuNjE5NzAyIA0KTCA0NDIuODU3ODY1IC0xMjYuNTIxOTIzIA0KTCA0NDMuMDE3Njk5IC0xMjAuNDgxNzk1IA0KTCA0NDMuMTc3NTMzIC0xMTQuNTkyODM2IA0KTCA0NDMuMzM3MzY3IC0xMDguOTM1MTIxIA0KTCA0NDMuNDk3MjAxIC0xMDMuNDQ4NzMgDQpMIDQ0My42NTcwMzQgLTk4LjI3NjU1MSANCkwgNDQzLjgxNjg2OCAtOTMuNDA5NTg2IA0KTCA0NDMuOTc2NzAyIC04OC43NTgyNjYgDQpMIDQ0NC4xMzY1MzYgLTg0LjQ3OTkyOSANCkwgNDQ0LjI5NjM3IC04MC41MDQzOTIgDQpMIDQ0NC40NTYyMDQgLTc2Ljc0ODA2NSANCkwgNDQ0LjYxNjAzOCAtNzMuMzY5OTE0IA0KTCA0NDQuNzc1ODcyIC03MC4yNjIzNTkgDQpMIDQ0NC45MzU3MDYgLTY3LjM1ODE3MyANCkwgNDQ1LjA5NTUzOSAtNjQuODA1NTY4IA0KTCA0NDUuMjU1MzczIC02Mi40NzU0MDEgDQpMIDQ0NS40MTUyMDcgLTYwLjMyMDI4MiANCkwgNDQ1LjU3NTA0MSAtNTguNDY3MTc4IA0KTCA0NDUuNzM0ODc1IC01Ni43ODM5MTMgDQpMIDQ0NS44OTQ3MDkgLTU1LjI0MTcxNiANCkwgNDQ2LjA1NDU0MyAtNTMuOTQyNjg0IA0KTCA0NDYuMjE0Mzc3IC01Mi43NjUyMDYgDQpMIDQ0Ni4zNzQyMSAtNTEuNjk1MTAyIA0KTCA0NDYuNTM0MDQ0IC01MC44MTA5NjIgDQpMIDQ0Ni42OTM4NzggLTUwLjAxMTIxNCANCkwgNDQ2Ljg1MzcxMiAtNDkuMjkxMjg1IA0KTCA0NDcuMDEzNTQ2IC00OC43MTAyNDkgDQpMIDQ0Ny4xNzMzOCAtNDguMTg2OTkzIA0KTCA0NDcuMzMzMjE0IC00Ny43MjUyNTYgDQpMIDQ0Ny40OTMwNDggLTQ3LjM2MjU5OCANCkwgNDQ3LjY1Mjg4MiAtNDcuMDQzNDQ3IA0KTCA0NDcuODEyNzE1IC00Ni43NzI4MzYgDQpMIDQ0Ny45NzI1NDkgLTQ2LjU3NjAyIA0KTCA0NDguMTMyMzgzIC00Ni40MTQwNDYgDQpMIDQ0OC4yOTIyMTcgLTQ2LjI5MzAyMiANCkwgNDQ4LjQ1MjA1MSAtNDYuMjMyNTkgDQpMIDQ0OC42MTE4ODUgLTQ2LjIwMzgyIA0KTCA0NDguNzcxNzE5IC00Ni4yMTQ0NDkgDQpMIDQ0OC45MzE1NTMgLTQ2LjI4MjI4MSANCkwgNDQ5LjA5MTM4NyAtNDYuMzgyODk1IA0KTCA0NDkuMjUxMjIgLTQ2LjUyNzE1OSANCkwgNDQ5LjQxMTA1NCAtNDYuNzM0NTcyIA0KTCA0NDkuNTcwODg4IC00Ni45ODEyNCANCkwgNDQ5LjczMDcyMiAtNDcuMjgzOTQ1IA0KTCA0NDkuODkwNTU2IC00Ny42NjUzOTkgDQpMIDQ1MC4wNTAzOSAtNDguMDk4NDMxIA0KTCA0NTAuMjEwMjI0IC00OC42MDk5MzkgDQpMIDQ1MC4zNzAwNTggLTQ5LjIyNjgyNSANCkwgNDUwLjUyOTg5MSAtNDkuOTE1Nzk1IA0KTCA0NTAuNjg5NzI1IC01MC43MjEzOTMgDQpMIDQ1MC44NDk1NTkgLTUxLjY3Mjg3IA0KTCA0NTEuMDA5MzkzIC01Mi43Mjc0ODYgDQpMIDQ1MS4xNjkyMjcgLTUzLjk1ODc0NyANCkwgNDUxLjMyOTA2MSAtNTUuMzk0MzA3IA0KTCA0NTEuNDg4ODk1IC01Ni45NzgzNjQgDQpMIDQ1MS42NDg3MjkgLTU4LjgyOTMyNCANCkwgNDUxLjgwODU2MyAtNjAuOTYxMzE3IA0KTCA0NTEuOTY4Mzk2IC02My4zMDI0NDkgDQpMIDQ1Mi4xMjgyMyAtNjYuMDM1MDQgDQpMIDQ1Mi4yODgwNjQgLTY5LjEzNjA3NCANCkwgNDUyLjQ0Nzg5OCAtNzIuNTE2Mjg2IA0KTCA0NTIuNjA3NzMyIC03Ni40MjcxMzkgDQpMIDQ1Mi43Njc1NjYgLTgwLjc2ODQxOCANCkwgNDUyLjkyNzQgLTg1LjQ0MDIyOCANCkwgNDUzLjA4NzIzNCAtOTAuNzIzMDU4IA0KTCA0NTMuMjQ3MDY3IC05Ni40MDIyNTUgDQpMIDQ1My40MDY5MDEgLTEwMi4zODk0MyANCkwgNDUzLjU2NjczNSAtMTA4Ljg3NDM4NSANCkwgNDUzLjcyNjU2OSAtMTE1LjU2NzY5NiANCkwgNDUzLjg4NjQwMyAtMTIyLjQyMjY0NSANCkwgNDU0LjA0NjIzNyAtMTI5LjM5NDUyNiANCkwgNDU0LjIwNjA3MSAtMTM2LjI5MjI2MiANCkwgNDU0LjM2NTkwNSAtMTQzLjExNjk1NCANCkwgNDU0LjUyNTczOSAtMTQ5LjU3NTg3MyANCkwgNDU0LjY4NTU3MiAtMTU1Ljc0NDQ3MyANCkwgNDU0Ljg0NTQwNiAtMTYxLjYzODU3OSANCkwgNDU1LjAwNTI0IC0xNjYuODU1NTU4IA0KTCA0NTUuMTY1MDc0IC0xNzEuNzIzNzU0IA0KTCA0NTUuMzI0OTA4IC0xNzYuMjIwMzczIA0KTCA0NTUuNDg0NzQyIC0xODAuMDM2MDE0IA0KTCA0NTUuNjQ0NTc2IC0xODMuNTM0OTE3IA0KTCA0NTUuODA0NDEgLTE4Ni42Nzg3NyANCkwgNDU1Ljk2NDI0NCAtMTg5LjI4NDk2NyANCkwgNDU2LjEyNDA3NyAtMTkxLjY0ODIzNiANCkwgNDU2LjI4MzkxMSAtMTkzLjcyODQ4MSANCkwgNDU2LjQ0Mzc0NSAtMTk1LjQzNjE2MSANCkwgNDU2LjYwMzU3OSAtMTk2Ljk3MzMxMSANCkwgNDU2Ljc2MzQxMyAtMTk4LjMwNTM0NSANCkwgNDU2LjkyMzI0NyAtMTk5LjM5NzA0NSANCkwgNDU3LjA4MzA4MSAtMjAwLjM3NTIzNSANCkwgNDU3LjI0MjkxNSAtMjAxLjIxMjY4OCANCkwgNDU3LjQwMjc0OCAtMjAxLjkwMTA4IA0KTCA0NTcuNTYyNTgyIC0yMDIuNTE2MDk1IA0KTCA0NTcuNzIyNDE2IC0yMDMuMDM3NjUgDQpMIDQ1Ny44ODIyNSAtMjAzLjQ2ODY4OSANCkwgNDU4LjA0MjA4NCAtMjAzLjg1MjgzOCANCkwgNDU4LjIwMTkxOCAtMjA0LjE3NTQxMyANCkwgNDU4LjM2MTc1MiAtMjA0LjQ0MzgzNiANCkwgNDU4LjUyMTU4NiAtMjA0LjY4Mjg0MSANCkwgNDU4LjY4MTQyIC0yMDQuODgyMzUxIA0KTCA0NTguODQxMjUzIC0yMDUuMDQ5NDI4IA0KTCA0NTkuMDAxMDg3IC0yMDUuMTk3ODc5IA0KTCA0NTkuMTYwOTIxIC0yMDUuMzIwNTk4IA0KTCA0NTkuMzIwNzU1IC0yMDUuNDI0MTc3IA0KTCA0NTkuNDgwNTg5IC0yMDUuNTE2MjA4IA0KTCA0NTkuNjQwNDIzIC0yMDUuNTkyMDcyIA0KTCA0NTkuODAwMjU3IC0yMDUuNjU2Mzk3IA0KTCA0NTkuOTYwMDkxIC0yMDUuNzEzMzYxIA0KTCA0NjAuMTE5OTI0IC0yMDUuNzU5ODE3IA0KTCA0NjAuMjc5NzU4IC0yMDUuNzk5NjE0IA0KTCA0NjAuNDM5NTkyIC0yMDUuODM0OTEgDQpMIDQ2MC41OTk0MjYgLTIwNS44NjM3MDMgDQpMIDQ2MC43NTkyNiAtMjA1Ljg4ODQ3MSANCkwgNDYwLjkxOTA5NCAtMjA2LjAzMzg4NCANCkwgNDYxLjA3ODkyOCAtMjA2LjAzMzg4NCANCkwgNDYxLjIzODc2MiAtMjA2LjAzMzg4NCANCkwgNDYxLjM5ODU5NiAtMjA2LjAzMzg4NCANCkwgNDYxLjU1ODQyOSAtMjA2LjAzMzg4NCANCkwgNDYxLjcxODI2MyAtMjA2LjAzMzg4NCANCkwgNDYxLjg3ODA5NyAtMjA2LjAzMzg4NCANCkwgNDYyLjAzNzkzMSAtMjA2LjAzMzg4NCANCkwgNDYyLjE5Nzc2NSAtMjA2LjAzMzg4NCANCkwgNDYyLjM1NzU5OSAtMjA2LjAzMzg4NCANCkwgNDYyLjUxNzQzMyAtMjA2LjAzMzg4NCANCkwgNDYyLjY3NzI2NyAtMjA2LjAzMzg4NCANCkwgNDYyLjgzNzEwMSAtMjA2LjAzMzg4NCANCkwgNDYyLjk5NjkzNCAtMjA2LjAzMzg4NCANCkwgNDYzLjE1Njc2OCAtMjA2LjAzMzg4NCANCkwgNDYzLjMxNjYwMiAtMjA2LjAzMzg4NCANCkwgNDYzLjQ3NjQzNiAtMjA2LjAzMzg4NCANCkwgNDYzLjYzNjI3IC0yMDYuMDMzODg0IA0KTCA0NjMuNzk2MTA0IC0yMDYuMDMzODg0IA0KTCA0NjMuOTU1OTM4IC0yMDYuMDMzODg0IA0KTCA0NjQuMTE1NzcyIC0yMDYuMDMzODg0IA0KTCA0NjQuMjc1NjA1IC0yMDYuMDMzODg0IA0KTCA0NjQuNDM1NDM5IC0yMDYuMDMzODg0IA0KTCA0NjQuNTk1MjczIC0yMDYuMDMzODg0IA0KTCA0NjQuNzU1MTA3IC0yMDYuMDMzODg0IA0KTCA0NjQuOTE0OTQxIC0yMDYuMDMzODg0IA0KTCA0NjUuMDc0Nzc1IC0yMDYuMDMzODg0IA0KTCA0NjUuMjM0NjA5IC0yMDYuMDMzODg0IA0KTCA0NjUuMzk0NDQzIC0yMDYuMDMzODg0IA0KTCA0NjUuNTU0Mjc3IC0yMDYuMDMzODg0IA0KTCA0NjUuNzE0MTEgLTIwNi4wMzM4ODQgDQpMIDQ2NS44NzM5NDQgLTIwNi4wMzM4ODQgDQpMIDQ2Ni4wMzM3NzggLTIwNi4wMzM4ODQgDQpMIDQ2Ni4xOTM2MTIgLTIwNi4wMzM4ODQgDQpMIDQ2Ni4zNTM0NDYgLTIwNi4wMzM4ODQgDQpMIDQ2Ni41MTMyOCAtMjA2LjAzMzg4NCANCkwgNDY2LjY3MzExNCAtMjA2LjAzMzg4NCANCkwgNDY2LjgzMjk0OCAtMjA2LjAzMzg4NCANCkwgNDY2Ljk5Mjc4MiAtMjA2LjAzMzg4NCANCkwgNDY3LjE1MjYxNSAtMjA2LjAzMzg4NCANCkwgNDY3LjMxMjQ0OSAtMjA2LjAzMzg4NCANCkwgNDY3LjQ3MjI4MyAtMjA2LjAzMzg4NCANCkwgNDY3LjYzMjExNyAtMjA2LjAzMzg4NCANCkwgNDY3Ljc5MTk1MSAtMjA2LjAzMzg4NCANCkwgNDY3Ljk1MTc4NSAtMjA2LjAzMzg4NCANCkwgNDY4LjExMTYxOSAtMjA2LjAzMzg4NCANCkwgNDY4LjI3MTQ1MyAtMjA2LjAzMzg4NCANCkwgNDY4LjQzMTI4NiAtMjA2LjAzMzg4NCANCkwgNDY4LjU5MTEyIC0yMDYuMDMzODg0IA0KTCA0NjguNzUwOTU0IC0yMDYuMDMzODg0IA0KTCA0NjguOTEwNzg4IC0yMDYuMDMzODg0IA0KTCA0NjkuMDcwNjIyIC0yMDYuMDMzODg0IA0KTCA0NjkuMjMwNDU2IC0yMDYuMDMzODg0IA0KTCA0NjkuMzkwMjkgLTIwNi4wMzM4ODQgDQpMIDQ2OS41NTAxMjQgLTIwNi4wMzM4ODQgDQpMIDQ2OS43MDk5NTggLTIwNi4wMzM4ODQgDQpMIDQ2OS44Njk3OTEgLTIwNi4wMzM4ODQgDQpMIDQ3MC4wMjk2MjUgLTIwNi4wMzM4ODQgDQpMIDQ3MC4xODk0NTkgLTIwNi4wMzM4ODQgDQpMIDQ3MC4zNDkyOTMgLTIwNi4wMzM4ODQgDQpMIDQ3MC41MDkxMjcgLTIwNi4wMzM4ODQgDQpMIDQ3MC42Njg5NjEgLTIwNi4wMzM4ODQgDQpMIDQ3MC44Mjg3OTUgLTIwNi4wMzM4ODQgDQpMIDQ3MC45ODg2MjkgLTIwNi4wMzM4ODQgDQpMIDQ3MS4xNDg0NjIgLTIwNi4wMzM4ODQgDQpMIDQ3MS4zMDgyOTYgLTIwNi4wMzM4ODQgDQpMIDQ3MS40NjgxMyAtMjA2LjAzMzg4NCANCkwgNDcxLjYyNzk2NCAtMjA2LjAzMzg4NCANCkwgNDcxLjc4Nzc5OCAtMjA2LjAzMzg4NCANCkwgNDcxLjk0NzYzMiAtMjA2LjAzMzg4NCANCkwgNDcyLjEwNzQ2NiAtMjA2LjAzMzg4NCANCkwgNDcyLjI2NzMgLTIwNi4wMzM4ODQgDQpMIDQ3Mi40MjcxMzQgLTIwNi4wMzM4ODQgDQpMIDQ3Mi41ODY5NjcgLTIwNi4wMzM4ODQgDQpMIDQ3Mi43NDY4MDEgLTIwNi4wMzM4ODQgDQpMIDQ3Mi45MDY2MzUgLTIwNi4wMzM4ODQgDQpMIDQ3My4wNjY0NjkgLTIwNi4wMzM4ODQgDQpMIDQ3My4yMjYzMDMgLTIwNi4wMzM4ODQgDQpMIDQ3My4zODYxMzcgLTIwNi4wMzM4ODQgDQpMIDQ3My41NDU5NzEgLTIwNi4wMzM4ODQgDQpMIDQ3My43MDU4MDUgLTIwNi4wMzM4ODQgDQpMIDQ3My44NjU2MzkgLTIwNi4wMzM4ODQgDQpMIDQ3NC4wMjU0NzIgLTIwNi4wMzM4ODQgDQpMIDQ3NC4xODUzMDYgLTIwNi4wMzM4ODQgDQpMIDQ3NC4zNDUxNCAtMjA2LjAzMzg4NCANCkwgNDc0LjUwNDk3NCAtMjA2LjAzMzg4NCANCkwgNDc0LjY2NDgwOCAtMjA2LjAzMzg4NCANCkwgNDc0LjgyNDY0MiAtMjA2LjAzMzg4NCANCkwgNDc0Ljk4NDQ3NiAtMjA2LjAzMzg4NCANCkwgNDc1LjE0NDMxIC0yMDYuMDMzODg0IA0KTCA0NzUuMzA0MTQzIC0yMDYuMDMzODg0IA0KTCA0NzUuNDYzOTc3IC0yMDYuMDMzODg0IA0KTCA0NzUuNjIzODExIC0yMDYuMDMzODg0IA0KTCA0NzUuNzgzNjQ1IC0yMDYuMDMzODg0IA0KTCA0NzUuOTQzNDc5IC0yMDYuMDMzODg0IA0KTCA0NzYuMTAzMzEzIC0yMDYuMDMzODg0IA0KTCA0NzYuMjYzMTQ3IC0yMDYuMDMzODg0IA0KTCA0NzYuNDIyOTgxIC0yMDYuMDMzODg0IA0KTCA0NzYuNTgyODE1IC0yMDYuMDMzODg0IA0KTCA0NzYuNzQyNjQ4IC0yMDYuMDMzODg0IA0KTCA0NzYuOTAyNDgyIC0yMDYuMDMzODg0IA0KTCA0NzcuMDYyMzE2IC0yMDYuMDMzODg0IA0KTCA0NzcuMjIyMTUgLTIwNi4wMzM4ODQgDQpMIDQ3Ny4zODE5ODQgLTIwNi4wMzM4ODQgDQpMIDQ3Ny41NDE4MTggLTIwNi4wMzM4ODQgDQpMIDQ3Ny43MDE2NTIgLTIwNi4wMzM4ODQgDQpMIDQ3Ny44NjE0ODYgLTIwNi4wMzM4ODQgDQpMIDQ3OC4wMjEzMTkgLTIwNi4wMzM4ODQgDQpMIDQ3OC4xODExNTMgLTIwNi4wMzM4ODQgDQpMIDQ3OC4zNDA5ODcgLTIwNi4wMzM4ODQgDQpMIDQ3OC41MDA4MjEgLTIwNi4wMzM4ODQgDQpMIDQ3OC42NjA2NTUgLTIwNi4wMzM4ODQgDQpMIDQ3OC44MjA0ODkgLTIwNi4wMzM4ODQgDQpMIDQ3OC45ODAzMjMgLTIwNi4wMzM4ODQgDQpMIDQ3OS4xNDAxNTcgLTIwNi4wMzM4ODQgDQpMIDQ3OS4yOTk5OTEgLTIwNi4wMzM4ODQgDQpMIDQ3OS40NTk4MjQgLTIwNi4wMzM4ODQgDQpMIDQ3OS42MTk2NTggLTIwNi4wMzM4ODQgDQpMIDQ3OS43Nzk0OTIgLTIwNi4wMzM4ODQgDQpMIDQ3OS45MzkzMjYgLTIwNi4wMzM4ODQgDQpMIDQ4MC4wOTkxNiAtMjA2LjAzMzg4NCANCkwgNDgwLjI1ODk5NCAtMjA2LjAzMzg4NCANCkwgNDgwLjQxODgyOCAtMjA2LjAzMzg4NCANCkwgNDgwLjU3ODY2MiAtMjA2LjAzMzg4NCANCkwgNDgwLjczODQ5NiAtMjA2LjAzMzg4NCANCkwgNDgwLjg5ODMyOSAtMjA2LjAzMzg4NCANCkwgNDgxLjA1ODE2MyAtMjA2LjAzMzg4NCANCkwgNDgxLjIxNzk5NyAtMjA1LjU2OTQ2MyANCkwgNDgxLjM3NzgzMSAtMjA1LjQ5OTI2OCANCkwgNDgxLjUzNzY2NSAtMjA1LjQxMzc3NSANCkwgNDgxLjY5NzQ5OSAtMjA1LjMxMDk2MiANCkwgNDgxLjg1NzMzMyAtMjA1LjE5NDk1MSANCkwgNDgyLjAxNzE2NyAtMjA1LjA1MzM5OCANCkwgNDgyLjE3NyAtMjA0Ljg4NTQ1OSANCkwgNDgyLjMzNjgzNCAtMjA0LjY5NjU4IA0KTCA0ODIuNDk2NjY4IC0yMDQuNDY0MzIgDQpMIDQ4Mi42NTY1MDIgLTIwNC4xOTIwNDQgDQpMIDQ4Mi44MTYzMzYgLTIwMy44ODY5NDIgDQpMIDQ4Mi45NzYxNyAtMjAzLjUxMDE1OCANCkwgNDgzLjEzNjAwNCAtMjAzLjA3MjEwNiANCkwgNDgzLjI5NTgzOCAtMjAyLjU4MjI0NiANCkwgNDgzLjQ1NTY3MiAtMjAxLjk3NDQ1NiANCkwgNDgzLjYxNTUwNSAtMjAxLjI3NDg2MiANCkwgNDgzLjc3NTMzOSAtMjAwLjQ5NDgwNSANCkwgNDgzLjkzNTE3MyAtMTk5LjUyNDEyMyANCkwgNDg0LjA5NTAwNyAtMTk4LjQxOTA1OCANCkwgNDg0LjI1NDg0MSAtMTk3LjE5MTY1IA0KTCA0ODQuNDE0Njc1IC0xOTUuNjY1MzcgDQpMIDQ4NC41NzQ1MDkgLTE5My45NTEwMzYgDQpMIDQ4NC43MzQzNDMgLTE5Mi4wNTQ0MjQgDQpMIDQ4NC44OTQxNzYgLTE4OS43MjIzNzcgDQpMIDQ4NS4wNTQwMSAtMTg3LjE0NDg4NyANCkwgNDg1LjIxMzg0NCAtMTg0LjMwMjM5NiANCkwgNDg1LjM3MzY3OCAtMTgwLjkxMzY4MSANCkwgNDg1LjUzMzUxMiAtMTc3LjIzMjE4NiANCkwgNDg1LjY5MzM0NiAtMTczLjIxNTE0MSANCkwgNDg1Ljg1MzE4IC0xNjguNjI5MDMzIA0KTCA0ODYuMDEzMDE0IC0xNjMuNzY1MDczIA0KTCA0ODYuMTcyODQ4IC0xNTguNTcwNTMzIA0KTCA0ODYuMzMyNjgxIC0xNTIuOTUzMTkyIA0KTCA0ODYuNDkyNTE1IC0xNDcuMTY1MzI2IA0KTCA0ODYuNjUyMzQ5IC0xNDEuMTc5OTQxIA0KTCA0ODYuODEyMTgzIC0xMzUuMDcwNzAyIA0KTCA0ODYuOTcyMDE3IC0xMjguOTU3MjExIA0KTCA0ODcuMTMxODUxIC0xMjIuODY5MDA2IA0KTCA0ODcuMjkxNjg1IC0xMTYuOTQ4NDE3IA0KTCA0ODcuNDUxNTE5IC0xMTEuMTYzMyANCkwgNDg3LjYxMTM1MyAtMTA1LjU5Mjg1MyANCkwgNDg3Ljc3MTE4NiAtMTAwLjM0NTQyNSANCkwgNDg3LjkzMTAyIC05NS4zMDI5OTggDQpMIDQ4OC4wOTA4NTQgLTkwLjU2OTQ3NiANCkwgNDg4LjI1MDY4OCAtODYuMTkxMjYgDQpMIDQ4OC40MTA1MjIgLTgyLjAzMzcwOCANCkwgNDg4LjU3MDM1NiAtNzguMjEwNDI3IA0KTCA0ODguNzMwMTkgLTc0LjcyMTE3OCANCkwgNDg4Ljg5MDAyNCAtNzEuNDQzMjEgDQpMIDQ4OS4wNDk4NTcgLTY4LjQ5MTA3NCANCkwgNDg5LjIwOTY5MSAtNjUuODI2NjE5IA0KTCA0ODkuMzY5NTI1IC02My4zNDkzNDMgDQpMIDQ4OS41MjkzNTkgLTYxLjE2NDQ5NSANCkwgNDg5LjY4OTE5MyAtNTkuMjA4NDI5IA0KTCA0ODkuODQ5MDI3IC01Ny40MDY5MzUgDQpMIDQ5MC4wMDg4NjEgLTU1Ljg0OTM3OCANCkwgNDkwLjE2ODY5NSAtNTQuNDYyMjk3IA0KTCA0OTAuMzI4NTI5IC01My4xOTU0NzIgDQpMIDQ5MC40ODgzNjIgLTUyLjExOTgwNyANCkwgNDkwLjY0ODE5NiAtNTEuMTY0NjIyIA0KTCA0OTAuODA4MDMgLTUwLjI5OTE5OCANCkwgNDkwLjk2Nzg2NCAtNDkuNTc5MjY5IA0KTCA0OTEuMTI3Njk4IC00OC45NDI1OTYgDQpMIDQ5MS4yODc1MzIgLTQ4LjM3MTY5NCANCkwgNDkxLjQ0NzM2NiAtNDcuOTA5OTQxIA0KTCA0OTEuNjA3MiAtNDcuNTA2MzY3IA0KTCA0OTEuNzY3MDM0IC00Ny4xNTE2ODUgDQpMIDQ5MS45MjY4NjcgLTQ2Ljg4MTA3NCANCkwgNDkyLjA4NjcwMSAtNDYuNjUyODAzIA0KTCA0OTIuMjQ2NTM1IC00Ni40NjI0NTkgDQpMIDQ5Mi40MDYzNjkgLTQ2LjM0MTQxOSANCkwgNDkyLjU2NjIwMyAtNDYuMjU0Mjk1IA0KTCA0OTIuNzI2MDM3IC00Ni4yIA0KTCA0OTIuODg1ODcxIC00Ni4yMTAxOTcgDQpMIDQ5My4wNDU3MDUgLTQ2LjI1MTk2MSANCkwgNDkzLjIwNTUzOCAtNDYuMzI3NzY5IA0KTCA0OTMuMzY1MzcyIC00Ni40Njk0NiANCkwgNDkzLjUyNTIwNiAtNDYuNjQ3MDQ5IA0KTCA0OTMuNjg1MDQgLTQ2Ljg2NTg0MiANCkwgNDkzLjg0NDg3NCAtNDcuMTYyODczIA0KTCA0OTQuMDA0NzA4IC00Ny41MDU3NTkgDQpMIDQ5NC4xNjQ1NDIgLTQ3LjkwNDg1OCANCkwgNDk0LjMyNDM3NiAtNDguNDA1MzM5IA0KTCA0OTQuNDg0MjEgLTQ4Ljk2ODY0OSANCkwgNDk0LjY0NDA0MyAtNDkuNjE0MTEzIA0KTCA0OTQuODAzODc3IC01MC4zOTkxNTcgDQpMIDQ5NC45NjM3MTEgLTUxLjI3MzQ4MyANCkwgNDk1LjEyMzU0NSAtNTIuMjcxOTUgDQpMIDQ5NS4yODMzNzkgLTUzLjQ2NjI0NCANCkwgNDk1LjQ0MzIxMyAtNTQuNzg5MjMyIA0KTCA0OTUuNjAzMDQ3IC01Ni4zMDE5MjQgDQpMIDQ5NS43NjI4ODEgLTU4LjA4ODk1NCANCkwgNDk1LjkyMjcxNCAtNjAuMDU5Mzg4IA0KTCA0OTYuMDgyNTQ4IC02Mi4zMTQyMjYgDQpMIDQ5Ni4yNDIzODIgLTY0Ljk0MiANCkwgNDk2LjQwMjIxNiAtNjcuODIxNTU2IA0KTCA0OTYuNTYyMDUgLTcxLjEwNzg1MSANCkwgNDk2LjcyMTg4NCAtNzQuODYyODA0IA0KTCA0OTYuODgxNzE4IC03OC45MzMwMjUgDQpMIDQ5Ny4wNDE1NTIgLTgzLjUyMTQ5OSANCkwgNDk3LjIwMTM4NiAtODguNjA5OTI2IA0KTCA0OTcuMzYxMjE5IC05NC4wMjY5ODMgDQpMIDQ5Ny41MjEwNTMgLTk5Ljk2NTE1NCANCkwgNDk3LjY4MDg4NyAtMTA2LjI4MDQxNiANCkwgNDk3Ljg0MDcyMSAtMTEyLjgyODY2NCANCkwgNDk4LjAwMDU1NSAtMTE5LjY3NjIyOSANCkwgNDk4LjE2MDM4OSAtMTI2LjYwNTc3MSANCkwgNDk4LjMyMDIyMyAtMTMzLjU1ODAwOSANCkwgNDk4LjQ4MDA1NyAtMTQwLjM5MzYzNCANCkwgNDk4LjYzOTg5MSAtMTQ2Ljk5MjMwOSANCkwgNDk4Ljc5OTcyNCAtMTUzLjM4NjgzMSANCkwgNDk4Ljk1OTU1OCAtMTU5LjI4MDkzNiANCkwgNDk5LjExOTM5MiAtMTY0Ljc2OTA4NiANCkwgNDk5LjI3OTIyNiAtMTY5LjkyNTEyMiANCkwgNDk5LjQzOTA2IC0xNzQuNDIxNzI1IA0KTCA0OTkuNTk4ODk0IC0xNzguNTE4NjM4IA0KTCA0OTkuNzU4NzI4IC0xODIuMjc3Mzc5IA0KTCA0OTkuOTE4NTYyIC0xODUuNDIxMjMyIA0KTCA1MDAuMDc4Mzk1IC0xODguMjU2NjQzIA0KTCA1MDAuMjM4MjI5IC0xOTAuODE2MTM5IA0KTCA1MDAuMzk4MDYzIC0xOTIuODk2MzgzIA0KTCA1MDAuNTU3ODk3IC0xOTQuNzY4MjI1IA0KTCA1MDAuNzE3NzMxIC0xOTYuNDM4MDY2IA0KTCA1MDAuODc3NTY1IC0xOTcuNzcyNTMyIA0KTCA1MDEuMDM3Mzk5IC0xOTguOTczNzczIA0KTCA1MDEuMTk3MjMzIC0yMDAuMDMxOTU1IA0KTCA1MDEuMzU3MDY3IC0yMDAuODc3NzA3IA0KTCA1MDEuNTE2OSAtMjAxLjYzNjQ3NyANCkwgNTAxLjY3NjczNCAtMjAyLjI5Nzk4NCANCkwgNTAxLjgzNjU2OCAtMjAyLjgyOTAyOCANCkwgNTAxLjk5NjQwMiAtMjAzLjMwNDM4MyANCkwgNTAyLjE1NjIzNiAtMjAzLjcxNTE0OCANCkwgNTAyLjMxNjA3IC0yMDQuMDQ2MzgzIA0KTCA1MDIuNDc1OTA0IC0yMDQuMzQyMzQzIA0KTCA1MDIuNjM1NzM4IC0yMDQuNTk2MDc1IA0KTCA1MDIuNzk1NTcxIC0yMDQuODAyNTQ3IA0KTCA1MDIuOTU1NDA1IC0yMDQuOTg2Nzc1IA0KTCA1MDMuMTE1MjM5IC0yMDUuMTQzNDA2IA0KTCA1MDMuMjc1MDczIC0yMDUuMjcxNTExIA0KTCA1MDMuNDM0OTA3IC0yMDUuMzg1NjM1IA0KTCA1MDMuNTk0NzQxIC0yMDUuNDgxOTkgDQpMIDUwMy43NTQ1NzUgLTIwNS41NjE3MjYgDQpMIDUwMy45MTQ0MDkgLTIwNS42MzI2ODUgDQpMIDUwNC4wNzQyNDMgLTIwNS42OTE5NjUgDQpMIDUwNC4yMzQwNzYgLTIwNS43NDEyMzUgDQpMIDUwNC4zOTM5MSAtMjA1Ljc4NTAzNSANCkwgNTA0LjU1Mzc0NCAtMjA1LjgyMTQ4MiANCkwgNTA0LjcxMzU3OCAtMjA1Ljg1MjE4NiANCkwgNTA0Ljg3MzQxMiAtMjA1Ljg3OTQ4OCANCkwgNTA1LjAzMzI0NiAtMjA1LjkwMTk0NCANCkwgNTA1LjE5MzA4IC0yMDYuMDMzODg0IA0KTCA1MDUuMzUyOTE0IC0yMDYuMDMzODg0IA0KTCA1MDUuNTEyNzQ4IC0yMDYuMDMzODg0IA0KTCA1MDUuNjcyNTgxIC0yMDYuMDMzODg0IA0KTCA1MDUuODMyNDE1IC0yMDYuMDMzODg0IA0KTCA1MDUuOTkyMjQ5IC0yMDYuMDMzODg0IA0KTCA1MDYuMTUyMDgzIC0yMDYuMDMzODg0IA0KTCA1MDYuMzExOTE3IC0yMDYuMDMzODg0IA0KTCA1MDYuNDcxNzUxIC0yMDYuMDMzODg0IA0KTCA1MDYuNjMxNTg1IC0yMDYuMDMzODg0IA0KTCA1MDYuNzkxNDE5IC0yMDYuMDMzODg0IA0KTCA1MDYuOTUxMjUyIC0yMDYuMDMzODg0IA0KTCA1MDcuMTExMDg2IC0yMDYuMDMzODg0IA0KTCA1MDcuMjcwOTIgLTIwNi4wMzM4ODQgDQpMIDUwNy40MzA3NTQgLTIwNi4wMzM4ODQgDQpMIDUwNy41OTA1ODggLTIwNi4wMzM4ODQgDQpMIDUwNy43NTA0MjIgLTIwNi4wMzM4ODQgDQpMIDUwNy45MTAyNTYgLTIwNi4wMzM4ODQgDQpMIDUwOC4wNzAwOSAtMjA2LjAzMzg4NCANCkwgNTA4LjIyOTkyNCAtMjA2LjAzMzg4NCANCkwgNTA4LjM4OTc1NyAtMjA2LjAzMzg4NCANCkwgNTA4LjU0OTU5MSAtMjA2LjAzMzg4NCANCkwgNTA4LjcwOTQyNSAtMjA2LjAzMzg4NCANCkwgNTA4Ljg2OTI1OSAtMjA2LjAzMzg4NCANCkwgNTA5LjAyOTA5MyAtMjA2LjAzMzg4NCANCkwgNTA5LjE4ODkyNyAtMjA2LjAzMzg4NCANCkwgNTA5LjM0ODc2MSAtMjA2LjAzMzg4NCANCkwgNTA5LjUwODU5NSAtMjA2LjAzMzg4NCANCkwgNTA5LjY2ODQyOSAtMjA2LjAzMzg4NCANCkwgNTA5LjgyODI2MiAtMjA2LjAzMzg4NCANCkwgNTA5Ljk4ODA5NiAtMjA2LjAzMzg4NCANCkwgNTEwLjE0NzkzIC0yMDYuMDMzODg0IA0KTCA1MTAuMzA3NzY0IC0yMDYuMDMzODg0IA0KTCA1MTAuNDY3NTk4IC0yMDYuMDMzODg0IA0KTCA1MTAuNjI3NDMyIC0yMDYuMDMzODg0IA0KTCA1MTAuNzg3MjY2IC0yMDYuMDMzODg0IA0KTCA1MTAuOTQ3MSAtMjA2LjAzMzg4NCANCkwgNTExLjEwNjkzMyAtMjA2LjAzMzg4NCANCkwgNTExLjI2Njc2NyAtMjA2LjAzMzg4NCANCkwgNTExLjQyNjYwMSAtMjA2LjAzMzg4NCANCkwgNTExLjU4NjQzNSAtMjA2LjAzMzg4NCANCkwgNTExLjc0NjI2OSAtMjA2LjAzMzg4NCANCkwgNTExLjkwNjEwMyAtMjA2LjAzMzg4NCANCkwgNTEyLjA2NTkzNyAtMjA2LjAzMzg4NCANCkwgNTEyLjIyNTc3MSAtMjA2LjAzMzg4NCANCkwgNTEyLjM4NTYwNSAtMjA2LjAzMzg4NCANCkwgNTEyLjU0NTQzOCAtMjA2LjAzMzg4NCANCkwgNTEyLjcwNTI3MiAtMjA2LjAzMzg4NCANCkwgNTEyLjg2NTEwNiAtMjA2LjAzMzg4NCANCkwgNTEzLjAyNDk0IC0yMDYuMDMzODg0IA0KTCA1MTMuMTg0Nzc0IC0yMDYuMDMzODg0IA0KTCA1MTMuMzQ0NjA4IC0yMDYuMDMzODg0IA0KTCA1MTMuNTA0NDQyIC0yMDYuMDMzODg0IA0KTCA1MTMuNjY0Mjc2IC0yMDYuMDMzODg0IA0KTCA1MTMuODI0MTA5IC0yMDYuMDMzODg0IA0KTCA1MTMuOTgzOTQzIC0yMDYuMDMzODg0IA0KTCA1MTQuMTQzNzc3IC0yMDYuMDMzODg0IA0KTCA1MTQuMzAzNjExIC0yMDYuMDMzODg0IA0KTCA1MTQuNDYzNDQ1IC0yMDYuMDMzODg0IA0KTCA1MTQuNjIzMjc5IC0yMDYuMDMzODg0IA0KTCA1MTQuNzgzMTEzIC0yMDYuMDMzODg0IA0KTCA1MTQuOTQyOTQ3IC0yMDYuMDMzODg0IA0KTCA1MTUuMTAyNzgxIC0yMDYuMDMzODg0IA0KTCA1MTUuMjYyNjE0IC0yMDYuMDMzODg0IA0KTCA1MTUuNDIyNDQ4IC0yMDYuMDMzODg0IA0KTCA1MTUuNTgyMjgyIC0yMDYuMDMzODg0IA0KTCA1MTUuNzQyMTE2IC0yMDYuMDMzODg0IA0KTCA1MTUuOTAxOTUgLTIwNi4wMzM4ODQgDQpMIDUxNi4wNjE3ODQgLTIwNi4wMzM4ODQgDQpMIDUxNi4yMjE2MTggLTIwNi4wMzM4ODQgDQpMIDUxNi4zODE0NTIgLTIwNi4wMzM4ODQgDQpMIDUxNi41NDEyODYgLTIwNi4wMzM4ODQgDQpMIDUxNi43MDExMTkgLTIwNi4wMzM4ODQgDQpMIDUxNi44NjA5NTMgLTIwNi4wMzM4ODQgDQpMIDUxNy4wMjA3ODcgLTIwNi4wMzM4ODQgDQpMIDUxNy4xODA2MjEgLTIwNi4wMzM4ODQgDQpMIDUxNy4zNDA0NTUgLTIwNi4wMzM4ODQgDQpMIDUxNy41MDAyODkgLTIwNi4wMzM4ODQgDQpMIDUxNy42NjAxMjMgLTIwNi4wMzM4ODQgDQpMIDUxNy44MTk5NTcgLTIwNi4wMzM4ODQgDQpMIDUxNy45Nzk3OSAtMjA2LjAzMzg4NCANCkwgNTE4LjEzOTYyNCAtMjA2LjAzMzg4NCANCkwgNTE4LjI5OTQ1OCAtMjA2LjAzMzg4NCANCkwgNTE4LjQ1OTI5MiAtMjA2LjAzMzg4NCANCkwgNTE4LjYxOTEyNiAtMjA2LjAzMzg4NCANCkwgNTE4Ljc3ODk2IC0yMDYuMDMzODg0IA0KTCA1MTguOTM4Nzk0IC0yMDYuMDMzODg0IA0KTCA1MTkuMDk4NjI4IC0yMDYuMDMzODg0IA0KTCA1MTkuMjU4NDYyIC0yMDYuMDMzODg0IA0KTCA1MTkuNDE4Mjk1IC0yMDYuMDMzODg0IA0KTCA1MTkuNTc4MTI5IC0yMDYuMDMzODg0IA0KTCA1MTkuNzM3OTYzIC0yMDYuMDMzODg0IA0KTCA1MTkuODk3Nzk3IC0yMDYuMDMzODg0IA0KTCA1MjAuMDU3NjMxIC0yMDYuMDMzODg0IA0KTCA1MjAuMjE3NDY1IC0yMDYuMDMzODg0IA0KTCA1MjAuMzc3Mjk5IC0yMDYuMDMzODg0IA0KTCA1MjAuNTM3MTMzIC0yMDYuMDMzODg0IA0KTCA1MjAuNjk2OTY2IC0yMDYuMDMzODg0IA0KTCA1MjAuODU2OCAtMjA2LjAzMzg4NCANCkwgNTIxLjAxNjYzNCAtMjA2LjAzMzg4NCANCkwgNTIxLjE3NjQ2OCAtMjA2LjAzMzg4NCANCkwgNTIxLjMzNjMwMiAtMjA2LjAzMzg4NCANCkwgNTIxLjQ5NjEzNiAtMjA2LjAzMzg4NCANCkwgNTIxLjY1NTk3IC0yMDYuMDMzODg0IA0KTCA1MjEuODE1ODA0IC0yMDYuMDMzODg0IA0KTCA1MjEuOTc1NjM4IC0yMDYuMDMzODg0IA0KTCA1MjIuMTM1NDcxIC0yMDYuMDMzODg0IA0KTCA1MjIuMjk1MzA1IC0yMDYuMDMzODg0IA0KTCA1MjIuNDU1MTM5IC0yMDYuMDMzODg0IA0KTCA1MjIuNjE0OTczIC0yMDYuMDMzODg0IA0KTCA1MjIuNzc0ODA3IC0yMDYuMDMzODg0IA0KTCA1MjIuOTM0NjQxIC0yMDYuMDMzODg0IA0KTCA1MjMuMDk0NDc1IC0yMDYuMDMzODg0IA0KTCA1MjMuMjU0MzA5IC0yMDYuMDMzODg0IA0KTCA1MjMuNDE0MTQzIC0yMDYuMDMzODg0IA0KTCA1MjMuNTczOTc2IC0yMDYuMDMzODg0IA0KTCA1MjMuNzMzODEgLTIwNi4wMzM4ODQgDQpMIDUyMy44OTM2NDQgLTIwNi4wMzM4ODQgDQpMIDUyNC4wNTM0NzggLTIwNi4wMzM4ODQgDQpMIDUyNC4yMTMzMTIgLTIwNi4wMzM4ODQgDQpMIDUyNC4zNzMxNDYgLTIwNi4wMzM4ODQgDQpMIDUyNC41MzI5OCAtMjA2LjAzMzg4NCANCkwgNTI0LjY5MjgxNCAtMjA2LjAzMzg4NCANCkwgNTI0Ljg1MjY0NyAtMjA2LjAzMzg4NCANCkwgNTI1LjAxMjQ4MSAtMjA2LjAzMzg4NCANCkwgNTI1LjE3MjMxNSAtMjA2LjAzMzg4NCANCkwgNTI1LjMzMjE0OSAtMjA1LjU5NTk2NiANCkwgNTI1LjQ5MTk4MyAtMjA1LjUyOTcxIA0KTCA1MjUuNjUxODE3IC0yMDUuNDQ3OTcyIA0KTCA1MjUuODExNjUxIC0yMDUuMzU1MjA2IA0KTCA1MjUuOTcxNDg1IC0yMDUuMjQ0NTk3IA0KTCA1MjYuMTMxMzE5IC0yMDUuMTEwMDE5IA0KTCA1MjYuMjkxMTUyIC0yMDQuOTU4MDg2IA0KTCA1MjYuNDUwOTg2IC0yMDQuNzc2NTE3IA0KTCA1MjYuNjEwODIgLTIwNC41NTcyMjQgDQpMIDUyNi43NzA2NTQgLTIwNC4zMTAzOTYgDQpMIDUyNi45MzA0ODggLTIwNC4wMTQ1MTcgDQpMIDUyNy4wOTAzMjIgLTIwMy42NjA4NzIgDQpMIDUyNy4yNTAxNTYgLTIwMy4yNjM3NDYgDQpMIDUyNy40MDk5OSAtMjAyLjc4NDY0NSANCkwgNTI3LjU2OTgyNCAtMjAyLjIxNzU3MiANCkwgNTI3LjcyOTY1NyAtMjAxLjU4MjU4MyANCkwgNTI3Ljg4OTQ5MSAtMjAwLjgxMzI4IA0KTCA1MjguMDQ5MzI1IC0xOTkuOTEyMzk2IA0KTCA1MjguMjA5MTU5IC0xOTguOTA3MjA2IA0KTCA1MjguMzY4OTkzIC0xOTcuNjg2ODM0IA0KTCA1MjguNTI4ODI3IC0xOTYuMjc1ODgyIA0KTCA1MjguNjg4NjYxIC0xOTQuNzA5NjggDQpMIDUyOC44NDg0OTUgLTE5Mi44MTMwNjkgDQpMIDUyOS4wMDgzMjggLTE5MC42NTY0NiANCkwgNTI5LjE2ODE2MiAtMTg4LjI4MTg5NiANCkwgNTI5LjMyNzk5NiAtMTg1LjQzOTM4OSANCkwgNTI5LjQ4NzgzIC0xODIuMjc3Njk5IA0KTCA1MjkuNjQ3NjY0IC0xNzguODM5MDA0IA0KTCA1MjkuODA3NDk4IC0xNzQuODIxOTU5IA0KTCA1MjkuOTY3MzMyIC0xNzAuNDgwMDI1IA0KTCA1MzAuMTI3MTY2IC0xNjUuODQyODgyIA0KTCA1MzAuMjg3IC0xNjAuNjQ4MzQzIA0KTCA1MzAuNDQ2ODMzIC0xNTUuMjE4NTMyIA0KTCA1MzAuNjA2NjY3IC0xNDkuNTU1MTQzIA0KTCA1MzAuNzY2NTAxIC0xNDMuNTc0MTA1IA0KTCA1MzAuOTI2MzM1IC0xMzcuNTIxNzAyIA0KTCA1MzEuMDg2MTY5IC0xMzEuMzk0MTk0IA0KTCA1MzEuMjQ2MDAzIC0xMjUuMzA0Mjc5IA0KTCA1MzEuNDA1ODM3IC0xMTkuMzAzOTk3IA0KTCA1MzEuNTY1NjcxIC0xMTMuNDE1MDM4IA0KTCA1MzEuNzI1NTA0IC0xMDcuODIxMDMyIA0KTCA1MzEuODg1MzM4IC0xMDIuNDE0MyANCkwgNTMyLjA0NTE3MiAtOTcuMjQyMTIxIA0KTCA1MzIuMjA1MDA2IC05Mi40NjI4ODggDQpMIDUzMi4zNjQ4NCAtODcuOTAyNjA4IA0KTCA1MzIuNTI0Njc0IC04My42MjQyNTUgDQpMIDUzMi42ODQ1MDggLTc5LjczOTc0MiANCkwgNTMyLjg0NDM0MiAtNzYuMDcyNDQxIA0KTCA1MzMuMDA0MTc2IC03Mi42OTQyNzUgDQpMIDUzMy4xNjQwMDkgLTY5LjY3MTk0MSANCkwgNTMzLjMyMzg0MyAtNjYuODQ3NjU1IA0KTCA1MzMuNDgzNjc3IC02NC4yOTUwNjYgDQpMIDUzMy42NDM1MTEgLTYyLjAzODQyMSANCkwgNTMzLjgwMzM0NSAtNTkuOTQ5NjYyIA0KTCA1MzMuOTYzMTc5IC01OC4wOTY1NjEgDQpMIDUzNC4xMjMwMTMgLTU2LjQ3MjQwMyANCkwgNTM0LjI4Mjg0NyAtNTQuOTgxODkzIA0KTCA1MzQuNDQyNjgxIC01My42ODI4NzkgDQpMIDUzNC42MDI1MTQgLTUyLjU1MDA3NCANCkwgNTM0Ljc2MjM0OCAtNTEuNTE4MjY0IA0KTCA1MzQuOTIyMTgyIC01MC42MzQxMjUgDQpMIDUzNS4wODIwMTYgLTQ5Ljg2NzIzOCANCkwgNTM1LjI0MTg1IC00OS4xNzQ5NTkgDQpMIDUzNS40MDE2ODQgLTQ4LjU5NDA2OCANCkwgNTM1LjU2MTUxOCAtNDguMDk0NjQzIA0KTCA1MzUuNzIxMzUyIC00Ny42NTAxMzUgDQpMIDUzNS44ODExODUgLTQ3LjI5MDcyMiANCkwgNTM2LjA0MTAxOSAtNDYuOTg5MzI4IA0KTCA1MzYuMjAwODUzIC00Ni43Mjk1ODYgDQpMIDUzNi4zNjA2ODcgLTQ2LjUzNzYyOCANCkwgNTM2LjUyMDUyMSAtNDYuMzg5ODQ4IA0KTCA1MzYuNjgwMzU1IC00Ni4yNzYgDQpMIDUzNi44NDAxODkgLTQ2LjIyMTc1MyANCkwgNTM3LjAwMDAyMyAtNDYuMjA1OTQ2IA0KTCA1MzcuMTU5ODU3IC00Ni4yMjE2MjUgDQpMIDUzNy4zMTk2OSAtNDYuMjk3NDMzIA0KTCA1MzcuNDc5NTI0IC00Ni40MTE3NDUgDQpMIDUzNy42MzkzNTggLTQ2LjU1OTU0MSANCkwgNTM3Ljc5OTE5MiAtNDYuNzc4MzM0IA0KTCA1MzcuOTU5MDI2IC00Ny4wNDE3ODQgDQpMIDUzOC4xMTg4NiAtNDcuMzQ2MTM2IA0KTCA1MzguMjc4Njk0IC00Ny43NDUyMzUgDQpMIDUzOC40Mzg1MjggLTQ4LjIwMDcyMyANCkwgNTM4LjU5ODM2MSAtNDguNzEyMjQ3IA0KTCA1MzguNzU4MTk1IC00OS4zNTU5MjEgDQpMIDUzOC45MTgwMjkgLTUwLjA3NjkyIA0KTCA1MzkuMDc3ODYzIC01MC44ODI1MDIgDQpMIDUzOS4yMzc2OTcgLTUxLjg3MjU2NCANCkwgNTM5LjM5NzUzMSAtNTIuOTczNzIyIA0KTCA1MzkuNTU3MzY1IC01NC4yMDQ5ODUgDQpMIDUzOS43MTcxOTkgLTU1LjY5Njg1MSANCkwgNTM5Ljg3NzAzMyAtNTcuMzQ4NTY1IA0KTCA1NDAuMDM2ODY2IC01OS4xOTk1MjggDQpMIDU0MC4xOTY3IC02MS40MTIyOTcgDQpMIDU0MC4zNTY1MzQgLTYzLjg0ODk3NiANCkwgNTQwLjUxNjM2OCAtNjYuNTgxNTY3IA0KTCA1NDAuNjc2MjAyIC02OS43OTMzMTcgDQpMIDU0MC44MzYwMzYgLTczLjI5ODQ3IA0KTCA1NDAuOTk1ODcgLTc3LjIwOTMwNiANCkwgNTQxLjE1NTcwNCAtODEuNjg2MTA2IA0KTCA1NDEuMzE1NTM4IC04Ni40OTY3OTQgDQpMIDU0MS40NzUzNzEgLTkxLjc3OTYyNCANCkwgNTQxLjYzNTIwNSAtOTcuNTg5ODgzIA0KTCA1NDEuNzk1MDM5IC0xMDMuNjg2NDE1IA0KTCA1NDEuOTU0ODczIC0xMTAuMTcxMzcgDQpMIDU0Mi4xMTQ3MDcgLTExNi45MzcxOTYgDQpMIDU0Mi4yNzQ1NDEgLTEyMy44MTcwMTUgDQpMIDU0Mi40MzQzNzUgLTEzMC43ODg4OTYgDQpMIDU0Mi41OTQyMDkgLTEzNy42NTkzODEgDQpMIDU0Mi43NTQwNDIgLTE0NC40MDg3MjkgDQpMIDU0Mi45MTM4NzYgLTE1MC44Njc2NjMgDQpMIDU0My4wNzM3MSAtMTU2LjkyMzI5NCANCkwgNTQzLjIzMzU0NCAtMTYyLjY4MjYxNCANCkwgNTQzLjM5MzM3OCAtMTY3Ljg5ODgxIA0KTCA1NDMuNTUzMjEyIC0xNzIuNjIzMDc4IA0KTCA1NDMuNzEzMDQ2IC0xNzcuMDAxMjc4IA0KTCA1NDMuODcyODggLTE4MC43OTQ3MDIgDQpMIDU0NC4wMzI3MTQgLTE4NC4xNjM2OTQgDQpMIDU0NC4xOTI1NDcgLTE4Ny4yMjgzMzUgDQpMIDU0NC4zNTIzODEgLTE4OS43OTkxMTMgDQpMIDU0NC41MTIyMTUgLTE5Mi4wNjQyODUgDQpMIDU0NC42NzIwNDkgLTE5NC4xMDAyODggDQpMIDU0NC44MzE4ODMgLTE5NS43NzAxMjkgDQpMIDU0NC45OTE3MTcgLTE5Ny4yMzk3MTggDQpMIDU0NS4xNTE1NTEgLTE5OC41NTA1MDEgDQpMIDU0NS4zMTEzODUgLTE5OS42MDg2ODIgDQpMIDU0NS40NzEyMTggLTIwMC41NDI3MjUgDQpMIDU0NS42MzEwNTIgLTIwMS4zNzE4NzQgDQpMIDU0NS43OTA4ODYgLTIwMi4wMzMzODEgDQpMIDU0NS45NTA3MiAtMjAyLjYyMDQwNiANCkwgNTQ2LjExMDU1NCAtMjAzLjE0MDA3NyANCkwgNTQ2LjI3MDM4OCAtMjAzLjU1MDg0MiANCkwgNTQ2LjQzMDIyMiAtMjAzLjkxNzM1MyANCkwgNTQ2LjU5MDA1NiAtMjA0LjIzOTkyOCANCkwgNTQ2Ljc0OTg5IC0yMDQuNDk0NTgyIA0KTCA1NDYuOTA5NzIzIC0yMDQuNzIyNzQzIA0KTCA1NDcuMDY5NTU3IC0yMDQuOTIyMjUzIA0KTCA1NDcuMjI5MzkxIC0yMDUuMDgwNzU0IA0KTCA1NDcuMzg5MjI1IC0yMDUuMjIyNDIzIA0KTCA1NDcuNTQ5MDU5IC0yMDUuMzQ1MTQyIA0KTCA1NDcuNzA4ODkzIC0yMDUuNDQzNDQ4IA0KTCA1NDcuODY4NzI3IC0yMDUuNTMxMzgxIA0KTCA1NDguMDI4NTYxIC0yMDUuNjA3MjQ0IA0KTCA1NDguMTg4Mzk1IC0yMDUuNjY4MjUzIA0KTCA1NDguMzQ4MjI4IC0yMDUuNzIyNjUyIA0KTCA1NDguNTA4MDYyIC0yMDUuNzY5MTA4IA0KTCA1NDguNjY3ODk2IC0yMDUuODA2OTAzIA0KTCA1NDguODI3NzMgLTIwNS44NDA2NjkgDQpMIDU0OC45ODc1NjQgLTIwNS44Njk0NjIgDQpMIDU0OS4xNDczOTggLTIwNS44OTI5NjIgDQpMIDU0OS4zMDcyMzIgLTIwNi4wMzM4ODQgDQpMIDU0OS40NjcwNjYgLTIwNi4wMzM4ODQgDQpMIDU0OS42MjY4OTkgLTIwNi4wMzM4ODQgDQpMIDU0OS43ODY3MzMgLTIwNi4wMzM4ODQgDQpMIDU0OS45NDY1NjcgLTIwNi4wMzM4ODQgDQpMIDU1MC4xMDY0MDEgLTIwNi4wMzM4ODQgDQpMIDU1MC4yNjYyMzUgLTIwNi4wMzM4ODQgDQpMIDU1MC40MjYwNjkgLTIwNi4wMzM4ODQgDQpMIDU1MC41ODU5MDMgLTIwNi4wMzM4ODQgDQpMIDU1MC43NDU3MzcgLTIwNi4wMzM4ODQgDQpMIDU1MC45MDU1NzEgLTIwNi4wMzM4ODQgDQpMIDU1MS4wNjU0MDQgLTIwNi4wMzM4ODQgDQpMIDU1MS4yMjUyMzggLTIwNi4wMzM4ODQgDQpMIDU1MS4zODUwNzIgLTIwNi4wMzM4ODQgDQpMIDU1MS41NDQ5MDYgLTIwNi4wMzM4ODQgDQpMIDU1MS43MDQ3NCAtMjA2LjAzMzg4NCANCkwgNTUxLjg2NDU3NCAtMjA2LjAzMzg4NCANCkwgNTUyLjAyNDQwOCAtMjA2LjAzMzg4NCANCkwgNTUyLjE4NDI0MiAtMjA2LjAzMzg4NCANCkwgNTUyLjM0NDA3NiAtMjA2LjAzMzg4NCANCkwgNTUyLjUwMzkwOSAtMjA2LjAzMzg4NCANCkwgNTUyLjY2Mzc0MyAtMjA2LjAzMzg4NCANCkwgNTUyLjgyMzU3NyAtMjA2LjAzMzg4NCANCkwgNTUyLjk4MzQxMSAtMjA2LjAzMzg4NCANCkwgNTUzLjE0MzI0NSAtMjA2LjAzMzg4NCANCkwgNTUzLjMwMzA3OSAtMjA2LjAzMzg4NCANCkwgNTUzLjQ2MjkxMyAtMjA2LjAzMzg4NCANCkwgNTUzLjYyMjc0NyAtMjA2LjAzMzg4NCANCkwgNTUzLjc4MjU4IC0yMDYuMDMzODg0IA0KTCA1NTMuOTQyNDE0IC0yMDYuMDMzODg0IA0KTCA1NTQuMTAyMjQ4IC0yMDYuMDMzODg0IA0KTCA1NTQuMjYyMDgyIC0yMDYuMDMzODg0IA0KTCA1NTQuNDIxOTE2IC0yMDYuMDMzODg0IA0KTCA1NTQuNTgxNzUgLTIwNi4wMzM4ODQgDQpMIDU1NC43NDE1ODQgLTIwNi4wMzM4ODQgDQpMIDU1NC45MDE0MTggLTIwNi4wMzM4ODQgDQpMIDU1NS4wNjEyNTIgLTIwNi4wMzM4ODQgDQpMIDU1NS4yMjEwODUgLTIwNi4wMzM4ODQgDQpMIDU1NS4zODA5MTkgLTIwNi4wMzM4ODQgDQpMIDU1NS41NDA3NTMgLTIwNi4wMzM4ODQgDQpMIDU1NS43MDA1ODcgLTIwNi4wMzM4ODQgDQpMIDU1NS44NjA0MjEgLTIwNi4wMzM4ODQgDQpMIDU1Ni4wMjAyNTUgLTIwNi4wMzM4ODQgDQpMIDU1Ni4xODAwODkgLTIwNi4wMzM4ODQgDQpMIDU1Ni4zMzk5MjMgLTIwNi4wMzM4ODQgDQpMIDU1Ni40OTk3NTYgLTIwNi4wMzM4ODQgDQpMIDU1Ni42NTk1OSAtMjA2LjAzMzg4NCANCkwgNTU2LjgxOTQyNCAtMjA2LjAzMzg4NCANCkwgNTU2Ljk3OTI1OCAtMjA2LjAzMzg4NCANCkwgNTU3LjEzOTA5MiAtMjA2LjAzMzg4NCANCkwgNTU3LjI5ODkyNiAtMjA2LjAzMzg4NCANCkwgNTU3LjQ1ODc2IC0yMDYuMDMzODg0IA0KTCA1NTcuNjE4NTk0IC0yMDYuMDMzODg0IA0KTCA1NTcuNzc4NDI4IC0yMDYuMDMzODg0IA0KTCA1NTcuOTM4MjYxIC0yMDYuMDMzODg0IA0KTCA1NTguMDk4MDk1IC0yMDYuMDMzODg0IA0KTCA1NTguMjU3OTI5IC0yMDYuMDMzODg0IA0KTCA1NTguNDE3NzYzIC0yMDYuMDMzODg0IA0KTCA1NTguNTc3NTk3IC0yMDYuMDMzODg0IA0KTCA1NTguNzM3NDMxIC0yMDYuMDMzODg0IA0KTCA1NTguODk3MjY1IC0yMDYuMDMzODg0IA0KTCA1NTkuMDU3MDk5IC0yMDYuMDMzODg0IA0KTCA1NTkuMjE2OTMzIC0yMDYuMDMzODg0IA0KTCA1NTkuMzc2NzY2IC0yMDYuMDMzODg0IA0KTCA1NTkuNTM2NiAtMjA2LjAzMzg4NCANCkwgNTU5LjY5NjQzNCAtMjA2LjAzMzg4NCANCkwgNTU5Ljg1NjI2OCAtMjA2LjAzMzg4NCANCkwgNTYwLjAxNjEwMiAtMjA2LjAzMzg4NCANCkwgNTYwLjE3NTkzNiAtMjA2LjAzMzg4NCANCkwgNTYwLjMzNTc3IC0yMDYuMDMzODg0IA0KTCA1NjAuNDk1NjA0IC0yMDYuMDMzODg0IA0KTCA1NjAuNjU1NDM3IC0yMDYuMDMzODg0IA0KTCA1NjAuODE1MjcxIC0yMDYuMDMzODg0IA0KTCA1NjAuOTc1MTA1IC0yMDYuMDMzODg0IA0KTCA1NjEuMTM0OTM5IC0yMDYuMDMzODg0IA0KTCA1NjEuMjk0NzczIC0yMDYuMDMzODg0IA0KTCA1NjEuNDU0NjA3IC0yMDYuMDMzODg0IA0KTCA1NjEuNjE0NDQxIC0yMDYuMDMzODg0IA0KTCA1NjEuNzc0Mjc1IC0yMDYuMDMzODg0IA0KTCA1NjEuOTM0MTA5IC0yMDYuMDMzODg0IA0KTCA1NjIuMDkzOTQyIC0yMDYuMDMzODg0IA0KTCA1NjIuMjUzNzc2IC0yMDYuMDMzODg0IA0KTCA1NjIuNDEzNjEgLTIwNi4wMzM4ODQgDQpMIDU2Mi41NzM0NDQgLTIwNi4wMzM4ODQgDQpMIDU2Mi43MzMyNzggLTIwNi4wMzM4ODQgDQpMIDU2Mi44OTMxMTIgLTIwNi4wMzM4ODQgDQpMIDU2My4wNTI5NDYgLTIwNi4wMzM4ODQgDQpMIDU2My4yMTI3OCAtMjA2LjAzMzg4NCANCkwgNTYzLjM3MjYxMyAtMjA2LjAzMzg4NCANCkwgNTYzLjUzMjQ0NyAtMjA2LjAzMzg4NCANCkwgNTYzLjY5MjI4MSAtMjA2LjAzMzg4NCANCkwgNTYzLjg1MjExNSAtMjA2LjAzMzg4NCANCkwgNTY0LjAxMTk0OSAtMjA2LjAzMzg4NCANCkwgNTY0LjE3MTc4MyAtMjA2LjAzMzg4NCANCkwgNTY0LjMzMTYxNyAtMjA2LjAzMzg4NCANCkwgNTY0LjQ5MTQ1MSAtMjA2LjAzMzg4NCANCkwgNTY0LjY1MTI4NSAtMjA2LjAzMzg4NCANCkwgNTY0LjgxMTExOCAtMjA2LjAzMzg4NCANCkwgNTY0Ljk3MDk1MiAtMjA2LjAzMzg4NCANCkwgNTY1LjEzMDc4NiAtMjA2LjAzMzg4NCANCkwgNTY1LjI5MDYyIC0yMDYuMDMzODg0IA0KTCA1NjUuNDUwNDU0IC0yMDYuMDMzODg0IA0KTCA1NjUuNjEwMjg4IC0yMDYuMDMzODg0IA0KTCA1NjUuNzcwMTIyIC0yMDYuMDMzODg0IA0KTCA1NjUuOTI5OTU2IC0yMDYuMDMzODg0IA0KTCA1NjYuMDg5NzkgLTIwNi4wMzM4ODQgDQpMIDU2Ni4yNDk2MjMgLTIwNi4wMzM4ODQgDQpMIDU2Ni40MDk0NTcgLTIwNi4wMzM4ODQgDQpMIDU2Ni41NjkyOTEgLTIwNi4wMzM4ODQgDQpMIDU2Ni43MjkxMjUgLTIwNi4wMzM4ODQgDQpMIDU2Ni44ODg5NTkgLTIwNi4wMzM4ODQgDQpMIDU2Ny4wNDg3OTMgLTIwNi4wMzM4ODQgDQpMIDU2Ny4yMDg2MjcgLTIwNi4wMzM4ODQgDQpMIDU2Ny4zNjg0NjEgLTIwNi4wMzM4ODQgDQpMIDU2Ny41MjgyOTQgLTIwNi4wMzM4ODQgDQpMIDU2Ny42ODgxMjggLTIwNi4wMzM4ODQgDQpMIDU2Ny44NDc5NjIgLTIwNi4wMzM4ODQgDQpMIDU2OC4wMDc3OTYgLTIwNi4wMzM4ODQgDQpMIDU2OC4xNjc2MyAtMjA2LjAzMzg4NCANCkwgNTY4LjMyNzQ2NCAtMjA2LjAzMzg4NCANCkwgNTY4LjQ4NzI5OCAtMjA2LjAzMzg4NCANCkwgNTY4LjY0NzEzMiAtMjA2LjAzMzg4NCANCkwgNTY4LjgwNjk2NiAtMjA2LjAzMzg4NCANCkwgNTY4Ljk2Njc5OSAtMjA2LjAzMzg4NCANCkwgNTY5LjEyNjYzMyAtMjA2LjAzMzg4NCANCkwgNTY5LjI4NjQ2NyAtMjA2LjAzMzg4NCANCkwgNTY5LjQ0NjMwMSAtMjA2LjAzMzg4NCANCkwgNTY5LjYwNjEzNSAtMjA1LjU1NjIxMiANCkwgNTY5Ljc2NTk2OSAtMjA1LjQ4MjE3IA0KTCA1NjkuOTI1ODAzIC0yMDUuMzk2Njc2IA0KTCA1NzAuMDg1NjM3IC0yMDUuMjg4ODQgDQpMIDU3MC4yNDU0NzEgLTIwNS4xNjY2NCANCkwgNTcwLjQwNTMwNCAtMjA1LjAyNTA4OCANCkwgNTcwLjU2NTEzOCAtMjA0Ljg0OTE0NSANCkwgNTcwLjcyNDk3MiAtMjA0LjY1MDEyOCANCkwgNTcwLjg4NDgwNiAtMjA0LjQxNzg2OCANCkwgNTcxLjA0NDY0IC0yMDQuMTMyODY4IA0KTCA1NzEuMjA0NDc0IC0yMDMuODExNTg1IA0KTCA1NzEuMzY0MzA4IC0yMDMuNDM0ODAxIA0KTCA1NzEuNTI0MTQyIC0yMDIuOTc2Mjg1IA0KTCA1NzEuNjgzOTc1IC0yMDIuNDYwNjg3IA0KTCA1NzEuODQzODA5IC0yMDEuODUyODk4IA0KTCA1NzIuMDAzNjQzIC0yMDEuMTIxMDAyIA0KTCA1NzIuMTYzNDc3IC0yMDAuMzAwNjY5IA0KTCA1NzIuMzIzMzExIC0xOTkuMzI5OTg2IA0KTCA1NzIuNDgzMTQ1IC0xOTguMTc0OTgzIA0KTCA1NzIuNjQyOTc5IC0xOTYuODg2Mzk0IA0KTCA1NzIuODAyODEzIC0xOTUuMzYwMTE2IA0KTCA1NzIuOTYyNjQ3IC0xOTMuNTcxNzEyIA0KTCA1NzMuMTIyNDggLTE5MS41OTA1NDEgDQpMIDU3My4yODIzMTQgLTE4OS4yNTUzMzQgDQpMIDU3My40NDIxNDggLTE4Ni41NzYzOTggDQpMIDU3My42MDE5ODIgLTE4My42NDE3MzIgDQpMIDU3My43NjE4MTYgLTE4MC4yMzE2OCANCkwgNTczLjkyMTY1IC0xNzYuNDI4Nzc3IA0KTCA1NzQuMDgxNDg0IC0xNzIuMzMxMDM0IA0KTCA1NzQuMjQxMzE4IC0xNjcuNzAzNTI4IA0KTCA1NzQuNDAxMTUxIC0xNjIuNzI2MTUyIA0KTCA1NzQuNTYwOTg1IC0xNTcuNDgzODg3IA0KTCA1NzQuNzIwODE5IC0xNTEuODIwNTE0IA0KTCA1NzQuODgwNjUzIC0xNDUuOTY4MjM2IA0KTCA1NzUuMDQwNDg3IC0xMzkuOTcyNzAyIA0KTCA1NzUuMjAwMzIxIC0xMzMuODQ1MTk0IA0KTCA1NzUuMzYwMTU1IC0xMjcuNzM5NTY3IA0KTCA1NzUuNTE5OTg5IC0xMjEuNjU5NTc3IA0KTCA1NzUuNjc5ODIzIC0xMTUuNzcwNjM0IA0KTCA1NzUuODM5NjU2IC0xMTAuMDQ5MjEgDQpMIDU3NS45OTk0OSAtMTA0LjQ4MzE1OSANCkwgNTc2LjE1OTMyNCAtOTkuMzEwOTggDQpMIDU3Ni4zMTkxNTggLTk0LjM1NjI4NCANCkwgNTc2LjQ3ODk5MiAtODkuNjIyNzYzIA0KTCA1NzYuNjM4ODI2IC04NS4zMzU1ODcgDQpMIDU3Ni43OTg2NiAtODEuMjY5MDQyIA0KTCA1NzYuOTU4NDk0IC03Ny40NDU3NzcgDQpMIDU3Ny4xMTgzMjggLTc0LjA0NTUzOCANCkwgNTc3LjI3ODE2MSAtNzAuODUyNzkyIA0KTCA1NzcuNDM3OTk1IC02Ny45MDA2NTcgDQpMIDU3Ny41OTc4MjkgLTY1LjMxNjEwMiANCkwgNTc3Ljc1NzY2MyAtNjIuOTEyMzY0IA0KTCA1NzcuOTE3NDk3IC02MC43Mjc1MzIgDQpMIDU3OC4wNzczMzEgLTU4LjgzNzgxMyANCkwgNTc4LjIzNzE2NSAtNTcuMDk1NDI0IA0KTCA1NzguMzk2OTk5IC01NS41Mzc4NjcgDQpMIDU3OC41NTY4MzIgLTU0LjIwMjQ5IA0KTCA1NzguNzE2NjY2IC01Mi45ODAzMzkgDQpMIDU3OC44NzY1IC01MS45MDQ2NzQgDQpMIDU3OS4wMzYzMzQgLTUwLjk4Nzc4NCANCkwgNTc5LjE5NjE2OCAtNTAuMTU1MjA2IA0KTCA1NzkuMzU2MDAyIC00OS40MzUyNzcgDQpMIDU3OS41MTU4MzYgLTQ4LjgyNjQzMSANCkwgNTc5LjY3NTY3IC00OC4yNzkzNDQgDQpMIDU3OS44MzU1MDQgLTQ3LjgxNzU5IA0KTCA1NzkuOTk1MzM3IC00Ny40MzQ0NzQgDQpMIDU4MC4xNTUxNzEgLTQ3LjA5NzU4MiANCkwgNTgwLjMxNTAwNSAtNDYuODI2OTU1IA0KTCA1ODAuNDc0ODM5IC00Ni42MTQ0MTEgDQpMIDU4MC42MzQ2NzMgLTQ2LjQzODI2MSANCkwgNTgwLjc5NDUwNyAtNDYuMzE3MjIgDQpMIDU4MC45NTQzNDEgLTQ2LjI0MzQ0MiANCkwgNTgxLjExNDE3NSAtNDYuMjAxNzU4IA0KTCA1ODEuMjc0MDA4IC00Ni4yMTIzMjMgDQpMIDU4MS40MzM4NDIgLTQ2LjI2NzEyOSANCkwgNTgxLjU5MzY3NiAtNDYuMzU0MDQ2IA0KTCA1ODEuNzUzNTEgLTQ2LjQ5ODMwOSANCkwgNTgxLjkxMzM0NCAtNDYuNjkwODEgDQpMIDU4Mi4wNzMxNzggLTQ2LjkyMDY5NiANCkwgNTgyLjIzMzAxMiAtNDcuMjIzNDAxIA0KTCA1ODIuMzkyODQ2IC00Ny41ODU1OTUgDQpMIDU4Mi41NTI2OCAtNDcuOTk2MTIyIA0KTCA1ODIuNzEyNTEzIC00OC41MDc2NDcgDQpMIDU4Mi44NzIzNDcgLTQ5LjA5NzcyOSANCkwgNTgzLjAzMjE4MSAtNDkuNzU0NjY4IA0KTCA1ODMuMTkyMDE1IC01MC41NjAyNjcgDQpMIDU4My4zNTE4NDkgLTUxLjQ3MzE2IA0KTCA1ODMuNTExNjgzIC01Mi40ODEyMzQgDQpMIDU4My42NzE1MTcgLTUzLjcxMjQ5NSANCkwgNTgzLjgzMTM1MSAtNTUuMDkxNzc2IA0KTCA1ODMuOTkxMTg1IC01Ni42MDgxNzkgDQpMIDU4NC4xNTEwMTggLTU4LjQ1OTEzOSANCkwgNTg0LjMxMDg1MiAtNjAuNTEwMzUyIA0KTCA1ODQuNDcwNjg2IC02Mi43NjUxOTEgDQpMIDU4NC42MzA1MiAtNjUuNDg4NTI4IA0KTCA1ODQuNzkwMzU0IC02OC40Nzg4MTUgDQpMIDU4NC45NTAxODggLTcxLjc2NTExIA0KTCA1ODUuMTEwMDIyIC03NS42NDQ5NzIgDQpMIDU4NS4yNjk4NTYgLTc5Ljg1MDcxMyANCkwgNTg1LjQyOTY4OSAtODQuNDM5MjA0IA0KTCA1ODUuNTg5NTIzIC04OS42NjY0OTIgDQpMIDU4NS43NDkzNTcgLTk1LjIxNDYxMSANCkwgNTg1LjkwOTE5MSAtMTAxLjE1MjgxNCANCkwgNTg2LjA2OTAyNSAtMTA3LjU3NzQwMSANCkwgNTg2LjIyODg1OSAtMTE0LjE5ODE4IA0KTCA1ODYuMzg4NjkzIC0xMjEuMDQ1NzI5IA0KTCA1ODYuNTQ4NTI3IC0xMjguMDAwMTQgDQpMIDU4Ni43MDgzNjEgLTEzNC45MjUxMjcgDQpMIDU4Ni44NjgxOTQgLTE0MS43NjA3NTIgDQpMIDU4Ny4wMjgwMjggLTE0OC4yODQwOTkgDQpMIDU4Ny4xODc4NjIgLTE1NC41NjU2NTIgDQpMIDU4Ny4zNDc2OTYgLTE2MC40NTk3NDIgDQpMIDU4Ny41MDc1MyAtMTY1LjgxMjMzOCANCkwgNTg3LjY2NzM2NCAtMTcwLjgyNDQ0NiANCkwgNTg3LjgyNzE5OCAtMTc1LjMyMTA0OSANCkwgNTg3Ljk4NzAzMiAtMTc5LjI3NzMyNiANCkwgNTg4LjE0Njg2NiAtMTgyLjkwNjE1NiANCkwgNTg4LjMwNjY5OSAtMTg2LjA1MDAwOSANCkwgNTg4LjQ2NjUzMyAtMTg4Ljc3MDgwNSANCkwgNTg4LjYyNjM2NyAtMTkxLjIzMjE4NyANCkwgNTg4Ljc4NjIwMSAtMTkzLjMxMjQzMyANCkwgNTg4Ljk0NjAzNSAtMTk1LjEwMjE5MyANCkwgNTg5LjEwNTg2OSAtMTk2LjcwNjkwNSANCkwgNTg5LjI2NTcwMyAtMTk4LjAzODkzOSANCkwgNTg5LjQyNTUzNyAtMTk5LjE4NTQwOSANCkwgNTg5LjU4NTM3IC0yMDAuMjA3NzQ0IA0KTCA1ODkuNzQ1MjA0IC0yMDEuMDQ1MTk3IA0KTCA1ODkuOTA1MDM4IC0yMDEuNzY4Nzc4IA0KTCA1OTAuMDY0ODcyIC0yMDIuNDExNzg0IA0KTCA1OTAuMjI0NzA2IC0yMDIuOTMzMzM4IA0KTCA1OTAuMzg0NTQgLTIwMy4zODY1MzYgDQpMIDU5MC41NDQzNzQgLTIwMy43ODgzMjMgDQpMIDU5MC43MDQyMDggLTIwNC4xMTA4OTggDQpMIDU5MC44NjQwNDIgLTIwNC4zOTMwOSANCkwgNTkxLjAyMzg3NSAtMjA0LjY0MjkzOSANCkwgNTkxLjE4MzcwOSAtMjA0Ljg0MjQ0OSANCkwgNTkxLjM0MzU0MyAtMjA1LjAxODEwMSANCkwgNTkxLjUwMzM3NyAtMjA1LjE3MzMzNSANCkwgNTkxLjY2MzIxMSAtMjA1LjI5NjA1NCANCkwgNTkxLjgyMzA0NSAtMjA1LjQwNDkwNiANCkwgNTkxLjk4Mjg3OSAtMjA1LjUwMTAzNiANCkwgNTkyLjE0MjcxMyAtMjA1LjU3Njg5OSANCkwgNTkyLjMwMjU0NiAtMjA1LjY0NDU0MSANCkwgNTkyLjQ2MjM4IC0yMDUuNzAzODIxIA0KTCA1OTIuNjIyMjE0IC0yMDUuNzUwNTI2IA0KTCA1OTIuNzgyMDQ4IC0yMDUuNzkyMzI0IA0KTCA1OTIuOTQxODgyIC0yMDUuODI4NzcyIA0KTCA1OTMuMTAxNzE2IC0yMDUuODU3OTQ1IA0KTCA1OTMuMjYxNTUgLTIwNS44ODM5OCANCkwgNTkzLjQyMTM4NCAtMjA2LjAzMzg4NCANCkwgNTkzLjU4MTIxOCAtMjA2LjAzMzg4NCANCkwgNTkzLjc0MTA1MSAtMjA2LjAzMzg4NCANCkwgNTkzLjkwMDg4NSAtMjA2LjAzMzg4NCANCkwgNTk0LjA2MDcxOSAtMjA2LjAzMzg4NCANCkwgNTk0LjIyMDU1MyAtMjA2LjAzMzg4NCANCkwgNTk0LjM4MDM4NyAtMjA2LjAzMzg4NCANCkwgNTk0LjU0MDIyMSAtMjA2LjAzMzg4NCANCkwgNTk0LjcwMDA1NSAtMjA2LjAzMzg4NCANCkwgNTk0Ljg1OTg4OSAtMjA2LjAzMzg4NCANCkwgNTk1LjAxOTcyMyAtMjA2LjAzMzg4NCANCkwgNTk1LjE3OTU1NiAtMjA2LjAzMzg4NCANCkwgNTk1LjMzOTM5IC0yMDYuMDMzODg0IA0KTCA1OTUuNDk5MjI0IC0yMDYuMDMzODg0IA0KTCA1OTUuNjU5MDU4IC0yMDYuMDMzODg0IA0KTCA1OTUuODE4ODkyIC0yMDYuMDMzODg0IA0KTCA1OTUuOTc4NzI2IC0yMDYuMDMzODg0IA0KTCA1OTYuMTM4NTYgLTIwNi4wMzM4ODQgDQpMIDU5Ni4yOTgzOTQgLTIwNi4wMzM4ODQgDQpMIDU5Ni40NTgyMjcgLTIwNi4wMzM4ODQgDQpMIDU5Ni42MTgwNjEgLTIwNi4wMzM4ODQgDQpMIDU5Ni43Nzc4OTUgLTIwNi4wMzM4ODQgDQpMIDU5Ni45Mzc3MjkgLTIwNi4wMzM4ODQgDQpMIDU5Ny4wOTc1NjMgLTIwNi4wMzM4ODQgDQpMIDU5Ny4yNTczOTcgLTIwNi4wMzM4ODQgDQpMIDU5Ny40MTcyMzEgLTIwNi4wMzM4ODQgDQpMIDU5Ny41NzcwNjUgLTIwNi4wMzM4ODQgDQpMIDU5Ny43MzY4OTkgLTIwNi4wMzM4ODQgDQpMIDU5Ny44OTY3MzIgLTIwNi4wMzM4ODQgDQpMIDU5OC4wNTY1NjYgLTIwNi4wMzM4ODQgDQpMIDU5OC4yMTY0IC0yMDYuMDMzODg0IA0KTCA1OTguMzc2MjM0IC0yMDYuMDMzODg0IA0KTCA1OTguNTM2MDY4IC0yMDYuMDMzODg0IA0KTCA1OTguNjk1OTAyIC0yMDYuMDMzODg0IA0KTCA1OTguODU1NzM2IC0yMDYuMDMzODg0IA0KTCA1OTkuMDE1NTcgLTIwNi4wMzM4ODQgDQpMIDU5OS4xNzU0MDMgLTIwNi4wMzM4ODQgDQpMIDU5OS4zMzUyMzcgLTIwNi4wMzM4ODQgDQpMIDU5OS40OTUwNzEgLTIwNi4wMzM4ODQgDQpMIDU5OS42NTQ5MDUgLTIwNi4wMzM4ODQgDQpMIDU5OS44MTQ3MzkgLTIwNi4wMzM4ODQgDQpMIDU5OS45NzQ1NzMgLTIwNi4wMzM4ODQgDQpMIDYwMC4xMzQ0MDcgLTIwNi4wMzM4ODQgDQpMIDYwMC4yOTQyNDEgLTIwNi4wMzM4ODQgDQpMIDYwMC40NTQwNzUgLTIwNi4wMzM4ODQgDQpMIDYwMC42MTM5MDggLTIwNi4wMzM4ODQgDQpMIDYwMC43NzM3NDIgLTIwNi4wMzM4ODQgDQpMIDYwMC45MzM1NzYgLTIwNi4wMzM4ODQgDQpMIDYwMS4wOTM0MSAtMjA2LjAzMzg4NCANCkwgNjAxLjI1MzI0NCAtMjA2LjAzMzg4NCANCkwgNjAxLjQxMzA3OCAtMjA2LjAzMzg4NCANCkwgNjAxLjU3MjkxMiAtMjA2LjAzMzg4NCANCkwgNjAxLjczMjc0NiAtMjA2LjAzMzg4NCANCkwgNjAxLjg5MjU4IC0yMDYuMDMzODg0IA0KTCA2MDIuMDUyNDEzIC0yMDYuMDMzODg0IA0KTCA2MDIuMjEyMjQ3IC0yMDYuMDMzODg0IA0KTCA2MDIuMzcyMDgxIC0yMDYuMDMzODg0IA0KTCA2MDIuNTMxOTE1IC0yMDYuMDMzODg0IA0KTCA2MDIuNjkxNzQ5IC0yMDYuMDMzODg0IA0KTCA2MDIuODUxNTgzIC0yMDYuMDMzODg0IA0KTCA2MDMuMDExNDE3IC0yMDYuMDMzODg0IA0KTCA2MDMuMTcxMjUxIC0yMDYuMDMzODg0IA0KTCA2MDMuMzMxMDg0IC0yMDYuMDMzODg0IA0KTCA2MDMuNDkwOTE4IC0yMDYuMDMzODg0IA0KTCA2MDMuNjUwNzUyIC0yMDYuMDMzODg0IA0KTCA2MDMuODEwNTg2IC0yMDYuMDMzODg0IA0KTCA2MDMuOTcwNDIgLTIwNi4wMzM4ODQgDQpMIDYwNC4xMzAyNTQgLTIwNi4wMzM4ODQgDQpMIDYwNC4yOTAwODggLTIwNi4wMzM4ODQgDQpMIDYwNC40NDk5MjIgLTIwNi4wMzM4ODQgDQpMIDYwNC42MDk3NTYgLTIwNi4wMzM4ODQgDQpMIDYwNC43Njk1ODkgLTIwNi4wMzM4ODQgDQpMIDYwNC45Mjk0MjMgLTIwNi4wMzM4ODQgDQpMIDYwNS4wODkyNTcgLTIwNi4wMzM4ODQgDQpMIDYwNS4yNDkwOTEgLTIwNi4wMzM4ODQgDQpMIDYwNS40MDg5MjUgLTIwNi4wMzM4ODQgDQpMIDYwNS41Njg3NTkgLTIwNi4wMzM4ODQgDQpMIDYwNS43Mjg1OTMgLTIwNi4wMzM4ODQgDQpMIDYwNS44ODg0MjcgLTIwNi4wMzM4ODQgDQpMIDYwNi4wNDgyNjEgLTIwNi4wMzM4ODQgDQpMIDYwNi4yMDgwOTQgLTIwNi4wMzM4ODQgDQpMIDYwNi4zNjc5MjggLTIwNi4wMzM4ODQgDQpMIDYwNi41Mjc3NjIgLTIwNi4wMzM4ODQgDQpMIDYwNi42ODc1OTYgLTIwNi4wMzM4ODQgDQpMIDYwNi44NDc0MyAtMjA2LjAzMzg4NCANCkwgNjA3LjAwNzI2NCAtMjA2LjAzMzg4NCANCkwgNjA3LjE2NzA5OCAtMjA2LjAzMzg4NCANCkwgNjA3LjMyNjkzMiAtMjA2LjAzMzg4NCANCkwgNjA3LjQ4Njc2NSAtMjA2LjAzMzg4NCANCkwgNjA3LjY0NjU5OSAtMjA2LjAzMzg4NCANCkwgNjA3LjgwNjQzMyAtMjA2LjAzMzg4NCANCkwgNjA3Ljk2NjI2NyAtMjA2LjAzMzg4NCANCkwgNjA4LjEyNjEwMSAtMjA2LjAzMzg4NCANCkwgNjA4LjI4NTkzNSAtMjA2LjAzMzg4NCANCkwgNjA4LjQ0NTc2OSAtMjA2LjAzMzg4NCANCkwgNjA4LjYwNTYwMyAtMjA2LjAzMzg4NCANCkwgNjA4Ljc2NTQzNyAtMjA2LjAzMzg4NCANCkwgNjA4LjkyNTI3IC0yMDYuMDMzODg0IA0KTCA2MDkuMDg1MTA0IC0yMDYuMDMzODg0IA0KTCA2MDkuMjQ0OTM4IC0yMDYuMDMzODg0IA0KTCA2MDkuNDA0NzcyIC0yMDYuMDMzODg0IA0KTCA2MDkuNTY0NjA2IC0yMDYuMDMzODg0IA0KTCA2MDkuNzI0NDQgLTIwNi4wMzM4ODQgDQpMIDYwOS44ODQyNzQgLTIwNi4wMzM4ODQgDQpMIDYxMC4wNDQxMDggLTIwNi4wMzM4ODQgDQpMIDYxMC4yMDM5NDEgLTIwNi4wMzM4ODQgDQpMIDYxMC4zNjM3NzUgLTIwNi4wMzM4ODQgDQpMIDYxMC41MjM2MDkgLTIwNi4wMzM4ODQgDQpMIDYxMC42ODM0NDMgLTIwNi4wMzM4ODQgDQpMIDYxMC44NDMyNzcgLTIwNi4wMzM4ODQgDQpMIDYxMS4wMDMxMTEgLTIwNi4wMzM4ODQgDQpMIDYxMS4xNjI5NDUgLTIwNi4wMzM4ODQgDQpMIDYxMS4zMjI3NzkgLTIwNi4wMzM4ODQgDQpMIDYxMS40ODI2MTMgLTIwNi4wMzM4ODQgDQpMIDYxMS42NDI0NDYgLTIwNi4wMzM4ODQgDQpMIDYxMS44MDIyOCAtMjA2LjAzMzg4NCANCkwgNjExLjk2MjExNCAtMjA2LjAzMzg4NCANCkwgNjEyLjEyMTk0OCAtMjA2LjAzMzg4NCANCkwgNjEyLjI4MTc4MiAtMjA2LjAzMzg4NCANCkwgNjEyLjQ0MTYxNiAtMjA2LjAzMzg4NCANCkwgNjEyLjYwMTQ1IC0yMDYuMDMzODg0IA0KTCA2MTIuNzYxMjg0IC0yMDYuMDMzODg0IA0KTCA2MTIuOTIxMTE4IC0yMDYuMDMzODg0IA0KTCA2MTMuMDgwOTUxIC0yMDYuMDMzODg0IA0KTCA2MTMuMjQwNzg1IC0yMDYuMDMzODg0IA0KTCA2MTMuNDAwNjE5IC0yMDYuMDMzODg0IA0KTCA2MTMuNTYwNDUzIC0yMDYuMDMzODg0IA0KTCA2MTMuNzIwMjg3IC0yMDUuNTgyNzE0IA0KTCA2MTMuODgwMTIxIC0yMDUuNTE2MzY3IA0KTCA2MTQuMDM5OTU1IC0yMDUuNDMwODc0IA0KTCA2MTQuMTk5Nzg5IC0yMDUuMzMzMDg0IA0KTCA2MTQuMzU5NjIyIC0yMDUuMjIyNDc1IA0KTCA2MTQuNTE5NDU2IC0yMDUuMDgxNzA5IA0KTCA2MTQuNjc5MjkgLTIwNC45MjE3NzIgDQpMIDYxNC44MzkxMjQgLTIwNC43NDAyMDMgDQpMIDYxNC45OTg5NTggLTIwNC41MTA3NzIgDQpMIDYxNS4xNTg3OTIgLTIwNC4yNTEyMiANCkwgNjE1LjMxODYyNiAtMjAzLjk1NTM0MSANCkwgNjE1LjQ3ODQ2IC0yMDMuNTg1NTE1IA0KTCA2MTUuNjM4Mjk0IC0yMDMuMTY3OTI2IA0KTCA2MTUuNzk4MTI3IC0yMDIuNjg4ODI0IA0KTCA2MTUuOTU3OTYxIC0yMDIuMDk2MDE0IA0KTCA2MTYuMTE3Nzk1IC0yMDEuNDI4NzIyIA0KTCA2MTYuMjc3NjI5IC0yMDAuNjU5NDIgDQpMIDYxNi40Mzc0NjMgLTE5OS43MTgyNTkgDQpMIDYxNi41OTcyOTcgLTE5OC42NjMxMzEgDQpMIDYxNi43NTcxMzEgLTE5Ny40NDI3NiANCkwgNjE2LjkxNjk2NSAtMTk1Ljk3MDYyNiANCkwgNjE3LjA3Njc5OCAtMTk0LjMzMDM1OCANCkwgNjE3LjIzNjYzMiAtMTkyLjQzMzc0NyANCkwgNjE3LjM5NjQ2NiAtMTkwLjE4OTQyIA0KTCA2MTcuNTU2MyAtMTg3LjcxMzM5MiANCkwgNjE3LjcxNjEzNCAtMTg0Ljg3MDkgDQpMIDYxNy44NzU5NjggLTE4MS41OTU2OTggDQpMIDYxOC4wMzU4MDIgLTE3OC4wMzU1OTUgDQpMIDYxOC4xOTU2MzYgLTE3NC4wMTg1NSANCkwgNjE4LjM1NTQ3IC0xNjkuNTU0NTM3IA0KTCA2MTguNTE1MzAzIC0xNjQuODAzOTc3IA0KTCA2MTguNjc1MTM3IC0xNTkuNjA5NDM4IA0KTCA2MTguODM0OTcxIC0xNTQuMDg1ODU0IA0KTCA2MTguOTk0ODA1IC0xNDguMzYyNCANCkwgNjE5LjE1NDYzOSAtMTQyLjM3NzAxNSANCkwgNjE5LjMxNDQ3MyAtMTM2LjI5NjE5NCANCkwgNjE5LjQ3NDMwNyAtMTMwLjE3NDg0IA0KTCA2MTkuNjM0MTQxIC0xMjQuMDg2NjUxIA0KTCA2MTkuNzkzOTc1IC0xMTguMTI2MTk5IA0KTCA2MTkuOTUzODA4IC0xMTIuMjc3MzczIA0KTCA2MjAuMTEzNjQyIC0xMDYuNzA2OTQyIA0KTCA2MjAuMjczNDc2IC0xMDEuMzc5ODU1IA0KTCA2MjAuNDMzMzEgLTk2LjI0OTY5NiANCkwgNjIwLjU5MzE0NCAtOTEuNTE2MTc0IA0KTCA2MjAuNzUyOTc4IC04Ny4wNDY5MzQgDQpMIDYyMC45MTI4MTIgLTgyLjc5ODM1OCANCkwgNjIxLjA3MjY0NiAtNzguOTc1MDc3IA0KTCA2MjEuMjMyNDc5IC03NS4zOTY4MDEgDQpMIDYyMS4zOTIzMTMgLTcyLjAzMzY0MyANCkwgNjIxLjU1MjE0NyAtNjkuMDgxNTA4IA0KTCA2MjEuNzExOTgxIC02Ni4zMzcxMzcgDQpMIDYyMS44NzE4MTUgLTYzLjc4NjMwNiANCkwgNjIyLjAzMTY0OSAtNjEuNjAxNDU4IA0KTCA2MjIuMTkxNDgzIC01OS41NzkwNDYgDQpMIDYyMi4zNTEzMTcgLTU3LjcyNTk0NSANCkwgNjIyLjUxMTE1MSAtNTYuMTYwODg5IA0KTCA2MjIuNjcwOTg0IC01NC43MjIxMDMgDQpMIDYyMi44MzA4MTggLTUzLjQyMzA3MyANCkwgNjIyLjk5MDY1MiAtNTIuMzM0OTM5IA0KTCA2MjMuMTUwNDg2IC01MS4zNDE0NDMgDQpMIDYyMy4zMTAzMiAtNTAuNDU3MzAzIA0KTCA2MjMuNDcwMTU0IC00OS43MjMyNjEgDQpMIDYyMy42Mjk5ODggLTQ5LjA1ODc3OCANCkwgNjIzLjc4OTgyMiAtNDguNDc3OTAyIA0KTCA2MjMuOTQ5NjU1IC00OC4wMDIyOTIgDQpMIDYyNC4xMDk0ODkgLTQ3LjU3ODI0MyANCkwgNjI0LjI2OTMyMyAtNDcuMjE4ODQ2IA0KTCA2MjQuNDI5MTU3IC00Ni45MzUxOTMgDQpMIDYyNC41ODg5OTEgLTQ2LjY5MTE5NCANCkwgNjI0Ljc0ODgyNSAtNDYuNDk5MjIgDQpMIDYyNC45MDg2NTkgLTQ2LjM2NTYzMyANCkwgNjI1LjA2ODQ5MyAtNDYuMjY1MTQ3IA0KTCA2MjUuMjI4MzI3IC00Ni4yMTA5MDEgDQpMIDYyNS4zODgxNiAtNDYuMjA4MDcxIA0KTCA2MjUuNTQ3OTk0IC00Ni4yMzY3OTMgDQpMIDYyNS43MDc4MjggLTQ2LjMxMjYwMSANCkwgNjI1Ljg2NzY2MiAtNDYuNDQwNjEgDQpMIDYyNi4wMjc0OTYgLTQ2LjYwMzI4NyANCkwgNjI2LjE4NzMzIC00Ni44MjIwOCANCkwgNjI2LjM0NzE2NCAtNDcuMTAyMzEzIA0KTCA2MjYuNTA2OTk4IC00Ny40MjU5NTUgDQpMIDYyNi42NjY4MzIgLTQ3LjgyNTA1NSANCkwgNjI2LjgyNjY2NSAtNDguMzAzMDMxIA0KTCA2MjYuOTg2NDk5IC00OC44Mzk1NTMgDQpMIDYyNy4xNDYzMzMgLTQ5LjQ4NTAxNyANCkwgNjI3LjMwNjE2NyAtNTAuMjM4MDMgDQpMIDYyNy40NjYwMDEgLTUxLjA3Mzc5IA0KTCA2MjcuNjI1ODM1IC01Mi4wNzIyNDEgDQpMIDYyNy43ODU2NjkgLTUzLjIxOTk5IA0KTCA2MjcuOTQ1NTAzIC01NC40ODY2ODcgDQpMIDYyOC4xMDUzMzYgLTU1Ljk5OTM4IA0KTCA2MjguMjY1MTcgLTU3LjcxODc1MyANCkwgNjI4LjQyNTAwNCAtNTkuNjA4NDA4IA0KTCA2MjguNTg0ODM4IC02MS44NjMyNDYgDQpMIDYyOC43NDQ2NzIgLTY0LjM5NTQ4OCANCkwgNjI4LjkwNDUwNiAtNjcuMTY0MjgxIA0KTCA2MjkuMDY0MzQgLTcwLjQ1MDU5MiANCkwgNjI5LjIyNDE3NCAtNzQuMDgwNjM3IA0KTCA2MjkuMzg0MDA4IC03OC4wMTUzMiANCkwgNjI5LjU0Mzg0MSAtODIuNjAzODExIA0KTCA2MjkuNzAzNjc1IC04Ny41NTMzNiANCkwgNjI5Ljg2MzUwOSAtOTIuODM5MzM5IA0KTCA2MzAuMDIzMzQzIC05OC43Nzc1MjYgDQpMIDYzMC4xODMxNzcgLTEwNC45ODM0MTUgDQpMIDYzMC4zNDMwMTEgLTExMS40NjgzNyANCkwgNjMwLjUwMjg0NSAtMTE4LjMwNjcxMiANCkwgNjMwLjY2MjY3OSAtMTI1LjIxMTM4NSANCkwgNjMwLjgyMjUxMyAtMTMyLjE4MzI4MiANCkwgNjMwLjk4MjM0NiAtMTM5LjAyNjUxNSANCkwgNjMxLjE0MjE4IC0xNDUuNzAwNTE5IA0KTCA2MzEuMzAyMDE0IC0xNTIuMTU5NDM3IA0KTCA2MzEuNDYxODQ4IC0xNTguMTAyMTE1IA0KTCA2MzEuNjIxNjgyIC0xNjMuNzI1ODUgDQpMIDYzMS43ODE1MTYgLTE2OC45NDIwNDcgDQpMIDYzMS45NDEzNSAtMTczLjUyMjQwMSANCkwgNjMyLjEwMTE4NCAtMTc3Ljc1OTk2NiANCkwgNjMyLjI2MTAxNyAtMTgxLjU1MzM5IA0KTCA2MzIuNDIwODUxIC0xODQuNzkyNDcxIA0KTCA2MzIuNTgwNjg1IC0xODcuNzQyNDk3IA0KTCA2MzIuNzQwNTE5IC0xOTAuMzEzMjY2IA0KTCA2MzIuOTAwMzUzIC0xOTIuNDgwMzM0IA0KTCA2MzMuMDYwMTg3IC0xOTQuNDM0MjU2IA0KTCA2MzMuMjIwMDIxIC0xOTYuMTA0MDk3IA0KTCA2MzMuMzc5ODU1IC0xOTcuNTA2MTI1IA0KTCA2MzMuNTM5Njg5IC0xOTguNzYyMTM3IA0KTCA2MzMuNjk5NTIyIC0xOTkuODIwMzE4IA0KTCA2MzMuODU5MzU2IC0yMDAuNzEwMjE2IA0KTCA2MzQuMDE5MTkgLTIwMS41MDQxNzUgDQpMIDYzNC4xNzkwMjQgLTIwMi4xNjU2ODIgDQpMIDYzNC4zMzg4NTggLTIwMi43MjQ3MTcgDQpMIDYzNC40OTg2OTIgLTIwMy4yMjIyMyANCkwgNjM0LjY1ODUyNiAtMjAzLjYzMjk5NSANCkwgNjM0LjgxODM2IC0yMDMuOTgxODY4IA0KTCA2MzQuOTc4MTkzIC0yMDQuMjkxNTk3IA0KTCA2MzUuMTM4MDI3IC0yMDQuNTQ1MzI4IA0KTCA2MzUuMjk3ODYxIC0yMDQuNzYyNjQ1IA0KTCA2MzUuNDU3Njk1IC0yMDQuOTU1NDQ5IA0KTCA2MzUuNjE3NTI5IC0yMDUuMTEyMDggDQpMIDYzNS43NzczNjMgLTIwNS4yNDY5NjcgDQpMIDYzNS45MzcxOTcgLTIwNS4zNjYzNjQgDQpMIDYzNi4wOTcwMzEgLTIwNS40NjI3MTkgDQpMIDYzNi4yNTY4NjUgLTIwNS41NDY1NTQgDQpMIDYzNi40MTY2OTggLTIwNS42MjA4MjggDQpMIDYzNi41NzY1MzIgLTIwNS42ODAxMDkgDQpMIDYzNi43MzYzNjYgLTIwNS43MzE5NDQgDQpMIDYzNi44OTYyIC0yMDUuNzc3NzQ1IA0KTCA2MzcuMDU2MDM0IC0yMDUuODE0MTkzIA0KTCA2MzcuMjE1ODY4IC0yMDUuODQ2NDI3IA0KTCA2MzcuMzc1NzAyIC0yMDUuODc0OTk3IA0KTCA2MzcuNTM1NTM2IC0yMDUuODk3NDUzIA0KTCA2MzcuNjk1MzcgLTIwNi4wMzM4ODQgDQpMIDYzNy44NTUyMDMgLTIwNi4wMzM4ODQgDQpMIDYzOC4wMTUwMzcgLTIwNi4wMzM4ODQgDQpMIDYzOC4xNzQ4NzEgLTIwNi4wMzM4ODQgDQpMIDYzOC4zMzQ3MDUgLTIwNi4wMzM4ODQgDQpMIDYzOC40OTQ1MzkgLTIwNi4wMzM4ODQgDQpMIDYzOC42NTQzNzMgLTIwNi4wMzM4ODQgDQpMIDYzOC44MTQyMDcgLTIwNi4wMzM4ODQgDQpMIDYzOC45NzQwNDEgLTIwNi4wMzM4ODQgDQpMIDYzOS4xMzM4NzQgLTIwNi4wMzM4ODQgDQpMIDYzOS4yOTM3MDggLTIwNi4wMzM4ODQgDQpMIDYzOS40NTM1NDIgLTIwNi4wMzM4ODQgDQpMIDYzOS42MTMzNzYgLTIwNi4wMzM4ODQgDQpMIDYzOS43NzMyMSAtMjA2LjAzMzg4NCANCkwgNjM5LjkzMzA0NCAtMjA2LjAzMzg4NCANCkwgNjQwLjA5Mjg3OCAtMjA2LjAzMzg4NCANCkwgNjQwLjI1MjcxMiAtMjA2LjAzMzg4NCANCkwgNjQwLjQxMjU0NiAtMjA2LjAzMzg4NCANCkwgNjQwLjU3MjM3OSAtMjA2LjAzMzg4NCANCkwgNjQwLjczMjIxMyAtMjA2LjAzMzg4NCANCkwgNjQwLjg5MjA0NyAtMjA2LjAzMzg4NCANCkwgNjQxLjA1MTg4MSAtMjA2LjAzMzg4NCANCkwgNjQxLjIxMTcxNSAtMjA2LjAzMzg4NCANCkwgNjQxLjM3MTU0OSAtMjA2LjAzMzg4NCANCkwgNjQxLjUzMTM4MyAtMjA2LjAzMzg4NCANCkwgNjQxLjY5MTIxNyAtMjA2LjAzMzg4NCANCkwgNjQxLjg1MTA1IC0yMDYuMDMzODg0IA0KTCA2NDIuMDEwODg0IC0yMDYuMDMzODg0IA0KTCA2NDIuMTcwNzE4IC0yMDYuMDMzODg0IA0KTCA2NDIuMzMwNTUyIC0yMDYuMDMzODg0IA0KTCA2NDIuNDkwMzg2IC0yMDYuMDMzODg0IA0KTCA2NDIuNjUwMjIgLTIwNi4wMzM4ODQgDQpMIDY0Mi44MTAwNTQgLTIwNi4wMzM4ODQgDQpMIDY0Mi45Njk4ODggLTIwNi4wMzM4ODQgDQpMIDY0My4xMjk3MjIgLTIwNi4wMzM4ODQgDQpMIDY0My4yODk1NTUgLTIwNi4wMzM4ODQgDQpMIDY0My40NDkzODkgLTIwNi4wMzM4ODQgDQpMIDY0My42MDkyMjMgLTIwNi4wMzM4ODQgDQpMIDY0My43NjkwNTcgLTIwNi4wMzM4ODQgDQpMIDY0My45Mjg4OTEgLTIwNi4wMzM4ODQgDQpMIDY0NC4wODg3MjUgLTIwNi4wMzM4ODQgDQpMIDY0NC4yNDg1NTkgLTIwNi4wMzM4ODQgDQpMIDY0NC40MDgzOTMgLTIwNi4wMzM4ODQgDQpMIDY0NC41NjgyMjcgLTIwNi4wMzM4ODQgDQpMIDY0NC43MjgwNiAtMjA2LjAzMzg4NCANCkwgNjQ0Ljg4Nzg5NCAtMjA2LjAzMzg4NCANCkwgNjQ1LjA0NzcyOCAtMjA2LjAzMzg4NCANCkwgNjQ1LjIwNzU2MiAtMjA2LjAzMzg4NCANCkwgNjQ1LjM2NzM5NiAtMjA2LjAzMzg4NCANCkwgNjQ1LjM2NzM5NiAtMjA2LjAzMzg4NCANCkwgNjQ1LjM2NzM5NiAtMjA2LjAzMzg4NCANCkwgNjQ1LjIwNzU2MiAtMjA2LjAzMzg4NCANCkwgNjQ1LjA0NzcyOCAtMjA2LjAzMzg4NCANCkwgNjQ0Ljg4Nzg5NCAtMjA2LjAzMzg4NCANCkwgNjQ0LjcyODA2IC0yMDYuMDMzODg0IA0KTCA2NDQuNTY4MjI3IC0yMDYuMDMzODg0IA0KTCA2NDQuNDA4MzkzIC0yMDYuMDMzODg0IA0KTCA2NDQuMjQ4NTU5IC0yMDYuMDMzODg0IA0KTCA2NDQuMDg4NzI1IC0yMDYuMDMzODg0IA0KTCA2NDMuOTI4ODkxIC0yMDYuMDMzODg0IA0KTCA2NDMuNzY5MDU3IC0yMDYuMDMzODg0IA0KTCA2NDMuNjA5MjIzIC0yMDYuMDMzODg0IA0KTCA2NDMuNDQ5Mzg5IC0yMDYuMDMzODg0IA0KTCA2NDMuMjg5NTU1IC0yMDYuMDMzODg0IA0KTCA2NDMuMTI5NzIyIC0yMDYuMDMzODg0IA0KTCA2NDIuOTY5ODg4IC0yMDYuMDMzODg0IA0KTCA2NDIuODEwMDU0IC0yMDYuMDMzODg0IA0KTCA2NDIuNjUwMjIgLTIwNi4wMzM4ODQgDQpMIDY0Mi40OTAzODYgLTIwNi4wMzM4ODQgDQpMIDY0Mi4zMzA1NTIgLTIwNi4wMzM4ODQgDQpMIDY0Mi4xNzA3MTggLTIwNi4wMzM4ODQgDQpMIDY0Mi4wMTA4ODQgLTIwNi4wMzM4ODQgDQpMIDY0MS44NTEwNSAtMjA2LjAzMzg4NCANCkwgNjQxLjY5MTIxNyAtMjA2LjAzMzg4NCANCkwgNjQxLjUzMTM4MyAtMjA2LjAzMzg4NCANCkwgNjQxLjM3MTU0OSAtMjA2LjAzMzg4NCANCkwgNjQxLjIxMTcxNSAtMjA2LjAzMzg4NCANCkwgNjQxLjA1MTg4MSAtMjA2LjAzMzg4NCANCkwgNjQwLjg5MjA0NyAtMjA2LjAzMzg4NCANCkwgNjQwLjczMjIxMyAtMjA2LjAzMzg4NCANCkwgNjQwLjU3MjM3OSAtMjA2LjAzMzg4NCANCkwgNjQwLjQxMjU0NiAtMjA2LjAzMzg4NCANCkwgNjQwLjI1MjcxMiAtMjA2LjAzMzg4NCANCkwgNjQwLjA5Mjg3OCAtMjA2LjAzMzg4NCANCkwgNjM5LjkzMzA0NCAtMjA2LjAzMzg4NCANCkwgNjM5Ljc3MzIxIC0yMDYuMDMzODg0IA0KTCA2MzkuNjEzMzc2IC0yMDYuMDMzODg0IA0KTCA2MzkuNDUzNTQyIC0yMDYuMDMzODg0IA0KTCA2MzkuMjkzNzA4IC0yMDYuMDMzODg0IA0KTCA2MzkuMTMzODc0IC0yMDYuMDMzODg0IA0KTCA2MzguOTc0MDQxIC0yMDYuMDMzODg0IA0KTCA2MzguODE0MjA3IC0yMDYuMDMzODg0IA0KTCA2MzguNjU0MzczIC0yMDYuMDMzODg0IA0KTCA2MzguNDk0NTM5IC0yMDYuMDMzODg0IA0KTCA2MzguMzM0NzA1IC0yMDYuMDMzODg0IA0KTCA2MzguMTc0ODcxIC0yMDYuMDMzODg0IA0KTCA2MzguMDE1MDM3IC0yMDYuMDMzODg0IA0KTCA2MzcuODU1MjAzIC0yMDYuMDMzODg0IA0KTCA2MzcuNjk1MzcgLTIwNi4wMzM4ODQgDQpMIDYzNy41MzU1MzYgLTIwNi4wMzM4ODQgDQpMIDYzNy4zNzU3MDIgLTIwNi4wMzM4ODQgDQpMIDYzNy4yMTU4NjggLTIwNi4wMzM4ODQgDQpMIDYzNy4wNTYwMzQgLTIwNi4wMzM4ODQgDQpMIDYzNi44OTYyIC0yMDYuMDMzODg0IA0KTCA2MzYuNzM2MzY2IC0yMDYuMDMzODg0IA0KTCA2MzYuNTc2NTMyIC0yMDYuMDMzODg0IA0KTCA2MzYuNDE2Njk4IC0yMDYuMDMzODg0IA0KTCA2MzYuMjU2ODY1IC0yMDYuMDMzODg0IA0KTCA2MzYuMDk3MDMxIC0yMDYuMDMzODg0IA0KTCA2MzUuOTM3MTk3IC0yMDYuMDMzODg0IA0KTCA2MzUuNzc3MzYzIC0yMDYuMDMzODg0IA0KTCA2MzUuNjE3NTI5IC0yMDYuMDMzODg0IA0KTCA2MzUuNDU3Njk1IC0yMDYuMDMzODg0IA0KTCA2MzUuMjk3ODYxIC0yMDYuMDMzODg0IA0KTCA2MzUuMTM4MDI3IC0yMDYuMDMzODg0IA0KTCA2MzQuOTc4MTkzIC0yMDYuMDMzODg0IA0KTCA2MzQuODE4MzYgLTIwNi4wMzM4ODQgDQpMIDYzNC42NTg1MjYgLTIwNi4wMzM4ODQgDQpMIDYzNC40OTg2OTIgLTIwNi4wMzM4ODQgDQpMIDYzNC4zMzg4NTggLTIwNi4wMzM4ODQgDQpMIDYzNC4xNzkwMjQgLTIwNi4wMzM4ODQgDQpMIDYzNC4wMTkxOSAtMjA2LjAzMzg4NCANCkwgNjMzLjg1OTM1NiAtMjA2LjAzMzg4NCANCkwgNjMzLjY5OTUyMiAtMjA2LjAzMzg4NCANCkwgNjMzLjUzOTY4OSAtMjA2LjAzMzg4NCANCkwgNjMzLjM3OTg1NSAtMjA2LjAzMzg4NCANCkwgNjMzLjIyMDAyMSAtMjA2LjAzMzg4NCANCkwgNjMzLjA2MDE4NyAtMjA2LjAzMzg4NCANCkwgNjMyLjkwMDM1MyAtMjA2LjAzMzg4NCANCkwgNjMyLjc0MDUxOSAtMjA2LjAzMzg4NCANCkwgNjMyLjU4MDY4NSAtMjA2LjAzMzg4NCANCkwgNjMyLjQyMDg1MSAtMjA2LjAzMzg4NCANCkwgNjMyLjI2MTAxNyAtMjA2LjAzMzg4NCANCkwgNjMyLjEwMTE4NCAtMjA2LjAzMzg4NCANCkwgNjMxLjk0MTM1IC0yMDYuMDMzODg0IA0KTCA2MzEuNzgxNTE2IC0yMDYuMDMzODg0IA0KTCA2MzEuNjIxNjgyIC0yMDYuMDMzODg0IA0KTCA2MzEuNDYxODQ4IC0yMDYuMDMzODg0IA0KTCA2MzEuMzAyMDE0IC0yMDYuMDMzODg0IA0KTCA2MzEuMTQyMTggLTIwNi4wMzM4ODQgDQpMIDYzMC45ODIzNDYgLTIwNi4wMzM4ODQgDQpMIDYzMC44MjI1MTMgLTIwNi4wMzM4ODQgDQpMIDYzMC42NjI2NzkgLTIwNi4wMzM4ODQgDQpMIDYzMC41MDI4NDUgLTIwNi4wMzM4ODQgDQpMIDYzMC4zNDMwMTEgLTIwNi4wMzM4ODQgDQpMIDYzMC4xODMxNzcgLTIwNi4wMzM4ODQgDQpMIDYzMC4wMjMzNDMgLTIwNi4wMzM4ODQgDQpMIDYyOS44NjM1MDkgLTIwNi4wMzM4ODQgDQpMIDYyOS43MDM2NzUgLTIwNi4wMzM4ODQgDQpMIDYyOS41NDM4NDEgLTIwNi4wMzM4ODQgDQpMIDYyOS4zODQwMDggLTIwNi4wMzM4ODQgDQpMIDYyOS4yMjQxNzQgLTIwNi4wMzM4ODQgDQpMIDYyOS4wNjQzNCAtMjA2LjAzMzg4NCANCkwgNjI4LjkwNDUwNiAtMjA2LjAzMzg4NCANCkwgNjI4Ljc0NDY3MiAtMjA2LjAzMzg4NCANCkwgNjI4LjU4NDgzOCAtMjA2LjAzMzg4NCANCkwgNjI4LjQyNTAwNCAtMjA2LjAzMzg4NCANCkwgNjI4LjI2NTE3IC0yMDYuMDMzODg0IA0KTCA2MjguMTA1MzM2IC0yMDYuMDMzODg0IA0KTCA2MjcuOTQ1NTAzIC0yMDYuMDMzODg0IA0KTCA2MjcuNzg1NjY5IC0yMDYuMDMzODg0IA0KTCA2MjcuNjI1ODM1IC0yMDYuMDMzODg0IA0KTCA2MjcuNDY2MDAxIC0yMDYuMDMzODg0IA0KTCA2MjcuMzA2MTY3IC0yMDYuMDMzODg0IA0KTCA2MjcuMTQ2MzMzIC0yMDYuMDMzODg0IA0KTCA2MjYuOTg2NDk5IC0yMDYuMDMzODg0IA0KTCA2MjYuODI2NjY1IC0yMDYuMDMzODg0IA0KTCA2MjYuNjY2ODMyIC0yMDYuMDMzODg0IA0KTCA2MjYuNTA2OTk4IC0yMDYuMDMzODg0IA0KTCA2MjYuMzQ3MTY0IC0yMDYuMDMzODg0IA0KTCA2MjYuMTg3MzMgLTIwNi4wMzM4ODQgDQpMIDYyNi4wMjc0OTYgLTIwNi4wMzM4ODQgDQpMIDYyNS44Njc2NjIgLTIwNi4wMzM4ODQgDQpMIDYyNS43MDc4MjggLTIwNi4wMzM4ODQgDQpMIDYyNS41NDc5OTQgLTIwNi4wMzM4ODQgDQpMIDYyNS4zODgxNiAtMjA2LjAzMzg4NCANCkwgNjI1LjIyODMyNyAtMjA2LjAzMzg4NCANCkwgNjI1LjA2ODQ5MyAtMjA2LjAzMzg4NCANCkwgNjI0LjkwODY1OSAtMjA2LjAzMzg4NCANCkwgNjI0Ljc0ODgyNSAtMjA2LjAzMzg4NCANCkwgNjI0LjU4ODk5MSAtMjA2LjAzMzg4NCANCkwgNjI0LjQyOTE1NyAtMjA2LjAzMzg4NCANCkwgNjI0LjI2OTMyMyAtMjA2LjAzMzg4NCANCkwgNjI0LjEwOTQ4OSAtMjA2LjAzMzg4NCANCkwgNjIzLjk0OTY1NSAtMjA2LjAzMzg4NCANCkwgNjIzLjc4OTgyMiAtMjA2LjAzMzg4NCANCkwgNjIzLjYyOTk4OCAtMjA2LjAzMzg4NCANCkwgNjIzLjQ3MDE1NCAtMjA2LjAzMzg4NCANCkwgNjIzLjMxMDMyIC0yMDYuMDMzODg0IA0KTCA2MjMuMTUwNDg2IC0yMDYuMDMzODg0IA0KTCA2MjIuOTkwNjUyIC0yMDYuMDMzODg0IA0KTCA2MjIuODMwODE4IC0yMDYuMDMzODg0IA0KTCA2MjIuNjcwOTg0IC0yMDYuMDMzODg0IA0KTCA2MjIuNTExMTUxIC0yMDYuMDMzODg0IA0KTCA2MjIuMzUxMzE3IC0yMDYuMDMzODg0IA0KTCA2MjIuMTkxNDgzIC0yMDYuMDMzODg0IA0KTCA2MjIuMDMxNjQ5IC0yMDYuMDMzODg0IA0KTCA2MjEuODcxODE1IC0yMDYuMDMzODg0IA0KTCA2MjEuNzExOTgxIC0yMDYuMDMzODg0IA0KTCA2MjEuNTUyMTQ3IC0yMDYuMDMzODg0IA0KTCA2MjEuMzkyMzEzIC0yMDYuMDMzODg0IA0KTCA2MjEuMjMyNDc5IC0yMDYuMDMzODg0IA0KTCA2MjEuMDcyNjQ2IC0yMDYuMDMzODg0IA0KTCA2MjAuOTEyODEyIC0yMDYuMDMzODg0IA0KTCA2MjAuNzUyOTc4IC0yMDYuMDMzODg0IA0KTCA2MjAuNTkzMTQ0IC0yMDYuMDMzODg0IA0KTCA2MjAuNDMzMzEgLTIwNi4wMzM4ODQgDQpMIDYyMC4yNzM0NzYgLTIwNi4wMzM4ODQgDQpMIDYyMC4xMTM2NDIgLTIwNi4wMzM4ODQgDQpMIDYxOS45NTM4MDggLTIwNi4wMzM4ODQgDQpMIDYxOS43OTM5NzUgLTIwNi4wMzM4ODQgDQpMIDYxOS42MzQxNDEgLTIwNi4wMzM4ODQgDQpMIDYxOS40NzQzMDcgLTIwNi4wMzM4ODQgDQpMIDYxOS4zMTQ0NzMgLTIwNi4wMzM4ODQgDQpMIDYxOS4xNTQ2MzkgLTIwNi4wMzM4ODQgDQpMIDYxOC45OTQ4MDUgLTIwNi4wMzM4ODQgDQpMIDYxOC44MzQ5NzEgLTIwNi4wMzM4ODQgDQpMIDYxOC42NzUxMzcgLTIwNi4wMzM4ODQgDQpMIDYxOC41MTUzMDMgLTIwNi4wMzM4ODQgDQpMIDYxOC4zNTU0NyAtMjA2LjAzMzg4NCANCkwgNjE4LjE5NTYzNiAtMjA2LjAzMzg4NCANCkwgNjE4LjAzNTgwMiAtMjA2LjAzMzg4NCANCkwgNjE3Ljg3NTk2OCAtMjA2LjAzMzg4NCANCkwgNjE3LjcxNjEzNCAtMjA2LjAzMzg4NCANCkwgNjE3LjU1NjMgLTIwNi4wMzM4ODQgDQpMIDYxNy4zOTY0NjYgLTIwNi4wMzM4ODQgDQpMIDYxNy4yMzY2MzIgLTIwNi4wMzM4ODQgDQpMIDYxNy4wNzY3OTggLTIwNi4wMzM4ODQgDQpMIDYxNi45MTY5NjUgLTIwNi4wMzM4ODQgDQpMIDYxNi43NTcxMzEgLTIwNi4wMzM4ODQgDQpMIDYxNi41OTcyOTcgLTIwNi4wMzM4ODQgDQpMIDYxNi40Mzc0NjMgLTIwNi4wMzM4ODQgDQpMIDYxNi4yNzc2MjkgLTIwNi4wMzM4ODQgDQpMIDYxNi4xMTc3OTUgLTIwNi4wMzM4ODQgDQpMIDYxNS45NTc5NjEgLTIwNi4wMzM4ODQgDQpMIDYxNS43OTgxMjcgLTIwNi4wMzM4ODQgDQpMIDYxNS42MzgyOTQgLTIwNi4wMzM4ODQgDQpMIDYxNS40Nzg0NiAtMjA2LjAzMzg4NCANCkwgNjE1LjMxODYyNiAtMjA2LjAzMzg4NCANCkwgNjE1LjE1ODc5MiAtMjA2LjAzMzg4NCANCkwgNjE0Ljk5ODk1OCAtMjA2LjAzMzg4NCANCkwgNjE0LjgzOTEyNCAtMjA2LjAzMzg4NCANCkwgNjE0LjY3OTI5IC0yMDYuMDMzODg0IA0KTCA2MTQuNTE5NDU2IC0yMDYuMDMzODg0IA0KTCA2MTQuMzU5NjIyIC0yMDYuMDMzODg0IA0KTCA2MTQuMTk5Nzg5IC0yMDYuMDMzODg0IA0KTCA2MTQuMDM5OTU1IC0yMDYuMDMzODg0IA0KTCA2MTMuODgwMTIxIC0yMDYuMDMzODg0IA0KTCA2MTMuNzIwMjg3IC0yMDYuMDMzODg0IA0KTCA2MTMuNTYwNDUzIC0yMDYuMDMzODg0IA0KTCA2MTMuNDAwNjE5IC0yMDYuMDMzODg0IA0KTCA2MTMuMjQwNzg1IC0yMDYuMDMzODg0IA0KTCA2MTMuMDgwOTUxIC0yMDYuMDMzODg0IA0KTCA2MTIuOTIxMTE4IC0yMDYuMDMzODg0IA0KTCA2MTIuNzYxMjg0IC0yMDYuMDMzODg0IA0KTCA2MTIuNjAxNDUgLTIwNi4wMzM4ODQgDQpMIDYxMi40NDE2MTYgLTIwNi4wMzM4ODQgDQpMIDYxMi4yODE3ODIgLTIwNi4wMzM4ODQgDQpMIDYxMi4xMjE5NDggLTIwNi4wMzM4ODQgDQpMIDYxMS45NjIxMTQgLTIwNi4wMzM4ODQgDQpMIDYxMS44MDIyOCAtMjA2LjAzMzg4NCANCkwgNjExLjY0MjQ0NiAtMjA2LjAzMzg4NCANCkwgNjExLjQ4MjYxMyAtMjA2LjAzMzg4NCANCkwgNjExLjMyMjc3OSAtMjA2LjAzMzg4NCANCkwgNjExLjE2Mjk0NSAtMjA2LjAzMzg4NCANCkwgNjExLjAwMzExMSAtMjA2LjAzMzg4NCANCkwgNjEwLjg0MzI3NyAtMjA2LjAzMzg4NCANCkwgNjEwLjY4MzQ0MyAtMjA2LjAzMzg4NCANCkwgNjEwLjUyMzYwOSAtMjA2LjAzMzg4NCANCkwgNjEwLjM2Mzc3NSAtMjA2LjAzMzg4NCANCkwgNjEwLjIwMzk0MSAtMjA2LjAzMzg4NCANCkwgNjEwLjA0NDEwOCAtMjA2LjAzMzg4NCANCkwgNjA5Ljg4NDI3NCAtMjA2LjAzMzg4NCANCkwgNjA5LjcyNDQ0IC0yMDYuMDMzODg0IA0KTCA2MDkuNTY0NjA2IC0yMDYuMDMzODg0IA0KTCA2MDkuNDA0NzcyIC0yMDYuMDMzODg0IA0KTCA2MDkuMjQ0OTM4IC0yMDYuMDMzODg0IA0KTCA2MDkuMDg1MTA0IC0yMDYuMDMzODg0IA0KTCA2MDguOTI1MjcgLTIwNi4wMzM4ODQgDQpMIDYwOC43NjU0MzcgLTIwNi4wMzM4ODQgDQpMIDYwOC42MDU2MDMgLTIwNi4wMzM4ODQgDQpMIDYwOC40NDU3NjkgLTIwNi4wMzM4ODQgDQpMIDYwOC4yODU5MzUgLTIwNi4wMzM4ODQgDQpMIDYwOC4xMjYxMDEgLTIwNi4wMzM4ODQgDQpMIDYwNy45NjYyNjcgLTIwNi4wMzM4ODQgDQpMIDYwNy44MDY0MzMgLTIwNi4wMzM4ODQgDQpMIDYwNy42NDY1OTkgLTIwNi4wMzM4ODQgDQpMIDYwNy40ODY3NjUgLTIwNi4wMzM4ODQgDQpMIDYwNy4zMjY5MzIgLTIwNi4wMzM4ODQgDQpMIDYwNy4xNjcwOTggLTIwNi4wMzM4ODQgDQpMIDYwNy4wMDcyNjQgLTIwNi4wMzM4ODQgDQpMIDYwNi44NDc0MyAtMjA2LjAzMzg4NCANCkwgNjA2LjY4NzU5NiAtMjA2LjAzMzg4NCANCkwgNjA2LjUyNzc2MiAtMjA2LjAzMzg4NCANCkwgNjA2LjM2NzkyOCAtMjA2LjAzMzg4NCANCkwgNjA2LjIwODA5NCAtMjA2LjAzMzg4NCANCkwgNjA2LjA0ODI2MSAtMjA2LjAzMzg4NCANCkwgNjA1Ljg4ODQyNyAtMjA2LjAzMzg4NCANCkwgNjA1LjcyODU5MyAtMjA2LjAzMzg4NCANCkwgNjA1LjU2ODc1OSAtMjA2LjAzMzg4NCANCkwgNjA1LjQwODkyNSAtMjA2LjAzMzg4NCANCkwgNjA1LjI0OTA5MSAtMjA2LjAzMzg4NCANCkwgNjA1LjA4OTI1NyAtMjA2LjAzMzg4NCANCkwgNjA0LjkyOTQyMyAtMjA2LjAzMzg4NCANCkwgNjA0Ljc2OTU4OSAtMjA2LjAzMzg4NCANCkwgNjA0LjYwOTc1NiAtMjA2LjAzMzg4NCANCkwgNjA0LjQ0OTkyMiAtMjA2LjAzMzg4NCANCkwgNjA0LjI5MDA4OCAtMjA2LjAzMzg4NCANCkwgNjA0LjEzMDI1NCAtMjA2LjAzMzg4NCANCkwgNjAzLjk3MDQyIC0yMDYuMDMzODg0IA0KTCA2MDMuODEwNTg2IC0yMDYuMDMzODg0IA0KTCA2MDMuNjUwNzUyIC0yMDYuMDMzODg0IA0KTCA2MDMuNDkwOTE4IC0yMDYuMDMzODg0IA0KTCA2MDMuMzMxMDg0IC0yMDYuMDMzODg0IA0KTCA2MDMuMTcxMjUxIC0yMDYuMDMzODg0IA0KTCA2MDMuMDExNDE3IC0yMDYuMDMzODg0IA0KTCA2MDIuODUxNTgzIC0yMDYuMDMzODg0IA0KTCA2MDIuNjkxNzQ5IC0yMDYuMDMzODg0IA0KTCA2MDIuNTMxOTE1IC0yMDYuMDMzODg0IA0KTCA2MDIuMzcyMDgxIC0yMDYuMDMzODg0IA0KTCA2MDIuMjEyMjQ3IC0yMDYuMDMzODg0IA0KTCA2MDIuMDUyNDEzIC0yMDYuMDMzODg0IA0KTCA2MDEuODkyNTggLTIwNi4wMzM4ODQgDQpMIDYwMS43MzI3NDYgLTIwNi4wMzM4ODQgDQpMIDYwMS41NzI5MTIgLTIwNi4wMzM4ODQgDQpMIDYwMS40MTMwNzggLTIwNi4wMzM4ODQgDQpMIDYwMS4yNTMyNDQgLTIwNi4wMzM4ODQgDQpMIDYwMS4wOTM0MSAtMjA2LjAzMzg4NCANCkwgNjAwLjkzMzU3NiAtMjA2LjAzMzg4NCANCkwgNjAwLjc3Mzc0MiAtMjA2LjAzMzg4NCANCkwgNjAwLjYxMzkwOCAtMjA2LjAzMzg4NCANCkwgNjAwLjQ1NDA3NSAtMjA2LjAzMzg4NCANCkwgNjAwLjI5NDI0MSAtMjA2LjAzMzg4NCANCkwgNjAwLjEzNDQwNyAtMjA2LjAzMzg4NCANCkwgNTk5Ljk3NDU3MyAtMjA2LjAzMzg4NCANCkwgNTk5LjgxNDczOSAtMjA2LjAzMzg4NCANCkwgNTk5LjY1NDkwNSAtMjA2LjAzMzg4NCANCkwgNTk5LjQ5NTA3MSAtMjA2LjAzMzg4NCANCkwgNTk5LjMzNTIzNyAtMjA2LjAzMzg4NCANCkwgNTk5LjE3NTQwMyAtMjA2LjAzMzg4NCANCkwgNTk5LjAxNTU3IC0yMDYuMDMzODg0IA0KTCA1OTguODU1NzM2IC0yMDYuMDMzODg0IA0KTCA1OTguNjk1OTAyIC0yMDYuMDMzODg0IA0KTCA1OTguNTM2MDY4IC0yMDYuMDMzODg0IA0KTCA1OTguMzc2MjM0IC0yMDYuMDMzODg0IA0KTCA1OTguMjE2NCAtMjA2LjAzMzg4NCANCkwgNTk4LjA1NjU2NiAtMjA2LjAzMzg4NCANCkwgNTk3Ljg5NjczMiAtMjA2LjAzMzg4NCANCkwgNTk3LjczNjg5OSAtMjA2LjAzMzg4NCANCkwgNTk3LjU3NzA2NSAtMjA2LjAzMzg4NCANCkwgNTk3LjQxNzIzMSAtMjA2LjAzMzg4NCANCkwgNTk3LjI1NzM5NyAtMjA2LjAzMzg4NCANCkwgNTk3LjA5NzU2MyAtMjA2LjAzMzg4NCANCkwgNTk2LjkzNzcyOSAtMjA2LjAzMzg4NCANCkwgNTk2Ljc3Nzg5NSAtMjA2LjAzMzg4NCANCkwgNTk2LjYxODA2MSAtMjA2LjAzMzg4NCANCkwgNTk2LjQ1ODIyNyAtMjA2LjAzMzg4NCANCkwgNTk2LjI5ODM5NCAtMjA2LjAzMzg4NCANCkwgNTk2LjEzODU2IC0yMDYuMDMzODg0IA0KTCA1OTUuOTc4NzI2IC0yMDYuMDMzODg0IA0KTCA1OTUuODE4ODkyIC0yMDYuMDMzODg0IA0KTCA1OTUuNjU5MDU4IC0yMDYuMDMzODg0IA0KTCA1OTUuNDk5MjI0IC0yMDYuMDMzODg0IA0KTCA1OTUuMzM5MzkgLTIwNi4wMzM4ODQgDQpMIDU5NS4xNzk1NTYgLTIwNi4wMzM4ODQgDQpMIDU5NS4wMTk3MjMgLTIwNi4wMzM4ODQgDQpMIDU5NC44NTk4ODkgLTIwNi4wMzM4ODQgDQpMIDU5NC43MDAwNTUgLTIwNi4wMzM4ODQgDQpMIDU5NC41NDAyMjEgLTIwNi4wMzM4ODQgDQpMIDU5NC4zODAzODcgLTIwNi4wMzM4ODQgDQpMIDU5NC4yMjA1NTMgLTIwNi4wMzM4ODQgDQpMIDU5NC4wNjA3MTkgLTIwNi4wMzM4ODQgDQpMIDU5My45MDA4ODUgLTIwNi4wMzM4ODQgDQpMIDU5My43NDEwNTEgLTIwNi4wMzM4ODQgDQpMIDU5My41ODEyMTggLTIwNi4wMzM4ODQgDQpMIDU5My40MjEzODQgLTIwNi4wMzM4ODQgDQpMIDU5My4yNjE1NSAtMjA2LjAzMzg4NCANCkwgNTkzLjEwMTcxNiAtMjA2LjAzMzg4NCANCkwgNTkyLjk0MTg4MiAtMjA2LjAzMzg4NCANCkwgNTkyLjc4MjA0OCAtMjA2LjAzMzg4NCANCkwgNTkyLjYyMjIxNCAtMjA2LjAzMzg4NCANCkwgNTkyLjQ2MjM4IC0yMDYuMDMzODg0IA0KTCA1OTIuMzAyNTQ2IC0yMDYuMDMzODg0IA0KTCA1OTIuMTQyNzEzIC0yMDYuMDMzODg0IA0KTCA1OTEuOTgyODc5IC0yMDYuMDMzODg0IA0KTCA1OTEuODIzMDQ1IC0yMDYuMDMzODg0IA0KTCA1OTEuNjYzMjExIC0yMDYuMDMzODg0IA0KTCA1OTEuNTAzMzc3IC0yMDYuMDMzODg0IA0KTCA1OTEuMzQzNTQzIC0yMDYuMDMzODg0IA0KTCA1OTEuMTgzNzA5IC0yMDYuMDMzODg0IA0KTCA1OTEuMDIzODc1IC0yMDYuMDMzODg0IA0KTCA1OTAuODY0MDQyIC0yMDYuMDMzODg0IA0KTCA1OTAuNzA0MjA4IC0yMDYuMDMzODg0IA0KTCA1OTAuNTQ0Mzc0IC0yMDYuMDMzODg0IA0KTCA1OTAuMzg0NTQgLTIwNi4wMzM4ODQgDQpMIDU5MC4yMjQ3MDYgLTIwNi4wMzM4ODQgDQpMIDU5MC4wNjQ4NzIgLTIwNi4wMzM4ODQgDQpMIDU4OS45MDUwMzggLTIwNi4wMzM4ODQgDQpMIDU4OS43NDUyMDQgLTIwNi4wMzM4ODQgDQpMIDU4OS41ODUzNyAtMjA2LjAzMzg4NCANCkwgNTg5LjQyNTUzNyAtMjA2LjAzMzg4NCANCkwgNTg5LjI2NTcwMyAtMjA2LjAzMzg4NCANCkwgNTg5LjEwNTg2OSAtMjA2LjAzMzg4NCANCkwgNTg4Ljk0NjAzNSAtMjA2LjAzMzg4NCANCkwgNTg4Ljc4NjIwMSAtMjA2LjAzMzg4NCANCkwgNTg4LjYyNjM2NyAtMjA2LjAzMzg4NCANCkwgNTg4LjQ2NjUzMyAtMjA2LjAzMzg4NCANCkwgNTg4LjMwNjY5OSAtMjA2LjAzMzg4NCANCkwgNTg4LjE0Njg2NiAtMjA2LjAzMzg4NCANCkwgNTg3Ljk4NzAzMiAtMjA2LjAzMzg4NCANCkwgNTg3LjgyNzE5OCAtMjA2LjAzMzg4NCANCkwgNTg3LjY2NzM2NCAtMjA2LjAzMzg4NCANCkwgNTg3LjUwNzUzIC0yMDYuMDMzODg0IA0KTCA1ODcuMzQ3Njk2IC0yMDYuMDMzODg0IA0KTCA1ODcuMTg3ODYyIC0yMDYuMDMzODg0IA0KTCA1ODcuMDI4MDI4IC0yMDYuMDMzODg0IA0KTCA1ODYuODY4MTk0IC0yMDYuMDMzODg0IA0KTCA1ODYuNzA4MzYxIC0yMDYuMDMzODg0IA0KTCA1ODYuNTQ4NTI3IC0yMDYuMDMzODg0IA0KTCA1ODYuMzg4NjkzIC0yMDYuMDMzODg0IA0KTCA1ODYuMjI4ODU5IC0yMDYuMDMzODg0IA0KTCA1ODYuMDY5MDI1IC0yMDYuMDMzODg0IA0KTCA1ODUuOTA5MTkxIC0yMDYuMDMzODg0IA0KTCA1ODUuNzQ5MzU3IC0yMDYuMDMzODg0IA0KTCA1ODUuNTg5NTIzIC0yMDYuMDMzODg0IA0KTCA1ODUuNDI5Njg5IC0yMDYuMDMzODg0IA0KTCA1ODUuMjY5ODU2IC0yMDYuMDMzODg0IA0KTCA1ODUuMTEwMDIyIC0yMDYuMDMzODg0IA0KTCA1ODQuOTUwMTg4IC0yMDYuMDMzODg0IA0KTCA1ODQuNzkwMzU0IC0yMDYuMDMzODg0IA0KTCA1ODQuNjMwNTIgLTIwNi4wMzM4ODQgDQpMIDU4NC40NzA2ODYgLTIwNi4wMzM4ODQgDQpMIDU4NC4zMTA4NTIgLTIwNi4wMzM4ODQgDQpMIDU4NC4xNTEwMTggLTIwNi4wMzM4ODQgDQpMIDU4My45OTExODUgLTIwNi4wMzM4ODQgDQpMIDU4My44MzEzNTEgLTIwNi4wMzM4ODQgDQpMIDU4My42NzE1MTcgLTIwNi4wMzM4ODQgDQpMIDU4My41MTE2ODMgLTIwNi4wMzM4ODQgDQpMIDU4My4zNTE4NDkgLTIwNi4wMzM4ODQgDQpMIDU4My4xOTIwMTUgLTIwNi4wMzM4ODQgDQpMIDU4My4wMzIxODEgLTIwNi4wMzM4ODQgDQpMIDU4Mi44NzIzNDcgLTIwNi4wMzM4ODQgDQpMIDU4Mi43MTI1MTMgLTIwNi4wMzM4ODQgDQpMIDU4Mi41NTI2OCAtMjA2LjAzMzg4NCANCkwgNTgyLjM5Mjg0NiAtMjA2LjAzMzg4NCANCkwgNTgyLjIzMzAxMiAtMjA2LjAzMzg4NCANCkwgNTgyLjA3MzE3OCAtMjA2LjAzMzg4NCANCkwgNTgxLjkxMzM0NCAtMjA2LjAzMzg4NCANCkwgNTgxLjc1MzUxIC0yMDYuMDMzODg0IA0KTCA1ODEuNTkzNjc2IC0yMDYuMDMzODg0IA0KTCA1ODEuNDMzODQyIC0yMDYuMDMzODg0IA0KTCA1ODEuMjc0MDA4IC0yMDYuMDMzODg0IA0KTCA1ODEuMTE0MTc1IC0yMDYuMDMzODg0IA0KTCA1ODAuOTU0MzQxIC0yMDYuMDMzODg0IA0KTCA1ODAuNzk0NTA3IC0yMDYuMDMzODg0IA0KTCA1ODAuNjM0NjczIC0yMDYuMDMzODg0IA0KTCA1ODAuNDc0ODM5IC0yMDYuMDMzODg0IA0KTCA1ODAuMzE1MDA1IC0yMDYuMDMzODg0IA0KTCA1ODAuMTU1MTcxIC0yMDYuMDMzODg0IA0KTCA1NzkuOTk1MzM3IC0yMDYuMDMzODg0IA0KTCA1NzkuODM1NTA0IC0yMDYuMDMzODg0IA0KTCA1NzkuNjc1NjcgLTIwNi4wMzM4ODQgDQpMIDU3OS41MTU4MzYgLTIwNi4wMzM4ODQgDQpMIDU3OS4zNTYwMDIgLTIwNi4wMzM4ODQgDQpMIDU3OS4xOTYxNjggLTIwNi4wMzM4ODQgDQpMIDU3OS4wMzYzMzQgLTIwNi4wMzM4ODQgDQpMIDU3OC44NzY1IC0yMDYuMDMzODg0IA0KTCA1NzguNzE2NjY2IC0yMDYuMDMzODg0IA0KTCA1NzguNTU2ODMyIC0yMDYuMDMzODg0IA0KTCA1NzguMzk2OTk5IC0yMDYuMDMzODg0IA0KTCA1NzguMjM3MTY1IC0yMDYuMDMzODg0IA0KTCA1NzguMDc3MzMxIC0yMDYuMDMzODg0IA0KTCA1NzcuOTE3NDk3IC0yMDYuMDMzODg0IA0KTCA1NzcuNzU3NjYzIC0yMDYuMDMzODg0IA0KTCA1NzcuNTk3ODI5IC0yMDYuMDMzODg0IA0KTCA1NzcuNDM3OTk1IC0yMDYuMDMzODg0IA0KTCA1NzcuMjc4MTYxIC0yMDYuMDMzODg0IA0KTCA1NzcuMTE4MzI4IC0yMDYuMDMzODg0IA0KTCA1NzYuOTU4NDk0IC0yMDYuMDMzODg0IA0KTCA1NzYuNzk4NjYgLTIwNi4wMzM4ODQgDQpMIDU3Ni42Mzg4MjYgLTIwNi4wMzM4ODQgDQpMIDU3Ni40Nzg5OTIgLTIwNi4wMzM4ODQgDQpMIDU3Ni4zMTkxNTggLTIwNi4wMzM4ODQgDQpMIDU3Ni4xNTkzMjQgLTIwNi4wMzM4ODQgDQpMIDU3NS45OTk0OSAtMjA2LjAzMzg4NCANCkwgNTc1LjgzOTY1NiAtMjA2LjAzMzg4NCANCkwgNTc1LjY3OTgyMyAtMjA2LjAzMzg4NCANCkwgNTc1LjUxOTk4OSAtMjA2LjAzMzg4NCANCkwgNTc1LjM2MDE1NSAtMjA2LjAzMzg4NCANCkwgNTc1LjIwMDMyMSAtMjA2LjAzMzg4NCANCkwgNTc1LjA0MDQ4NyAtMjA2LjAzMzg4NCANCkwgNTc0Ljg4MDY1MyAtMjA2LjAzMzg4NCANCkwgNTc0LjcyMDgxOSAtMjA2LjAzMzg4NCANCkwgNTc0LjU2MDk4NSAtMjA2LjAzMzg4NCANCkwgNTc0LjQwMTE1MSAtMjA2LjAzMzg4NCANCkwgNTc0LjI0MTMxOCAtMjA2LjAzMzg4NCANCkwgNTc0LjA4MTQ4NCAtMjA2LjAzMzg4NCANCkwgNTczLjkyMTY1IC0yMDYuMDMzODg0IA0KTCA1NzMuNzYxODE2IC0yMDYuMDMzODg0IA0KTCA1NzMuNjAxOTgyIC0yMDYuMDMzODg0IA0KTCA1NzMuNDQyMTQ4IC0yMDYuMDMzODg0IA0KTCA1NzMuMjgyMzE0IC0yMDYuMDMzODg0IA0KTCA1NzMuMTIyNDggLTIwNi4wMzM4ODQgDQpMIDU3Mi45NjI2NDcgLTIwNi4wMzM4ODQgDQpMIDU3Mi44MDI4MTMgLTIwNi4wMzM4ODQgDQpMIDU3Mi42NDI5NzkgLTIwNi4wMzM4ODQgDQpMIDU3Mi40ODMxNDUgLTIwNi4wMzM4ODQgDQpMIDU3Mi4zMjMzMTEgLTIwNi4wMzM4ODQgDQpMIDU3Mi4xNjM0NzcgLTIwNi4wMzM4ODQgDQpMIDU3Mi4wMDM2NDMgLTIwNi4wMzM4ODQgDQpMIDU3MS44NDM4MDkgLTIwNi4wMzM4ODQgDQpMIDU3MS42ODM5NzUgLTIwNi4wMzM4ODQgDQpMIDU3MS41MjQxNDIgLTIwNi4wMzM4ODQgDQpMIDU3MS4zNjQzMDggLTIwNi4wMzM4ODQgDQpMIDU3MS4yMDQ0NzQgLTIwNi4wMzM4ODQgDQpMIDU3MS4wNDQ2NCAtMjA2LjAzMzg4NCANCkwgNTcwLjg4NDgwNiAtMjA2LjAzMzg4NCANCkwgNTcwLjcyNDk3MiAtMjA2LjAzMzg4NCANCkwgNTcwLjU2NTEzOCAtMjA2LjAzMzg4NCANCkwgNTcwLjQwNTMwNCAtMjA2LjAzMzg4NCANCkwgNTcwLjI0NTQ3MSAtMjA2LjAzMzg4NCANCkwgNTcwLjA4NTYzNyAtMjA2LjAzMzg4NCANCkwgNTY5LjkyNTgwMyAtMjA2LjAzMzg4NCANCkwgNTY5Ljc2NTk2OSAtMjA2LjAzMzg4NCANCkwgNTY5LjYwNjEzNSAtMjA2LjAzMzg4NCANCkwgNTY5LjQ0NjMwMSAtMjA2LjAzMzg4NCANCkwgNTY5LjI4NjQ2NyAtMjA2LjAzMzg4NCANCkwgNTY5LjEyNjYzMyAtMjA2LjAzMzg4NCANCkwgNTY4Ljk2Njc5OSAtMjA2LjAzMzg4NCANCkwgNTY4LjgwNjk2NiAtMjA2LjAzMzg4NCANCkwgNTY4LjY0NzEzMiAtMjA2LjAzMzg4NCANCkwgNTY4LjQ4NzI5OCAtMjA2LjAzMzg4NCANCkwgNTY4LjMyNzQ2NCAtMjA2LjAzMzg4NCANCkwgNTY4LjE2NzYzIC0yMDYuMDMzODg0IA0KTCA1NjguMDA3Nzk2IC0yMDYuMDMzODg0IA0KTCA1NjcuODQ3OTYyIC0yMDYuMDMzODg0IA0KTCA1NjcuNjg4MTI4IC0yMDYuMDMzODg0IA0KTCA1NjcuNTI4Mjk0IC0yMDYuMDMzODg0IA0KTCA1NjcuMzY4NDYxIC0yMDYuMDMzODg0IA0KTCA1NjcuMjA4NjI3IC0yMDYuMDMzODg0IA0KTCA1NjcuMDQ4NzkzIC0yMDYuMDMzODg0IA0KTCA1NjYuODg4OTU5IC0yMDYuMDMzODg0IA0KTCA1NjYuNzI5MTI1IC0yMDYuMDMzODg0IA0KTCA1NjYuNTY5MjkxIC0yMDYuMDMzODg0IA0KTCA1NjYuNDA5NDU3IC0yMDYuMDMzODg0IA0KTCA1NjYuMjQ5NjIzIC0yMDYuMDMzODg0IA0KTCA1NjYuMDg5NzkgLTIwNi4wMzM4ODQgDQpMIDU2NS45Mjk5NTYgLTIwNi4wMzM4ODQgDQpMIDU2NS43NzAxMjIgLTIwNi4wMzM4ODQgDQpMIDU2NS42MTAyODggLTIwNi4wMzM4ODQgDQpMIDU2NS40NTA0NTQgLTIwNi4wMzM4ODQgDQpMIDU2NS4yOTA2MiAtMjA2LjAzMzg4NCANCkwgNTY1LjEzMDc4NiAtMjA2LjAzMzg4NCANCkwgNTY0Ljk3MDk1MiAtMjA2LjAzMzg4NCANCkwgNTY0LjgxMTExOCAtMjA2LjAzMzg4NCANCkwgNTY0LjY1MTI4NSAtMjA2LjAzMzg4NCANCkwgNTY0LjQ5MTQ1MSAtMjA2LjAzMzg4NCANCkwgNTY0LjMzMTYxNyAtMjA2LjAzMzg4NCANCkwgNTY0LjE3MTc4MyAtMjA2LjAzMzg4NCANCkwgNTY0LjAxMTk0OSAtMjA2LjAzMzg4NCANCkwgNTYzLjg1MjExNSAtMjA2LjAzMzg4NCANCkwgNTYzLjY5MjI4MSAtMjA2LjAzMzg4NCANCkwgNTYzLjUzMjQ0NyAtMjA2LjAzMzg4NCANCkwgNTYzLjM3MjYxMyAtMjA2LjAzMzg4NCANCkwgNTYzLjIxMjc4IC0yMDYuMDMzODg0IA0KTCA1NjMuMDUyOTQ2IC0yMDYuMDMzODg0IA0KTCA1NjIuODkzMTEyIC0yMDYuMDMzODg0IA0KTCA1NjIuNzMzMjc4IC0yMDYuMDMzODg0IA0KTCA1NjIuNTczNDQ0IC0yMDYuMDMzODg0IA0KTCA1NjIuNDEzNjEgLTIwNi4wMzM4ODQgDQpMIDU2Mi4yNTM3NzYgLTIwNi4wMzM4ODQgDQpMIDU2Mi4wOTM5NDIgLTIwNi4wMzM4ODQgDQpMIDU2MS45MzQxMDkgLTIwNi4wMzM4ODQgDQpMIDU2MS43NzQyNzUgLTIwNi4wMzM4ODQgDQpMIDU2MS42MTQ0NDEgLTIwNi4wMzM4ODQgDQpMIDU2MS40NTQ2MDcgLTIwNi4wMzM4ODQgDQpMIDU2MS4yOTQ3NzMgLTIwNi4wMzM4ODQgDQpMIDU2MS4xMzQ5MzkgLTIwNi4wMzM4ODQgDQpMIDU2MC45NzUxMDUgLTIwNi4wMzM4ODQgDQpMIDU2MC44MTUyNzEgLTIwNi4wMzM4ODQgDQpMIDU2MC42NTU0MzcgLTIwNi4wMzM4ODQgDQpMIDU2MC40OTU2MDQgLTIwNi4wMzM4ODQgDQpMIDU2MC4zMzU3NyAtMjA2LjAzMzg4NCANCkwgNTYwLjE3NTkzNiAtMjA2LjAzMzg4NCANCkwgNTYwLjAxNjEwMiAtMjA2LjAzMzg4NCANCkwgNTU5Ljg1NjI2OCAtMjA2LjAzMzg4NCANCkwgNTU5LjY5NjQzNCAtMjA2LjAzMzg4NCANCkwgNTU5LjUzNjYgLTIwNi4wMzM4ODQgDQpMIDU1OS4zNzY3NjYgLTIwNi4wMzM4ODQgDQpMIDU1OS4yMTY5MzMgLTIwNi4wMzM4ODQgDQpMIDU1OS4wNTcwOTkgLTIwNi4wMzM4ODQgDQpMIDU1OC44OTcyNjUgLTIwNi4wMzM4ODQgDQpMIDU1OC43Mzc0MzEgLTIwNi4wMzM4ODQgDQpMIDU1OC41Nzc1OTcgLTIwNi4wMzM4ODQgDQpMIDU1OC40MTc3NjMgLTIwNi4wMzM4ODQgDQpMIDU1OC4yNTc5MjkgLTIwNi4wMzM4ODQgDQpMIDU1OC4wOTgwOTUgLTIwNi4wMzM4ODQgDQpMIDU1Ny45MzgyNjEgLTIwNi4wMzM4ODQgDQpMIDU1Ny43Nzg0MjggLTIwNi4wMzM4ODQgDQpMIDU1Ny42MTg1OTQgLTIwNi4wMzM4ODQgDQpMIDU1Ny40NTg3NiAtMjA2LjAzMzg4NCANCkwgNTU3LjI5ODkyNiAtMjA2LjAzMzg4NCANCkwgNTU3LjEzOTA5MiAtMjA2LjAzMzg4NCANCkwgNTU2Ljk3OTI1OCAtMjA2LjAzMzg4NCANCkwgNTU2LjgxOTQyNCAtMjA2LjAzMzg4NCANCkwgNTU2LjY1OTU5IC0yMDYuMDMzODg0IA0KTCA1NTYuNDk5NzU2IC0yMDYuMDMzODg0IA0KTCA1NTYuMzM5OTIzIC0yMDYuMDMzODg0IA0KTCA1NTYuMTgwMDg5IC0yMDYuMDMzODg0IA0KTCA1NTYuMDIwMjU1IC0yMDYuMDMzODg0IA0KTCA1NTUuODYwNDIxIC0yMDYuMDMzODg0IA0KTCA1NTUuNzAwNTg3IC0yMDYuMDMzODg0IA0KTCA1NTUuNTQwNzUzIC0yMDYuMDMzODg0IA0KTCA1NTUuMzgwOTE5IC0yMDYuMDMzODg0IA0KTCA1NTUuMjIxMDg1IC0yMDYuMDMzODg0IA0KTCA1NTUuMDYxMjUyIC0yMDYuMDMzODg0IA0KTCA1NTQuOTAxNDE4IC0yMDYuMDMzODg0IA0KTCA1NTQuNzQxNTg0IC0yMDYuMDMzODg0IA0KTCA1NTQuNTgxNzUgLTIwNi4wMzM4ODQgDQpMIDU1NC40MjE5MTYgLTIwNi4wMzM4ODQgDQpMIDU1NC4yNjIwODIgLTIwNi4wMzM4ODQgDQpMIDU1NC4xMDIyNDggLTIwNi4wMzM4ODQgDQpMIDU1My45NDI0MTQgLTIwNi4wMzM4ODQgDQpMIDU1My43ODI1OCAtMjA2LjAzMzg4NCANCkwgNTUzLjYyMjc0NyAtMjA2LjAzMzg4NCANCkwgNTUzLjQ2MjkxMyAtMjA2LjAzMzg4NCANCkwgNTUzLjMwMzA3OSAtMjA2LjAzMzg4NCANCkwgNTUzLjE0MzI0NSAtMjA2LjAzMzg4NCANCkwgNTUyLjk4MzQxMSAtMjA2LjAzMzg4NCANCkwgNTUyLjgyMzU3NyAtMjA2LjAzMzg4NCANCkwgNTUyLjY2Mzc0MyAtMjA2LjAzMzg4NCANCkwgNTUyLjUwMzkwOSAtMjA2LjAzMzg4NCANCkwgNTUyLjM0NDA3NiAtMjA2LjAzMzg4NCANCkwgNTUyLjE4NDI0MiAtMjA2LjAzMzg4NCANCkwgNTUyLjAyNDQwOCAtMjA2LjAzMzg4NCANCkwgNTUxLjg2NDU3NCAtMjA2LjAzMzg4NCANCkwgNTUxLjcwNDc0IC0yMDYuMDMzODg0IA0KTCA1NTEuNTQ0OTA2IC0yMDYuMDMzODg0IA0KTCA1NTEuMzg1MDcyIC0yMDYuMDMzODg0IA0KTCA1NTEuMjI1MjM4IC0yMDYuMDMzODg0IA0KTCA1NTEuMDY1NDA0IC0yMDYuMDMzODg0IA0KTCA1NTAuOTA1NTcxIC0yMDYuMDMzODg0IA0KTCA1NTAuNzQ1NzM3IC0yMDYuMDMzODg0IA0KTCA1NTAuNTg1OTAzIC0yMDYuMDMzODg0IA0KTCA1NTAuNDI2MDY5IC0yMDYuMDMzODg0IA0KTCA1NTAuMjY2MjM1IC0yMDYuMDMzODg0IA0KTCA1NTAuMTA2NDAxIC0yMDYuMDMzODg0IA0KTCA1NDkuOTQ2NTY3IC0yMDYuMDMzODg0IA0KTCA1NDkuNzg2NzMzIC0yMDYuMDMzODg0IA0KTCA1NDkuNjI2ODk5IC0yMDYuMDMzODg0IA0KTCA1NDkuNDY3MDY2IC0yMDYuMDMzODg0IA0KTCA1NDkuMzA3MjMyIC0yMDYuMDMzODg0IA0KTCA1NDkuMTQ3Mzk4IC0yMDYuMDMzODg0IA0KTCA1NDguOTg3NTY0IC0yMDYuMDMzODg0IA0KTCA1NDguODI3NzMgLTIwNi4wMzM4ODQgDQpMIDU0OC42Njc4OTYgLTIwNi4wMzM4ODQgDQpMIDU0OC41MDgwNjIgLTIwNi4wMzM4ODQgDQpMIDU0OC4zNDgyMjggLTIwNi4wMzM4ODQgDQpMIDU0OC4xODgzOTUgLTIwNi4wMzM4ODQgDQpMIDU0OC4wMjg1NjEgLTIwNi4wMzM4ODQgDQpMIDU0Ny44Njg3MjcgLTIwNi4wMzM4ODQgDQpMIDU0Ny43MDg4OTMgLTIwNi4wMzM4ODQgDQpMIDU0Ny41NDkwNTkgLTIwNi4wMzM4ODQgDQpMIDU0Ny4zODkyMjUgLTIwNi4wMzM4ODQgDQpMIDU0Ny4yMjkzOTEgLTIwNi4wMzM4ODQgDQpMIDU0Ny4wNjk1NTcgLTIwNi4wMzM4ODQgDQpMIDU0Ni45MDk3MjMgLTIwNi4wMzM4ODQgDQpMIDU0Ni43NDk4OSAtMjA2LjAzMzg4NCANCkwgNTQ2LjU5MDA1NiAtMjA2LjAzMzg4NCANCkwgNTQ2LjQzMDIyMiAtMjA2LjAzMzg4NCANCkwgNTQ2LjI3MDM4OCAtMjA2LjAzMzg4NCANCkwgNTQ2LjExMDU1NCAtMjA2LjAzMzg4NCANCkwgNTQ1Ljk1MDcyIC0yMDYuMDMzODg0IA0KTCA1NDUuNzkwODg2IC0yMDYuMDMzODg0IA0KTCA1NDUuNjMxMDUyIC0yMDYuMDMzODg0IA0KTCA1NDUuNDcxMjE4IC0yMDYuMDMzODg0IA0KTCA1NDUuMzExMzg1IC0yMDYuMDMzODg0IA0KTCA1NDUuMTUxNTUxIC0yMDYuMDMzODg0IA0KTCA1NDQuOTkxNzE3IC0yMDYuMDMzODg0IA0KTCA1NDQuODMxODgzIC0yMDYuMDMzODg0IA0KTCA1NDQuNjcyMDQ5IC0yMDYuMDMzODg0IA0KTCA1NDQuNTEyMjE1IC0yMDYuMDMzODg0IA0KTCA1NDQuMzUyMzgxIC0yMDYuMDMzODg0IA0KTCA1NDQuMTkyNTQ3IC0yMDYuMDMzODg0IA0KTCA1NDQuMDMyNzE0IC0yMDYuMDMzODg0IA0KTCA1NDMuODcyODggLTIwNi4wMzM4ODQgDQpMIDU0My43MTMwNDYgLTIwNi4wMzM4ODQgDQpMIDU0My41NTMyMTIgLTIwNi4wMzM4ODQgDQpMIDU0My4zOTMzNzggLTIwNi4wMzM4ODQgDQpMIDU0My4yMzM1NDQgLTIwNi4wMzM4ODQgDQpMIDU0My4wNzM3MSAtMjA2LjAzMzg4NCANCkwgNTQyLjkxMzg3NiAtMjA2LjAzMzg4NCANCkwgNTQyLjc1NDA0MiAtMjA2LjAzMzg4NCANCkwgNTQyLjU5NDIwOSAtMjA2LjAzMzg4NCANCkwgNTQyLjQzNDM3NSAtMjA2LjAzMzg4NCANCkwgNTQyLjI3NDU0MSAtMjA2LjAzMzg4NCANCkwgNTQyLjExNDcwNyAtMjA2LjAzMzg4NCANCkwgNTQxLjk1NDg3MyAtMjA2LjAzMzg4NCANCkwgNTQxLjc5NTAzOSAtMjA2LjAzMzg4NCANCkwgNTQxLjYzNTIwNSAtMjA2LjAzMzg4NCANCkwgNTQxLjQ3NTM3MSAtMjA2LjAzMzg4NCANCkwgNTQxLjMxNTUzOCAtMjA2LjAzMzg4NCANCkwgNTQxLjE1NTcwNCAtMjA2LjAzMzg4NCANCkwgNTQwLjk5NTg3IC0yMDYuMDMzODg0IA0KTCA1NDAuODM2MDM2IC0yMDYuMDMzODg0IA0KTCA1NDAuNjc2MjAyIC0yMDYuMDMzODg0IA0KTCA1NDAuNTE2MzY4IC0yMDYuMDMzODg0IA0KTCA1NDAuMzU2NTM0IC0yMDYuMDMzODg0IA0KTCA1NDAuMTk2NyAtMjA2LjAzMzg4NCANCkwgNTQwLjAzNjg2NiAtMjA2LjAzMzg4NCANCkwgNTM5Ljg3NzAzMyAtMjA2LjAzMzg4NCANCkwgNTM5LjcxNzE5OSAtMjA2LjAzMzg4NCANCkwgNTM5LjU1NzM2NSAtMjA2LjAzMzg4NCANCkwgNTM5LjM5NzUzMSAtMjA2LjAzMzg4NCANCkwgNTM5LjIzNzY5NyAtMjA2LjAzMzg4NCANCkwgNTM5LjA3Nzg2MyAtMjA2LjAzMzg4NCANCkwgNTM4LjkxODAyOSAtMjA2LjAzMzg4NCANCkwgNTM4Ljc1ODE5NSAtMjA2LjAzMzg4NCANCkwgNTM4LjU5ODM2MSAtMjA2LjAzMzg4NCANCkwgNTM4LjQzODUyOCAtMjA2LjAzMzg4NCANCkwgNTM4LjI3ODY5NCAtMjA2LjAzMzg4NCANCkwgNTM4LjExODg2IC0yMDYuMDMzODg0IA0KTCA1MzcuOTU5MDI2IC0yMDYuMDMzODg0IA0KTCA1MzcuNzk5MTkyIC0yMDYuMDMzODg0IA0KTCA1MzcuNjM5MzU4IC0yMDYuMDMzODg0IA0KTCA1MzcuNDc5NTI0IC0yMDYuMDMzODg0IA0KTCA1MzcuMzE5NjkgLTIwNi4wMzM4ODQgDQpMIDUzNy4xNTk4NTcgLTIwNi4wMzM4ODQgDQpMIDUzNy4wMDAwMjMgLTIwNi4wMzM4ODQgDQpMIDUzNi44NDAxODkgLTIwNi4wMzM4ODQgDQpMIDUzNi42ODAzNTUgLTIwNi4wMzM4ODQgDQpMIDUzNi41MjA1MjEgLTIwNi4wMzM4ODQgDQpMIDUzNi4zNjA2ODcgLTIwNi4wMzM4ODQgDQpMIDUzNi4yMDA4NTMgLTIwNi4wMzM4ODQgDQpMIDUzNi4wNDEwMTkgLTIwNi4wMzM4ODQgDQpMIDUzNS44ODExODUgLTIwNi4wMzM4ODQgDQpMIDUzNS43MjEzNTIgLTIwNi4wMzM4ODQgDQpMIDUzNS41NjE1MTggLTIwNi4wMzM4ODQgDQpMIDUzNS40MDE2ODQgLTIwNi4wMzM4ODQgDQpMIDUzNS4yNDE4NSAtMjA2LjAzMzg4NCANCkwgNTM1LjA4MjAxNiAtMjA2LjAzMzg4NCANCkwgNTM0LjkyMjE4MiAtMjA2LjAzMzg4NCANCkwgNTM0Ljc2MjM0OCAtMjA2LjAzMzg4NCANCkwgNTM0LjYwMjUxNCAtMjA2LjAzMzg4NCANCkwgNTM0LjQ0MjY4MSAtMjA2LjAzMzg4NCANCkwgNTM0LjI4Mjg0NyAtMjA2LjAzMzg4NCANCkwgNTM0LjEyMzAxMyAtMjA2LjAzMzg4NCANCkwgNTMzLjk2MzE3OSAtMjA2LjAzMzg4NCANCkwgNTMzLjgwMzM0NSAtMjA2LjAzMzg4NCANCkwgNTMzLjY0MzUxMSAtMjA2LjAzMzg4NCANCkwgNTMzLjQ4MzY3NyAtMjA2LjAzMzg4NCANCkwgNTMzLjMyMzg0MyAtMjA2LjAzMzg4NCANCkwgNTMzLjE2NDAwOSAtMjA2LjAzMzg4NCANCkwgNTMzLjAwNDE3NiAtMjA2LjAzMzg4NCANCkwgNTMyLjg0NDM0MiAtMjA2LjAzMzg4NCANCkwgNTMyLjY4NDUwOCAtMjA2LjAzMzg4NCANCkwgNTMyLjUyNDY3NCAtMjA2LjAzMzg4NCANCkwgNTMyLjM2NDg0IC0yMDYuMDMzODg0IA0KTCA1MzIuMjA1MDA2IC0yMDYuMDMzODg0IA0KTCA1MzIuMDQ1MTcyIC0yMDYuMDMzODg0IA0KTCA1MzEuODg1MzM4IC0yMDYuMDMzODg0IA0KTCA1MzEuNzI1NTA0IC0yMDYuMDMzODg0IA0KTCA1MzEuNTY1NjcxIC0yMDYuMDMzODg0IA0KTCA1MzEuNDA1ODM3IC0yMDYuMDMzODg0IA0KTCA1MzEuMjQ2MDAzIC0yMDYuMDMzODg0IA0KTCA1MzEuMDg2MTY5IC0yMDYuMDMzODg0IA0KTCA1MzAuOTI2MzM1IC0yMDYuMDMzODg0IA0KTCA1MzAuNzY2NTAxIC0yMDYuMDMzODg0IA0KTCA1MzAuNjA2NjY3IC0yMDYuMDMzODg0IA0KTCA1MzAuNDQ2ODMzIC0yMDYuMDMzODg0IA0KTCA1MzAuMjg3IC0yMDYuMDMzODg0IA0KTCA1MzAuMTI3MTY2IC0yMDYuMDMzODg0IA0KTCA1MjkuOTY3MzMyIC0yMDYuMDMzODg0IA0KTCA1MjkuODA3NDk4IC0yMDYuMDMzODg0IA0KTCA1MjkuNjQ3NjY0IC0yMDYuMDMzODg0IA0KTCA1MjkuNDg3ODMgLTIwNi4wMzM4ODQgDQpMIDUyOS4zMjc5OTYgLTIwNi4wMzM4ODQgDQpMIDUyOS4xNjgxNjIgLTIwNi4wMzM4ODQgDQpMIDUyOS4wMDgzMjggLTIwNi4wMzM4ODQgDQpMIDUyOC44NDg0OTUgLTIwNi4wMzM4ODQgDQpMIDUyOC42ODg2NjEgLTIwNi4wMzM4ODQgDQpMIDUyOC41Mjg4MjcgLTIwNi4wMzM4ODQgDQpMIDUyOC4zNjg5OTMgLTIwNi4wMzM4ODQgDQpMIDUyOC4yMDkxNTkgLTIwNi4wMzM4ODQgDQpMIDUyOC4wNDkzMjUgLTIwNi4wMzM4ODQgDQpMIDUyNy44ODk0OTEgLTIwNi4wMzM4ODQgDQpMIDUyNy43Mjk2NTcgLTIwNi4wMzM4ODQgDQpMIDUyNy41Njk4MjQgLTIwNi4wMzM4ODQgDQpMIDUyNy40MDk5OSAtMjA2LjAzMzg4NCANCkwgNTI3LjI1MDE1NiAtMjA2LjAzMzg4NCANCkwgNTI3LjA5MDMyMiAtMjA2LjAzMzg4NCANCkwgNTI2LjkzMDQ4OCAtMjA2LjAzMzg4NCANCkwgNTI2Ljc3MDY1NCAtMjA2LjAzMzg4NCANCkwgNTI2LjYxMDgyIC0yMDYuMDMzODg0IA0KTCA1MjYuNDUwOTg2IC0yMDYuMDMzODg0IA0KTCA1MjYuMjkxMTUyIC0yMDYuMDMzODg0IA0KTCA1MjYuMTMxMzE5IC0yMDYuMDMzODg0IA0KTCA1MjUuOTcxNDg1IC0yMDYuMDMzODg0IA0KTCA1MjUuODExNjUxIC0yMDYuMDMzODg0IA0KTCA1MjUuNjUxODE3IC0yMDYuMDMzODg0IA0KTCA1MjUuNDkxOTgzIC0yMDYuMDMzODg0IA0KTCA1MjUuMzMyMTQ5IC0yMDYuMDMzODg0IA0KTCA1MjUuMTcyMzE1IC0yMDYuMDMzODg0IA0KTCA1MjUuMDEyNDgxIC0yMDYuMDMzODg0IA0KTCA1MjQuODUyNjQ3IC0yMDYuMDMzODg0IA0KTCA1MjQuNjkyODE0IC0yMDYuMDMzODg0IA0KTCA1MjQuNTMyOTggLTIwNi4wMzM4ODQgDQpMIDUyNC4zNzMxNDYgLTIwNi4wMzM4ODQgDQpMIDUyNC4yMTMzMTIgLTIwNi4wMzM4ODQgDQpMIDUyNC4wNTM0NzggLTIwNi4wMzM4ODQgDQpMIDUyMy44OTM2NDQgLTIwNi4wMzM4ODQgDQpMIDUyMy43MzM4MSAtMjA2LjAzMzg4NCANCkwgNTIzLjU3Mzk3NiAtMjA2LjAzMzg4NCANCkwgNTIzLjQxNDE0MyAtMjA2LjAzMzg4NCANCkwgNTIzLjI1NDMwOSAtMjA2LjAzMzg4NCANCkwgNTIzLjA5NDQ3NSAtMjA2LjAzMzg4NCANCkwgNTIyLjkzNDY0MSAtMjA2LjAzMzg4NCANCkwgNTIyLjc3NDgwNyAtMjA2LjAzMzg4NCANCkwgNTIyLjYxNDk3MyAtMjA2LjAzMzg4NCANCkwgNTIyLjQ1NTEzOSAtMjA2LjAzMzg4NCANCkwgNTIyLjI5NTMwNSAtMjA2LjAzMzg4NCANCkwgNTIyLjEzNTQ3MSAtMjA2LjAzMzg4NCANCkwgNTIxLjk3NTYzOCAtMjA2LjAzMzg4NCANCkwgNTIxLjgxNTgwNCAtMjA2LjAzMzg4NCANCkwgNTIxLjY1NTk3IC0yMDYuMDMzODg0IA0KTCA1MjEuNDk2MTM2IC0yMDYuMDMzODg0IA0KTCA1MjEuMzM2MzAyIC0yMDYuMDMzODg0IA0KTCA1MjEuMTc2NDY4IC0yMDYuMDMzODg0IA0KTCA1MjEuMDE2NjM0IC0yMDYuMDMzODg0IA0KTCA1MjAuODU2OCAtMjA2LjAzMzg4NCANCkwgNTIwLjY5Njk2NiAtMjA2LjAzMzg4NCANCkwgNTIwLjUzNzEzMyAtMjA2LjAzMzg4NCANCkwgNTIwLjM3NzI5OSAtMjA2LjAzMzg4NCANCkwgNTIwLjIxNzQ2NSAtMjA2LjAzMzg4NCANCkwgNTIwLjA1NzYzMSAtMjA2LjAzMzg4NCANCkwgNTE5Ljg5Nzc5NyAtMjA2LjAzMzg4NCANCkwgNTE5LjczNzk2MyAtMjA2LjAzMzg4NCANCkwgNTE5LjU3ODEyOSAtMjA2LjAzMzg4NCANCkwgNTE5LjQxODI5NSAtMjA2LjAzMzg4NCANCkwgNTE5LjI1ODQ2MiAtMjA2LjAzMzg4NCANCkwgNTE5LjA5ODYyOCAtMjA2LjAzMzg4NCANCkwgNTE4LjkzODc5NCAtMjA2LjAzMzg4NCANCkwgNTE4Ljc3ODk2IC0yMDYuMDMzODg0IA0KTCA1MTguNjE5MTI2IC0yMDYuMDMzODg0IA0KTCA1MTguNDU5MjkyIC0yMDYuMDMzODg0IA0KTCA1MTguMjk5NDU4IC0yMDYuMDMzODg0IA0KTCA1MTguMTM5NjI0IC0yMDYuMDMzODg0IA0KTCA1MTcuOTc5NzkgLTIwNi4wMzM4ODQgDQpMIDUxNy44MTk5NTcgLTIwNi4wMzM4ODQgDQpMIDUxNy42NjAxMjMgLTIwNi4wMzM4ODQgDQpMIDUxNy41MDAyODkgLTIwNi4wMzM4ODQgDQpMIDUxNy4zNDA0NTUgLTIwNi4wMzM4ODQgDQpMIDUxNy4xODA2MjEgLTIwNi4wMzM4ODQgDQpMIDUxNy4wMjA3ODcgLTIwNi4wMzM4ODQgDQpMIDUxNi44NjA5NTMgLTIwNi4wMzM4ODQgDQpMIDUxNi43MDExMTkgLTIwNi4wMzM4ODQgDQpMIDUxNi41NDEyODYgLTIwNi4wMzM4ODQgDQpMIDUxNi4zODE0NTIgLTIwNi4wMzM4ODQgDQpMIDUxNi4yMjE2MTggLTIwNi4wMzM4ODQgDQpMIDUxNi4wNjE3ODQgLTIwNi4wMzM4ODQgDQpMIDUxNS45MDE5NSAtMjA2LjAzMzg4NCANCkwgNTE1Ljc0MjExNiAtMjA2LjAzMzg4NCANCkwgNTE1LjU4MjI4MiAtMjA2LjAzMzg4NCANCkwgNTE1LjQyMjQ0OCAtMjA2LjAzMzg4NCANCkwgNTE1LjI2MjYxNCAtMjA2LjAzMzg4NCANCkwgNTE1LjEwMjc4MSAtMjA2LjAzMzg4NCANCkwgNTE0Ljk0Mjk0NyAtMjA2LjAzMzg4NCANCkwgNTE0Ljc4MzExMyAtMjA2LjAzMzg4NCANCkwgNTE0LjYyMzI3OSAtMjA2LjAzMzg4NCANCkwgNTE0LjQ2MzQ0NSAtMjA2LjAzMzg4NCANCkwgNTE0LjMwMzYxMSAtMjA2LjAzMzg4NCANCkwgNTE0LjE0Mzc3NyAtMjA2LjAzMzg4NCANCkwgNTEzLjk4Mzk0MyAtMjA2LjAzMzg4NCANCkwgNTEzLjgyNDEwOSAtMjA2LjAzMzg4NCANCkwgNTEzLjY2NDI3NiAtMjA2LjAzMzg4NCANCkwgNTEzLjUwNDQ0MiAtMjA2LjAzMzg4NCANCkwgNTEzLjM0NDYwOCAtMjA2LjAzMzg4NCANCkwgNTEzLjE4NDc3NCAtMjA2LjAzMzg4NCANCkwgNTEzLjAyNDk0IC0yMDYuMDMzODg0IA0KTCA1MTIuODY1MTA2IC0yMDYuMDMzODg0IA0KTCA1MTIuNzA1MjcyIC0yMDYuMDMzODg0IA0KTCA1MTIuNTQ1NDM4IC0yMDYuMDMzODg0IA0KTCA1MTIuMzg1NjA1IC0yMDYuMDMzODg0IA0KTCA1MTIuMjI1NzcxIC0yMDYuMDMzODg0IA0KTCA1MTIuMDY1OTM3IC0yMDYuMDMzODg0IA0KTCA1MTEuOTA2MTAzIC0yMDYuMDMzODg0IA0KTCA1MTEuNzQ2MjY5IC0yMDYuMDMzODg0IA0KTCA1MTEuNTg2NDM1IC0yMDYuMDMzODg0IA0KTCA1MTEuNDI2NjAxIC0yMDYuMDMzODg0IA0KTCA1MTEuMjY2NzY3IC0yMDYuMDMzODg0IA0KTCA1MTEuMTA2OTMzIC0yMDYuMDMzODg0IA0KTCA1MTAuOTQ3MSAtMjA2LjAzMzg4NCANCkwgNTEwLjc4NzI2NiAtMjA2LjAzMzg4NCANCkwgNTEwLjYyNzQzMiAtMjA2LjAzMzg4NCANCkwgNTEwLjQ2NzU5OCAtMjA2LjAzMzg4NCANCkwgNTEwLjMwNzc2NCAtMjA2LjAzMzg4NCANCkwgNTEwLjE0NzkzIC0yMDYuMDMzODg0IA0KTCA1MDkuOTg4MDk2IC0yMDYuMDMzODg0IA0KTCA1MDkuODI4MjYyIC0yMDYuMDMzODg0IA0KTCA1MDkuNjY4NDI5IC0yMDYuMDMzODg0IA0KTCA1MDkuNTA4NTk1IC0yMDYuMDMzODg0IA0KTCA1MDkuMzQ4NzYxIC0yMDYuMDMzODg0IA0KTCA1MDkuMTg4OTI3IC0yMDYuMDMzODg0IA0KTCA1MDkuMDI5MDkzIC0yMDYuMDMzODg0IA0KTCA1MDguODY5MjU5IC0yMDYuMDMzODg0IA0KTCA1MDguNzA5NDI1IC0yMDYuMDMzODg0IA0KTCA1MDguNTQ5NTkxIC0yMDYuMDMzODg0IA0KTCA1MDguMzg5NzU3IC0yMDYuMDMzODg0IA0KTCA1MDguMjI5OTI0IC0yMDYuMDMzODg0IA0KTCA1MDguMDcwMDkgLTIwNi4wMzM4ODQgDQpMIDUwNy45MTAyNTYgLTIwNi4wMzM4ODQgDQpMIDUwNy43NTA0MjIgLTIwNi4wMzM4ODQgDQpMIDUwNy41OTA1ODggLTIwNi4wMzM4ODQgDQpMIDUwNy40MzA3NTQgLTIwNi4wMzM4ODQgDQpMIDUwNy4yNzA5MiAtMjA2LjAzMzg4NCANCkwgNTA3LjExMTA4NiAtMjA2LjAzMzg4NCANCkwgNTA2Ljk1MTI1MiAtMjA2LjAzMzg4NCANCkwgNTA2Ljc5MTQxOSAtMjA2LjAzMzg4NCANCkwgNTA2LjYzMTU4NSAtMjA2LjAzMzg4NCANCkwgNTA2LjQ3MTc1MSAtMjA2LjAzMzg4NCANCkwgNTA2LjMxMTkxNyAtMjA2LjAzMzg4NCANCkwgNTA2LjE1MjA4MyAtMjA2LjAzMzg4NCANCkwgNTA1Ljk5MjI0OSAtMjA2LjAzMzg4NCANCkwgNTA1LjgzMjQxNSAtMjA2LjAzMzg4NCANCkwgNTA1LjY3MjU4MSAtMjA2LjAzMzg4NCANCkwgNTA1LjUxMjc0OCAtMjA2LjAzMzg4NCANCkwgNTA1LjM1MjkxNCAtMjA2LjAzMzg4NCANCkwgNTA1LjE5MzA4IC0yMDYuMDMzODg0IA0KTCA1MDUuMDMzMjQ2IC0yMDYuMDMzODg0IA0KTCA1MDQuODczNDEyIC0yMDYuMDMzODg0IA0KTCA1MDQuNzEzNTc4IC0yMDYuMDMzODg0IA0KTCA1MDQuNTUzNzQ0IC0yMDYuMDMzODg0IA0KTCA1MDQuMzkzOTEgLTIwNi4wMzM4ODQgDQpMIDUwNC4yMzQwNzYgLTIwNi4wMzM4ODQgDQpMIDUwNC4wNzQyNDMgLTIwNi4wMzM4ODQgDQpMIDUwMy45MTQ0MDkgLTIwNi4wMzM4ODQgDQpMIDUwMy43NTQ1NzUgLTIwNi4wMzM4ODQgDQpMIDUwMy41OTQ3NDEgLTIwNi4wMzM4ODQgDQpMIDUwMy40MzQ5MDcgLTIwNi4wMzM4ODQgDQpMIDUwMy4yNzUwNzMgLTIwNi4wMzM4ODQgDQpMIDUwMy4xMTUyMzkgLTIwNi4wMzM4ODQgDQpMIDUwMi45NTU0MDUgLTIwNi4wMzM4ODQgDQpMIDUwMi43OTU1NzEgLTIwNi4wMzM4ODQgDQpMIDUwMi42MzU3MzggLTIwNi4wMzM4ODQgDQpMIDUwMi40NzU5MDQgLTIwNi4wMzM4ODQgDQpMIDUwMi4zMTYwNyAtMjA2LjAzMzg4NCANCkwgNTAyLjE1NjIzNiAtMjA2LjAzMzg4NCANCkwgNTAxLjk5NjQwMiAtMjA2LjAzMzg4NCANCkwgNTAxLjgzNjU2OCAtMjA2LjAzMzg4NCANCkwgNTAxLjY3NjczNCAtMjA2LjAzMzg4NCANCkwgNTAxLjUxNjkgLTIwNi4wMzM4ODQgDQpMIDUwMS4zNTcwNjcgLTIwNi4wMzM4ODQgDQpMIDUwMS4xOTcyMzMgLTIwNi4wMzM4ODQgDQpMIDUwMS4wMzczOTkgLTIwNi4wMzM4ODQgDQpMIDUwMC44Nzc1NjUgLTIwNi4wMzM4ODQgDQpMIDUwMC43MTc3MzEgLTIwNi4wMzM4ODQgDQpMIDUwMC41NTc4OTcgLTIwNi4wMzM4ODQgDQpMIDUwMC4zOTgwNjMgLTIwNi4wMzM4ODQgDQpMIDUwMC4yMzgyMjkgLTIwNi4wMzM4ODQgDQpMIDUwMC4wNzgzOTUgLTIwNi4wMzM4ODQgDQpMIDQ5OS45MTg1NjIgLTIwNi4wMzM4ODQgDQpMIDQ5OS43NTg3MjggLTIwNi4wMzM4ODQgDQpMIDQ5OS41OTg4OTQgLTIwNi4wMzM4ODQgDQpMIDQ5OS40MzkwNiAtMjA2LjAzMzg4NCANCkwgNDk5LjI3OTIyNiAtMjA2LjAzMzg4NCANCkwgNDk5LjExOTM5MiAtMjA2LjAzMzg4NCANCkwgNDk4Ljk1OTU1OCAtMjA2LjAzMzg4NCANCkwgNDk4Ljc5OTcyNCAtMjA2LjAzMzg4NCANCkwgNDk4LjYzOTg5MSAtMjA2LjAzMzg4NCANCkwgNDk4LjQ4MDA1NyAtMjA2LjAzMzg4NCANCkwgNDk4LjMyMDIyMyAtMjA2LjAzMzg4NCANCkwgNDk4LjE2MDM4OSAtMjA2LjAzMzg4NCANCkwgNDk4LjAwMDU1NSAtMjA2LjAzMzg4NCANCkwgNDk3Ljg0MDcyMSAtMjA2LjAzMzg4NCANCkwgNDk3LjY4MDg4NyAtMjA2LjAzMzg4NCANCkwgNDk3LjUyMTA1MyAtMjA2LjAzMzg4NCANCkwgNDk3LjM2MTIxOSAtMjA2LjAzMzg4NCANCkwgNDk3LjIwMTM4NiAtMjA2LjAzMzg4NCANCkwgNDk3LjA0MTU1MiAtMjA2LjAzMzg4NCANCkwgNDk2Ljg4MTcxOCAtMjA2LjAzMzg4NCANCkwgNDk2LjcyMTg4NCAtMjA2LjAzMzg4NCANCkwgNDk2LjU2MjA1IC0yMDYuMDMzODg0IA0KTCA0OTYuNDAyMjE2IC0yMDYuMDMzODg0IA0KTCA0OTYuMjQyMzgyIC0yMDYuMDMzODg0IA0KTCA0OTYuMDgyNTQ4IC0yMDYuMDMzODg0IA0KTCA0OTUuOTIyNzE0IC0yMDYuMDMzODg0IA0KTCA0OTUuNzYyODgxIC0yMDYuMDMzODg0IA0KTCA0OTUuNjAzMDQ3IC0yMDYuMDMzODg0IA0KTCA0OTUuNDQzMjEzIC0yMDYuMDMzODg0IA0KTCA0OTUuMjgzMzc5IC0yMDYuMDMzODg0IA0KTCA0OTUuMTIzNTQ1IC0yMDYuMDMzODg0IA0KTCA0OTQuOTYzNzExIC0yMDYuMDMzODg0IA0KTCA0OTQuODAzODc3IC0yMDYuMDMzODg0IA0KTCA0OTQuNjQ0MDQzIC0yMDYuMDMzODg0IA0KTCA0OTQuNDg0MjEgLTIwNi4wMzM4ODQgDQpMIDQ5NC4zMjQzNzYgLTIwNi4wMzM4ODQgDQpMIDQ5NC4xNjQ1NDIgLTIwNi4wMzM4ODQgDQpMIDQ5NC4wMDQ3MDggLTIwNi4wMzM4ODQgDQpMIDQ5My44NDQ4NzQgLTIwNi4wMzM4ODQgDQpMIDQ5My42ODUwNCAtMjA2LjAzMzg4NCANCkwgNDkzLjUyNTIwNiAtMjA2LjAzMzg4NCANCkwgNDkzLjM2NTM3MiAtMjA2LjAzMzg4NCANCkwgNDkzLjIwNTUzOCAtMjA2LjAzMzg4NCANCkwgNDkzLjA0NTcwNSAtMjA2LjAzMzg4NCANCkwgNDkyLjg4NTg3MSAtMjA2LjAzMzg4NCANCkwgNDkyLjcyNjAzNyAtMjA2LjAzMzg4NCANCkwgNDkyLjU2NjIwMyAtMjA2LjAzMzg4NCANCkwgNDkyLjQwNjM2OSAtMjA2LjAzMzg4NCANCkwgNDkyLjI0NjUzNSAtMjA2LjAzMzg4NCANCkwgNDkyLjA4NjcwMSAtMjA2LjAzMzg4NCANCkwgNDkxLjkyNjg2NyAtMjA2LjAzMzg4NCANCkwgNDkxLjc2NzAzNCAtMjA2LjAzMzg4NCANCkwgNDkxLjYwNzIgLTIwNi4wMzM4ODQgDQpMIDQ5MS40NDczNjYgLTIwNi4wMzM4ODQgDQpMIDQ5MS4yODc1MzIgLTIwNi4wMzM4ODQgDQpMIDQ5MS4xMjc2OTggLTIwNi4wMzM4ODQgDQpMIDQ5MC45Njc4NjQgLTIwNi4wMzM4ODQgDQpMIDQ5MC44MDgwMyAtMjA2LjAzMzg4NCANCkwgNDkwLjY0ODE5NiAtMjA2LjAzMzg4NCANCkwgNDkwLjQ4ODM2MiAtMjA2LjAzMzg4NCANCkwgNDkwLjMyODUyOSAtMjA2LjAzMzg4NCANCkwgNDkwLjE2ODY5NSAtMjA2LjAzMzg4NCANCkwgNDkwLjAwODg2MSAtMjA2LjAzMzg4NCANCkwgNDg5Ljg0OTAyNyAtMjA2LjAzMzg4NCANCkwgNDg5LjY4OTE5MyAtMjA2LjAzMzg4NCANCkwgNDg5LjUyOTM1OSAtMjA2LjAzMzg4NCANCkwgNDg5LjM2OTUyNSAtMjA2LjAzMzg4NCANCkwgNDg5LjIwOTY5MSAtMjA2LjAzMzg4NCANCkwgNDg5LjA0OTg1NyAtMjA2LjAzMzg4NCANCkwgNDg4Ljg5MDAyNCAtMjA2LjAzMzg4NCANCkwgNDg4LjczMDE5IC0yMDYuMDMzODg0IA0KTCA0ODguNTcwMzU2IC0yMDYuMDMzODg0IA0KTCA0ODguNDEwNTIyIC0yMDYuMDMzODg0IA0KTCA0ODguMjUwNjg4IC0yMDYuMDMzODg0IA0KTCA0ODguMDkwODU0IC0yMDYuMDMzODg0IA0KTCA0ODcuOTMxMDIgLTIwNi4wMzM4ODQgDQpMIDQ4Ny43NzExODYgLTIwNi4wMzM4ODQgDQpMIDQ4Ny42MTEzNTMgLTIwNi4wMzM4ODQgDQpMIDQ4Ny40NTE1MTkgLTIwNi4wMzM4ODQgDQpMIDQ4Ny4yOTE2ODUgLTIwNi4wMzM4ODQgDQpMIDQ4Ny4xMzE4NTEgLTIwNi4wMzM4ODQgDQpMIDQ4Ni45NzIwMTcgLTIwNi4wMzM4ODQgDQpMIDQ4Ni44MTIxODMgLTIwNi4wMzM4ODQgDQpMIDQ4Ni42NTIzNDkgLTIwNi4wMzM4ODQgDQpMIDQ4Ni40OTI1MTUgLTIwNi4wMzM4ODQgDQpMIDQ4Ni4zMzI2ODEgLTIwNi4wMzM4ODQgDQpMIDQ4Ni4xNzI4NDggLTIwNi4wMzM4ODQgDQpMIDQ4Ni4wMTMwMTQgLTIwNi4wMzM4ODQgDQpMIDQ4NS44NTMxOCAtMjA2LjAzMzg4NCANCkwgNDg1LjY5MzM0NiAtMjA2LjAzMzg4NCANCkwgNDg1LjUzMzUxMiAtMjA2LjAzMzg4NCANCkwgNDg1LjM3MzY3OCAtMjA2LjAzMzg4NCANCkwgNDg1LjIxMzg0NCAtMjA2LjAzMzg4NCANCkwgNDg1LjA1NDAxIC0yMDYuMDMzODg0IA0KTCA0ODQuODk0MTc2IC0yMDYuMDMzODg0IA0KTCA0ODQuNzM0MzQzIC0yMDYuMDMzODg0IA0KTCA0ODQuNTc0NTA5IC0yMDYuMDMzODg0IA0KTCA0ODQuNDE0Njc1IC0yMDYuMDMzODg0IA0KTCA0ODQuMjU0ODQxIC0yMDYuMDMzODg0IA0KTCA0ODQuMDk1MDA3IC0yMDYuMDMzODg0IA0KTCA0ODMuOTM1MTczIC0yMDYuMDMzODg0IA0KTCA0ODMuNzc1MzM5IC0yMDYuMDMzODg0IA0KTCA0ODMuNjE1NTA1IC0yMDYuMDMzODg0IA0KTCA0ODMuNDU1NjcyIC0yMDYuMDMzODg0IA0KTCA0ODMuMjk1ODM4IC0yMDYuMDMzODg0IA0KTCA0ODMuMTM2MDA0IC0yMDYuMDMzODg0IA0KTCA0ODIuOTc2MTcgLTIwNi4wMzM4ODQgDQpMIDQ4Mi44MTYzMzYgLTIwNi4wMzM4ODQgDQpMIDQ4Mi42NTY1MDIgLTIwNi4wMzM4ODQgDQpMIDQ4Mi40OTY2NjggLTIwNi4wMzM4ODQgDQpMIDQ4Mi4zMzY4MzQgLTIwNi4wMzM4ODQgDQpMIDQ4Mi4xNzcgLTIwNi4wMzM4ODQgDQpMIDQ4Mi4wMTcxNjcgLTIwNi4wMzM4ODQgDQpMIDQ4MS44NTczMzMgLTIwNi4wMzM4ODQgDQpMIDQ4MS42OTc0OTkgLTIwNi4wMzM4ODQgDQpMIDQ4MS41Mzc2NjUgLTIwNi4wMzM4ODQgDQpMIDQ4MS4zNzc4MzEgLTIwNi4wMzM4ODQgDQpMIDQ4MS4yMTc5OTcgLTIwNi4wMzM4ODQgDQpMIDQ4MS4wNTgxNjMgLTIwNi4wMzM4ODQgDQpMIDQ4MC44OTgzMjkgLTIwNi4wMzM4ODQgDQpMIDQ4MC43Mzg0OTYgLTIwNi4wMzM4ODQgDQpMIDQ4MC41Nzg2NjIgLTIwNi4wMzM4ODQgDQpMIDQ4MC40MTg4MjggLTIwNi4wMzM4ODQgDQpMIDQ4MC4yNTg5OTQgLTIwNi4wMzM4ODQgDQpMIDQ4MC4wOTkxNiAtMjA2LjAzMzg4NCANCkwgNDc5LjkzOTMyNiAtMjA2LjAzMzg4NCANCkwgNDc5Ljc3OTQ5MiAtMjA2LjAzMzg4NCANCkwgNDc5LjYxOTY1OCAtMjA2LjAzMzg4NCANCkwgNDc5LjQ1OTgyNCAtMjA2LjAzMzg4NCANCkwgNDc5LjI5OTk5MSAtMjA2LjAzMzg4NCANCkwgNDc5LjE0MDE1NyAtMjA2LjAzMzg4NCANCkwgNDc4Ljk4MDMyMyAtMjA2LjAzMzg4NCANCkwgNDc4LjgyMDQ4OSAtMjA2LjAzMzg4NCANCkwgNDc4LjY2MDY1NSAtMjA2LjAzMzg4NCANCkwgNDc4LjUwMDgyMSAtMjA2LjAzMzg4NCANCkwgNDc4LjM0MDk4NyAtMjA2LjAzMzg4NCANCkwgNDc4LjE4MTE1MyAtMjA2LjAzMzg4NCANCkwgNDc4LjAyMTMxOSAtMjA2LjAzMzg4NCANCkwgNDc3Ljg2MTQ4NiAtMjA2LjAzMzg4NCANCkwgNDc3LjcwMTY1MiAtMjA2LjAzMzg4NCANCkwgNDc3LjU0MTgxOCAtMjA2LjAzMzg4NCANCkwgNDc3LjM4MTk4NCAtMjA2LjAzMzg4NCANCkwgNDc3LjIyMjE1IC0yMDYuMDMzODg0IA0KTCA0NzcuMDYyMzE2IC0yMDYuMDMzODg0IA0KTCA0NzYuOTAyNDgyIC0yMDYuMDMzODg0IA0KTCA0NzYuNzQyNjQ4IC0yMDYuMDMzODg0IA0KTCA0NzYuNTgyODE1IC0yMDYuMDMzODg0IA0KTCA0NzYuNDIyOTgxIC0yMDYuMDMzODg0IA0KTCA0NzYuMjYzMTQ3IC0yMDYuMDMzODg0IA0KTCA0NzYuMTAzMzEzIC0yMDYuMDMzODg0IA0KTCA0NzUuOTQzNDc5IC0yMDYuMDMzODg0IA0KTCA0NzUuNzgzNjQ1IC0yMDYuMDMzODg0IA0KTCA0NzUuNjIzODExIC0yMDYuMDMzODg0IA0KTCA0NzUuNDYzOTc3IC0yMDYuMDMzODg0IA0KTCA0NzUuMzA0MTQzIC0yMDYuMDMzODg0IA0KTCA0NzUuMTQ0MzEgLTIwNi4wMzM4ODQgDQpMIDQ3NC45ODQ0NzYgLTIwNi4wMzM4ODQgDQpMIDQ3NC44MjQ2NDIgLTIwNi4wMzM4ODQgDQpMIDQ3NC42NjQ4MDggLTIwNi4wMzM4ODQgDQpMIDQ3NC41MDQ5NzQgLTIwNi4wMzM4ODQgDQpMIDQ3NC4zNDUxNCAtMjA2LjAzMzg4NCANCkwgNDc0LjE4NTMwNiAtMjA2LjAzMzg4NCANCkwgNDc0LjAyNTQ3MiAtMjA2LjAzMzg4NCANCkwgNDczLjg2NTYzOSAtMjA2LjAzMzg4NCANCkwgNDczLjcwNTgwNSAtMjA2LjAzMzg4NCANCkwgNDczLjU0NTk3MSAtMjA2LjAzMzg4NCANCkwgNDczLjM4NjEzNyAtMjA2LjAzMzg4NCANCkwgNDczLjIyNjMwMyAtMjA2LjAzMzg4NCANCkwgNDczLjA2NjQ2OSAtMjA2LjAzMzg4NCANCkwgNDcyLjkwNjYzNSAtMjA2LjAzMzg4NCANCkwgNDcyLjc0NjgwMSAtMjA2LjAzMzg4NCANCkwgNDcyLjU4Njk2NyAtMjA2LjAzMzg4NCANCkwgNDcyLjQyNzEzNCAtMjA2LjAzMzg4NCANCkwgNDcyLjI2NzMgLTIwNi4wMzM4ODQgDQpMIDQ3Mi4xMDc0NjYgLTIwNi4wMzM4ODQgDQpMIDQ3MS45NDc2MzIgLTIwNi4wMzM4ODQgDQpMIDQ3MS43ODc3OTggLTIwNi4wMzM4ODQgDQpMIDQ3MS42Mjc5NjQgLTIwNi4wMzM4ODQgDQpMIDQ3MS40NjgxMyAtMjA2LjAzMzg4NCANCkwgNDcxLjMwODI5NiAtMjA2LjAzMzg4NCANCkwgNDcxLjE0ODQ2MiAtMjA2LjAzMzg4NCANCkwgNDcwLjk4ODYyOSAtMjA2LjAzMzg4NCANCkwgNDcwLjgyODc5NSAtMjA2LjAzMzg4NCANCkwgNDcwLjY2ODk2MSAtMjA2LjAzMzg4NCANCkwgNDcwLjUwOTEyNyAtMjA2LjAzMzg4NCANCkwgNDcwLjM0OTI5MyAtMjA2LjAzMzg4NCANCkwgNDcwLjE4OTQ1OSAtMjA2LjAzMzg4NCANCkwgNDcwLjAyOTYyNSAtMjA2LjAzMzg4NCANCkwgNDY5Ljg2OTc5MSAtMjA2LjAzMzg4NCANCkwgNDY5LjcwOTk1OCAtMjA2LjAzMzg4NCANCkwgNDY5LjU1MDEyNCAtMjA2LjAzMzg4NCANCkwgNDY5LjM5MDI5IC0yMDYuMDMzODg0IA0KTCA0NjkuMjMwNDU2IC0yMDYuMDMzODg0IA0KTCA0NjkuMDcwNjIyIC0yMDYuMDMzODg0IA0KTCA0NjguOTEwNzg4IC0yMDYuMDMzODg0IA0KTCA0NjguNzUwOTU0IC0yMDYuMDMzODg0IA0KTCA0NjguNTkxMTIgLTIwNi4wMzM4ODQgDQpMIDQ2OC40MzEyODYgLTIwNi4wMzM4ODQgDQpMIDQ2OC4yNzE0NTMgLTIwNi4wMzM4ODQgDQpMIDQ2OC4xMTE2MTkgLTIwNi4wMzM4ODQgDQpMIDQ2Ny45NTE3ODUgLTIwNi4wMzM4ODQgDQpMIDQ2Ny43OTE5NTEgLTIwNi4wMzM4ODQgDQpMIDQ2Ny42MzIxMTcgLTIwNi4wMzM4ODQgDQpMIDQ2Ny40NzIyODMgLTIwNi4wMzM4ODQgDQpMIDQ2Ny4zMTI0NDkgLTIwNi4wMzM4ODQgDQpMIDQ2Ny4xNTI2MTUgLTIwNi4wMzM4ODQgDQpMIDQ2Ni45OTI3ODIgLTIwNi4wMzM4ODQgDQpMIDQ2Ni44MzI5NDggLTIwNi4wMzM4ODQgDQpMIDQ2Ni42NzMxMTQgLTIwNi4wMzM4ODQgDQpMIDQ2Ni41MTMyOCAtMjA2LjAzMzg4NCANCkwgNDY2LjM1MzQ0NiAtMjA2LjAzMzg4NCANCkwgNDY2LjE5MzYxMiAtMjA2LjAzMzg4NCANCkwgNDY2LjAzMzc3OCAtMjA2LjAzMzg4NCANCkwgNDY1Ljg3Mzk0NCAtMjA2LjAzMzg4NCANCkwgNDY1LjcxNDExIC0yMDYuMDMzODg0IA0KTCA0NjUuNTU0Mjc3IC0yMDYuMDMzODg0IA0KTCA0NjUuMzk0NDQzIC0yMDYuMDMzODg0IA0KTCA0NjUuMjM0NjA5IC0yMDYuMDMzODg0IA0KTCA0NjUuMDc0Nzc1IC0yMDYuMDMzODg0IA0KTCA0NjQuOTE0OTQxIC0yMDYuMDMzODg0IA0KTCA0NjQuNzU1MTA3IC0yMDYuMDMzODg0IA0KTCA0NjQuNTk1MjczIC0yMDYuMDMzODg0IA0KTCA0NjQuNDM1NDM5IC0yMDYuMDMzODg0IA0KTCA0NjQuMjc1NjA1IC0yMDYuMDMzODg0IA0KTCA0NjQuMTE1NzcyIC0yMDYuMDMzODg0IA0KTCA0NjMuOTU1OTM4IC0yMDYuMDMzODg0IA0KTCA0NjMuNzk2MTA0IC0yMDYuMDMzODg0IA0KTCA0NjMuNjM2MjcgLTIwNi4wMzM4ODQgDQpMIDQ2My40NzY0MzYgLTIwNi4wMzM4ODQgDQpMIDQ2My4zMTY2MDIgLTIwNi4wMzM4ODQgDQpMIDQ2My4xNTY3NjggLTIwNi4wMzM4ODQgDQpMIDQ2Mi45OTY5MzQgLTIwNi4wMzM4ODQgDQpMIDQ2Mi44MzcxMDEgLTIwNi4wMzM4ODQgDQpMIDQ2Mi42NzcyNjcgLTIwNi4wMzM4ODQgDQpMIDQ2Mi41MTc0MzMgLTIwNi4wMzM4ODQgDQpMIDQ2Mi4zNTc1OTkgLTIwNi4wMzM4ODQgDQpMIDQ2Mi4xOTc3NjUgLTIwNi4wMzM4ODQgDQpMIDQ2Mi4wMzc5MzEgLTIwNi4wMzM4ODQgDQpMIDQ2MS44NzgwOTcgLTIwNi4wMzM4ODQgDQpMIDQ2MS43MTgyNjMgLTIwNi4wMzM4ODQgDQpMIDQ2MS41NTg0MjkgLTIwNi4wMzM4ODQgDQpMIDQ2MS4zOTg1OTYgLTIwNi4wMzM4ODQgDQpMIDQ2MS4yMzg3NjIgLTIwNi4wMzM4ODQgDQpMIDQ2MS4wNzg5MjggLTIwNi4wMzM4ODQgDQpMIDQ2MC45MTkwOTQgLTIwNi4wMzM4ODQgDQpMIDQ2MC43NTkyNiAtMjA2LjAzMzg4NCANCkwgNDYwLjU5OTQyNiAtMjA2LjAzMzg4NCANCkwgNDYwLjQzOTU5MiAtMjA2LjAzMzg4NCANCkwgNDYwLjI3OTc1OCAtMjA2LjAzMzg4NCANCkwgNDYwLjExOTkyNCAtMjA2LjAzMzg4NCANCkwgNDU5Ljk2MDA5MSAtMjA2LjAzMzg4NCANCkwgNDU5LjgwMDI1NyAtMjA2LjAzMzg4NCANCkwgNDU5LjY0MDQyMyAtMjA2LjAzMzg4NCANCkwgNDU5LjQ4MDU4OSAtMjA2LjAzMzg4NCANCkwgNDU5LjMyMDc1NSAtMjA2LjAzMzg4NCANCkwgNDU5LjE2MDkyMSAtMjA2LjAzMzg4NCANCkwgNDU5LjAwMTA4NyAtMjA2LjAzMzg4NCANCkwgNDU4Ljg0MTI1MyAtMjA2LjAzMzg4NCANCkwgNDU4LjY4MTQyIC0yMDYuMDMzODg0IA0KTCA0NTguNTIxNTg2IC0yMDYuMDMzODg0IA0KTCA0NTguMzYxNzUyIC0yMDYuMDMzODg0IA0KTCA0NTguMjAxOTE4IC0yMDYuMDMzODg0IA0KTCA0NTguMDQyMDg0IC0yMDYuMDMzODg0IA0KTCA0NTcuODgyMjUgLTIwNi4wMzM4ODQgDQpMIDQ1Ny43MjI0MTYgLTIwNi4wMzM4ODQgDQpMIDQ1Ny41NjI1ODIgLTIwNi4wMzM4ODQgDQpMIDQ1Ny40MDI3NDggLTIwNi4wMzM4ODQgDQpMIDQ1Ny4yNDI5MTUgLTIwNi4wMzM4ODQgDQpMIDQ1Ny4wODMwODEgLTIwNi4wMzM4ODQgDQpMIDQ1Ni45MjMyNDcgLTIwNi4wMzM4ODQgDQpMIDQ1Ni43NjM0MTMgLTIwNi4wMzM4ODQgDQpMIDQ1Ni42MDM1NzkgLTIwNi4wMzM4ODQgDQpMIDQ1Ni40NDM3NDUgLTIwNi4wMzM4ODQgDQpMIDQ1Ni4yODM5MTEgLTIwNi4wMzM4ODQgDQpMIDQ1Ni4xMjQwNzcgLTIwNi4wMzM4ODQgDQpMIDQ1NS45NjQyNDQgLTIwNi4wMzM4ODQgDQpMIDQ1NS44MDQ0MSAtMjA2LjAzMzg4NCANCkwgNDU1LjY0NDU3NiAtMjA2LjAzMzg4NCANCkwgNDU1LjQ4NDc0MiAtMjA2LjAzMzg4NCANCkwgNDU1LjMyNDkwOCAtMjA2LjAzMzg4NCANCkwgNDU1LjE2NTA3NCAtMjA2LjAzMzg4NCANCkwgNDU1LjAwNTI0IC0yMDYuMDMzODg0IA0KTCA0NTQuODQ1NDA2IC0yMDYuMDMzODg0IA0KTCA0NTQuNjg1NTcyIC0yMDYuMDMzODg0IA0KTCA0NTQuNTI1NzM5IC0yMDYuMDMzODg0IA0KTCA0NTQuMzY1OTA1IC0yMDYuMDMzODg0IA0KTCA0NTQuMjA2MDcxIC0yMDYuMDMzODg0IA0KTCA0NTQuMDQ2MjM3IC0yMDYuMDMzODg0IA0KTCA0NTMuODg2NDAzIC0yMDYuMDMzODg0IA0KTCA0NTMuNzI2NTY5IC0yMDYuMDMzODg0IA0KTCA0NTMuNTY2NzM1IC0yMDYuMDMzODg0IA0KTCA0NTMuNDA2OTAxIC0yMDYuMDMzODg0IA0KTCA0NTMuMjQ3MDY3IC0yMDYuMDMzODg0IA0KTCA0NTMuMDg3MjM0IC0yMDYuMDMzODg0IA0KTCA0NTIuOTI3NCAtMjA2LjAzMzg4NCANCkwgNDUyLjc2NzU2NiAtMjA2LjAzMzg4NCANCkwgNDUyLjYwNzczMiAtMjA2LjAzMzg4NCANCkwgNDUyLjQ0Nzg5OCAtMjA2LjAzMzg4NCANCkwgNDUyLjI4ODA2NCAtMjA2LjAzMzg4NCANCkwgNDUyLjEyODIzIC0yMDYuMDMzODg0IA0KTCA0NTEuOTY4Mzk2IC0yMDYuMDMzODg0IA0KTCA0NTEuODA4NTYzIC0yMDYuMDMzODg0IA0KTCA0NTEuNjQ4NzI5IC0yMDYuMDMzODg0IA0KTCA0NTEuNDg4ODk1IC0yMDYuMDMzODg0IA0KTCA0NTEuMzI5MDYxIC0yMDYuMDMzODg0IA0KTCA0NTEuMTY5MjI3IC0yMDYuMDMzODg0IA0KTCA0NTEuMDA5MzkzIC0yMDYuMDMzODg0IA0KTCA0NTAuODQ5NTU5IC0yMDYuMDMzODg0IA0KTCA0NTAuNjg5NzI1IC0yMDYuMDMzODg0IA0KTCA0NTAuNTI5ODkxIC0yMDYuMDMzODg0IA0KTCA0NTAuMzcwMDU4IC0yMDYuMDMzODg0IA0KTCA0NTAuMjEwMjI0IC0yMDYuMDMzODg0IA0KTCA0NTAuMDUwMzkgLTIwNi4wMzM4ODQgDQpMIDQ0OS44OTA1NTYgLTIwNi4wMzM4ODQgDQpMIDQ0OS43MzA3MjIgLTIwNi4wMzM4ODQgDQpMIDQ0OS41NzA4ODggLTIwNi4wMzM4ODQgDQpMIDQ0OS40MTEwNTQgLTIwNi4wMzM4ODQgDQpMIDQ0OS4yNTEyMiAtMjA2LjAzMzg4NCANCkwgNDQ5LjA5MTM4NyAtMjA2LjAzMzg4NCANCkwgNDQ4LjkzMTU1MyAtMjA2LjAzMzg4NCANCkwgNDQ4Ljc3MTcxOSAtMjA2LjAzMzg4NCANCkwgNDQ4LjYxMTg4NSAtMjA2LjAzMzg4NCANCkwgNDQ4LjQ1MjA1MSAtMjA2LjAzMzg4NCANCkwgNDQ4LjI5MjIxNyAtMjA2LjAzMzg4NCANCkwgNDQ4LjEzMjM4MyAtMjA2LjAzMzg4NCANCkwgNDQ3Ljk3MjU0OSAtMjA2LjAzMzg4NCANCkwgNDQ3LjgxMjcxNSAtMjA2LjAzMzg4NCANCkwgNDQ3LjY1Mjg4MiAtMjA2LjAzMzg4NCANCkwgNDQ3LjQ5MzA0OCAtMjA2LjAzMzg4NCANCkwgNDQ3LjMzMzIxNCAtMjA2LjAzMzg4NCANCkwgNDQ3LjE3MzM4IC0yMDYuMDMzODg0IA0KTCA0NDcuMDEzNTQ2IC0yMDYuMDMzODg0IA0KTCA0NDYuODUzNzEyIC0yMDYuMDMzODg0IA0KTCA0NDYuNjkzODc4IC0yMDYuMDMzODg0IA0KTCA0NDYuNTM0MDQ0IC0yMDYuMDMzODg0IA0KTCA0NDYuMzc0MjEgLTIwNi4wMzM4ODQgDQpMIDQ0Ni4yMTQzNzcgLTIwNi4wMzM4ODQgDQpMIDQ0Ni4wNTQ1NDMgLTIwNi4wMzM4ODQgDQpMIDQ0NS44OTQ3MDkgLTIwNi4wMzM4ODQgDQpMIDQ0NS43MzQ4NzUgLTIwNi4wMzM4ODQgDQpMIDQ0NS41NzUwNDEgLTIwNi4wMzM4ODQgDQpMIDQ0NS40MTUyMDcgLTIwNi4wMzM4ODQgDQpMIDQ0NS4yNTUzNzMgLTIwNi4wMzM4ODQgDQpMIDQ0NS4wOTU1MzkgLTIwNi4wMzM4ODQgDQpMIDQ0NC45MzU3MDYgLTIwNi4wMzM4ODQgDQpMIDQ0NC43NzU4NzIgLTIwNi4wMzM4ODQgDQpMIDQ0NC42MTYwMzggLTIwNi4wMzM4ODQgDQpMIDQ0NC40NTYyMDQgLTIwNi4wMzM4ODQgDQpMIDQ0NC4yOTYzNyAtMjA2LjAzMzg4NCANCkwgNDQ0LjEzNjUzNiAtMjA2LjAzMzg4NCANCkwgNDQzLjk3NjcwMiAtMjA2LjAzMzg4NCANCkwgNDQzLjgxNjg2OCAtMjA2LjAzMzg4NCANCkwgNDQzLjY1NzAzNCAtMjA2LjAzMzg4NCANCkwgNDQzLjQ5NzIwMSAtMjA2LjAzMzg4NCANCkwgNDQzLjMzNzM2NyAtMjA2LjAzMzg4NCANCkwgNDQzLjE3NzUzMyAtMjA2LjAzMzg4NCANCkwgNDQzLjAxNzY5OSAtMjA2LjAzMzg4NCANCkwgNDQyLjg1Nzg2NSAtMjA2LjAzMzg4NCANCkwgNDQyLjY5ODAzMSAtMjA2LjAzMzg4NCANCkwgNDQyLjUzODE5NyAtMjA2LjAzMzg4NCANCkwgNDQyLjM3ODM2MyAtMjA2LjAzMzg4NCANCkwgNDQyLjIxODUyOSAtMjA2LjAzMzg4NCANCkwgNDQyLjA1ODY5NiAtMjA2LjAzMzg4NCANCkwgNDQxLjg5ODg2MiAtMjA2LjAzMzg4NCANCkwgNDQxLjczOTAyOCAtMjA2LjAzMzg4NCANCkwgNDQxLjU3OTE5NCAtMjA2LjAzMzg4NCANCkwgNDQxLjQxOTM2IC0yMDYuMDMzODg0IA0KTCA0NDEuMjU5NTI2IC0yMDYuMDMzODg0IA0KTCA0NDEuMDk5NjkyIC0yMDYuMDMzODg0IA0KTCA0NDAuOTM5ODU4IC0yMDYuMDMzODg0IA0KTCA0NDAuNzgwMDI1IC0yMDYuMDMzODg0IA0KTCA0NDAuNjIwMTkxIC0yMDYuMDMzODg0IA0KTCA0NDAuNDYwMzU3IC0yMDYuMDMzODg0IA0KTCA0NDAuMzAwNTIzIC0yMDYuMDMzODg0IA0KTCA0NDAuMTQwNjg5IC0yMDYuMDMzODg0IA0KTCA0MzkuOTgwODU1IC0yMDYuMDMzODg0IA0KTCA0MzkuODIxMDIxIC0yMDYuMDMzODg0IA0KTCA0MzkuNjYxMTg3IC0yMDYuMDMzODg0IA0KTCA0MzkuNTAxMzUzIC0yMDYuMDMzODg0IA0KTCA0MzkuMzQxNTIgLTIwNi4wMzM4ODQgDQpMIDQzOS4xODE2ODYgLTIwNi4wMzM4ODQgDQpMIDQzOS4wMjE4NTIgLTIwNi4wMzM4ODQgDQpMIDQzOC44NjIwMTggLTIwNi4wMzM4ODQgDQpMIDQzOC43MDIxODQgLTIwNi4wMzM4ODQgDQpMIDQzOC41NDIzNSAtMjA2LjAzMzg4NCANCkwgNDM4LjM4MjUxNiAtMjA2LjAzMzg4NCANCkwgNDM4LjIyMjY4MiAtMjA2LjAzMzg4NCANCkwgNDM4LjA2Mjg0OSAtMjA2LjAzMzg4NCANCkwgNDM3LjkwMzAxNSAtMjA2LjAzMzg4NCANCkwgNDM3Ljc0MzE4MSAtMjA2LjAzMzg4NCANCkwgNDM3LjU4MzM0NyAtMjA2LjAzMzg4NCANCkwgNDM3LjQyMzUxMyAtMjA2LjAzMzg4NCANCkwgNDM3LjI2MzY3OSAtMjA2LjAzMzg4NCANCkwgNDM3LjEwMzg0NSAtMjA2LjAzMzg4NCANCkwgNDM2Ljk0NDAxMSAtMjA2LjAzMzg4NCANCkwgNDM2Ljc4NDE3NyAtMjA2LjAzMzg4NCANCkwgNDM2LjYyNDM0NCAtMjA2LjAzMzg4NCANCkwgNDM2LjQ2NDUxIC0yMDYuMDMzODg0IA0KTCA0MzYuMzA0Njc2IC0yMDYuMDMzODg0IA0KTCA0MzYuMTQ0ODQyIC0yMDYuMDMzODg0IA0KTCA0MzUuOTg1MDA4IC0yMDYuMDMzODg0IA0KTCA0MzUuODI1MTc0IC0yMDYuMDMzODg0IA0KTCA0MzUuNjY1MzQgLTIwNi4wMzM4ODQgDQpMIDQzNS41MDU1MDYgLTIwNi4wMzM4ODQgDQpMIDQzNS4zNDU2NzIgLTIwNi4wMzM4ODQgDQpMIDQzNS4xODU4MzkgLTIwNi4wMzM4ODQgDQpMIDQzNS4wMjYwMDUgLTIwNi4wMzM4ODQgDQpMIDQzNC44NjYxNzEgLTIwNi4wMzM4ODQgDQpMIDQzNC43MDYzMzcgLTIwNi4wMzM4ODQgDQpMIDQzNC41NDY1MDMgLTIwNi4wMzM4ODQgDQpMIDQzNC4zODY2NjkgLTIwNi4wMzM4ODQgDQpMIDQzNC4yMjY4MzUgLTIwNi4wMzM4ODQgDQpMIDQzNC4wNjcwMDEgLTIwNi4wMzM4ODQgDQpMIDQzMy45MDcxNjggLTIwNi4wMzM4ODQgDQpMIDQzMy43NDczMzQgLTIwNi4wMzM4ODQgDQpMIDQzMy41ODc1IC0yMDYuMDMzODg0IA0KTCA0MzMuNDI3NjY2IC0yMDYuMDMzODg0IA0KTCA0MzMuMjY3ODMyIC0yMDYuMDMzODg0IA0KTCA0MzMuMTA3OTk4IC0yMDYuMDMzODg0IA0KTCA0MzIuOTQ4MTY0IC0yMDYuMDMzODg0IA0KTCA0MzIuNzg4MzMgLTIwNi4wMzM4ODQgDQpMIDQzMi42Mjg0OTYgLTIwNi4wMzM4ODQgDQpMIDQzMi40Njg2NjMgLTIwNi4wMzM4ODQgDQpMIDQzMi4zMDg4MjkgLTIwNi4wMzM4ODQgDQpMIDQzMi4xNDg5OTUgLTIwNi4wMzM4ODQgDQpMIDQzMS45ODkxNjEgLTIwNi4wMzM4ODQgDQpMIDQzMS44MjkzMjcgLTIwNi4wMzM4ODQgDQpMIDQzMS42Njk0OTMgLTIwNi4wMzM4ODQgDQpMIDQzMS41MDk2NTkgLTIwNi4wMzM4ODQgDQpMIDQzMS4zNDk4MjUgLTIwNi4wMzM4ODQgDQpMIDQzMS4xODk5OTIgLTIwNi4wMzM4ODQgDQpMIDQzMS4wMzAxNTggLTIwNi4wMzM4ODQgDQpMIDQzMC44NzAzMjQgLTIwNi4wMzM4ODQgDQpMIDQzMC43MTA0OSAtMjA2LjAzMzg4NCANCkwgNDMwLjU1MDY1NiAtMjA2LjAzMzg4NCANCkwgNDMwLjM5MDgyMiAtMjA2LjAzMzg4NCANCkwgNDMwLjIzMDk4OCAtMjA2LjAzMzg4NCANCkwgNDMwLjA3MTE1NCAtMjA2LjAzMzg4NCANCkwgNDI5LjkxMTMyIC0yMDYuMDMzODg0IA0KTCA0MjkuNzUxNDg3IC0yMDYuMDMzODg0IA0KTCA0MjkuNTkxNjUzIC0yMDYuMDMzODg0IA0KTCA0MjkuNDMxODE5IC0yMDYuMDMzODg0IA0KTCA0MjkuMjcxOTg1IC0yMDYuMDMzODg0IA0KTCA0MjkuMTEyMTUxIC0yMDYuMDMzODg0IA0KTCA0MjguOTUyMzE3IC0yMDYuMDMzODg0IA0KTCA0MjguNzkyNDgzIC0yMDYuMDMzODg0IA0KTCA0MjguNjMyNjQ5IC0yMDYuMDMzODg0IA0KTCA0MjguNDcyODE1IC0yMDYuMDMzODg0IA0KTCA0MjguMzEyOTgyIC0yMDYuMDMzODg0IA0KTCA0MjguMTUzMTQ4IC0yMDYuMDMzODg0IA0KTCA0MjcuOTkzMzE0IC0yMDYuMDMzODg0IA0KTCA0MjcuODMzNDggLTIwNi4wMzM4ODQgDQpMIDQyNy42NzM2NDYgLTIwNi4wMzM4ODQgDQpMIDQyNy41MTM4MTIgLTIwNi4wMzM4ODQgDQpMIDQyNy4zNTM5NzggLTIwNi4wMzM4ODQgDQpMIDQyNy4xOTQxNDQgLTIwNi4wMzM4ODQgDQpMIDQyNy4wMzQzMTEgLTIwNi4wMzM4ODQgDQpMIDQyNi44NzQ0NzcgLTIwNi4wMzM4ODQgDQpMIDQyNi43MTQ2NDMgLTIwNi4wMzM4ODQgDQpMIDQyNi41NTQ4MDkgLTIwNi4wMzM4ODQgDQpMIDQyNi4zOTQ5NzUgLTIwNi4wMzM4ODQgDQpMIDQyNi4yMzUxNDEgLTIwNi4wMzM4ODQgDQpMIDQyNi4wNzUzMDcgLTIwNi4wMzM4ODQgDQpMIDQyNS45MTU0NzMgLTIwNi4wMzM4ODQgDQpMIDQyNS43NTU2MzkgLTIwNi4wMzM4ODQgDQpMIDQyNS41OTU4MDYgLTIwNi4wMzM4ODQgDQpMIDQyNS40MzU5NzIgLTIwNi4wMzM4ODQgDQpMIDQyNS4yNzYxMzggLTIwNi4wMzM4ODQgDQpMIDQyNS4xMTYzMDQgLTIwNi4wMzM4ODQgDQpMIDQyNC45NTY0NyAtMjA2LjAzMzg4NCANCkwgNDI0Ljc5NjYzNiAtMjA2LjAzMzg4NCANCkwgNDI0LjYzNjgwMiAtMjA2LjAzMzg4NCANCkwgNDI0LjQ3Njk2OCAtMjA2LjAzMzg4NCANCkwgNDI0LjMxNzEzNCAtMjA2LjAzMzg4NCANCkwgNDI0LjE1NzMwMSAtMjA2LjAzMzg4NCANCkwgNDIzLjk5NzQ2NyAtMjA2LjAzMzg4NCANCkwgNDIzLjgzNzYzMyAtMjA2LjAzMzg4NCANCkwgNDIzLjY3Nzc5OSAtMjA2LjAzMzg4NCANCkwgNDIzLjUxNzk2NSAtMjA2LjAzMzg4NCANCkwgNDIzLjM1ODEzMSAtMjA2LjAzMzg4NCANCkwgNDIzLjE5ODI5NyAtMjA2LjAzMzg4NCANCkwgNDIzLjAzODQ2MyAtMjA2LjAzMzg4NCANCkwgNDIyLjg3ODYzIC0yMDYuMDMzODg0IA0KTCA0MjIuNzE4Nzk2IC0yMDYuMDMzODg0IA0KTCA0MjIuNTU4OTYyIC0yMDYuMDMzODg0IA0KTCA0MjIuMzk5MTI4IC0yMDYuMDMzODg0IA0KTCA0MjIuMjM5Mjk0IC0yMDYuMDMzODg0IA0KTCA0MjIuMDc5NDYgLTIwNi4wMzM4ODQgDQpMIDQyMS45MTk2MjYgLTIwNi4wMzM4ODQgDQpMIDQyMS43NTk3OTIgLTIwNi4wMzM4ODQgDQpMIDQyMS41OTk5NTggLTIwNi4wMzM4ODQgDQpMIDQyMS40NDAxMjUgLTIwNi4wMzM4ODQgDQpMIDQyMS4yODAyOTEgLTIwNi4wMzM4ODQgDQpMIDQyMS4xMjA0NTcgLTIwNi4wMzM4ODQgDQpMIDQyMC45NjA2MjMgLTIwNi4wMzM4ODQgDQpMIDQyMC44MDA3ODkgLTIwNi4wMzM4ODQgDQpMIDQyMC42NDA5NTUgLTIwNi4wMzM4ODQgDQpMIDQyMC40ODExMjEgLTIwNi4wMzM4ODQgDQpMIDQyMC4zMjEyODcgLTIwNi4wMzM4ODQgDQpMIDQyMC4xNjE0NTQgLTIwNi4wMzM4ODQgDQpMIDQyMC4wMDE2MiAtMjA2LjAzMzg4NCANCkwgNDE5Ljg0MTc4NiAtMjA2LjAzMzg4NCANCkwgNDE5LjY4MTk1MiAtMjA2LjAzMzg4NCANCkwgNDE5LjUyMjExOCAtMjA2LjAzMzg4NCANCkwgNDE5LjM2MjI4NCAtMjA2LjAzMzg4NCANCkwgNDE5LjIwMjQ1IC0yMDYuMDMzODg0IA0KTCA0MTkuMDQyNjE2IC0yMDYuMDMzODg0IA0KTCA0MTguODgyNzgyIC0yMDYuMDMzODg0IA0KTCA0MTguNzIyOTQ5IC0yMDYuMDMzODg0IA0KTCA0MTguNTYzMTE1IC0yMDYuMDMzODg0IA0KTCA0MTguNDAzMjgxIC0yMDYuMDMzODg0IA0KTCA0MTguMjQzNDQ3IC0yMDYuMDMzODg0IA0KTCA0MTguMDgzNjEzIC0yMDYuMDMzODg0IA0KTCA0MTcuOTIzNzc5IC0yMDYuMDMzODg0IA0KTCA0MTcuNzYzOTQ1IC0yMDYuMDMzODg0IA0KTCA0MTcuNjA0MTExIC0yMDYuMDMzODg0IA0KTCA0MTcuNDQ0Mjc3IC0yMDYuMDMzODg0IA0KTCA0MTcuMjg0NDQ0IC0yMDYuMDMzODg0IA0KTCA0MTcuMTI0NjEgLTIwNi4wMzM4ODQgDQpMIDQxNi45NjQ3NzYgLTIwNi4wMzM4ODQgDQpMIDQxNi44MDQ5NDIgLTIwNi4wMzM4ODQgDQpMIDQxNi42NDUxMDggLTIwNi4wMzM4ODQgDQpMIDQxNi40ODUyNzQgLTIwNi4wMzM4ODQgDQpMIDQxNi4zMjU0NCAtMjA2LjAzMzg4NCANCkwgNDE2LjE2NTYwNiAtMjA2LjAzMzg4NCANCkwgNDE2LjAwNTc3MyAtMjA2LjAzMzg4NCANCkwgNDE1Ljg0NTkzOSAtMjA2LjAzMzg4NCANCkwgNDE1LjY4NjEwNSAtMjA2LjAzMzg4NCANCkwgNDE1LjUyNjI3MSAtMjA2LjAzMzg4NCANCkwgNDE1LjM2NjQzNyAtMjA2LjAzMzg4NCANCkwgNDE1LjIwNjYwMyAtMjA2LjAzMzg4NCANCkwgNDE1LjA0Njc2OSAtMjA2LjAzMzg4NCANCkwgNDE0Ljg4NjkzNSAtMjA2LjAzMzg4NCANCkwgNDE0LjcyNzEwMSAtMjA2LjAzMzg4NCANCkwgNDE0LjU2NzI2OCAtMjA2LjAzMzg4NCANCkwgNDE0LjQwNzQzNCAtMjA2LjAzMzg4NCANCkwgNDE0LjI0NzYgLTIwNi4wMzM4ODQgDQpMIDQxNC4wODc3NjYgLTIwNi4wMzM4ODQgDQpMIDQxMy45Mjc5MzIgLTIwNi4wMzM4ODQgDQpMIDQxMy43NjgwOTggLTIwNi4wMzM4ODQgDQpMIDQxMy42MDgyNjQgLTIwNi4wMzM4ODQgDQpMIDQxMy40NDg0MyAtMjA2LjAzMzg4NCANCkwgNDEzLjI4ODU5NyAtMjA2LjAzMzg4NCANCkwgNDEzLjEyODc2MyAtMjA2LjAzMzg4NCANCkwgNDEyLjk2ODkyOSAtMjA2LjAzMzg4NCANCkwgNDEyLjgwOTA5NSAtMjA2LjAzMzg4NCANCkwgNDEyLjY0OTI2MSAtMjA2LjAzMzg4NCANCkwgNDEyLjQ4OTQyNyAtMjA2LjAzMzg4NCANCkwgNDEyLjMyOTU5MyAtMjA2LjAzMzg4NCANCkwgNDEyLjE2OTc1OSAtMjA2LjAzMzg4NCANCkwgNDEyLjAwOTkyNSAtMjA2LjAzMzg4NCANCkwgNDExLjg1MDA5MiAtMjA2LjAzMzg4NCANCkwgNDExLjY5MDI1OCAtMjA2LjAzMzg4NCANCkwgNDExLjUzMDQyNCAtMjA2LjAzMzg4NCANCkwgNDExLjM3MDU5IC0yMDYuMDMzODg0IA0KTCA0MTEuMjEwNzU2IC0yMDYuMDMzODg0IA0KTCA0MTEuMDUwOTIyIC0yMDYuMDMzODg0IA0KTCA0MTAuODkxMDg4IC0yMDYuMDMzODg0IA0KTCA0MTAuNzMxMjU0IC0yMDYuMDMzODg0IA0KTCA0MTAuNTcxNDIgLTIwNi4wMzM4ODQgDQpMIDQxMC40MTE1ODcgLTIwNi4wMzM4ODQgDQpMIDQxMC4yNTE3NTMgLTIwNi4wMzM4ODQgDQpMIDQxMC4wOTE5MTkgLTIwNi4wMzM4ODQgDQpMIDQwOS45MzIwODUgLTIwNi4wMzM4ODQgDQpMIDQwOS43NzIyNTEgLTIwNi4wMzM4ODQgDQpMIDQwOS42MTI0MTcgLTIwNi4wMzM4ODQgDQpMIDQwOS40NTI1ODMgLTIwNi4wMzM4ODQgDQpMIDQwOS4yOTI3NDkgLTIwNi4wMzM4ODQgDQpMIDQwOS4xMzI5MTYgLTIwNi4wMzM4ODQgDQpMIDQwOC45NzMwODIgLTIwNi4wMzM4ODQgDQpMIDQwOC44MTMyNDggLTIwNi4wMzM4ODQgDQpMIDQwOC42NTM0MTQgLTIwNi4wMzM4ODQgDQpMIDQwOC40OTM1OCAtMjA2LjAzMzg4NCANCkwgNDA4LjMzMzc0NiAtMjA2LjAzMzg4NCANCkwgNDA4LjE3MzkxMiAtMjA2LjAzMzg4NCANCkwgNDA4LjAxNDA3OCAtMjA2LjAzMzg4NCANCkwgNDA3Ljg1NDI0NCAtMjA2LjAzMzg4NCANCkwgNDA3LjY5NDQxMSAtMjA2LjAzMzg4NCANCkwgNDA3LjUzNDU3NyAtMjA2LjAzMzg4NCANCkwgNDA3LjM3NDc0MyAtMjA2LjAzMzg4NCANCkwgNDA3LjIxNDkwOSAtMjA2LjAzMzg4NCANCkwgNDA3LjA1NTA3NSAtMjA2LjAzMzg4NCANCkwgNDA2Ljg5NTI0MSAtMjA2LjAzMzg4NCANCkwgNDA2LjczNTQwNyAtMjA2LjAzMzg4NCANCkwgNDA2LjU3NTU3MyAtMjA2LjAzMzg4NCANCkwgNDA2LjQxNTczOSAtMjA2LjAzMzg4NCANCkwgNDA2LjI1NTkwNiAtMjA2LjAzMzg4NCANCkwgNDA2LjA5NjA3MiAtMjA2LjAzMzg4NCANCkwgNDA1LjkzNjIzOCAtMjA2LjAzMzg4NCANCkwgNDA1Ljc3NjQwNCAtMjA2LjAzMzg4NCANCkwgNDA1LjYxNjU3IC0yMDYuMDMzODg0IA0KTCA0MDUuNDU2NzM2IC0yMDYuMDMzODg0IA0KTCA0MDUuMjk2OTAyIC0yMDYuMDMzODg0IA0KTCA0MDUuMTM3MDY4IC0yMDYuMDMzODg0IA0KTCA0MDQuOTc3MjM1IC0yMDYuMDMzODg0IA0KTCA0MDQuODE3NDAxIC0yMDYuMDMzODg0IA0KTCA0MDQuNjU3NTY3IC0yMDYuMDMzODg0IA0KTCA0MDQuNDk3NzMzIC0yMDYuMDMzODg0IA0KTCA0MDQuMzM3ODk5IC0yMDYuMDMzODg0IA0KTCA0MDQuMTc4MDY1IC0yMDYuMDMzODg0IA0KTCA0MDQuMDE4MjMxIC0yMDYuMDMzODg0IA0KTCA0MDMuODU4Mzk3IC0yMDYuMDMzODg0IA0KTCA0MDMuNjk4NTYzIC0yMDYuMDMzODg0IA0KTCA0MDMuNTM4NzMgLTIwNi4wMzM4ODQgDQpMIDQwMy4zNzg4OTYgLTIwNi4wMzM4ODQgDQpMIDQwMy4yMTkwNjIgLTIwNi4wMzM4ODQgDQpMIDQwMy4wNTkyMjggLTIwNi4wMzM4ODQgDQpMIDQwMi44OTkzOTQgLTIwNi4wMzM4ODQgDQpMIDQwMi43Mzk1NiAtMjA2LjAzMzg4NCANCkwgNDAyLjU3OTcyNiAtMjA2LjAzMzg4NCANCkwgNDAyLjQxOTg5MiAtMjA2LjAzMzg4NCANCkwgNDAyLjI2MDA1OSAtMjA2LjAzMzg4NCANCkwgNDAyLjEwMDIyNSAtMjA2LjAzMzg4NCANCkwgNDAxLjk0MDM5MSAtMjA2LjAzMzg4NCANCkwgNDAxLjc4MDU1NyAtMjA2LjAzMzg4NCANCkwgNDAxLjYyMDcyMyAtMjA2LjAzMzg4NCANCkwgNDAxLjQ2MDg4OSAtMjA2LjAzMzg4NCANCkwgNDAxLjMwMTA1NSAtMjA2LjAzMzg4NCANCkwgNDAxLjE0MTIyMSAtMjA2LjAzMzg4NCANCkwgNDAwLjk4MTM4NyAtMjA2LjAzMzg4NCANCkwgNDAwLjgyMTU1NCAtMjA2LjAzMzg4NCANCkwgNDAwLjY2MTcyIC0yMDYuMDMzODg0IA0KTCA0MDAuNTAxODg2IC0yMDYuMDMzODg0IA0KTCA0MDAuMzQyMDUyIC0yMDYuMDMzODg0IA0KTCA0MDAuMTgyMjE4IC0yMDYuMDMzODg0IA0KTCA0MDAuMDIyMzg0IC0yMDYuMDMzODg0IA0KTCAzOTkuODYyNTUgLTIwNi4wMzM4ODQgDQpMIDM5OS43MDI3MTYgLTIwNi4wMzM4ODQgDQpMIDM5OS41NDI4ODIgLTIwNi4wMzM4ODQgDQpMIDM5OS4zODMwNDkgLTIwNi4wMzM4ODQgDQpMIDM5OS4yMjMyMTUgLTIwNi4wMzM4ODQgDQpMIDM5OS4wNjMzODEgLTIwNi4wMzM4ODQgDQpMIDM5OC45MDM1NDcgLTIwNi4wMzM4ODQgDQpMIDM5OC43NDM3MTMgLTIwNi4wMzM4ODQgDQpMIDM5OC41ODM4NzkgLTIwNi4wMzM4ODQgDQpMIDM5OC40MjQwNDUgLTIwNi4wMzM4ODQgDQpMIDM5OC4yNjQyMTEgLTIwNi4wMzM4ODQgDQpMIDM5OC4xMDQzNzggLTIwNi4wMzM4ODQgDQpMIDM5Ny45NDQ1NDQgLTIwNi4wMzM4ODQgDQpMIDM5Ny43ODQ3MSAtMjA2LjAzMzg4NCANCkwgMzk3LjYyNDg3NiAtMjA2LjAzMzg4NCANCkwgMzk3LjQ2NTA0MiAtMjA2LjAzMzg4NCANCkwgMzk3LjMwNTIwOCAtMjA2LjAzMzg4NCANCkwgMzk3LjE0NTM3NCAtMjA2LjAzMzg4NCANCkwgMzk2Ljk4NTU0IC0yMDYuMDMzODg0IA0KTCAzOTYuODI1NzA2IC0yMDYuMDMzODg0IA0KTCAzOTYuNjY1ODczIC0yMDYuMDMzODg0IA0KTCAzOTYuNTA2MDM5IC0yMDYuMDMzODg0IA0KTCAzOTYuMzQ2MjA1IC0yMDYuMDMzODg0IA0KTCAzOTYuMTg2MzcxIC0yMDYuMDMzODg0IA0KTCAzOTYuMDI2NTM3IC0yMDYuMDMzODg0IA0KTCAzOTUuODY2NzAzIC0yMDYuMDMzODg0IA0KTCAzOTUuNzA2ODY5IC0yMDYuMDMzODg0IA0KTCAzOTUuNTQ3MDM1IC0yMDYuMDMzODg0IA0KTCAzOTUuMzg3MjAyIC0yMDYuMDMzODg0IA0KTCAzOTUuMjI3MzY4IC0yMDYuMDMzODg0IA0KTCAzOTUuMDY3NTM0IC0yMDYuMDMzODg0IA0KTCAzOTQuOTA3NyAtMjA2LjAzMzg4NCANCkwgMzk0Ljc0Nzg2NiAtMjA2LjAzMzg4NCANCkwgMzk0LjU4ODAzMiAtMjA2LjAzMzg4NCANCkwgMzk0LjQyODE5OCAtMjA2LjAzMzg4NCANCkwgMzk0LjI2ODM2NCAtMjA2LjAzMzg4NCANCkwgMzk0LjEwODUzIC0yMDYuMDMzODg0IA0KTCAzOTMuOTQ4Njk3IC0yMDYuMDMzODg0IA0KTCAzOTMuNzg4ODYzIC0yMDYuMDMzODg0IA0KTCAzOTMuNjI5MDI5IC0yMDYuMDMzODg0IA0KTCAzOTMuNDY5MTk1IC0yMDYuMDMzODg0IA0KTCAzOTMuMzA5MzYxIC0yMDYuMDMzODg0IA0KTCAzOTMuMTQ5NTI3IC0yMDYuMDMzODg0IA0KTCAzOTIuOTg5NjkzIC0yMDYuMDMzODg0IA0KTCAzOTIuODI5ODU5IC0yMDYuMDMzODg0IA0KTCAzOTIuNjcwMDI1IC0yMDYuMDMzODg0IA0KTCAzOTIuNTEwMTkyIC0yMDYuMDMzODg0IA0KTCAzOTIuMzUwMzU4IC0yMDYuMDMzODg0IA0KTCAzOTIuMTkwNTI0IC0yMDYuMDMzODg0IA0KTCAzOTIuMDMwNjkgLTIwNi4wMzM4ODQgDQpMIDM5MS44NzA4NTYgLTIwNi4wMzM4ODQgDQpMIDM5MS43MTEwMjIgLTIwNi4wMzM4ODQgDQpMIDM5MS41NTExODggLTIwNi4wMzM4ODQgDQpMIDM5MS4zOTEzNTQgLTIwNi4wMzM4ODQgDQpMIDM5MS4yMzE1MjEgLTIwNi4wMzM4ODQgDQpMIDM5MS4wNzE2ODcgLTIwNi4wMzM4ODQgDQpMIDM5MC45MTE4NTMgLTIwNi4wMzM4ODQgDQpMIDM5MC43NTIwMTkgLTIwNi4wMzM4ODQgDQpMIDM5MC41OTIxODUgLTIwNi4wMzM4ODQgDQpMIDM5MC40MzIzNTEgLTIwNi4wMzM4ODQgDQpMIDM5MC4yNzI1MTcgLTIwNi4wMzM4ODQgDQpMIDM5MC4xMTI2ODMgLTIwNi4wMzM4ODQgDQpMIDM4OS45NTI4NDkgLTIwNi4wMzM4ODQgDQpMIDM4OS43OTMwMTYgLTIwNi4wMzM4ODQgDQpMIDM4OS42MzMxODIgLTIwNi4wMzM4ODQgDQpMIDM4OS40NzMzNDggLTIwNi4wMzM4ODQgDQpMIDM4OS4zMTM1MTQgLTIwNi4wMzM4ODQgDQpMIDM4OS4xNTM2OCAtMjA2LjAzMzg4NCANCkwgMzg4Ljk5Mzg0NiAtMjA2LjAzMzg4NCANCkwgMzg4LjgzNDAxMiAtMjA2LjAzMzg4NCANCkwgMzg4LjY3NDE3OCAtMjA2LjAzMzg4NCANCkwgMzg4LjUxNDM0NSAtMjA2LjAzMzg4NCANCkwgMzg4LjM1NDUxMSAtMjA2LjAzMzg4NCANCkwgMzg4LjE5NDY3NyAtMjA2LjAzMzg4NCANCkwgMzg4LjAzNDg0MyAtMjA2LjAzMzg4NCANCkwgMzg3Ljg3NTAwOSAtMjA2LjAzMzg4NCANCkwgMzg3LjcxNTE3NSAtMjA2LjAzMzg4NCANCkwgMzg3LjU1NTM0MSAtMjA2LjAzMzg4NCANCkwgMzg3LjM5NTUwNyAtMjA2LjAzMzg4NCANCkwgMzg3LjIzNTY3MyAtMjA2LjAzMzg4NCANCkwgMzg3LjA3NTg0IC0yMDYuMDMzODg0IA0KTCAzODYuOTE2MDA2IC0yMDYuMDMzODg0IA0KTCAzODYuNzU2MTcyIC0yMDYuMDMzODg0IA0KTCAzODYuNTk2MzM4IC0yMDYuMDMzODg0IA0KTCAzODYuNDM2NTA0IC0yMDYuMDMzODg0IA0KTCAzODYuMjc2NjcgLTIwNi4wMzM4ODQgDQpMIDM4Ni4xMTY4MzYgLTIwNi4wMzM4ODQgDQpMIDM4NS45NTcwMDIgLTIwNi4wMzM4ODQgDQpMIDM4NS43OTcxNjggLTIwNi4wMzM4ODQgDQpMIDM4NS42MzczMzUgLTIwNi4wMzM4ODQgDQpMIDM4NS40Nzc1MDEgLTIwNi4wMzM4ODQgDQpMIDM4NS4zMTc2NjcgLTIwNi4wMzM4ODQgDQpMIDM4NS4xNTc4MzMgLTIwNi4wMzM4ODQgDQpMIDM4NC45OTc5OTkgLTIwNi4wMzM4ODQgDQpMIDM4NC44MzgxNjUgLTIwNi4wMzM4ODQgDQpMIDM4NC42NzgzMzEgLTIwNi4wMzM4ODQgDQpMIDM4NC41MTg0OTcgLTIwNi4wMzM4ODQgDQpMIDM4NC4zNTg2NjQgLTIwNi4wMzM4ODQgDQpMIDM4NC4xOTg4MyAtMjA2LjAzMzg4NCANCkwgMzg0LjAzODk5NiAtMjA2LjAzMzg4NCANCkwgMzgzLjg3OTE2MiAtMjA2LjAzMzg4NCANCkwgMzgzLjcxOTMyOCAtMjA2LjAzMzg4NCANCkwgMzgzLjU1OTQ5NCAtMjA2LjAzMzg4NCANCkwgMzgzLjM5OTY2IC0yMDYuMDMzODg0IA0KTCAzODMuMjM5ODI2IC0yMDYuMDMzODg0IA0KTCAzODMuMDc5OTkyIC0yMDYuMDMzODg0IA0KTCAzODIuOTIwMTU5IC0yMDYuMDMzODg0IA0KTCAzODIuNzYwMzI1IC0yMDYuMDMzODg0IA0KTCAzODIuNjAwNDkxIC0yMDYuMDMzODg0IA0KTCAzODIuNDQwNjU3IC0yMDYuMDMzODg0IA0KTCAzODIuMjgwODIzIC0yMDYuMDMzODg0IA0KTCAzODIuMTIwOTg5IC0yMDYuMDMzODg0IA0KTCAzODEuOTYxMTU1IC0yMDYuMDMzODg0IA0KTCAzODEuODAxMzIxIC0yMDYuMDMzODg0IA0KTCAzODEuNjQxNDg3IC0yMDYuMDMzODg0IA0KTCAzODEuNDgxNjU0IC0yMDYuMDMzODg0IA0KTCAzODEuMzIxODIgLTIwNi4wMzM4ODQgDQpMIDM4MS4xNjE5ODYgLTIwNi4wMzM4ODQgDQpMIDM4MS4wMDIxNTIgLTIwNi4wMzM4ODQgDQpMIDM4MC44NDIzMTggLTIwNi4wMzM4ODQgDQpMIDM4MC42ODI0ODQgLTIwNi4wMzM4ODQgDQpMIDM4MC41MjI2NSAtMjA2LjAzMzg4NCANCkwgMzgwLjM2MjgxNiAtMjA2LjAzMzg4NCANCkwgMzgwLjIwMjk4MyAtMjA2LjAzMzg4NCANCkwgMzgwLjA0MzE0OSAtMjA2LjAzMzg4NCANCkwgMzc5Ljg4MzMxNSAtMjA2LjAzMzg4NCANCkwgMzc5LjcyMzQ4MSAtMjA2LjAzMzg4NCANCkwgMzc5LjU2MzY0NyAtMjA2LjAzMzg4NCANCkwgMzc5LjQwMzgxMyAtMjA2LjAzMzg4NCANCkwgMzc5LjI0Mzk3OSAtMjA2LjAzMzg4NCANCkwgMzc5LjA4NDE0NSAtMjA2LjAzMzg4NCANCkwgMzc4LjkyNDMxMSAtMjA2LjAzMzg4NCANCkwgMzc4Ljc2NDQ3OCAtMjA2LjAzMzg4NCANCkwgMzc4LjYwNDY0NCAtMjA2LjAzMzg4NCANCkwgMzc4LjQ0NDgxIC0yMDYuMDMzODg0IA0KTCAzNzguMjg0OTc2IC0yMDYuMDMzODg0IA0KTCAzNzguMTI1MTQyIC0yMDYuMDMzODg0IA0KTCAzNzcuOTY1MzA4IC0yMDYuMDMzODg0IA0KTCAzNzcuODA1NDc0IC0yMDYuMDMzODg0IA0KTCAzNzcuNjQ1NjQgLTIwNi4wMzM4ODQgDQpMIDM3Ny40ODU4MDcgLTIwNi4wMzM4ODQgDQpMIDM3Ny4zMjU5NzMgLTIwNi4wMzM4ODQgDQpMIDM3Ny4xNjYxMzkgLTIwNi4wMzM4ODQgDQpMIDM3Ny4wMDYzMDUgLTIwNi4wMzM4ODQgDQpMIDM3Ni44NDY0NzEgLTIwNi4wMzM4ODQgDQpMIDM3Ni42ODY2MzcgLTIwNi4wMzM4ODQgDQpMIDM3Ni41MjY4MDMgLTIwNi4wMzM4ODQgDQpMIDM3Ni4zNjY5NjkgLTIwNi4wMzM4ODQgDQpMIDM3Ni4yMDcxMzUgLTIwNi4wMzM4ODQgDQpMIDM3Ni4wNDczMDIgLTIwNi4wMzM4ODQgDQpMIDM3NS44ODc0NjggLTIwNi4wMzM4ODQgDQpMIDM3NS43Mjc2MzQgLTIwNi4wMzM4ODQgDQpMIDM3NS41Njc4IC0yMDYuMDMzODg0IA0KTCAzNzUuNDA3OTY2IC0yMDYuMDMzODg0IA0KTCAzNzUuMjQ4MTMyIC0yMDYuMDMzODg0IA0KTCAzNzUuMDg4Mjk4IC0yMDYuMDMzODg0IA0KTCAzNzQuOTI4NDY0IC0yMDYuMDMzODg0IA0KTCAzNzQuNzY4NjMgLTIwNi4wMzM4ODQgDQpMIDM3NC42MDg3OTcgLTIwNi4wMzM4ODQgDQpMIDM3NC40NDg5NjMgLTIwNi4wMzM4ODQgDQpMIDM3NC4yODkxMjkgLTIwNi4wMzM4ODQgDQpMIDM3NC4xMjkyOTUgLTIwNi4wMzM4ODQgDQpMIDM3My45Njk0NjEgLTIwNi4wMzM4ODQgDQpMIDM3My44MDk2MjcgLTIwNi4wMzM4ODQgDQpMIDM3My42NDk3OTMgLTIwNi4wMzM4ODQgDQpMIDM3My40ODk5NTkgLTIwNi4wMzM4ODQgDQpMIDM3My4zMzAxMjYgLTIwNi4wMzM4ODQgDQpMIDM3My4xNzAyOTIgLTIwNi4wMzM4ODQgDQpMIDM3My4wMTA0NTggLTIwNi4wMzM4ODQgDQpMIDM3Mi44NTA2MjQgLTIwNi4wMzM4ODQgDQpMIDM3Mi42OTA3OSAtMjA2LjAzMzg4NCANCkwgMzcyLjUzMDk1NiAtMjA2LjAzMzg4NCANCkwgMzcyLjM3MTEyMiAtMjA2LjAzMzg4NCANCkwgMzcyLjIxMTI4OCAtMjA2LjAzMzg4NCANCkwgMzcyLjA1MTQ1NCAtMjA2LjAzMzg4NCANCkwgMzcxLjg5MTYyMSAtMjA2LjAzMzg4NCANCkwgMzcxLjczMTc4NyAtMjA2LjAzMzg4NCANCkwgMzcxLjU3MTk1MyAtMjA2LjAzMzg4NCANCkwgMzcxLjQxMjExOSAtMjA2LjAzMzg4NCANCkwgMzcxLjI1MjI4NSAtMjA2LjAzMzg4NCANCkwgMzcxLjA5MjQ1MSAtMjA2LjAzMzg4NCANCkwgMzcwLjkzMjYxNyAtMjA2LjAzMzg4NCANCkwgMzcwLjc3Mjc4MyAtMjA2LjAzMzg4NCANCkwgMzcwLjYxMjk1IC0yMDYuMDMzODg0IA0KTCAzNzAuNDUzMTE2IC0yMDYuMDMzODg0IA0KTCAzNzAuMjkzMjgyIC0yMDYuMDMzODg0IA0KTCAzNzAuMTMzNDQ4IC0yMDYuMDMzODg0IA0KTCAzNjkuOTczNjE0IC0yMDYuMDMzODg0IA0KTCAzNjkuODEzNzggLTIwNi4wMzM4ODQgDQpMIDM2OS42NTM5NDYgLTIwNi4wMzM4ODQgDQpMIDM2OS40OTQxMTIgLTIwNi4wMzM4ODQgDQpMIDM2OS4zMzQyNzggLTIwNi4wMzM4ODQgDQpMIDM2OS4xNzQ0NDUgLTIwNi4wMzM4ODQgDQpMIDM2OS4wMTQ2MTEgLTIwNi4wMzM4ODQgDQpMIDM2OC44NTQ3NzcgLTIwNi4wMzM4ODQgDQpMIDM2OC42OTQ5NDMgLTIwNi4wMzM4ODQgDQpMIDM2OC41MzUxMDkgLTIwNi4wMzM4ODQgDQpMIDM2OC4zNzUyNzUgLTIwNi4wMzM4ODQgDQpMIDM2OC4yMTU0NDEgLTIwNi4wMzM4ODQgDQpMIDM2OC4wNTU2MDcgLTIwNi4wMzM4ODQgDQpMIDM2Ny44OTU3NzMgLTIwNi4wMzM4ODQgDQpMIDM2Ny43MzU5NCAtMjA2LjAzMzg4NCANCkwgMzY3LjU3NjEwNiAtMjA2LjAzMzg4NCANCkwgMzY3LjQxNjI3MiAtMjA2LjAzMzg4NCANCkwgMzY3LjI1NjQzOCAtMjA2LjAzMzg4NCANCkwgMzY3LjA5NjYwNCAtMjA2LjAzMzg4NCANCkwgMzY2LjkzNjc3IC0yMDYuMDMzODg0IA0KTCAzNjYuNzc2OTM2IC0yMDYuMDMzODg0IA0KTCAzNjYuNjE3MTAyIC0yMDYuMDMzODg0IA0KTCAzNjYuNDU3MjY5IC0yMDYuMDMzODg0IA0KTCAzNjYuMjk3NDM1IC0yMDYuMDMzODg0IA0KTCAzNjYuMTM3NjAxIC0yMDYuMDMzODg0IA0KTCAzNjUuOTc3NzY3IC0yMDYuMDMzODg0IA0KTCAzNjUuODE3OTMzIC0yMDYuMDMzODg0IA0KTCAzNjUuNjU4MDk5IC0yMDYuMDMzODg0IA0KTCAzNjUuNDk4MjY1IC0yMDYuMDMzODg0IA0KTCAzNjUuMzM4NDMxIC0yMDYuMDMzODg0IA0KTCAzNjUuMTc4NTk3IC0yMDYuMDMzODg0IA0KTCAzNjUuMDE4NzY0IC0yMDYuMDMzODg0IA0KTCAzNjQuODU4OTMgLTIwNi4wMzM4ODQgDQpMIDM2NC42OTkwOTYgLTIwNi4wMzM4ODQgDQpMIDM2NC41MzkyNjIgLTIwNi4wMzM4ODQgDQpMIDM2NC4zNzk0MjggLTIwNi4wMzM4ODQgDQpMIDM2NC4yMTk1OTQgLTIwNi4wMzM4ODQgDQpMIDM2NC4wNTk3NiAtMjA2LjAzMzg4NCANCkwgMzYzLjg5OTkyNiAtMjA2LjAzMzg4NCANCkwgMzYzLjc0MDA5MiAtMjA2LjAzMzg4NCANCkwgMzYzLjU4MDI1OSAtMjA2LjAzMzg4NCANCkwgMzYzLjQyMDQyNSAtMjA2LjAzMzg4NCANCkwgMzYzLjI2MDU5MSAtMjA2LjAzMzg4NCANCkwgMzYzLjEwMDc1NyAtMjA2LjAzMzg4NCANCkwgMzYyLjk0MDkyMyAtMjA2LjAzMzg4NCANCkwgMzYyLjc4MTA4OSAtMjA2LjAzMzg4NCANCkwgMzYyLjYyMTI1NSAtMjA2LjAzMzg4NCANCkwgMzYyLjQ2MTQyMSAtMjA2LjAzMzg4NCANCkwgMzYyLjMwMTU4OCAtMjA2LjAzMzg4NCANCkwgMzYyLjE0MTc1NCAtMjA2LjAzMzg4NCANCkwgMzYxLjk4MTkyIC0yMDYuMDMzODg0IA0KTCAzNjEuODIyMDg2IC0yMDYuMDMzODg0IA0KTCAzNjEuNjYyMjUyIC0yMDYuMDMzODg0IA0KTCAzNjEuNTAyNDE4IC0yMDYuMDMzODg0IA0KTCAzNjEuMzQyNTg0IC0yMDYuMDMzODg0IA0KTCAzNjEuMTgyNzUgLTIwNi4wMzM4ODQgDQpMIDM2MS4wMjI5MTYgLTIwNi4wMzM4ODQgDQpMIDM2MC44NjMwODMgLTIwNi4wMzM4ODQgDQpMIDM2MC43MDMyNDkgLTIwNi4wMzM4ODQgDQpMIDM2MC41NDM0MTUgLTIwNi4wMzM4ODQgDQpMIDM2MC4zODM1ODEgLTIwNi4wMzM4ODQgDQpMIDM2MC4yMjM3NDcgLTIwNi4wMzM4ODQgDQpMIDM2MC4wNjM5MTMgLTIwNi4wMzM4ODQgDQpMIDM1OS45MDQwNzkgLTIwNi4wMzM4ODQgDQpMIDM1OS43NDQyNDUgLTIwNi4wMzM4ODQgDQpMIDM1OS41ODQ0MTIgLTIwNi4wMzM4ODQgDQpMIDM1OS40MjQ1NzggLTIwNi4wMzM4ODQgDQpMIDM1OS4yNjQ3NDQgLTIwNi4wMzM4ODQgDQpMIDM1OS4xMDQ5MSAtMjA2LjAzMzg4NCANCkwgMzU4Ljk0NTA3NiAtMjA2LjAzMzg4NCANCkwgMzU4Ljc4NTI0MiAtMjA2LjAzMzg4NCANCkwgMzU4LjYyNTQwOCAtMjA2LjAzMzg4NCANCkwgMzU4LjQ2NTU3NCAtMjA2LjAzMzg4NCANCkwgMzU4LjMwNTc0IC0yMDYuMDMzODg0IA0KTCAzNTguMTQ1OTA3IC0yMDYuMDMzODg0IA0KTCAzNTcuOTg2MDczIC0yMDYuMDMzODg0IA0KTCAzNTcuODI2MjM5IC0yMDYuMDMzODg0IA0KTCAzNTcuNjY2NDA1IC0yMDYuMDMzODg0IA0KTCAzNTcuNTA2NTcxIC0yMDYuMDMzODg0IA0KTCAzNTcuMzQ2NzM3IC0yMDYuMDMzODg0IA0KTCAzNTcuMTg2OTAzIC0yMDYuMDMzODg0IA0KTCAzNTcuMDI3MDY5IC0yMDYuMDMzODg0IA0KTCAzNTYuODY3MjM1IC0yMDYuMDMzODg0IA0KTCAzNTYuNzA3NDAyIC0yMDYuMDMzODg0IA0KTCAzNTYuNTQ3NTY4IC0yMDYuMDMzODg0IA0KTCAzNTYuMzg3NzM0IC0yMDYuMDMzODg0IA0KTCAzNTYuMjI3OSAtMjA2LjAzMzg4NCANCkwgMzU2LjA2ODA2NiAtMjA2LjAzMzg4NCANCkwgMzU1LjkwODIzMiAtMjA2LjAzMzg4NCANCkwgMzU1Ljc0ODM5OCAtMjA2LjAzMzg4NCANCkwgMzU1LjU4ODU2NCAtMjA2LjAzMzg4NCANCkwgMzU1LjQyODczMSAtMjA2LjAzMzg4NCANCkwgMzU1LjI2ODg5NyAtMjA2LjAzMzg4NCANCkwgMzU1LjEwOTA2MyAtMjA2LjAzMzg4NCANCkwgMzU0Ljk0OTIyOSAtMjA2LjAzMzg4NCANCkwgMzU0Ljc4OTM5NSAtMjA2LjAzMzg4NCANCkwgMzU0LjYyOTU2MSAtMjA2LjAzMzg4NCANCkwgMzU0LjQ2OTcyNyAtMjA2LjAzMzg4NCANCkwgMzU0LjMwOTg5MyAtMjA2LjAzMzg4NCANCkwgMzU0LjE1MDA1OSAtMjA2LjAzMzg4NCANCkwgMzUzLjk5MDIyNiAtMjA2LjAzMzg4NCANCkwgMzUzLjgzMDM5MiAtMjA2LjAzMzg4NCANCkwgMzUzLjY3MDU1OCAtMjA2LjAzMzg4NCANCkwgMzUzLjUxMDcyNCAtMjA2LjAzMzg4NCANCkwgMzUzLjM1MDg5IC0yMDYuMDMzODg0IA0KTCAzNTMuMTkxMDU2IC0yMDYuMDMzODg0IA0KTCAzNTMuMDMxMjIyIC0yMDYuMDMzODg0IA0KTCAzNTIuODcxMzg4IC0yMDYuMDMzODg0IA0KTCAzNTIuNzExNTU1IC0yMDYuMDMzODg0IA0KTCAzNTIuNTUxNzIxIC0yMDYuMDMzODg0IA0KTCAzNTIuMzkxODg3IC0yMDYuMDMzODg0IA0KTCAzNTIuMjMyMDUzIC0yMDYuMDMzODg0IA0KTCAzNTIuMDcyMjE5IC0yMDYuMDMzODg0IA0KTCAzNTEuOTEyMzg1IC0yMDYuMDMzODg0IA0KTCAzNTEuNzUyNTUxIC0yMDYuMDMzODg0IA0KTCAzNTEuNTkyNzE3IC0yMDYuMDMzODg0IA0KTCAzNTEuNDMyODgzIC0yMDYuMDMzODg0IA0KTCAzNTEuMjczMDUgLTIwNi4wMzM4ODQgDQpMIDM1MS4xMTMyMTYgLTIwNi4wMzM4ODQgDQpMIDM1MC45NTMzODIgLTIwNi4wMzM4ODQgDQpMIDM1MC43OTM1NDggLTIwNi4wMzM4ODQgDQpMIDM1MC42MzM3MTQgLTIwNi4wMzM4ODQgDQpMIDM1MC40NzM4OCAtMjA2LjAzMzg4NCANCkwgMzUwLjMxNDA0NiAtMjA2LjAzMzg4NCANCkwgMzUwLjE1NDIxMiAtMjA2LjAzMzg4NCANCkwgMzQ5Ljk5NDM3OCAtMjA2LjAzMzg4NCANCkwgMzQ5LjgzNDU0NSAtMjA2LjAzMzg4NCANCkwgMzQ5LjY3NDcxMSAtMjA2LjAzMzg4NCANCkwgMzQ5LjUxNDg3NyAtMjA2LjAzMzg4NCANCkwgMzQ5LjM1NTA0MyAtMjA2LjAzMzg4NCANCkwgMzQ5LjE5NTIwOSAtMjA2LjAzMzg4NCANCkwgMzQ5LjAzNTM3NSAtMjA2LjAzMzg4NCANCkwgMzQ4Ljg3NTU0MSAtMjA2LjAzMzg4NCANCkwgMzQ4LjcxNTcwNyAtMjA2LjAzMzg4NCANCkwgMzQ4LjU1NTg3NCAtMjA2LjAzMzg4NCANCkwgMzQ4LjM5NjA0IC0yMDYuMDMzODg0IA0KTCAzNDguMjM2MjA2IC0yMDYuMDMzODg0IA0KTCAzNDguMDc2MzcyIC0yMDYuMDMzODg0IA0KTCAzNDcuOTE2NTM4IC0yMDYuMDMzODg0IA0KTCAzNDcuNzU2NzA0IC0yMDYuMDMzODg0IA0KTCAzNDcuNTk2ODcgLTIwNi4wMzM4ODQgDQpMIDM0Ny40MzcwMzYgLTIwNi4wMzM4ODQgDQpMIDM0Ny4yNzcyMDIgLTIwNi4wMzM4ODQgDQpMIDM0Ny4xMTczNjkgLTIwNi4wMzM4ODQgDQpMIDM0Ni45NTc1MzUgLTIwNi4wMzM4ODQgDQpMIDM0Ni43OTc3MDEgLTIwNi4wMzM4ODQgDQpMIDM0Ni42Mzc4NjcgLTIwNi4wMzM4ODQgDQpMIDM0Ni40NzgwMzMgLTIwNi4wMzM4ODQgDQpMIDM0Ni4zMTgxOTkgLTIwNi4wMzM4ODQgDQpMIDM0Ni4xNTgzNjUgLTIwNi4wMzM4ODQgDQpMIDM0NS45OTg1MzEgLTIwNi4wMzM4ODQgDQpMIDM0NS44Mzg2OTcgLTIwNi4wMzM4ODQgDQpMIDM0NS42Nzg4NjQgLTIwNi4wMzM4ODQgDQpMIDM0NS41MTkwMyAtMjA2LjAzMzg4NCANCkwgMzQ1LjM1OTE5NiAtMjA2LjAzMzg4NCANCkwgMzQ1LjE5OTM2MiAtMjA2LjAzMzg4NCANCkwgMzQ1LjAzOTUyOCAtMjA2LjAzMzg4NCANCkwgMzQ0Ljg3OTY5NCAtMjA2LjAzMzg4NCANCkwgMzQ0LjcxOTg2IC0yMDYuMDMzODg0IA0KTCAzNDQuNTYwMDI2IC0yMDYuMDMzODg0IA0KTCAzNDQuNDAwMTkzIC0yMDYuMDMzODg0IA0KTCAzNDQuMjQwMzU5IC0yMDYuMDMzODg0IA0KTCAzNDQuMDgwNTI1IC0yMDYuMDMzODg0IA0KTCAzNDMuOTIwNjkxIC0yMDYuMDMzODg0IA0KTCAzNDMuNzYwODU3IC0yMDYuMDMzODg0IA0KTCAzNDMuNjAxMDIzIC0yMDYuMDMzODg0IA0KTCAzNDMuNDQxMTg5IC0yMDYuMDMzODg0IA0KTCAzNDMuMjgxMzU1IC0yMDYuMDMzODg0IA0KTCAzNDMuMTIxNTIxIC0yMDYuMDMzODg0IA0KTCAzNDIuOTYxNjg4IC0yMDYuMDMzODg0IA0KTCAzNDIuODAxODU0IC0yMDYuMDMzODg0IA0KTCAzNDIuNjQyMDIgLTIwNi4wMzM4ODQgDQpMIDM0Mi40ODIxODYgLTIwNi4wMzM4ODQgDQpMIDM0Mi4zMjIzNTIgLTIwNi4wMzM4ODQgDQpMIDM0Mi4xNjI1MTggLTIwNi4wMzM4ODQgDQpMIDM0Mi4wMDI2ODQgLTIwNi4wMzM4ODQgDQpMIDM0MS44NDI4NSAtMjA2LjAzMzg4NCANCkwgMzQxLjY4MzAxNyAtMjA2LjAzMzg4NCANCkwgMzQxLjUyMzE4MyAtMjA2LjAzMzg4NCANCkwgMzQxLjM2MzM0OSAtMjA2LjAzMzg4NCANCkwgMzQxLjIwMzUxNSAtMjA2LjAzMzg4NCANCkwgMzQxLjA0MzY4MSAtMjA2LjAzMzg4NCANCkwgMzQwLjg4Mzg0NyAtMjA2LjAzMzg4NCANCkwgMzQwLjcyNDAxMyAtMjA2LjAzMzg4NCANCkwgMzQwLjU2NDE3OSAtMjA2LjAzMzg4NCANCkwgMzQwLjQwNDM0NSAtMjA2LjAzMzg4NCANCkwgMzQwLjI0NDUxMiAtMjA2LjAzMzg4NCANCkwgMzQwLjA4NDY3OCAtMjA2LjAzMzg4NCANCkwgMzM5LjkyNDg0NCAtMjA2LjAzMzg4NCANCkwgMzM5Ljc2NTAxIC0yMDYuMDMzODg0IA0KTCAzMzkuNjA1MTc2IC0yMDYuMDMzODg0IA0KTCAzMzkuNDQ1MzQyIC0yMDYuMDMzODg0IA0KTCAzMzkuMjg1NTA4IC0yMDYuMDMzODg0IA0KTCAzMzkuMTI1Njc0IC0yMDYuMDMzODg0IA0KTCAzMzguOTY1ODQgLTIwNi4wMzM4ODQgDQpMIDMzOC44MDYwMDcgLTIwNi4wMzM4ODQgDQpMIDMzOC42NDYxNzMgLTIwNi4wMzM4ODQgDQpMIDMzOC40ODYzMzkgLTIwNi4wMzM4ODQgDQpMIDMzOC4zMjY1MDUgLTIwNi4wMzM4ODQgDQpMIDMzOC4xNjY2NzEgLTIwNi4wMzM4ODQgDQpMIDMzOC4wMDY4MzcgLTIwNi4wMzM4ODQgDQpMIDMzNy44NDcwMDMgLTIwNi4wMzM4ODQgDQpMIDMzNy42ODcxNjkgLTIwNi4wMzM4ODQgDQpMIDMzNy41MjczMzYgLTIwNi4wMzM4ODQgDQpMIDMzNy4zNjc1MDIgLTIwNi4wMzM4ODQgDQpMIDMzNy4yMDc2NjggLTIwNi4wMzM4ODQgDQpMIDMzNy4wNDc4MzQgLTIwNi4wMzM4ODQgDQpMIDMzNi44ODggLTIwNi4wMzM4ODQgDQpMIDMzNi43MjgxNjYgLTIwNi4wMzM4ODQgDQpMIDMzNi41NjgzMzIgLTIwNi4wMzM4ODQgDQpMIDMzNi40MDg0OTggLTIwNi4wMzM4ODQgDQpMIDMzNi4yNDg2NjQgLTIwNi4wMzM4ODQgDQpMIDMzNi4wODg4MzEgLTIwNi4wMzM4ODQgDQpMIDMzNS45Mjg5OTcgLTIwNi4wMzM4ODQgDQpMIDMzNS43NjkxNjMgLTIwNi4wMzM4ODQgDQpMIDMzNS42MDkzMjkgLTIwNi4wMzM4ODQgDQpMIDMzNS40NDk0OTUgLTIwNi4wMzM4ODQgDQpMIDMzNS4yODk2NjEgLTIwNi4wMzM4ODQgDQpMIDMzNS4xMjk4MjcgLTIwNi4wMzM4ODQgDQpMIDMzNC45Njk5OTMgLTIwNi4wMzM4ODQgDQpMIDMzNC44MTAxNiAtMjA2LjAzMzg4NCANCkwgMzM0LjY1MDMyNiAtMjA2LjAzMzg4NCANCkwgMzM0LjQ5MDQ5MiAtMjA2LjAzMzg4NCANCkwgMzM0LjMzMDY1OCAtMjA2LjAzMzg4NCANCkwgMzM0LjE3MDgyNCAtMjA2LjAzMzg4NCANCkwgMzM0LjAxMDk5IC0yMDYuMDMzODg0IA0KTCAzMzMuODUxMTU2IC0yMDYuMDMzODg0IA0KTCAzMzMuNjkxMzIyIC0yMDYuMDMzODg0IA0KTCAzMzMuNTMxNDg4IC0yMDYuMDMzODg0IA0KTCAzMzMuMzcxNjU1IC0yMDYuMDMzODg0IA0KTCAzMzMuMjExODIxIC0yMDYuMDMzODg0IA0KTCAzMzMuMDUxOTg3IC0yMDYuMDMzODg0IA0KTCAzMzIuODkyMTUzIC0yMDYuMDMzODg0IA0KTCAzMzIuNzMyMzE5IC0yMDYuMDMzODg0IA0KTCAzMzIuNTcyNDg1IC0yMDYuMDMzODg0IA0KTCAzMzIuNDEyNjUxIC0yMDYuMDMzODg0IA0KTCAzMzIuMjUyODE3IC0yMDYuMDMzODg0IA0KTCAzMzIuMDkyOTgzIC0yMDYuMDMzODg0IA0KTCAzMzEuOTMzMTUgLTIwNi4wMzM4ODQgDQpMIDMzMS43NzMzMTYgLTIwNi4wMzM4ODQgDQpMIDMzMS42MTM0ODIgLTIwNi4wMzM4ODQgDQpMIDMzMS40NTM2NDggLTIwNi4wMzM4ODQgDQpMIDMzMS4yOTM4MTQgLTIwNi4wMzM4ODQgDQpMIDMzMS4xMzM5OCAtMjA2LjAzMzg4NCANCkwgMzMwLjk3NDE0NiAtMjA2LjAzMzg4NCANCkwgMzMwLjgxNDMxMiAtMjA2LjAzMzg4NCANCkwgMzMwLjY1NDQ3OSAtMjA2LjAzMzg4NCANCkwgMzMwLjQ5NDY0NSAtMjA2LjAzMzg4NCANCkwgMzMwLjMzNDgxMSAtMjA2LjAzMzg4NCANCkwgMzMwLjE3NDk3NyAtMjA2LjAzMzg4NCANCkwgMzMwLjAxNTE0MyAtMjA2LjAzMzg4NCANCkwgMzI5Ljg1NTMwOSAtMjA2LjAzMzg4NCANCkwgMzI5LjY5NTQ3NSAtMjA2LjAzMzg4NCANCkwgMzI5LjUzNTY0MSAtMjA2LjAzMzg4NCANCkwgMzI5LjM3NTgwNyAtMjA2LjAzMzg4NCANCkwgMzI5LjIxNTk3NCAtMjA2LjAzMzg4NCANCkwgMzI5LjA1NjE0IC0yMDYuMDMzODg0IA0KTCAzMjguODk2MzA2IC0yMDYuMDMzODg0IA0KTCAzMjguNzM2NDcyIC0yMDYuMDMzODg0IA0KTCAzMjguNTc2NjM4IC0yMDYuMDMzODg0IA0KTCAzMjguNDE2ODA0IC0yMDYuMDMzODg0IA0KTCAzMjguMjU2OTcgLTIwNi4wMzM4ODQgDQpMIDMyOC4wOTcxMzYgLTIwNi4wMzM4ODQgDQpMIDMyNy45MzczMDMgLTIwNi4wMzM4ODQgDQpMIDMyNy43Nzc0NjkgLTIwNi4wMzM4ODQgDQpMIDMyNy42MTc2MzUgLTIwNi4wMzM4ODQgDQpMIDMyNy40NTc4MDEgLTIwNi4wMzM4ODQgDQpMIDMyNy4yOTc5NjcgLTIwNi4wMzM4ODQgDQpMIDMyNy4xMzgxMzMgLTIwNi4wMzM4ODQgDQpMIDMyNi45NzgyOTkgLTIwNi4wMzM4ODQgDQpMIDMyNi44MTg0NjUgLTIwNi4wMzM4ODQgDQpMIDMyNi42NTg2MzEgLTIwNi4wMzM4ODQgDQpMIDMyNi40OTg3OTggLTIwNi4wMzM4ODQgDQpMIDMyNi4zMzg5NjQgLTIwNi4wMzM4ODQgDQpMIDMyNi4xNzkxMyAtMjA2LjAzMzg4NCANCkwgMzI2LjAxOTI5NiAtMjA2LjAzMzg4NCANCkwgMzI1Ljg1OTQ2MiAtMjA2LjAzMzg4NCANCkwgMzI1LjY5OTYyOCAtMjA2LjAzMzg4NCANCkwgMzI1LjUzOTc5NCAtMjA2LjAzMzg4NCANCkwgMzI1LjM3OTk2IC0yMDYuMDMzODg0IA0KTCAzMjUuMjIwMTI2IC0yMDYuMDMzODg0IA0KTCAzMjUuMDYwMjkzIC0yMDYuMDMzODg0IA0KTCAzMjQuOTAwNDU5IC0yMDYuMDMzODg0IA0KTCAzMjQuNzQwNjI1IC0yMDYuMDMzODg0IA0KTCAzMjQuNTgwNzkxIC0yMDYuMDMzODg0IA0KTCAzMjQuNDIwOTU3IC0yMDYuMDMzODg0IA0KTCAzMjQuMjYxMTIzIC0yMDYuMDMzODg0IA0KTCAzMjQuMTAxMjg5IC0yMDYuMDMzODg0IA0KTCAzMjMuOTQxNDU1IC0yMDYuMDMzODg0IA0KTCAzMjMuNzgxNjIyIC0yMDYuMDMzODg0IA0KTCAzMjMuNjIxNzg4IC0yMDYuMDMzODg0IA0KTCAzMjMuNDYxOTU0IC0yMDYuMDMzODg0IA0KTCAzMjMuMzAyMTIgLTIwNi4wMzM4ODQgDQpMIDMyMy4xNDIyODYgLTIwNi4wMzM4ODQgDQpMIDMyMi45ODI0NTIgLTIwNi4wMzM4ODQgDQpMIDMyMi44MjI2MTggLTIwNi4wMzM4ODQgDQpMIDMyMi42NjI3ODQgLTIwNi4wMzM4ODQgDQpMIDMyMi41MDI5NSAtMjA2LjAzMzg4NCANCkwgMzIyLjM0MzExNyAtMjA2LjAzMzg4NCANCkwgMzIyLjE4MzI4MyAtMjA2LjAzMzg4NCANCkwgMzIyLjAyMzQ0OSAtMjA2LjAzMzg4NCANCkwgMzIxLjg2MzYxNSAtMjA2LjAzMzg4NCANCkwgMzIxLjcwMzc4MSAtMjA2LjAzMzg4NCANCkwgMzIxLjU0Mzk0NyAtMjA2LjAzMzg4NCANCkwgMzIxLjM4NDExMyAtMjA2LjAzMzg4NCANCkwgMzIxLjIyNDI3OSAtMjA2LjAzMzg4NCANCkwgMzIxLjA2NDQ0NSAtMjA2LjAzMzg4NCANCkwgMzIwLjkwNDYxMiAtMjA2LjAzMzg4NCANCkwgMzIwLjc0NDc3OCAtMjA2LjAzMzg4NCANCkwgMzIwLjU4NDk0NCAtMjA2LjAzMzg4NCANCkwgMzIwLjQyNTExIC0yMDYuMDMzODg0IA0KTCAzMjAuMjY1Mjc2IC0yMDYuMDMzODg0IA0KTCAzMjAuMTA1NDQyIC0yMDYuMDMzODg0IA0KTCAzMTkuOTQ1NjA4IC0yMDYuMDMzODg0IA0KTCAzMTkuNzg1Nzc0IC0yMDYuMDMzODg0IA0KTCAzMTkuNjI1OTQxIC0yMDYuMDMzODg0IA0KTCAzMTkuNDY2MTA3IC0yMDYuMDMzODg0IA0KTCAzMTkuMzA2MjczIC0yMDYuMDMzODg0IA0KTCAzMTkuMTQ2NDM5IC0yMDYuMDMzODg0IA0KTCAzMTguOTg2NjA1IC0yMDYuMDMzODg0IA0KTCAzMTguODI2NzcxIC0yMDYuMDMzODg0IA0KTCAzMTguNjY2OTM3IC0yMDYuMDMzODg0IA0KTCAzMTguNTA3MTAzIC0yMDYuMDMzODg0IA0KTCAzMTguMzQ3MjY5IC0yMDYuMDMzODg0IA0KTCAzMTguMTg3NDM2IC0yMDYuMDMzODg0IA0KTCAzMTguMDI3NjAyIC0yMDYuMDMzODg0IA0KTCAzMTcuODY3NzY4IC0yMDYuMDMzODg0IA0KTCAzMTcuNzA3OTM0IC0yMDYuMDMzODg0IA0KTCAzMTcuNTQ4MSAtMjA2LjAzMzg4NCANCkwgMzE3LjM4ODI2NiAtMjA2LjAzMzg4NCANCkwgMzE3LjIyODQzMiAtMjA2LjAzMzg4NCANCkwgMzE3LjA2ODU5OCAtMjA2LjAzMzg4NCANCkwgMzE2LjkwODc2NSAtMjA2LjAzMzg4NCANCkwgMzE2Ljc0ODkzMSAtMjA2LjAzMzg4NCANCkwgMzE2LjU4OTA5NyAtMjA2LjAzMzg4NCANCkwgMzE2LjQyOTI2MyAtMjA2LjAzMzg4NCANCkwgMzE2LjI2OTQyOSAtMjA2LjAzMzg4NCANCkwgMzE2LjEwOTU5NSAtMjA2LjAzMzg4NCANCkwgMzE1Ljk0OTc2MSAtMjA2LjAzMzg4NCANCkwgMzE1Ljc4OTkyNyAtMjA2LjAzMzg4NCANCkwgMzE1LjYzMDA5MyAtMjA2LjAzMzg4NCANCkwgMzE1LjQ3MDI2IC0yMDYuMDMzODg0IA0KTCAzMTUuMzEwNDI2IC0yMDYuMDMzODg0IA0KTCAzMTUuMTUwNTkyIC0yMDYuMDMzODg0IA0KTCAzMTQuOTkwNzU4IC0yMDYuMDMzODg0IA0KTCAzMTQuODMwOTI0IC0yMDYuMDMzODg0IA0KTCAzMTQuNjcxMDkgLTIwNi4wMzM4ODQgDQpMIDMxNC41MTEyNTYgLTIwNi4wMzM4ODQgDQpMIDMxNC4zNTE0MjIgLTIwNi4wMzM4ODQgDQpMIDMxNC4xOTE1ODggLTIwNi4wMzM4ODQgDQpMIDMxNC4wMzE3NTUgLTIwNi4wMzM4ODQgDQpMIDMxMy44NzE5MjEgLTIwNi4wMzM4ODQgDQpMIDMxMy43MTIwODcgLTIwNi4wMzM4ODQgDQpMIDMxMy41NTIyNTMgLTIwNi4wMzM4ODQgDQpMIDMxMy4zOTI0MTkgLTIwNi4wMzM4ODQgDQpMIDMxMy4yMzI1ODUgLTIwNi4wMzM4ODQgDQpMIDMxMy4wNzI3NTEgLTIwNi4wMzM4ODQgDQpMIDMxMi45MTI5MTcgLTIwNi4wMzM4ODQgDQpMIDMxMi43NTMwODQgLTIwNi4wMzM4ODQgDQpMIDMxMi41OTMyNSAtMjA2LjAzMzg4NCANCkwgMzEyLjQzMzQxNiAtMjA2LjAzMzg4NCANCkwgMzEyLjI3MzU4MiAtMjA2LjAzMzg4NCANCkwgMzEyLjExMzc0OCAtMjA2LjAzMzg4NCANCkwgMzExLjk1MzkxNCAtMjA2LjAzMzg4NCANCkwgMzExLjc5NDA4IC0yMDYuMDMzODg0IA0KTCAzMTEuNjM0MjQ2IC0yMDYuMDMzODg0IA0KTCAzMTEuNDc0NDEyIC0yMDYuMDMzODg0IA0KTCAzMTEuMzE0NTc5IC0yMDYuMDMzODg0IA0KTCAzMTEuMTU0NzQ1IC0yMDYuMDMzODg0IA0KTCAzMTAuOTk0OTExIC0yMDYuMDMzODg0IA0KTCAzMTAuODM1MDc3IC0yMDYuMDMzODg0IA0KTCAzMTAuNjc1MjQzIC0yMDYuMDMzODg0IA0KTCAzMTAuNTE1NDA5IC0yMDYuMDMzODg0IA0KTCAzMTAuMzU1NTc1IC0yMDYuMDMzODg0IA0KTCAzMTAuMTk1NzQxIC0yMDYuMDMzODg0IA0KTCAzMTAuMDM1OTA4IC0yMDYuMDMzODg0IA0KTCAzMDkuODc2MDc0IC0yMDYuMDMzODg0IA0KTCAzMDkuNzE2MjQgLTIwNi4wMzM4ODQgDQpMIDMwOS41NTY0MDYgLTIwNi4wMzM4ODQgDQpMIDMwOS4zOTY1NzIgLTIwNi4wMzM4ODQgDQpMIDMwOS4yMzY3MzggLTIwNi4wMzM4ODQgDQpMIDMwOS4wNzY5MDQgLTIwNi4wMzM4ODQgDQpMIDMwOC45MTcwNyAtMjA2LjAzMzg4NCANCkwgMzA4Ljc1NzIzNiAtMjA2LjAzMzg4NCANCkwgMzA4LjU5NzQwMyAtMjA2LjAzMzg4NCANCkwgMzA4LjQzNzU2OSAtMjA2LjAzMzg4NCANCkwgMzA4LjI3NzczNSAtMjA2LjAzMzg4NCANCkwgMzA4LjExNzkwMSAtMjA2LjAzMzg4NCANCkwgMzA3Ljk1ODA2NyAtMjA2LjAzMzg4NCANCkwgMzA3Ljc5ODIzMyAtMjA2LjAzMzg4NCANCkwgMzA3LjYzODM5OSAtMjA2LjAzMzg4NCANCkwgMzA3LjQ3ODU2NSAtMjA2LjAzMzg4NCANCkwgMzA3LjMxODczMSAtMjA2LjAzMzg4NCANCkwgMzA3LjE1ODg5OCAtMjA2LjAzMzg4NCANCkwgMzA2Ljk5OTA2NCAtMjA2LjAzMzg4NCANCkwgMzA2LjgzOTIzIC0yMDYuMDMzODg0IA0KTCAzMDYuNjc5Mzk2IC0yMDYuMDMzODg0IA0KTCAzMDYuNTE5NTYyIC0yMDYuMDMzODg0IA0KTCAzMDYuMzU5NzI4IC0yMDYuMDMzODg0IA0KTCAzMDYuMTk5ODk0IC0yMDYuMDMzODg0IA0KTCAzMDYuMDQwMDYgLTIwNi4wMzM4ODQgDQpMIDMwNS44ODAyMjcgLTIwNi4wMzM4ODQgDQpMIDMwNS43MjAzOTMgLTIwNi4wMzM4ODQgDQpMIDMwNS41NjA1NTkgLTIwNi4wMzM4ODQgDQpMIDMwNS40MDA3MjUgLTIwNi4wMzM4ODQgDQpMIDMwNS4yNDA4OTEgLTIwNi4wMzM4ODQgDQpMIDMwNS4wODEwNTcgLTIwNi4wMzM4ODQgDQpMIDMwNC45MjEyMjMgLTIwNi4wMzM4ODQgDQpMIDMwNC43NjEzODkgLTIwNi4wMzM4ODQgDQpMIDMwNC42MDE1NTUgLTIwNi4wMzM4ODQgDQpMIDMwNC40NDE3MjIgLTIwNi4wMzM4ODQgDQpMIDMwNC4yODE4ODggLTIwNi4wMzM4ODQgDQpMIDMwNC4xMjIwNTQgLTIwNi4wMzM4ODQgDQpMIDMwMy45NjIyMiAtMjA2LjAzMzg4NCANCkwgMzAzLjgwMjM4NiAtMjA2LjAzMzg4NCANCkwgMzAzLjY0MjU1MiAtMjA2LjAzMzg4NCANCkwgMzAzLjQ4MjcxOCAtMjA2LjAzMzg4NCANCkwgMzAzLjMyMjg4NCAtMjA2LjAzMzg4NCANCkwgMzAzLjE2MzA1IC0yMDYuMDMzODg0IA0KTCAzMDMuMDAzMjE3IC0yMDYuMDMzODg0IA0KTCAzMDIuODQzMzgzIC0yMDYuMDMzODg0IA0KTCAzMDIuNjgzNTQ5IC0yMDYuMDMzODg0IA0KTCAzMDIuNTIzNzE1IC0yMDYuMDMzODg0IA0KTCAzMDIuMzYzODgxIC0yMDYuMDMzODg0IA0KTCAzMDIuMjA0MDQ3IC0yMDYuMDMzODg0IA0KTCAzMDIuMDQ0MjEzIC0yMDYuMDMzODg0IA0KTCAzMDEuODg0Mzc5IC0yMDYuMDMzODg0IA0KTCAzMDEuNzI0NTQ2IC0yMDYuMDMzODg0IA0KTCAzMDEuNTY0NzEyIC0yMDYuMDMzODg0IA0KTCAzMDEuNDA0ODc4IC0yMDYuMDMzODg0IA0KTCAzMDEuMjQ1MDQ0IC0yMDYuMDMzODg0IA0KTCAzMDEuMDg1MjEgLTIwNi4wMzM4ODQgDQpMIDMwMC45MjUzNzYgLTIwNi4wMzM4ODQgDQpMIDMwMC43NjU1NDIgLTIwNi4wMzM4ODQgDQpMIDMwMC42MDU3MDggLTIwNi4wMzM4ODQgDQpMIDMwMC40NDU4NzQgLTIwNi4wMzM4ODQgDQpMIDMwMC4yODYwNDEgLTIwNi4wMzM4ODQgDQpMIDMwMC4xMjYyMDcgLTIwNi4wMzM4ODQgDQpMIDI5OS45NjYzNzMgLTIwNi4wMzM4ODQgDQpMIDI5OS44MDY1MzkgLTIwNi4wMzM4ODQgDQpMIDI5OS42NDY3MDUgLTIwNi4wMzM4ODQgDQpMIDI5OS40ODY4NzEgLTIwNi4wMzM4ODQgDQpMIDI5OS4zMjcwMzcgLTIwNi4wMzM4ODQgDQpMIDI5OS4xNjcyMDMgLTIwNi4wMzM4ODQgDQpMIDI5OS4wMDczNyAtMjA2LjAzMzg4NCANCkwgMjk4Ljg0NzUzNiAtMjA2LjAzMzg4NCANCkwgMjk4LjY4NzcwMiAtMjA2LjAzMzg4NCANCkwgMjk4LjUyNzg2OCAtMjA2LjAzMzg4NCANCkwgMjk4LjM2ODAzNCAtMjA2LjAzMzg4NCANCkwgMjk4LjIwODIgLTIwNi4wMzM4ODQgDQpMIDI5OC4wNDgzNjYgLTIwNi4wMzM4ODQgDQpMIDI5Ny44ODg1MzIgLTIwNi4wMzM4ODQgDQpMIDI5Ny43Mjg2OTggLTIwNi4wMzM4ODQgDQpMIDI5Ny41Njg4NjUgLTIwNi4wMzM4ODQgDQpMIDI5Ny40MDkwMzEgLTIwNi4wMzM4ODQgDQpMIDI5Ny4yNDkxOTcgLTIwNi4wMzM4ODQgDQpMIDI5Ny4wODkzNjMgLTIwNi4wMzM4ODQgDQpMIDI5Ni45Mjk1MjkgLTIwNi4wMzM4ODQgDQpMIDI5Ni43Njk2OTUgLTIwNi4wMzM4ODQgDQpMIDI5Ni42MDk4NjEgLTIwNi4wMzM4ODQgDQpMIDI5Ni40NTAwMjcgLTIwNi4wMzM4ODQgDQpMIDI5Ni4yOTAxOTMgLTIwNi4wMzM4ODQgDQpMIDI5Ni4xMzAzNiAtMjA2LjAzMzg4NCANCkwgMjk1Ljk3MDUyNiAtMjA2LjAzMzg4NCANCkwgMjk1LjgxMDY5MiAtMjA2LjAzMzg4NCANCkwgMjk1LjY1MDg1OCAtMjA2LjAzMzg4NCANCkwgMjk1LjQ5MTAyNCAtMjA2LjAzMzg4NCANCkwgMjk1LjMzMTE5IC0yMDYuMDMzODg0IA0KTCAyOTUuMTcxMzU2IC0yMDYuMDMzODg0IA0KTCAyOTUuMDExNTIyIC0yMDYuMDMzODg0IA0KTCAyOTQuODUxNjg5IC0yMDYuMDMzODg0IA0KTCAyOTQuNjkxODU1IC0yMDYuMDMzODg0IA0KTCAyOTQuNTMyMDIxIC0yMDYuMDMzODg0IA0KTCAyOTQuMzcyMTg3IC0yMDYuMDMzODg0IA0KTCAyOTQuMjEyMzUzIC0yMDYuMDMzODg0IA0KTCAyOTQuMDUyNTE5IC0yMDYuMDMzODg0IA0KTCAyOTMuODkyNjg1IC0yMDYuMDMzODg0IA0KTCAyOTMuNzMyODUxIC0yMDYuMDMzODg0IA0KTCAyOTMuNTczMDE3IC0yMDYuMDMzODg0IA0KTCAyOTMuNDEzMTg0IC0yMDYuMDMzODg0IA0KTCAyOTMuMjUzMzUgLTIwNi4wMzM4ODQgDQpMIDI5My4wOTM1MTYgLTIwNi4wMzM4ODQgDQpMIDI5Mi45MzM2ODIgLTIwNi4wMzM4ODQgDQpMIDI5Mi43NzM4NDggLTIwNi4wMzM4ODQgDQpMIDI5Mi42MTQwMTQgLTIwNi4wMzM4ODQgDQpMIDI5Mi40NTQxOCAtMjA2LjAzMzg4NCANCkwgMjkyLjI5NDM0NiAtMjA2LjAzMzg4NCANCkwgMjkyLjEzNDUxMyAtMjA2LjAzMzg4NCANCkwgMjkxLjk3NDY3OSAtMjA2LjAzMzg4NCANCkwgMjkxLjgxNDg0NSAtMjA2LjAzMzg4NCANCkwgMjkxLjY1NTAxMSAtMjA2LjAzMzg4NCANCkwgMjkxLjQ5NTE3NyAtMjA2LjAzMzg4NCANCkwgMjkxLjMzNTM0MyAtMjA2LjAzMzg4NCANCkwgMjkxLjE3NTUwOSAtMjA2LjAzMzg4NCANCkwgMjkxLjAxNTY3NSAtMjA2LjAzMzg4NCANCkwgMjkwLjg1NTg0MSAtMjA2LjAzMzg4NCANCkwgMjkwLjY5NjAwOCAtMjA2LjAzMzg4NCANCkwgMjkwLjUzNjE3NCAtMjA2LjAzMzg4NCANCkwgMjkwLjM3NjM0IC0yMDYuMDMzODg0IA0KTCAyOTAuMjE2NTA2IC0yMDYuMDMzODg0IA0KTCAyOTAuMDU2NjcyIC0yMDYuMDMzODg0IA0KTCAyODkuODk2ODM4IC0yMDYuMDMzODg0IA0KTCAyODkuNzM3MDA0IC0yMDYuMDMzODg0IA0KTCAyODkuNTc3MTcgLTIwNi4wMzM4ODQgDQpMIDI4OS40MTczMzYgLTIwNi4wMzM4ODQgDQpMIDI4OS4yNTc1MDMgLTIwNi4wMzM4ODQgDQpMIDI4OS4wOTc2NjkgLTIwNi4wMzM4ODQgDQpMIDI4OC45Mzc4MzUgLTIwNi4wMzM4ODQgDQpMIDI4OC43NzgwMDEgLTIwNi4wMzM4ODQgDQpMIDI4OC42MTgxNjcgLTIwNi4wMzM4ODQgDQpMIDI4OC40NTgzMzMgLTIwNi4wMzM4ODQgDQpMIDI4OC4yOTg0OTkgLTIwNi4wMzM4ODQgDQpMIDI4OC4xMzg2NjUgLTIwNi4wMzM4ODQgDQpMIDI4Ny45Nzg4MzIgLTIwNi4wMzM4ODQgDQpMIDI4Ny44MTg5OTggLTIwNi4wMzM4ODQgDQpMIDI4Ny42NTkxNjQgLTIwNi4wMzM4ODQgDQpMIDI4Ny40OTkzMyAtMjA2LjAzMzg4NCANCkwgMjg3LjMzOTQ5NiAtMjA2LjAzMzg4NCANCkwgMjg3LjE3OTY2MiAtMjA2LjAzMzg4NCANCkwgMjg3LjAxOTgyOCAtMjA2LjAzMzg4NCANCkwgMjg2Ljg1OTk5NCAtMjA2LjAzMzg4NCANCkwgMjg2LjcwMDE2IC0yMDYuMDMzODg0IA0KTCAyODYuNTQwMzI3IC0yMDYuMDMzODg0IA0KTCAyODYuMzgwNDkzIC0yMDYuMDMzODg0IA0KTCAyODYuMjIwNjU5IC0yMDYuMDMzODg0IA0KTCAyODYuMDYwODI1IC0yMDYuMDMzODg0IA0KTCAyODUuOTAwOTkxIC0yMDYuMDMzODg0IA0KTCAyODUuNzQxMTU3IC0yMDYuMDMzODg0IA0KTCAyODUuNTgxMzIzIC0yMDYuMDMzODg0IA0KTCAyODUuNDIxNDg5IC0yMDYuMDMzODg0IA0KTCAyODUuMjYxNjU1IC0yMDYuMDMzODg0IA0KTCAyODUuMTAxODIyIC0yMDYuMDMzODg0IA0KTCAyODQuOTQxOTg4IC0yMDYuMDMzODg0IA0KTCAyODQuNzgyMTU0IC0yMDYuMDMzODg0IA0KTCAyODQuNjIyMzIgLTIwNi4wMzM4ODQgDQpMIDI4NC40NjI0ODYgLTIwNi4wMzM4ODQgDQpMIDI4NC4zMDI2NTIgLTIwNi4wMzM4ODQgDQpMIDI4NC4xNDI4MTggLTIwNi4wMzM4ODQgDQpMIDI4My45ODI5ODQgLTIwNi4wMzM4ODQgDQpMIDI4My44MjMxNTEgLTIwNi4wMzM4ODQgDQpMIDI4My42NjMzMTcgLTIwNi4wMzM4ODQgDQpMIDI4My41MDM0ODMgLTIwNi4wMzM4ODQgDQpMIDI4My4zNDM2NDkgLTIwNi4wMzM4ODQgDQpMIDI4My4xODM4MTUgLTIwNi4wMzM4ODQgDQpMIDI4My4wMjM5ODEgLTIwNi4wMzM4ODQgDQpMIDI4Mi44NjQxNDcgLTIwNi4wMzM4ODQgDQpMIDI4Mi43MDQzMTMgLTIwNi4wMzM4ODQgDQpMIDI4Mi41NDQ0NzkgLTIwNi4wMzM4ODQgDQpMIDI4Mi4zODQ2NDYgLTIwNi4wMzM4ODQgDQpMIDI4Mi4yMjQ4MTIgLTIwNi4wMzM4ODQgDQpMIDI4Mi4wNjQ5NzggLTIwNi4wMzM4ODQgDQpMIDI4MS45MDUxNDQgLTIwNi4wMzM4ODQgDQpMIDI4MS43NDUzMSAtMjA2LjAzMzg4NCANCkwgMjgxLjU4NTQ3NiAtMjA2LjAzMzg4NCANCkwgMjgxLjQyNTY0MiAtMjA2LjAzMzg4NCANCkwgMjgxLjI2NTgwOCAtMjA2LjAzMzg4NCANCkwgMjgxLjEwNTk3NSAtMjA2LjAzMzg4NCANCkwgMjgwLjk0NjE0MSAtMjA2LjAzMzg4NCANCkwgMjgwLjc4NjMwNyAtMjA2LjAzMzg4NCANCkwgMjgwLjYyNjQ3MyAtMjA2LjAzMzg4NCANCkwgMjgwLjQ2NjYzOSAtMjA2LjAzMzg4NCANCkwgMjgwLjMwNjgwNSAtMjA2LjAzMzg4NCANCkwgMjgwLjE0Njk3MSAtMjA2LjAzMzg4NCANCkwgMjc5Ljk4NzEzNyAtMjA2LjAzMzg4NCANCkwgMjc5LjgyNzMwMyAtMjA2LjAzMzg4NCANCkwgMjc5LjY2NzQ3IC0yMDYuMDMzODg0IA0KTCAyNzkuNTA3NjM2IC0yMDYuMDMzODg0IA0KTCAyNzkuMzQ3ODAyIC0yMDYuMDMzODg0IA0KTCAyNzkuMTg3OTY4IC0yMDYuMDMzODg0IA0KTCAyNzkuMDI4MTM0IC0yMDYuMDMzODg0IA0KTCAyNzguODY4MyAtMjA2LjAzMzg4NCANCkwgMjc4LjcwODQ2NiAtMjA2LjAzMzg4NCANCkwgMjc4LjU0ODYzMiAtMjA2LjAzMzg4NCANCkwgMjc4LjM4ODc5OCAtMjA2LjAzMzg4NCANCkwgMjc4LjIyODk2NSAtMjA2LjAzMzg4NCANCkwgMjc4LjA2OTEzMSAtMjA2LjAzMzg4NCANCkwgMjc3LjkwOTI5NyAtMjA2LjAzMzg4NCANCkwgMjc3Ljc0OTQ2MyAtMjA2LjAzMzg4NCANCkwgMjc3LjU4OTYyOSAtMjA2LjAzMzg4NCANCkwgMjc3LjQyOTc5NSAtMjA2LjAzMzg4NCANCkwgMjc3LjI2OTk2MSAtMjA2LjAzMzg4NCANCkwgMjc3LjExMDEyNyAtMjA2LjAzMzg4NCANCkwgMjc2Ljk1MDI5NCAtMjA2LjAzMzg4NCANCkwgMjc2Ljc5MDQ2IC0yMDYuMDMzODg0IA0KTCAyNzYuNjMwNjI2IC0yMDYuMDMzODg0IA0KTCAyNzYuNDcwNzkyIC0yMDYuMDMzODg0IA0KTCAyNzYuMzEwOTU4IC0yMDYuMDMzODg0IA0KTCAyNzYuMTUxMTI0IC0yMDYuMDMzODg0IA0KTCAyNzUuOTkxMjkgLTIwNi4wMzM4ODQgDQpMIDI3NS44MzE0NTYgLTIwNi4wMzM4ODQgDQpMIDI3NS42NzE2MjIgLTIwNi4wMzM4ODQgDQpMIDI3NS41MTE3ODkgLTIwNi4wMzM4ODQgDQpMIDI3NS4zNTE5NTUgLTIwNi4wMzM4ODQgDQpMIDI3NS4xOTIxMjEgLTIwNi4wMzM4ODQgDQpMIDI3NS4wMzIyODcgLTIwNi4wMzM4ODQgDQpMIDI3NC44NzI0NTMgLTIwNi4wMzM4ODQgDQpMIDI3NC43MTI2MTkgLTIwNi4wMzM4ODQgDQpMIDI3NC41NTI3ODUgLTIwNi4wMzM4ODQgDQpMIDI3NC4zOTI5NTEgLTIwNi4wMzM4ODQgDQpMIDI3NC4yMzMxMTggLTIwNi4wMzM4ODQgDQpMIDI3NC4wNzMyODQgLTIwNi4wMzM4ODQgDQpMIDI3My45MTM0NSAtMjA2LjAzMzg4NCANCkwgMjczLjc1MzYxNiAtMjA2LjAzMzg4NCANCkwgMjczLjU5Mzc4MiAtMjA2LjAzMzg4NCANCkwgMjczLjQzMzk0OCAtMjA2LjAzMzg4NCANCkwgMjczLjI3NDExNCAtMjA2LjAzMzg4NCANCkwgMjczLjExNDI4IC0yMDYuMDMzODg0IA0KTCAyNzIuOTU0NDQ2IC0yMDYuMDMzODg0IA0KTCAyNzIuNzk0NjEzIC0yMDYuMDMzODg0IA0KTCAyNzIuNjM0Nzc5IC0yMDYuMDMzODg0IA0KTCAyNzIuNDc0OTQ1IC0yMDYuMDMzODg0IA0KTCAyNzIuMzE1MTExIC0yMDYuMDMzODg0IA0KTCAyNzIuMTU1Mjc3IC0yMDYuMDMzODg0IA0KTCAyNzEuOTk1NDQzIC0yMDYuMDMzODg0IA0KTCAyNzEuODM1NjA5IC0yMDYuMDMzODg0IA0KTCAyNzEuNjc1Nzc1IC0yMDYuMDMzODg0IA0KTCAyNzEuNTE1OTQxIC0yMDYuMDMzODg0IA0KTCAyNzEuMzU2MTA4IC0yMDYuMDMzODg0IA0KTCAyNzEuMTk2Mjc0IC0yMDYuMDMzODg0IA0KTCAyNzEuMDM2NDQgLTIwNi4wMzM4ODQgDQpMIDI3MC44NzY2MDYgLTIwNi4wMzM4ODQgDQpMIDI3MC43MTY3NzIgLTIwNi4wMzM4ODQgDQpMIDI3MC41NTY5MzggLTIwNi4wMzM4ODQgDQpMIDI3MC4zOTcxMDQgLTIwNi4wMzM4ODQgDQpMIDI3MC4yMzcyNyAtMjA2LjAzMzg4NCANCkwgMjcwLjA3NzQzNyAtMjA2LjAzMzg4NCANCkwgMjY5LjkxNzYwMyAtMjA2LjAzMzg4NCANCkwgMjY5Ljc1Nzc2OSAtMjA2LjAzMzg4NCANCkwgMjY5LjU5NzkzNSAtMjA2LjAzMzg4NCANCkwgMjY5LjQzODEwMSAtMjA2LjAzMzg4NCANCkwgMjY5LjI3ODI2NyAtMjA2LjAzMzg4NCANCkwgMjY5LjExODQzMyAtMjA2LjAzMzg4NCANCkwgMjY4Ljk1ODU5OSAtMjA2LjAzMzg4NCANCkwgMjY4Ljc5ODc2NSAtMjA2LjAzMzg4NCANCkwgMjY4LjYzODkzMiAtMjA2LjAzMzg4NCANCkwgMjY4LjQ3OTA5OCAtMjA2LjAzMzg4NCANCkwgMjY4LjMxOTI2NCAtMjA2LjAzMzg4NCANCkwgMjY4LjE1OTQzIC0yMDYuMDMzODg0IA0KTCAyNjcuOTk5NTk2IC0yMDYuMDMzODg0IA0KTCAyNjcuODM5NzYyIC0yMDYuMDMzODg0IA0KTCAyNjcuNjc5OTI4IC0yMDYuMDMzODg0IA0KTCAyNjcuNTIwMDk0IC0yMDYuMDMzODg0IA0KTCAyNjcuMzYwMjYxIC0yMDYuMDMzODg0IA0KTCAyNjcuMjAwNDI3IC0yMDYuMDMzODg0IA0KTCAyNjcuMDQwNTkzIC0yMDYuMDMzODg0IA0KTCAyNjYuODgwNzU5IC0yMDYuMDMzODg0IA0KTCAyNjYuNzIwOTI1IC0yMDYuMDMzODg0IA0KTCAyNjYuNTYxMDkxIC0yMDYuMDMzODg0IA0KTCAyNjYuNDAxMjU3IC0yMDYuMDMzODg0IA0KTCAyNjYuMjQxNDIzIC0yMDYuMDMzODg0IA0KTCAyNjYuMDgxNTg5IC0yMDYuMDMzODg0IA0KTCAyNjUuOTIxNzU2IC0yMDYuMDMzODg0IA0KTCAyNjUuNzYxOTIyIC0yMDYuMDMzODg0IA0KTCAyNjUuNjAyMDg4IC0yMDYuMDMzODg0IA0KTCAyNjUuNDQyMjU0IC0yMDYuMDMzODg0IA0KTCAyNjUuMjgyNDIgLTIwNi4wMzM4ODQgDQpMIDI2NS4xMjI1ODYgLTIwNi4wMzM4ODQgDQpMIDI2NC45NjI3NTIgLTIwNi4wMzM4ODQgDQpMIDI2NC44MDI5MTggLTIwNi4wMzM4ODQgDQpMIDI2NC42NDMwODQgLTIwNi4wMzM4ODQgDQpMIDI2NC40ODMyNTEgLTIwNi4wMzM4ODQgDQpMIDI2NC4zMjM0MTcgLTIwNi4wMzM4ODQgDQpMIDI2NC4xNjM1ODMgLTIwNi4wMzM4ODQgDQpMIDI2NC4wMDM3NDkgLTIwNi4wMzM4ODQgDQpMIDI2My44NDM5MTUgLTIwNi4wMzM4ODQgDQpMIDI2My42ODQwODEgLTIwNi4wMzM4ODQgDQpMIDI2My41MjQyNDcgLTIwNi4wMzM4ODQgDQpMIDI2My4zNjQ0MTMgLTIwNi4wMzM4ODQgDQpMIDI2My4yMDQ1OCAtMjA2LjAzMzg4NCANCkwgMjYzLjA0NDc0NiAtMjA2LjAzMzg4NCANCkwgMjYyLjg4NDkxMiAtMjA2LjAzMzg4NCANCkwgMjYyLjcyNTA3OCAtMjA2LjAzMzg4NCANCkwgMjYyLjU2NTI0NCAtMjA2LjAzMzg4NCANCkwgMjYyLjQwNTQxIC0yMDYuMDMzODg0IA0KTCAyNjIuMjQ1NTc2IC0yMDYuMDMzODg0IA0KTCAyNjIuMDg1NzQyIC0yMDYuMDMzODg0IA0KTCAyNjEuOTI1OTA4IC0yMDYuMDMzODg0IA0KTCAyNjEuNzY2MDc1IC0yMDYuMDMzODg0IA0KTCAyNjEuNjA2MjQxIC0yMDYuMDMzODg0IA0KTCAyNjEuNDQ2NDA3IC0yMDYuMDMzODg0IA0KTCAyNjEuMjg2NTczIC0yMDYuMDMzODg0IA0KTCAyNjEuMTI2NzM5IC0yMDYuMDMzODg0IA0KTCAyNjAuOTY2OTA1IC0yMDYuMDMzODg0IA0KTCAyNjAuODA3MDcxIC0yMDYuMDMzODg0IA0KTCAyNjAuNjQ3MjM3IC0yMDYuMDMzODg0IA0KTCAyNjAuNDg3NDAzIC0yMDYuMDMzODg0IA0KTCAyNjAuMzI3NTcgLTIwNi4wMzM4ODQgDQpMIDI2MC4xNjc3MzYgLTIwNi4wMzM4ODQgDQpMIDI2MC4wMDc5MDIgLTIwNi4wMzM4ODQgDQpMIDI1OS44NDgwNjggLTIwNi4wMzM4ODQgDQpMIDI1OS42ODgyMzQgLTIwNi4wMzM4ODQgDQpMIDI1OS41Mjg0IC0yMDYuMDMzODg0IA0KTCAyNTkuMzY4NTY2IC0yMDYuMDMzODg0IA0KTCAyNTkuMjA4NzMyIC0yMDYuMDMzODg0IA0KTCAyNTkuMDQ4ODk5IC0yMDYuMDMzODg0IA0KTCAyNTguODg5MDY1IC0yMDYuMDMzODg0IA0KTCAyNTguNzI5MjMxIC0yMDYuMDMzODg0IA0KTCAyNTguNTY5Mzk3IC0yMDYuMDMzODg0IA0KTCAyNTguNDA5NTYzIC0yMDYuMDMzODg0IA0KTCAyNTguMjQ5NzI5IC0yMDYuMDMzODg0IA0KTCAyNTguMDg5ODk1IC0yMDYuMDMzODg0IA0KTCAyNTcuOTMwMDYxIC0yMDYuMDMzODg0IA0KTCAyNTcuNzcwMjI3IC0yMDYuMDMzODg0IA0KTCAyNTcuNjEwMzk0IC0yMDYuMDMzODg0IA0KTCAyNTcuNDUwNTYgLTIwNi4wMzM4ODQgDQpMIDI1Ny4yOTA3MjYgLTIwNi4wMzM4ODQgDQpMIDI1Ny4xMzA4OTIgLTIwNi4wMzM4ODQgDQpMIDI1Ni45NzEwNTggLTIwNi4wMzM4ODQgDQpMIDI1Ni44MTEyMjQgLTIwNi4wMzM4ODQgDQpMIDI1Ni42NTEzOSAtMjA2LjAzMzg4NCANCkwgMjU2LjQ5MTU1NiAtMjA2LjAzMzg4NCANCkwgMjU2LjMzMTcyMyAtMjA2LjAzMzg4NCANCkwgMjU2LjE3MTg4OSAtMjA2LjAzMzg4NCANCkwgMjU2LjAxMjA1NSAtMjA2LjAzMzg4NCANCkwgMjU1Ljg1MjIyMSAtMjA2LjAzMzg4NCANCkwgMjU1LjY5MjM4NyAtMjA2LjAzMzg4NCANCkwgMjU1LjUzMjU1MyAtMjA2LjAzMzg4NCANCkwgMjU1LjM3MjcxOSAtMjA2LjAzMzg4NCANCkwgMjU1LjIxMjg4NSAtMjA2LjAzMzg4NCANCkwgMjU1LjA1MzA1MSAtMjA2LjAzMzg4NCANCkwgMjU0Ljg5MzIxOCAtMjA2LjAzMzg4NCANCkwgMjU0LjczMzM4NCAtMjA2LjAzMzg4NCANCkwgMjU0LjU3MzU1IC0yMDYuMDMzODg0IA0KTCAyNTQuNDEzNzE2IC0yMDYuMDMzODg0IA0KTCAyNTQuMjUzODgyIC0yMDYuMDMzODg0IA0KTCAyNTQuMDk0MDQ4IC0yMDYuMDMzODg0IA0KTCAyNTMuOTM0MjE0IC0yMDYuMDMzODg0IA0KTCAyNTMuNzc0MzggLTIwNi4wMzM4ODQgDQpMIDI1My42MTQ1NDYgLTIwNi4wMzM4ODQgDQpMIDI1My40NTQ3MTMgLTIwNi4wMzM4ODQgDQpMIDI1My4yOTQ4NzkgLTIwNi4wMzM4ODQgDQpMIDI1My4xMzUwNDUgLTIwNi4wMzM4ODQgDQpMIDI1Mi45NzUyMTEgLTIwNi4wMzM4ODQgDQpMIDI1Mi44MTUzNzcgLTIwNi4wMzM4ODQgDQpMIDI1Mi42NTU1NDMgLTIwNi4wMzM4ODQgDQpMIDI1Mi40OTU3MDkgLTIwNi4wMzM4ODQgDQpMIDI1Mi4zMzU4NzUgLTIwNi4wMzM4ODQgDQpMIDI1Mi4xNzYwNDIgLTIwNi4wMzM4ODQgDQpMIDI1Mi4wMTYyMDggLTIwNi4wMzM4ODQgDQpMIDI1MS44NTYzNzQgLTIwNi4wMzM4ODQgDQpMIDI1MS42OTY1NCAtMjA2LjAzMzg4NCANCkwgMjUxLjUzNjcwNiAtMjA2LjAzMzg4NCANCkwgMjUxLjM3Njg3MiAtMjA2LjAzMzg4NCANCkwgMjUxLjIxNzAzOCAtMjA2LjAzMzg4NCANCkwgMjUxLjA1NzIwNCAtMjA2LjAzMzg4NCANCkwgMjUwLjg5NzM3IC0yMDYuMDMzODg0IA0KTCAyNTAuNzM3NTM3IC0yMDYuMDMzODg0IA0KTCAyNTAuNTc3NzAzIC0yMDYuMDMzODg0IA0KTCAyNTAuNDE3ODY5IC0yMDYuMDMzODg0IA0KTCAyNTAuMjU4MDM1IC0yMDYuMDMzODg0IA0KTCAyNTAuMDk4MjAxIC0yMDYuMDMzODg0IA0KTCAyNDkuOTM4MzY3IC0yMDYuMDMzODg0IA0KTCAyNDkuNzc4NTMzIC0yMDYuMDMzODg0IA0KTCAyNDkuNjE4Njk5IC0yMDYuMDMzODg0IA0KTCAyNDkuNDU4ODY2IC0yMDYuMDMzODg0IA0KTCAyNDkuMjk5MDMyIC0yMDYuMDMzODg0IA0KTCAyNDkuMTM5MTk4IC0yMDYuMDMzODg0IA0KTCAyNDguOTc5MzY0IC0yMDYuMDMzODg0IA0KTCAyNDguODE5NTMgLTIwNi4wMzM4ODQgDQpMIDI0OC42NTk2OTYgLTIwNi4wMzM4ODQgDQpMIDI0OC40OTk4NjIgLTIwNi4wMzM4ODQgDQpMIDI0OC4zNDAwMjggLTIwNi4wMzM4ODQgDQpMIDI0OC4xODAxOTQgLTIwNi4wMzM4ODQgDQpMIDI0OC4wMjAzNjEgLTIwNi4wMzM4ODQgDQpMIDI0Ny44NjA1MjcgLTIwNi4wMzM4ODQgDQpMIDI0Ny43MDA2OTMgLTIwNi4wMzM4ODQgDQpMIDI0Ny41NDA4NTkgLTIwNi4wMzM4ODQgDQpMIDI0Ny4zODEwMjUgLTIwNi4wMzM4ODQgDQpMIDI0Ny4yMjExOTEgLTIwNi4wMzM4ODQgDQpMIDI0Ny4wNjEzNTcgLTIwNi4wMzM4ODQgDQpMIDI0Ni45MDE1MjMgLTIwNi4wMzM4ODQgDQpMIDI0Ni43NDE2ODkgLTIwNi4wMzM4ODQgDQpMIDI0Ni41ODE4NTYgLTIwNi4wMzM4ODQgDQpMIDI0Ni40MjIwMjIgLTIwNi4wMzM4ODQgDQpMIDI0Ni4yNjIxODggLTIwNi4wMzM4ODQgDQpMIDI0Ni4xMDIzNTQgLTIwNi4wMzM4ODQgDQpMIDI0NS45NDI1MiAtMjA2LjAzMzg4NCANCkwgMjQ1Ljc4MjY4NiAtMjA2LjAzMzg4NCANCkwgMjQ1LjYyMjg1MiAtMjA2LjAzMzg4NCANCkwgMjQ1LjQ2MzAxOCAtMjA2LjAzMzg4NCANCkwgMjQ1LjMwMzE4NSAtMjA2LjAzMzg4NCANCkwgMjQ1LjE0MzM1MSAtMjA2LjAzMzg4NCANCkwgMjQ0Ljk4MzUxNyAtMjA2LjAzMzg4NCANCkwgMjQ0LjgyMzY4MyAtMjA2LjAzMzg4NCANCkwgMjQ0LjY2Mzg0OSAtMjA2LjAzMzg4NCANCkwgMjQ0LjUwNDAxNSAtMjA2LjAzMzg4NCANCkwgMjQ0LjM0NDE4MSAtMjA2LjAzMzg4NCANCkwgMjQ0LjE4NDM0NyAtMjA2LjAzMzg4NCANCkwgMjQ0LjAyNDUxMyAtMjA2LjAzMzg4NCANCkwgMjQzLjg2NDY4IC0yMDYuMDMzODg0IA0KTCAyNDMuNzA0ODQ2IC0yMDYuMDMzODg0IA0KTCAyNDMuNTQ1MDEyIC0yMDYuMDMzODg0IA0KTCAyNDMuMzg1MTc4IC0yMDYuMDMzODg0IA0KTCAyNDMuMjI1MzQ0IC0yMDYuMDMzODg0IA0KTCAyNDMuMDY1NTEgLTIwNi4wMzM4ODQgDQpMIDI0Mi45MDU2NzYgLTIwNi4wMzM4ODQgDQpMIDI0Mi43NDU4NDIgLTIwNi4wMzM4ODQgDQpMIDI0Mi41ODYwMDggLTIwNi4wMzM4ODQgDQpMIDI0Mi40MjYxNzUgLTIwNi4wMzM4ODQgDQpMIDI0Mi4yNjYzNDEgLTIwNi4wMzM4ODQgDQpMIDI0Mi4xMDY1MDcgLTIwNi4wMzM4ODQgDQpMIDI0MS45NDY2NzMgLTIwNi4wMzM4ODQgDQpMIDI0MS43ODY4MzkgLTIwNi4wMzM4ODQgDQpMIDI0MS42MjcwMDUgLTIwNi4wMzM4ODQgDQpMIDI0MS40NjcxNzEgLTIwNi4wMzM4ODQgDQpMIDI0MS4zMDczMzcgLTIwNi4wMzM4ODQgDQpMIDI0MS4xNDc1MDQgLTIwNi4wMzM4ODQgDQpMIDI0MC45ODc2NyAtMjA2LjAzMzg4NCANCkwgMjQwLjgyNzgzNiAtMjA2LjAzMzg4NCANCkwgMjQwLjY2ODAwMiAtMjA2LjAzMzg4NCANCkwgMjQwLjUwODE2OCAtMjA2LjAzMzg4NCANCkwgMjQwLjM0ODMzNCAtMjA2LjAzMzg4NCANCkwgMjQwLjE4ODUgLTIwNi4wMzM4ODQgDQpMIDI0MC4wMjg2NjYgLTIwNi4wMzM4ODQgDQpMIDIzOS44Njg4MzIgLTIwNi4wMzM4ODQgDQpMIDIzOS43MDg5OTkgLTIwNi4wMzM4ODQgDQpMIDIzOS41NDkxNjUgLTIwNi4wMzM4ODQgDQpMIDIzOS4zODkzMzEgLTIwNi4wMzM4ODQgDQpMIDIzOS4yMjk0OTcgLTIwNi4wMzM4ODQgDQpMIDIzOS4wNjk2NjMgLTIwNi4wMzM4ODQgDQpMIDIzOC45MDk4MjkgLTIwNi4wMzM4ODQgDQpMIDIzOC43NDk5OTUgLTIwNi4wMzM4ODQgDQpMIDIzOC41OTAxNjEgLTIwNi4wMzM4ODQgDQpMIDIzOC40MzAzMjggLTIwNi4wMzM4ODQgDQpMIDIzOC4yNzA0OTQgLTIwNi4wMzM4ODQgDQpMIDIzOC4xMTA2NiAtMjA2LjAzMzg4NCANCkwgMjM3Ljk1MDgyNiAtMjA2LjAzMzg4NCANCkwgMjM3Ljc5MDk5MiAtMjA2LjAzMzg4NCANCkwgMjM3LjYzMTE1OCAtMjA2LjAzMzg4NCANCkwgMjM3LjQ3MTMyNCAtMjA2LjAzMzg4NCANCkwgMjM3LjMxMTQ5IC0yMDYuMDMzODg0IA0KTCAyMzcuMTUxNjU2IC0yMDYuMDMzODg0IA0KTCAyMzYuOTkxODIzIC0yMDYuMDMzODg0IA0KTCAyMzYuODMxOTg5IC0yMDYuMDMzODg0IA0KTCAyMzYuNjcyMTU1IC0yMDYuMDMzODg0IA0KTCAyMzYuNTEyMzIxIC0yMDYuMDMzODg0IA0KTCAyMzYuMzUyNDg3IC0yMDYuMDMzODg0IA0KTCAyMzYuMTkyNjUzIC0yMDYuMDMzODg0IA0KTCAyMzYuMDMyODE5IC0yMDYuMDMzODg0IA0KTCAyMzUuODcyOTg1IC0yMDYuMDMzODg0IA0KTCAyMzUuNzEzMTUxIC0yMDYuMDMzODg0IA0KTCAyMzUuNTUzMzE4IC0yMDYuMDMzODg0IA0KTCAyMzUuMzkzNDg0IC0yMDYuMDMzODg0IA0KTCAyMzUuMjMzNjUgLTIwNi4wMzM4ODQgDQpMIDIzNS4wNzM4MTYgLTIwNi4wMzM4ODQgDQpMIDIzNC45MTM5ODIgLTIwNi4wMzM4ODQgDQpMIDIzNC43NTQxNDggLTIwNi4wMzM4ODQgDQpMIDIzNC41OTQzMTQgLTIwNi4wMzM4ODQgDQpMIDIzNC40MzQ0OCAtMjA2LjAzMzg4NCANCkwgMjM0LjI3NDY0NyAtMjA2LjAzMzg4NCANCkwgMjM0LjExNDgxMyAtMjA2LjAzMzg4NCANCkwgMjMzLjk1NDk3OSAtMjA2LjAzMzg4NCANCkwgMjMzLjc5NTE0NSAtMjA2LjAzMzg4NCANCkwgMjMzLjYzNTMxMSAtMjA2LjAzMzg4NCANCkwgMjMzLjQ3NTQ3NyAtMjA2LjAzMzg4NCANCkwgMjMzLjMxNTY0MyAtMjA2LjAzMzg4NCANCkwgMjMzLjE1NTgwOSAtMjA2LjAzMzg4NCANCkwgMjMyLjk5NTk3NSAtMjA2LjAzMzg4NCANCkwgMjMyLjgzNjE0MiAtMjA2LjAzMzg4NCANCkwgMjMyLjY3NjMwOCAtMjA2LjAzMzg4NCANCkwgMjMyLjUxNjQ3NCAtMjA2LjAzMzg4NCANCkwgMjMyLjM1NjY0IC0yMDYuMDMzODg0IA0KTCAyMzIuMTk2ODA2IC0yMDYuMDMzODg0IA0KTCAyMzIuMDM2OTcyIC0yMDYuMDMzODg0IA0KTCAyMzEuODc3MTM4IC0yMDYuMDMzODg0IA0KTCAyMzEuNzE3MzA0IC0yMDYuMDMzODg0IA0KTCAyMzEuNTU3NDcxIC0yMDYuMDMzODg0IA0KTCAyMzEuMzk3NjM3IC0yMDYuMDMzODg0IA0KTCAyMzEuMjM3ODAzIC0yMDYuMDMzODg0IA0KTCAyMzEuMDc3OTY5IC0yMDYuMDMzODg0IA0KTCAyMzAuOTE4MTM1IC0yMDYuMDMzODg0IA0KTCAyMzAuNzU4MzAxIC0yMDYuMDMzODg0IA0KTCAyMzAuNTk4NDY3IC0yMDYuMDMzODg0IA0KTCAyMzAuNDM4NjMzIC0yMDYuMDMzODg0IA0KTCAyMzAuMjc4Nzk5IC0yMDYuMDMzODg0IA0KTCAyMzAuMTE4OTY2IC0yMDYuMDMzODg0IA0KTCAyMjkuOTU5MTMyIC0yMDYuMDMzODg0IA0KTCAyMjkuNzk5Mjk4IC0yMDYuMDMzODg0IA0KTCAyMjkuNjM5NDY0IC0yMDYuMDMzODg0IA0KTCAyMjkuNDc5NjMgLTIwNi4wMzM4ODQgDQpMIDIyOS4zMTk3OTYgLTIwNi4wMzM4ODQgDQpMIDIyOS4xNTk5NjIgLTIwNi4wMzM4ODQgDQpMIDIyOS4wMDAxMjggLTIwNi4wMzM4ODQgDQpMIDIyOC44NDAyOTQgLTIwNi4wMzM4ODQgDQpMIDIyOC42ODA0NjEgLTIwNi4wMzM4ODQgDQpMIDIyOC41MjA2MjcgLTIwNi4wMzM4ODQgDQpMIDIyOC4zNjA3OTMgLTIwNi4wMzM4ODQgDQpMIDIyOC4yMDA5NTkgLTIwNi4wMzM4ODQgDQpMIDIyOC4wNDExMjUgLTIwNi4wMzM4ODQgDQpMIDIyNy44ODEyOTEgLTIwNi4wMzM4ODQgDQpMIDIyNy43MjE0NTcgLTIwNi4wMzM4ODQgDQpMIDIyNy41NjE2MjMgLTIwNi4wMzM4ODQgDQpMIDIyNy40MDE3OSAtMjA2LjAzMzg4NCANCkwgMjI3LjI0MTk1NiAtMjA2LjAzMzg4NCANCkwgMjI3LjA4MjEyMiAtMjA2LjAzMzg4NCANCkwgMjI2LjkyMjI4OCAtMjA2LjAzMzg4NCANCkwgMjI2Ljc2MjQ1NCAtMjA2LjAzMzg4NCANCkwgMjI2LjYwMjYyIC0yMDYuMDMzODg0IA0KTCAyMjYuNDQyNzg2IC0yMDYuMDMzODg0IA0KTCAyMjYuMjgyOTUyIC0yMDYuMDMzODg0IA0KTCAyMjYuMTIzMTE4IC0yMDYuMDMzODg0IA0KTCAyMjUuOTYzMjg1IC0yMDYuMDMzODg0IA0KTCAyMjUuODAzNDUxIC0yMDYuMDMzODg0IA0KTCAyMjUuNjQzNjE3IC0yMDYuMDMzODg0IA0KTCAyMjUuNDgzNzgzIC0yMDYuMDMzODg0IA0KTCAyMjUuMzIzOTQ5IC0yMDYuMDMzODg0IA0KTCAyMjUuMTY0MTE1IC0yMDYuMDMzODg0IA0KTCAyMjUuMDA0MjgxIC0yMDYuMDMzODg0IA0KTCAyMjQuODQ0NDQ3IC0yMDYuMDMzODg0IA0KTCAyMjQuNjg0NjEzIC0yMDYuMDMzODg0IA0KTCAyMjQuNTI0NzggLTIwNi4wMzM4ODQgDQpMIDIyNC4zNjQ5NDYgLTIwNi4wMzM4ODQgDQpMIDIyNC4yMDUxMTIgLTIwNi4wMzM4ODQgDQpMIDIyNC4wNDUyNzggLTIwNi4wMzM4ODQgDQpMIDIyMy44ODU0NDQgLTIwNi4wMzM4ODQgDQpMIDIyMy43MjU2MSAtMjA2LjAzMzg4NCANCkwgMjIzLjU2NTc3NiAtMjA2LjAzMzg4NCANCkwgMjIzLjQwNTk0MiAtMjA2LjAzMzg4NCANCkwgMjIzLjI0NjEwOSAtMjA2LjAzMzg4NCANCkwgMjIzLjA4NjI3NSAtMjA2LjAzMzg4NCANCkwgMjIyLjkyNjQ0MSAtMjA2LjAzMzg4NCANCkwgMjIyLjc2NjYwNyAtMjA2LjAzMzg4NCANCkwgMjIyLjYwNjc3MyAtMjA2LjAzMzg4NCANCkwgMjIyLjQ0NjkzOSAtMjA2LjAzMzg4NCANCkwgMjIyLjI4NzEwNSAtMjA2LjAzMzg4NCANCkwgMjIyLjEyNzI3MSAtMjA2LjAzMzg4NCANCkwgMjIxLjk2NzQzNyAtMjA2LjAzMzg4NCANCkwgMjIxLjgwNzYwNCAtMjA2LjAzMzg4NCANCkwgMjIxLjY0Nzc3IC0yMDYuMDMzODg0IA0KTCAyMjEuNDg3OTM2IC0yMDYuMDMzODg0IA0KTCAyMjEuMzI4MTAyIC0yMDYuMDMzODg0IA0KTCAyMjEuMTY4MjY4IC0yMDYuMDMzODg0IA0KTCAyMjEuMDA4NDM0IC0yMDYuMDMzODg0IA0KTCAyMjAuODQ4NiAtMjA2LjAzMzg4NCANCkwgMjIwLjY4ODc2NiAtMjA2LjAzMzg4NCANCkwgMjIwLjUyODkzMyAtMjA2LjAzMzg4NCANCkwgMjIwLjM2OTA5OSAtMjA2LjAzMzg4NCANCkwgMjIwLjIwOTI2NSAtMjA2LjAzMzg4NCANCkwgMjIwLjA0OTQzMSAtMjA2LjAzMzg4NCANCkwgMjE5Ljg4OTU5NyAtMjA2LjAzMzg4NCANCkwgMjE5LjcyOTc2MyAtMjA2LjAzMzg4NCANCkwgMjE5LjU2OTkyOSAtMjA2LjAzMzg4NCANCkwgMjE5LjQxMDA5NSAtMjA2LjAzMzg4NCANCkwgMjE5LjI1MDI2MSAtMjA2LjAzMzg4NCANCkwgMjE5LjA5MDQyOCAtMjA2LjAzMzg4NCANCkwgMjE4LjkzMDU5NCAtMjA2LjAzMzg4NCANCkwgMjE4Ljc3MDc2IC0yMDYuMDMzODg0IA0KTCAyMTguNjEwOTI2IC0yMDYuMDMzODg0IA0KTCAyMTguNDUxMDkyIC0yMDYuMDMzODg0IA0KTCAyMTguMjkxMjU4IC0yMDYuMDMzODg0IA0KTCAyMTguMTMxNDI0IC0yMDYuMDMzODg0IA0KTCAyMTcuOTcxNTkgLTIwNi4wMzM4ODQgDQpMIDIxNy44MTE3NTYgLTIwNi4wMzM4ODQgDQpMIDIxNy42NTE5MjMgLTIwNi4wMzM4ODQgDQpMIDIxNy40OTIwODkgLTIwNi4wMzM4ODQgDQpMIDIxNy4zMzIyNTUgLTIwNi4wMzM4ODQgDQpMIDIxNy4xNzI0MjEgLTIwNi4wMzM4ODQgDQpMIDIxNy4wMTI1ODcgLTIwNi4wMzM4ODQgDQpMIDIxNi44NTI3NTMgLTIwNi4wMzM4ODQgDQpMIDIxNi42OTI5MTkgLTIwNi4wMzM4ODQgDQpMIDIxNi41MzMwODUgLTIwNi4wMzM4ODQgDQpMIDIxNi4zNzMyNTIgLTIwNi4wMzM4ODQgDQpMIDIxNi4yMTM0MTggLTIwNi4wMzM4ODQgDQpMIDIxNi4wNTM1ODQgLTIwNi4wMzM4ODQgDQpMIDIxNS44OTM3NSAtMjA2LjAzMzg4NCANCkwgMjE1LjczMzkxNiAtMjA2LjAzMzg4NCANCkwgMjE1LjU3NDA4MiAtMjA2LjAzMzg4NCANCkwgMjE1LjQxNDI0OCAtMjA2LjAzMzg4NCANCkwgMjE1LjI1NDQxNCAtMjA2LjAzMzg4NCANCkwgMjE1LjA5NDU4IC0yMDYuMDMzODg0IA0KTCAyMTQuOTM0NzQ3IC0yMDYuMDMzODg0IA0KTCAyMTQuNzc0OTEzIC0yMDYuMDMzODg0IA0KTCAyMTQuNjE1MDc5IC0yMDYuMDMzODg0IA0KTCAyMTQuNDU1MjQ1IC0yMDYuMDMzODg0IA0KTCAyMTQuMjk1NDExIC0yMDYuMDMzODg0IA0KTCAyMTQuMTM1NTc3IC0yMDYuMDMzODg0IA0KTCAyMTMuOTc1NzQzIC0yMDYuMDMzODg0IA0KTCAyMTMuODE1OTA5IC0yMDYuMDMzODg0IA0KTCAyMTMuNjU2MDc2IC0yMDYuMDMzODg0IA0KTCAyMTMuNDk2MjQyIC0yMDYuMDMzODg0IA0KTCAyMTMuMzM2NDA4IC0yMDYuMDMzODg0IA0KTCAyMTMuMTc2NTc0IC0yMDYuMDMzODg0IA0KTCAyMTMuMDE2NzQgLTIwNi4wMzM4ODQgDQpMIDIxMi44NTY5MDYgLTIwNi4wMzM4ODQgDQpMIDIxMi42OTcwNzIgLTIwNi4wMzM4ODQgDQpMIDIxMi41MzcyMzggLTIwNi4wMzM4ODQgDQpMIDIxMi4zNzc0MDQgLTIwNi4wMzM4ODQgDQpMIDIxMi4yMTc1NzEgLTIwNi4wMzM4ODQgDQpMIDIxMi4wNTc3MzcgLTIwNi4wMzM4ODQgDQpMIDIxMS44OTc5MDMgLTIwNi4wMzM4ODQgDQpMIDIxMS43MzgwNjkgLTIwNi4wMzM4ODQgDQpMIDIxMS41NzgyMzUgLTIwNi4wMzM4ODQgDQpMIDIxMS40MTg0MDEgLTIwNi4wMzM4ODQgDQpMIDIxMS4yNTg1NjcgLTIwNi4wMzM4ODQgDQpMIDIxMS4wOTg3MzMgLTIwNi4wMzM4ODQgDQpMIDIxMC45Mzg4OTkgLTIwNi4wMzM4ODQgDQpMIDIxMC43NzkwNjYgLTIwNi4wMzM4ODQgDQpMIDIxMC42MTkyMzIgLTIwNi4wMzM4ODQgDQpMIDIxMC40NTkzOTggLTIwNi4wMzM4ODQgDQpMIDIxMC4yOTk1NjQgLTIwNi4wMzM4ODQgDQpMIDIxMC4xMzk3MyAtMjA2LjAzMzg4NCANCkwgMjA5Ljk3OTg5NiAtMjA2LjAzMzg4NCANCkwgMjA5LjgyMDA2MiAtMjA2LjAzMzg4NCANCkwgMjA5LjY2MDIyOCAtMjA2LjAzMzg4NCANCkwgMjA5LjUwMDM5NSAtMjA2LjAzMzg4NCANCkwgMjA5LjM0MDU2MSAtMjA2LjAzMzg4NCANCkwgMjA5LjE4MDcyNyAtMjA2LjAzMzg4NCANCkwgMjA5LjAyMDg5MyAtMjA2LjAzMzg4NCANCkwgMjA4Ljg2MTA1OSAtMjA2LjAzMzg4NCANCkwgMjA4LjcwMTIyNSAtMjA2LjAzMzg4NCANCkwgMjA4LjU0MTM5MSAtMjA2LjAzMzg4NCANCkwgMjA4LjM4MTU1NyAtMjA2LjAzMzg4NCANCkwgMjA4LjIyMTcyMyAtMjA2LjAzMzg4NCANCkwgMjA4LjA2MTg5IC0yMDYuMDMzODg0IA0KTCAyMDcuOTAyMDU2IC0yMDYuMDMzODg0IA0KTCAyMDcuNzQyMjIyIC0yMDYuMDMzODg0IA0KTCAyMDcuNTgyMzg4IC0yMDYuMDMzODg0IA0KTCAyMDcuNDIyNTU0IC0yMDYuMDMzODg0IA0KTCAyMDcuMjYyNzIgLTIwNi4wMzM4ODQgDQpMIDIwNy4xMDI4ODYgLTIwNi4wMzM4ODQgDQpMIDIwNi45NDMwNTIgLTIwNi4wMzM4ODQgDQpMIDIwNi43ODMyMTggLTIwNi4wMzM4ODQgDQpMIDIwNi42MjMzODUgLTIwNi4wMzM4ODQgDQpMIDIwNi40NjM1NTEgLTIwNi4wMzM4ODQgDQpMIDIwNi4zMDM3MTcgLTIwNi4wMzM4ODQgDQpMIDIwNi4xNDM4ODMgLTIwNi4wMzM4ODQgDQpMIDIwNS45ODQwNDkgLTIwNi4wMzM4ODQgDQpMIDIwNS44MjQyMTUgLTIwNi4wMzM4ODQgDQpMIDIwNS42NjQzODEgLTIwNi4wMzM4ODQgDQpMIDIwNS41MDQ1NDcgLTIwNi4wMzM4ODQgDQpMIDIwNS4zNDQ3MTQgLTIwNi4wMzM4ODQgDQpMIDIwNS4xODQ4OCAtMjA2LjAzMzg4NCANCkwgMjA1LjAyNTA0NiAtMjA2LjAzMzg4NCANCkwgMjA0Ljg2NTIxMiAtMjA2LjAzMzg4NCANCkwgMjA0LjcwNTM3OCAtMjA2LjAzMzg4NCANCkwgMjA0LjU0NTU0NCAtMjA2LjAzMzg4NCANCkwgMjA0LjM4NTcxIC0yMDYuMDMzODg0IA0KTCAyMDQuMjI1ODc2IC0yMDYuMDMzODg0IA0KTCAyMDQuMDY2MDQyIC0yMDYuMDMzODg0IA0KTCAyMDMuOTA2MjA5IC0yMDYuMDMzODg0IA0KTCAyMDMuNzQ2Mzc1IC0yMDYuMDMzODg0IA0KTCAyMDMuNTg2NTQxIC0yMDYuMDMzODg0IA0KTCAyMDMuNDI2NzA3IC0yMDYuMDMzODg0IA0KTCAyMDMuMjY2ODczIC0yMDYuMDMzODg0IA0KTCAyMDMuMTA3MDM5IC0yMDYuMDMzODg0IA0KTCAyMDIuOTQ3MjA1IC0yMDYuMDMzODg0IA0KTCAyMDIuNzg3MzcxIC0yMDYuMDMzODg0IA0KTCAyMDIuNjI3NTM4IC0yMDYuMDMzODg0IA0KTCAyMDIuNDY3NzA0IC0yMDYuMDMzODg0IA0KTCAyMDIuMzA3ODcgLTIwNi4wMzM4ODQgDQpMIDIwMi4xNDgwMzYgLTIwNi4wMzM4ODQgDQpMIDIwMS45ODgyMDIgLTIwNi4wMzM4ODQgDQpMIDIwMS44MjgzNjggLTIwNi4wMzM4ODQgDQpMIDIwMS42Njg1MzQgLTIwNi4wMzM4ODQgDQpMIDIwMS41MDg3IC0yMDYuMDMzODg0IA0KTCAyMDEuMzQ4ODY2IC0yMDYuMDMzODg0IA0KTCAyMDEuMTg5MDMzIC0yMDYuMDMzODg0IA0KTCAyMDEuMDI5MTk5IC0yMDYuMDMzODg0IA0KTCAyMDAuODY5MzY1IC0yMDYuMDMzODg0IA0KTCAyMDAuNzA5NTMxIC0yMDYuMDMzODg0IA0KTCAyMDAuNTQ5Njk3IC0yMDYuMDMzODg0IA0KTCAyMDAuMzg5ODYzIC0yMDYuMDMzODg0IA0KTCAyMDAuMjMwMDI5IC0yMDYuMDMzODg0IA0KTCAyMDAuMDcwMTk1IC0yMDYuMDMzODg0IA0KTCAxOTkuOTEwMzYxIC0yMDYuMDMzODg0IA0KTCAxOTkuNzUwNTI4IC0yMDYuMDMzODg0IA0KTCAxOTkuNTkwNjk0IC0yMDYuMDMzODg0IA0KTCAxOTkuNDMwODYgLTIwNi4wMzM4ODQgDQpMIDE5OS4yNzEwMjYgLTIwNi4wMzM4ODQgDQpMIDE5OS4xMTExOTIgLTIwNi4wMzM4ODQgDQpMIDE5OC45NTEzNTggLTIwNi4wMzM4ODQgDQpMIDE5OC43OTE1MjQgLTIwNi4wMzM4ODQgDQpMIDE5OC42MzE2OSAtMjA2LjAzMzg4NCANCkwgMTk4LjQ3MTg1NyAtMjA2LjAzMzg4NCANCkwgMTk4LjMxMjAyMyAtMjA2LjAzMzg4NCANCkwgMTk4LjE1MjE4OSAtMjA2LjAzMzg4NCANCkwgMTk3Ljk5MjM1NSAtMjA2LjAzMzg4NCANCkwgMTk3LjgzMjUyMSAtMjA2LjAzMzg4NCANCkwgMTk3LjY3MjY4NyAtMjA2LjAzMzg4NCANCkwgMTk3LjUxMjg1MyAtMjA2LjAzMzg4NCANCkwgMTk3LjM1MzAxOSAtMjA2LjAzMzg4NCANCkwgMTk3LjE5MzE4NSAtMjA2LjAzMzg4NCANCkwgMTk3LjAzMzM1MiAtMjA2LjAzMzg4NCANCkwgMTk2Ljg3MzUxOCAtMjA2LjAzMzg4NCANCkwgMTk2LjcxMzY4NCAtMjA2LjAzMzg4NCANCkwgMTk2LjU1Mzg1IC0yMDYuMDMzODg0IA0KTCAxOTYuMzk0MDE2IC0yMDYuMDMzODg0IA0KTCAxOTYuMjM0MTgyIC0yMDYuMDMzODg0IA0KTCAxOTYuMDc0MzQ4IC0yMDYuMDMzODg0IA0KTCAxOTUuOTE0NTE0IC0yMDYuMDMzODg0IA0KTCAxOTUuNzU0NjgxIC0yMDYuMDMzODg0IA0KTCAxOTUuNTk0ODQ3IC0yMDYuMDMzODg0IA0KTCAxOTUuNDM1MDEzIC0yMDYuMDMzODg0IA0KTCAxOTUuMjc1MTc5IC0yMDYuMDMzODg0IA0KTCAxOTUuMTE1MzQ1IC0yMDYuMDMzODg0IA0KTCAxOTQuOTU1NTExIC0yMDYuMDMzODg0IA0KTCAxOTQuNzk1Njc3IC0yMDYuMDMzODg0IA0KTCAxOTQuNjM1ODQzIC0yMDYuMDMzODg0IA0KTCAxOTQuNDc2MDA5IC0yMDYuMDMzODg0IA0KTCAxOTQuMzE2MTc2IC0yMDYuMDMzODg0IA0KTCAxOTQuMTU2MzQyIC0yMDYuMDMzODg0IA0KTCAxOTMuOTk2NTA4IC0yMDYuMDMzODg0IA0KTCAxOTMuODM2Njc0IC0yMDYuMDMzODg0IA0KTCAxOTMuNjc2ODQgLTIwNi4wMzM4ODQgDQpMIDE5My41MTcwMDYgLTIwNi4wMzM4ODQgDQpMIDE5My4zNTcxNzIgLTIwNi4wMzM4ODQgDQpMIDE5My4xOTczMzggLTIwNi4wMzM4ODQgDQpMIDE5My4wMzc1MDQgLTIwNi4wMzM4ODQgDQpMIDE5Mi44Nzc2NzEgLTIwNi4wMzM4ODQgDQpMIDE5Mi43MTc4MzcgLTIwNi4wMzM4ODQgDQpMIDE5Mi41NTgwMDMgLTIwNi4wMzM4ODQgDQpMIDE5Mi4zOTgxNjkgLTIwNi4wMzM4ODQgDQpMIDE5Mi4yMzgzMzUgLTIwNi4wMzM4ODQgDQpMIDE5Mi4wNzg1MDEgLTIwNi4wMzM4ODQgDQpMIDE5MS45MTg2NjcgLTIwNi4wMzM4ODQgDQpMIDE5MS43NTg4MzMgLTIwNi4wMzM4ODQgDQpMIDE5MS41OTkgLTIwNi4wMzM4ODQgDQpMIDE5MS40MzkxNjYgLTIwNi4wMzM4ODQgDQpMIDE5MS4yNzkzMzIgLTIwNi4wMzM4ODQgDQpMIDE5MS4xMTk0OTggLTIwNi4wMzM4ODQgDQpMIDE5MC45NTk2NjQgLTIwNi4wMzM4ODQgDQpMIDE5MC43OTk4MyAtMjA2LjAzMzg4NCANCkwgMTkwLjYzOTk5NiAtMjA2LjAzMzg4NCANCkwgMTkwLjQ4MDE2MiAtMjA2LjAzMzg4NCANCkwgMTkwLjMyMDMyOCAtMjA2LjAzMzg4NCANCkwgMTkwLjE2MDQ5NSAtMjA2LjAzMzg4NCANCkwgMTkwLjAwMDY2MSAtMjA2LjAzMzg4NCANCkwgMTg5Ljg0MDgyNyAtMjA2LjAzMzg4NCANCkwgMTg5LjY4MDk5MyAtMjA2LjAzMzg4NCANCkwgMTg5LjUyMTE1OSAtMjA2LjAzMzg4NCANCkwgMTg5LjM2MTMyNSAtMjA2LjAzMzg4NCANCkwgMTg5LjIwMTQ5MSAtMjA2LjAzMzg4NCANCkwgMTg5LjA0MTY1NyAtMjA2LjAzMzg4NCANCkwgMTg4Ljg4MTgyNCAtMjA2LjAzMzg4NCANCkwgMTg4LjcyMTk5IC0yMDYuMDMzODg0IA0KTCAxODguNTYyMTU2IC0yMDYuMDMzODg0IA0KTCAxODguNDAyMzIyIC0yMDYuMDMzODg0IA0Keg0KIiBpZD0ibTVlMDk0YWRlYzQiIHN0eWxlPSJzdHJva2U6IzAwMDAwMDtzdHJva2Utb3BhY2l0eTowLjI1OyIvPg0KICAgIDwvZGVmcz4NCiAgICA8ZyBjbGlwLXBhdGg9InVybCgjcDM4ZDdjNjBiNjkpIj4NCiAgICAgPHVzZSBzdHlsZT0iZmlsbDojMzBhMmRhO2ZpbGwtb3BhY2l0eTowLjI1O3N0cm9rZTojMDAwMDAwO3N0cm9rZS1vcGFjaXR5OjAuMjU7IiB4PSIwIiB4bGluazpocmVmPSIjbTVlMDk0YWRlYzQiIHk9IjQzOC40NDI4NSIvPg0KICAgIDwvZz4NCiAgIDwvZz4NCiAgIDxnIGlkPSJtYXRwbG90bGliLmF4aXNfMyI+DQogICAgPGcgaWQ9Inh0aWNrXzkiPg0KICAgICA8ZyBpZD0ibGluZTJkXzI4Ij4NCiAgICAgIDxwYXRoIGNsaXAtcGF0aD0idXJsKCNwMzhkN2M2MGI2OSkiIGQ9Ik0gMTY2LjAyNTU3OCAzOTIuMjQyODUgDQpMIDE2Ni4wMjU1NzggMjMyLjQwODk2NiANCiIgc3R5bGU9ImZpbGw6bm9uZTtzdHJva2U6I2IwYjBiMDtzdHJva2UtbGluZWNhcDpzcXVhcmU7c3Ryb2tlLXdpZHRoOjAuODsiLz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0ibGluZTJkXzI5Ij4NCiAgICAgIDxnPg0KICAgICAgIDx1c2Ugc3R5bGU9InN0cm9rZTojMDAwMDAwO3N0cm9rZS13aWR0aDowLjg7IiB4PSIxNjYuMDI1NTc4IiB4bGluazpocmVmPSIjbTE5MmI3ZGI3NzQiIHk9IjM5Mi4yNDI4NSIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJ0ZXh0XzE3Ij4NCiAgICAgIDwhLS0gMCAtLT4NCiAgICAgIDxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MS41NzE4MjggNDA5Ljg4MDY2MylzY2FsZSgwLjE0IC0wLjE0KSI+DQogICAgICAgPHVzZSB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy00OCIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgPC9nPg0KICAgIDxnIGlkPSJ4dGlja18xMCI+DQogICAgIDxnIGlkPSJsaW5lMmRfMzAiPg0KICAgICAgPHBhdGggY2xpcC1wYXRoPSJ1cmwoI3AzOGQ3YzYwYjY5KSIgZD0iTSAyMjkuOTU5MTMyIDM5Mi4yNDI4NSANCkwgMjI5Ljk1OTEzMiAyMzIuNDA4OTY2IA0KIiBzdHlsZT0iZmlsbDpub25lO3N0cm9rZTojYjBiMGIwO3N0cm9rZS1saW5lY2FwOnNxdWFyZTtzdHJva2Utd2lkdGg6MC44OyIvPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJsaW5lMmRfMzEiPg0KICAgICAgPGc+DQogICAgICAgPHVzZSBzdHlsZT0ic3Ryb2tlOiMwMDAwMDA7c3Ryb2tlLXdpZHRoOjAuODsiIHg9IjIyOS45NTkxMzIiIHhsaW5rOmhyZWY9IiNtMTkyYjdkYjc3NCIgeT0iMzkyLjI0Mjg1Ii8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9InRleHRfMTgiPg0KICAgICAgPCEtLSAyIC0tPg0KICAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjI1LjUwNTM4MiA0MDkuODgwNjYzKXNjYWxlKDAuMTQgLTAuMTQpIj4NCiAgICAgICA8dXNlIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTUwIi8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICA8L2c+DQogICAgPGcgaWQ9Inh0aWNrXzExIj4NCiAgICAgPGcgaWQ9ImxpbmUyZF8zMiI+DQogICAgICA8cGF0aCBjbGlwLXBhdGg9InVybCgjcDM4ZDdjNjBiNjkpIiBkPSJNIDI5My44OTI2ODUgMzkyLjI0Mjg1IA0KTCAyOTMuODkyNjg1IDIzMi40MDg5NjYgDQoiIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlOiNiMGIwYjA7c3Ryb2tlLWxpbmVjYXA6c3F1YXJlO3N0cm9rZS13aWR0aDowLjg7Ii8+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9ImxpbmUyZF8zMyI+DQogICAgICA8Zz4NCiAgICAgICA8dXNlIHN0eWxlPSJzdHJva2U6IzAwMDAwMDtzdHJva2Utd2lkdGg6MC44OyIgeD0iMjkzLjg5MjY4NSIgeGxpbms6aHJlZj0iI20xOTJiN2RiNzc0IiB5PSIzOTIuMjQyODUiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0idGV4dF8xOSI+DQogICAgICA8IS0tIDQgLS0+DQogICAgICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyODkuNDM4OTM1IDQwOS44ODA2NjMpc2NhbGUoMC4xNCAtMC4xNCkiPg0KICAgICAgIDx1c2UgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNTIiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgIDwvZz4NCiAgICA8ZyBpZD0ieHRpY2tfMTIiPg0KICAgICA8ZyBpZD0ibGluZTJkXzM0Ij4NCiAgICAgIDxwYXRoIGNsaXAtcGF0aD0idXJsKCNwMzhkN2M2MGI2OSkiIGQ9Ik0gMzU3LjgyNjIzOSAzOTIuMjQyODUgDQpMIDM1Ny44MjYyMzkgMjMyLjQwODk2NiANCiIgc3R5bGU9ImZpbGw6bm9uZTtzdHJva2U6I2IwYjBiMDtzdHJva2UtbGluZWNhcDpzcXVhcmU7c3Ryb2tlLXdpZHRoOjAuODsiLz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0ibGluZTJkXzM1Ij4NCiAgICAgIDxnPg0KICAgICAgIDx1c2Ugc3R5bGU9InN0cm9rZTojMDAwMDAwO3N0cm9rZS13aWR0aDowLjg7IiB4PSIzNTcuODI2MjM5IiB4bGluazpocmVmPSIjbTE5MmI3ZGI3NzQiIHk9IjM5Mi4yNDI4NSIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJ0ZXh0XzIwIj4NCiAgICAgIDwhLS0gNiAtLT4NCiAgICAgIDxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM1My4zNzI0ODkgNDA5Ljg4MDY2MylzY2FsZSgwLjE0IC0wLjE0KSI+DQogICAgICAgPHVzZSB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy01NCIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgPC9nPg0KICAgIDxnIGlkPSJ4dGlja18xMyI+DQogICAgIDxnIGlkPSJsaW5lMmRfMzYiPg0KICAgICAgPHBhdGggY2xpcC1wYXRoPSJ1cmwoI3AzOGQ3YzYwYjY5KSIgZD0iTSA0MjEuNzU5NzkyIDM5Mi4yNDI4NSANCkwgNDIxLjc1OTc5MiAyMzIuNDA4OTY2IA0KIiBzdHlsZT0iZmlsbDpub25lO3N0cm9rZTojYjBiMGIwO3N0cm9rZS1saW5lY2FwOnNxdWFyZTtzdHJva2Utd2lkdGg6MC44OyIvPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJsaW5lMmRfMzciPg0KICAgICAgPGc+DQogICAgICAgPHVzZSBzdHlsZT0ic3Ryb2tlOiMwMDAwMDA7c3Ryb2tlLXdpZHRoOjAuODsiIHg9IjQyMS43NTk3OTIiIHhsaW5rOmhyZWY9IiNtMTkyYjdkYjc3NCIgeT0iMzkyLjI0Mjg1Ii8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9InRleHRfMjEiPg0KICAgICAgPCEtLSA4IC0tPg0KICAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDE3LjMwNjA0MiA0MDkuODgwNjYzKXNjYWxlKDAuMTQgLTAuMTQpIj4NCiAgICAgICA8dXNlIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTU2Ii8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICA8L2c+DQogICAgPGcgaWQ9Inh0aWNrXzE0Ij4NCiAgICAgPGcgaWQ9ImxpbmUyZF8zOCI+DQogICAgICA8cGF0aCBjbGlwLXBhdGg9InVybCgjcDM4ZDdjNjBiNjkpIiBkPSJNIDQ4NS42OTMzNDYgMzkyLjI0Mjg1IA0KTCA0ODUuNjkzMzQ2IDIzMi40MDg5NjYgDQoiIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlOiNiMGIwYjA7c3Ryb2tlLWxpbmVjYXA6c3F1YXJlO3N0cm9rZS13aWR0aDowLjg7Ii8+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9ImxpbmUyZF8zOSI+DQogICAgICA8Zz4NCiAgICAgICA8dXNlIHN0eWxlPSJzdHJva2U6IzAwMDAwMDtzdHJva2Utd2lkdGg6MC44OyIgeD0iNDg1LjY5MzM0NiIgeGxpbms6aHJlZj0iI20xOTJiN2RiNzc0IiB5PSIzOTIuMjQyODUiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0idGV4dF8yMiI+DQogICAgICA8IS0tIDEwIC0tPg0KICAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDc2Ljc4NTg0NiA0MDkuODgwNjYzKXNjYWxlKDAuMTQgLTAuMTQpIj4NCiAgICAgICA8dXNlIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTQ5Ii8+DQogICAgICAgPHVzZSB4PSI2My42MjMwNDciIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTQ4Ii8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICA8L2c+DQogICAgPGcgaWQ9Inh0aWNrXzE1Ij4NCiAgICAgPGcgaWQ9ImxpbmUyZF80MCI+DQogICAgICA8cGF0aCBjbGlwLXBhdGg9InVybCgjcDM4ZDdjNjBiNjkpIiBkPSJNIDU0OS42MjY4OTkgMzkyLjI0Mjg1IA0KTCA1NDkuNjI2ODk5IDIzMi40MDg5NjYgDQoiIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlOiNiMGIwYjA7c3Ryb2tlLWxpbmVjYXA6c3F1YXJlO3N0cm9rZS13aWR0aDowLjg7Ii8+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9ImxpbmUyZF80MSI+DQogICAgICA8Zz4NCiAgICAgICA8dXNlIHN0eWxlPSJzdHJva2U6IzAwMDAwMDtzdHJva2Utd2lkdGg6MC44OyIgeD0iNTQ5LjYyNjg5OSIgeGxpbms6aHJlZj0iI20xOTJiN2RiNzc0IiB5PSIzOTIuMjQyODUiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0idGV4dF8yMyI+DQogICAgICA8IS0tIDEyIC0tPg0KICAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTQwLjcxOTM5OSA0MDkuODgwNjYzKXNjYWxlKDAuMTQgLTAuMTQpIj4NCiAgICAgICA8dXNlIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTQ5Ii8+DQogICAgICAgPHVzZSB4PSI2My42MjMwNDciIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTUwIi8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICA8L2c+DQogICAgPGcgaWQ9Inh0aWNrXzE2Ij4NCiAgICAgPGcgaWQ9ImxpbmUyZF80MiI+DQogICAgICA8cGF0aCBjbGlwLXBhdGg9InVybCgjcDM4ZDdjNjBiNjkpIiBkPSJNIDYxMy41NjA0NTMgMzkyLjI0Mjg1IA0KTCA2MTMuNTYwNDUzIDIzMi40MDg5NjYgDQoiIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlOiNiMGIwYjA7c3Ryb2tlLWxpbmVjYXA6c3F1YXJlO3N0cm9rZS13aWR0aDowLjg7Ii8+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9ImxpbmUyZF80MyI+DQogICAgICA8Zz4NCiAgICAgICA8dXNlIHN0eWxlPSJzdHJva2U6IzAwMDAwMDtzdHJva2Utd2lkdGg6MC44OyIgeD0iNjEzLjU2MDQ1MyIgeGxpbms6aHJlZj0iI20xOTJiN2RiNzc0IiB5PSIzOTIuMjQyODUiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0idGV4dF8yNCI+DQogICAgICA8IS0tIDE0IC0tPg0KICAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjA0LjY1Mjk1MyA0MDkuODgwNjYzKXNjYWxlKDAuMTQgLTAuMTQpIj4NCiAgICAgICA8dXNlIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTQ5Ii8+DQogICAgICAgPHVzZSB4PSI2My42MjMwNDciIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTUyIi8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICA8L2c+DQogICAgPGcgaWQ9InRleHRfMjUiPg0KICAgICA8IS0tIHogKG0pIC0tPg0KICAgICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODcuNTk3MTg1IDQyNy40MzAwMzgpc2NhbGUoMC4xNCAtMC4xNCkiPg0KICAgICAgPHVzZSB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy0xMjIiLz4NCiAgICAgIDx1c2UgeD0iNTIuNDkwMjM0IiB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy0zMiIvPg0KICAgICAgPHVzZSB4PSI4NC4yNzczNDQiIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTQwIi8+DQogICAgICA8dXNlIHg9IjEyMy4yOTEwMTYiIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTEwOSIvPg0KICAgICAgPHVzZSB4PSIyMjAuNzAzMTI1IiB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy00MSIvPg0KICAgICA8L2c+DQogICAgPC9nPg0KICAgPC9nPg0KICAgPGcgaWQ9Im1hdHBsb3RsaWIuYXhpc180Ij4NCiAgICA8ZyBpZD0ieXRpY2tfNiI+DQogICAgIDxnIGlkPSJsaW5lMmRfNDQiPg0KICAgICAgPHBhdGggY2xpcC1wYXRoPSJ1cmwoI3AzOGQ3YzYwYjY5KSIgZD0iTSAxNjYuMDI1NTc4IDM3NC40ODEzOTkgDQpMIDY0NS41MjcyMyAzNzQuNDgxMzk5IA0KIiBzdHlsZT0iZmlsbDpub25lO3N0cm9rZTojYjBiMGIwO3N0cm9rZS1saW5lY2FwOnNxdWFyZTtzdHJva2Utd2lkdGg6MC44OyIvPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJsaW5lMmRfNDUiPg0KICAgICAgPGc+DQogICAgICAgPHVzZSBzdHlsZT0ic3Ryb2tlOiMwMDAwMDA7c3Ryb2tlLXdpZHRoOjAuODsiIHg9IjE2Ni4wMjU1NzgiIHhsaW5rOmhyZWY9IiNtZTE4NDliNDA1MCIgeT0iMzc0LjQ4MTM5OSIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJ0ZXh0XzI2Ij4NCiAgICAgIDwhLS0g4oiSMC44IC0tPg0KICAgICAgPGRlZnM+DQogICAgICAgPHBhdGggZD0iTSAxMC41OTM3NSAzNS41IA0KTCA3My4xODc1IDM1LjUgDQpMIDczLjE4NzUgMjcuMjAzMTI1IA0KTCAxMC41OTM3NSAyNy4yMDMxMjUgDQp6DQoiIGlkPSJEZWphVnVTYW5zLTg3MjIiLz4NCiAgICAgICA8cGF0aCBkPSJNIDEwLjY4NzUgMTIuNDA2MjUgDQpMIDIxIDEyLjQwNjI1IA0KTCAyMSAwIA0KTCAxMC42ODc1IDAgDQp6DQoiIGlkPSJEZWphVnVTYW5zLTQ2Ii8+DQogICAgICA8L2RlZnM+DQogICAgICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjUuMDI5NjQxIDM3OS44MDAzMDUpc2NhbGUoMC4xNCAtMC4xNCkiPg0KICAgICAgIDx1c2UgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtODcyMiIvPg0KICAgICAgIDx1c2UgeD0iODMuNzg5MDYyIiB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy00OCIvPg0KICAgICAgIDx1c2UgeD0iMTQ3LjQxMjEwOSIgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNDYiLz4NCiAgICAgICA8dXNlIHg9IjE3OS4xOTkyMTkiIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTU2Ii8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICA8L2c+DQogICAgPGcgaWQ9Inl0aWNrXzciPg0KICAgICA8ZyBpZD0ibGluZTJkXzQ2Ij4NCiAgICAgIDxwYXRoIGNsaXAtcGF0aD0idXJsKCNwMzhkN2M2MGI2OSkiIGQ9Ik0gMTY2LjAyNTU3OCAzMzguOTYzMjkxIA0KTCA2NDUuNTI3MjMgMzM4Ljk2MzI5MSANCiIgc3R5bGU9ImZpbGw6bm9uZTtzdHJva2U6I2IwYjBiMDtzdHJva2UtbGluZWNhcDpzcXVhcmU7c3Ryb2tlLXdpZHRoOjAuODsiLz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0ibGluZTJkXzQ3Ij4NCiAgICAgIDxnPg0KICAgICAgIDx1c2Ugc3R5bGU9InN0cm9rZTojMDAwMDAwO3N0cm9rZS13aWR0aDowLjg7IiB4PSIxNjYuMDI1NTc4IiB4bGluazpocmVmPSIjbWUxODQ5YjQwNTAiIHk9IjMzOC45NjMyOTEiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgICA8ZyBpZD0idGV4dF8yNyI+DQogICAgICA8IS0tIOKIkjAuNiAtLT4NCiAgICAgIDxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyNS4wMjk2NDEgMzQ0LjI4MjE5NylzY2FsZSgwLjE0IC0wLjE0KSI+DQogICAgICAgPHVzZSB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy04NzIyIi8+DQogICAgICAgPHVzZSB4PSI4My43ODkwNjIiIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTQ4Ii8+DQogICAgICAgPHVzZSB4PSIxNDcuNDEyMTA5IiB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy00NiIvPg0KICAgICAgIDx1c2UgeD0iMTc5LjE5OTIxOSIgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNTQiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgIDwvZz4NCiAgICA8ZyBpZD0ieXRpY2tfOCI+DQogICAgIDxnIGlkPSJsaW5lMmRfNDgiPg0KICAgICAgPHBhdGggY2xpcC1wYXRoPSJ1cmwoI3AzOGQ3YzYwYjY5KSIgZD0iTSAxNjYuMDI1NTc4IDMwMy40NDUxODMgDQpMIDY0NS41MjcyMyAzMDMuNDQ1MTgzIA0KIiBzdHlsZT0iZmlsbDpub25lO3N0cm9rZTojYjBiMGIwO3N0cm9rZS1saW5lY2FwOnNxdWFyZTtzdHJva2Utd2lkdGg6MC44OyIvPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJsaW5lMmRfNDkiPg0KICAgICAgPGc+DQogICAgICAgPHVzZSBzdHlsZT0ic3Ryb2tlOiMwMDAwMDA7c3Ryb2tlLXdpZHRoOjAuODsiIHg9IjE2Ni4wMjU1NzgiIHhsaW5rOmhyZWY9IiNtZTE4NDliNDA1MCIgeT0iMzAzLjQ0NTE4MyIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgIDxnIGlkPSJ0ZXh0XzI4Ij4NCiAgICAgIDwhLS0g4oiSMC40IC0tPg0KICAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTI1LjAyOTY0MSAzMDguNzY0MDg5KXNjYWxlKDAuMTQgLTAuMTQpIj4NCiAgICAgICA8dXNlIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTg3MjIiLz4NCiAgICAgICA8dXNlIHg9IjgzLjc4OTA2MiIgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNDgiLz4NCiAgICAgICA8dXNlIHg9IjE0Ny40MTIxMDkiIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTQ2Ii8+DQogICAgICAgPHVzZSB4PSIxNzkuMTk5MjE5IiB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy01MiIvPg0KICAgICAgPC9nPg0KICAgICA8L2c+DQogICAgPC9nPg0KICAgIDxnIGlkPSJ5dGlja185Ij4NCiAgICAgPGcgaWQ9ImxpbmUyZF81MCI+DQogICAgICA8cGF0aCBjbGlwLXBhdGg9InVybCgjcDM4ZDdjNjBiNjkpIiBkPSJNIDE2Ni4wMjU1NzggMjY3LjkyNzA3NSANCkwgNjQ1LjUyNzIzIDI2Ny45MjcwNzUgDQoiIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlOiNiMGIwYjA7c3Ryb2tlLWxpbmVjYXA6c3F1YXJlO3N0cm9rZS13aWR0aDowLjg7Ii8+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9ImxpbmUyZF81MSI+DQogICAgICA8Zz4NCiAgICAgICA8dXNlIHN0eWxlPSJzdHJva2U6IzAwMDAwMDtzdHJva2Utd2lkdGg6MC44OyIgeD0iMTY2LjAyNTU3OCIgeGxpbms6aHJlZj0iI21lMTg0OWI0MDUwIiB5PSIyNjcuOTI3MDc1Ii8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9InRleHRfMjkiPg0KICAgICAgPCEtLSDiiJIwLjIgLS0+DQogICAgICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjUuMDI5NjQxIDI3My4yNDU5ODEpc2NhbGUoMC4xNCAtMC4xNCkiPg0KICAgICAgIDx1c2UgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtODcyMiIvPg0KICAgICAgIDx1c2UgeD0iODMuNzg5MDYyIiB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy00OCIvPg0KICAgICAgIDx1c2UgeD0iMTQ3LjQxMjEwOSIgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNDYiLz4NCiAgICAgICA8dXNlIHg9IjE3OS4xOTkyMTkiIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTUwIi8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICA8L2c+DQogICAgPGcgaWQ9Inl0aWNrXzEwIj4NCiAgICAgPGcgaWQ9ImxpbmUyZF81MiI+DQogICAgICA8cGF0aCBjbGlwLXBhdGg9InVybCgjcDM4ZDdjNjBiNjkpIiBkPSJNIDE2Ni4wMjU1NzggMjMyLjQwODk2NiANCkwgNjQ1LjUyNzIzIDIzMi40MDg5NjYgDQoiIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlOiNiMGIwYjA7c3Ryb2tlLWxpbmVjYXA6c3F1YXJlO3N0cm9rZS13aWR0aDowLjg7Ii8+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9ImxpbmUyZF81MyI+DQogICAgICA8Zz4NCiAgICAgICA8dXNlIHN0eWxlPSJzdHJva2U6IzAwMDAwMDtzdHJva2Utd2lkdGg6MC44OyIgeD0iMTY2LjAyNTU3OCIgeGxpbms6aHJlZj0iI21lMTg0OWI0MDUwIiB5PSIyMzIuNDA4OTY2Ii8+DQogICAgICA8L2c+DQogICAgIDwvZz4NCiAgICAgPGcgaWQ9InRleHRfMzAiPg0KICAgICAgPCEtLSAwLjAgLS0+DQogICAgICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzYuNzYxMjAzIDIzNy43Mjc4NzMpc2NhbGUoMC4xNCAtMC4xNCkiPg0KICAgICAgIDx1c2UgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNDgiLz4NCiAgICAgICA8dXNlIHg9IjYzLjYyMzA0NyIgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNDYiLz4NCiAgICAgICA8dXNlIHg9Ijk1LjQxMDE1NiIgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtNDgiLz4NCiAgICAgIDwvZz4NCiAgICAgPC9nPg0KICAgIDwvZz4NCiAgICA8ZyBpZD0idGV4dF8zMSI+DQogICAgIDwhLS0gJEVfeiQgKE1WL20pIC0tPg0KICAgICA8ZGVmcz4NCiAgICAgIDxwYXRoIGQ9Ik0gMTYuODkwNjI1IDcyLjkwNjI1IA0KTCA2Mi45ODQzNzUgNzIuOTA2MjUgDQpMIDYxLjM3NSA2NC41OTM3NSANCkwgMjUuMDkzNzUgNjQuNTkzNzUgDQpMIDIwLjkwNjI1IDQzLjAxNTYyNSANCkwgNTUuNzE4NzUgNDMuMDE1NjI1IA0KTCA1NC4xMDkzNzUgMzQuNzE4NzUgDQpMIDE5LjI4MTI1IDM0LjcxODc1IA0KTCAxNC4yMDMxMjUgOC4yOTY4NzUgDQpMIDUxLjMxMjUgOC4yOTY4NzUgDQpMIDQ5LjcwMzEyNSAwIA0KTCAyLjY4NzUgMCANCnoNCiIgaWQ9IkRlamFWdVNhbnMtT2JsaXF1ZS02OSIvPg0KICAgICAgPHBhdGggZD0iTSAxMS42MjUgNTQuNjg3NSANCkwgNTQuMjk2ODc1IDU0LjY4NzUgDQpMIDUyLjY4NzUgNDYuNDg0Mzc1IA0KTCAxMS41MzEyNSA3LjE3MTg3NSANCkwgNDUuNTE1NjI1IDcuMTcxODc1IA0KTCA0NC4wOTM3NSAwIA0KTCAtMC4yOTY4NzUgMCANCkwgMS4zMTI1IDguMjAzMTI1IA0KTCA0Mi40ODQzNzUgNDcuNTE1NjI1IA0KTCAxMC4yMDMxMjUgNDcuNTE1NjI1IA0Keg0KIiBpZD0iRGVqYVZ1U2Fucy1PYmxpcXVlLTEyMiIvPg0KICAgICAgPHBhdGggZD0iTSA5LjgxMjUgNzIuOTA2MjUgDQpMIDI0LjUxNTYyNSA3Mi45MDYyNSANCkwgNDMuMTA5Mzc1IDIzLjI5Njg3NSANCkwgNjEuODEyNSA3Mi45MDYyNSANCkwgNzYuNTE1NjI1IDcyLjkwNjI1IA0KTCA3Ni41MTU2MjUgMCANCkwgNjYuODkwNjI1IDAgDQpMIDY2Ljg5MDYyNSA2NC4wMTU2MjUgDQpMIDQ4LjA5Mzc1IDE0LjAxNTYyNSANCkwgMzguMTg3NSAxNC4wMTU2MjUgDQpMIDE5LjM5MDYyNSA2NC4wMTU2MjUgDQpMIDE5LjM5MDYyNSAwIA0KTCA5LjgxMjUgMCANCnoNCiIgaWQ9IkRlamFWdVNhbnMtNzciLz4NCiAgICAgIDxwYXRoIGQ9Ik0gMjguNjA5Mzc1IDAgDQpMIDAuNzgxMjUgNzIuOTA2MjUgDQpMIDExLjA3ODEyNSA3Mi45MDYyNSANCkwgMzQuMTg3NSAxMS41MzEyNSANCkwgNTcuMzI4MTI1IDcyLjkwNjI1IA0KTCA2Ny41NzgxMjUgNzIuOTA2MjUgDQpMIDM5Ljc5Njg3NSAwIA0Keg0KIiBpZD0iRGVqYVZ1U2Fucy04NiIvPg0KICAgICAgPHBhdGggZD0iTSAyNS4zOTA2MjUgNzIuOTA2MjUgDQpMIDMzLjY4NzUgNzIuOTA2MjUgDQpMIDguMjk2ODc1IC05LjI4MTI1IA0KTCAwIC05LjI4MTI1IA0Keg0KIiBpZD0iRGVqYVZ1U2Fucy00NyIvPg0KICAgICA8L2RlZnM+DQogICAgIDxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExOC4xMTgwNzggMzQ3LjI1NTkwOClyb3RhdGUoLTkwKXNjYWxlKDAuMTQgLTAuMTQpIj4NCiAgICAgIDx1c2UgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCAwLjEyNSkiIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLU9ibGlxdWUtNjkiLz4NCiAgICAgIDx1c2UgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjMuMTgzNTk0IC0xNi4yODEyNSlzY2FsZSgwLjcpIiB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy1PYmxpcXVlLTEyMiIvPg0KICAgICAgPHVzZSB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDIuNjYxMTMzIDAuMTI1KSIgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtMzIiLz4NCiAgICAgIDx1c2UgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTM0LjQ0ODI0MiAwLjEyNSkiIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTQwIi8+DQogICAgICA8dXNlIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3My40NjE5MTQgMC4xMjUpIiB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy03NyIvPg0KICAgICAgPHVzZSB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNTkuNzQxMjExIDAuMTI1KSIgeGxpbms6aHJlZj0iI0RlamFWdVNhbnMtODYiLz4NCiAgICAgIDx1c2UgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzI4LjE0OTQxNCAwLjEyNSkiIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTQ3Ii8+DQogICAgICA8dXNlIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM2MS44NDA4MiAwLjEyNSkiIHhsaW5rOmhyZWY9IiNEZWphVnVTYW5zLTEwOSIvPg0KICAgICAgPHVzZSB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTkuMjUyOTMgMC4xMjUpIiB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy00MSIvPg0KICAgICA8L2c+DQogICAgPC9nPg0KICAgPC9nPg0KICAgPGcgaWQ9InBhdGNoXzYiPg0KICAgIDxwYXRoIGQ9Ik0gMTY2LjAyNTU3OCAzOTIuMjQyODUgDQpMIDE2Ni4wMjU1NzggMjMyLjQwODk2NiANCiIgc3R5bGU9ImZpbGw6bm9uZTtzdHJva2U6IzAwMDAwMDtzdHJva2UtbGluZWNhcDpzcXVhcmU7c3Ryb2tlLWxpbmVqb2luOm1pdGVyO3N0cm9rZS13aWR0aDowLjg7Ii8+DQogICA8L2c+DQogICA8ZyBpZD0icGF0Y2hfNyI+DQogICAgPHBhdGggZD0iTSAxNjYuMDI1NTc4IDM5Mi4yNDI4NSANCkwgNjQ1LjUyNzIzIDM5Mi4yNDI4NSANCiIgc3R5bGU9ImZpbGw6bm9uZTtzdHJva2U6IzAwMDAwMDtzdHJva2UtbGluZWNhcDpzcXVhcmU7c3Ryb2tlLWxpbmVqb2luOm1pdGVyO3N0cm9rZS13aWR0aDowLjg7Ii8+DQogICA8L2c+DQogICA8ZyBpZD0idGV4dF8zMiI+DQogICAgPCEtLSBCIC0tPg0KICAgIDxkZWZzPg0KICAgICA8cGF0aCBkPSJNIDM4LjM3NSA0NC42NzE4NzUgDQpRIDQyLjgyODEyNSA0NC42NzE4NzUgNDUuMTA5Mzc1IDQ2LjYyNSANClEgNDcuNDA2MjUgNDguNTc4MTI1IDQ3LjQwNjI1IDUyLjM5MDYyNSANClEgNDcuNDA2MjUgNTYuMTU2MjUgNDUuMTA5Mzc1IDU4LjEyNSANClEgNDIuODI4MTI1IDYwLjEwOTM3NSAzOC4zNzUgNjAuMTA5Mzc1IA0KTCAyNy45ODQzNzUgNjAuMTA5Mzc1IA0KTCAyNy45ODQzNzUgNDQuNjcxODc1IA0Keg0KTSAzOS4wMTU2MjUgMTIuNzk2ODc1IA0KUSA0NC42NzE4NzUgMTIuNzk2ODc1IDQ3LjUzMTI1IDE1LjE4NzUgDQpRIDUwLjM5MDYyNSAxNy41NzgxMjUgNTAuMzkwNjI1IDIyLjQwNjI1IA0KUSA1MC4zOTA2MjUgMjcuMTU2MjUgNDcuNTYyNSAyOS41MTU2MjUgDQpRIDQ0LjczNDM3NSAzMS44OTA2MjUgMzkuMDE1NjI1IDMxLjg5MDYyNSANCkwgMjcuOTg0Mzc1IDMxLjg5MDYyNSANCkwgMjcuOTg0Mzc1IDEyLjc5Njg3NSANCnoNCk0gNTYuNSAzOS4wMTU2MjUgDQpRIDYyLjU0Njg3NSAzNy4yNSA2NS44NTkzNzUgMzIuNTE1NjI1IA0KUSA2OS4xODc1IDI3Ljc4MTI1IDY5LjE4NzUgMjAuOTA2MjUgDQpRIDY5LjE4NzUgMTAuMzU5Mzc1IDYyLjA2MjUgNS4xNzE4NzUgDQpRIDU0LjkzNzUgMCA0MC4zNzUgMCANCkwgOS4xODc1IDAgDQpMIDkuMTg3NSA3Mi45MDYyNSANCkwgMzcuNDA2MjUgNzIuOTA2MjUgDQpRIDUyLjU5Mzc1IDcyLjkwNjI1IDU5LjQwNjI1IDY4LjMxMjUgDQpRIDY2LjIxODc1IDYzLjcxODc1IDY2LjIxODc1IDUzLjYwOTM3NSANClEgNjYuMjE4NzUgNDguMjk2ODc1IDYzLjcxODc1IDQ0LjU2MjUgDQpRIDYxLjIzNDM3NSA0MC44MjgxMjUgNTYuNSAzOS4wMTU2MjUgDQp6DQoiIGlkPSJEZWphVnVTYW5zLUJvbGQtNjYiLz4NCiAgICA8L2RlZnM+DQogICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQuNCAyMzYuNDQwNjEyKXNjYWxlKDAuMTggLTAuMTgpIj4NCiAgICAgPHVzZSB4bGluazpocmVmPSIjRGVqYVZ1U2Fucy1Cb2xkLTY2Ii8+DQogICAgPC9nPg0KICAgPC9nPg0KICA8L2c+DQogPC9nPg0KIDxkZWZzPg0KICA8Y2xpcFBhdGggaWQ9InA5NmM3MjQxODUzIj4NCiAgIDxyZWN0IGhlaWdodD0iMTU5LjgzMzg4NCIgd2lkdGg9IjQ3OS41MDE2NTIiIHg9IjE2Ni4wMjU1NzgiIHk9IjI0LjYyNDkxNyIvPg0KICA8L2NsaXBQYXRoPg0KICA8Y2xpcFBhdGggaWQ9InAzOGQ3YzYwYjY5Ij4NCiAgIDxyZWN0IGhlaWdodD0iMTU5LjgzMzg4NCIgd2lkdGg9IjQ3OS41MDE2NTIiIHg9IjE2Ni4wMjU1NzgiIHk9IjIzMi40MDg5NjYiLz4NCiAgPC9jbGlwUGF0aD4NCiA8L2RlZnM+DQo8L3N2Zz4NCg==)
Для дальнейшего использования в решении уравнения на огибающую преобразуем массив gamma в функцию:
gamma = interpolate.interp1d(z[1:], gamma, fill_value=(gamma[0], gamma[-1]), bounds_error=False)
#hv.Curve((z,gamma(z)), kdims=dim_z, vdims=dim_gamma)
Решение уравнения огибающей для круглого пучка
Уравнение огибающей для круглого пучка радиуса \(r\) с распределением Капчинского-Владимирского с внешней фокусировкой линейными полями: $$ \displaystyle r'' + \frac{1}{\beta^2\gamma} \gamma' r' + \frac{1}{2\beta^2\gamma}\gamma''r + kr - \frac{2I}{I_a (\beta\gamma)^3}\frac{1}{r} - \frac{\epsilon^2}{r^3} = 0. $$
Перейдем к среднеквадратичному радиусу для распределения Капчинского-Владимирского и перевеансу \(\displaystyle r_{rms} = \frac{r}{2}\) и \(\displaystyle P = \frac{2I}{I_a\beta^3\gamma^3} \). Получим $$ \displaystyle r_{rms}'' + \frac{1}{\beta^2\gamma} \gamma' r_{rms}' + \frac{1}{2\beta^2\gamma}\gamma''r_{rms} + kr_{rms} - \frac{P}{4r_{rms}} - \frac{\epsilon^2}{16{r_{rms}}^3} = 0. $$
Пусть \(\displaystyle y=\frac{dr_{rms}}{dz}, \displaystyle \frac{d\gamma }{dz}\approx \frac{e E_z}{m c^2}\), тогда $$ \begin{matrix} \displaystyle \frac{dy}{dz}= - \frac{1}{\beta^2\gamma} \gamma' r_{rms}' - \frac{1}{2\beta^2\gamma}\gamma''r_{rms} - kr_{rms} + \frac{P}{4r_{rms}} + \frac{\epsilon^2}{16r_{rms}^3}\\ \displaystyle\frac{dr_{rms}}{dz} = y \end{matrix}. $$ Пусть \(\vec X = \begin{bmatrix} y \ r_{rms} \ \end{bmatrix} \), теперь составим дифференциальное уравнение \(X' = F(X).\)
\(k\) - жесткость соленоида:$$ k = \left ( \frac{eB_z}{2m_ec\beta\gamma} \right )^2 = \left ( \frac{e B_z}{2\beta\gamma\cdot 0.511\cdot 10^6 e \cdot \mathrm{volt}/c} \right )^2 = \left ( \frac{cB_z[\mathrm{T}]}{2\beta\gamma\cdot 0.511\cdot 10^6 \cdot \mathrm{volt}} \right )^2. $$
c = 299792458 # (m/s) скорость света
Зададим начальные условия
I = 2000#2000.000 # A Ток в ускорителе
Ia = 17000 # A Альфвеновский ток
emitt_n = 1.80e-4#1.80e-5 # m нормализованный эммитанс
R_rms = 27.5e-3 #m r_rms пучка
dR_rmsdz = 35.4e-3 #50e-3 dr_rms/dz пучка ## 50/2*sqrt(2) = 35.4
from scipy.integrate import odeint
from scipy.misc import derivative
def dXdz(X, z):
y = X[0]
sigma = X[1]
g = gamma(z)
dgdz = Ez(z)/mc
d2gdz2 = derivative(lambda z:Ez(z),z, dz)/mc
beta = np.sqrt(1-1/(g*g))
K = ( c * Bz(z) / (2*0.511e6))**2
emitt = emitt_n/(g*beta) # m
P=2*I/(Ia*beta*beta*beta*g*g*g)
dydz = P/(4*sigma) + emitt*emitt/(sigma*sigma*sigma*16) - K*sigma/(g*beta)**2 - \
dgdz*y/(beta*beta*g) - d2gdz2*sigma/(2*beta*beta*g)
dsigmadz = y
return [dydz, dsigmadz]
Функция решения уравнения на огибающую пучка:
def find_sigma(z):
X0 = [dR_rmsdz, R_rms]
sol = odeint(dXdz, X0, z, rtol = 0.001) # rtol - относительная точность (по умолчанию rtol = 1.49012e-8)
sigma = sol[:, 1] # m
return sigma # m
%opts Area.Beam [aspect=3 show_grid=True] (color='red' linewidth=1 alpha=0.3)
sigma = find_sigma(z)
dim_sig = hv.Dimension('r_{rms}', label="$r_{rms}$", unit='mm', range=(0,150))
sigma_img = hv.Area((z,sigma*1e3), kdims=[dim_z], vdims=[dim_sig], group='Beam')
sigma_img

Релятивисткая разностная схема для расчета динамики частиц в сложных электрических и магнитных полях
First, we write the main quantities in the difference scheme, then we consider the algorithm.
Basic values
At the initial time \(t\) set Cartesian coordinates of the \(i -\)particles \(\overrightarrow{r_{i}} = (x_i, y_i, z_i)\)nd the initial pulses \(\overrightarrow{p_{i}} = (p_{x_i}, p_{y_i}, p_{z_i})\). Minimum time step is set \(\delta t\).
For convenience, made dimensionless physical quantities (with tilde): \begin{equation} \widetilde{\overrightarrow{r_i}} = \frac{\overrightarrow{r_i}}{c \delta t}, \end{equation} \begin{equation} \widetilde{\overrightarrow{E_i}} = \frac{\overrightarrow{E_i}e}{mc} \delta t, \end{equation} \begin{equation} \widetilde{\overrightarrow{H_i}} = \frac{\overrightarrow{H_i}e}{mc} \delta t, \end{equation} where \(m\) is the speed of light, \(e\) is the particle charge and \(m\) is the particle mass.
Algorithm
Consider the relativistic difference scheme algorithm step by step:
-
Calculation of electric fields \(\overrightarrow{E_i}\) at the points where the particles are.
-
Pulse increment: \begin{equation} \overrightarrow{p_i} = \overrightarrow{p_i} + 2\cdot\overrightarrow{E_i}, \end{equation} where the coefficient means that the increment of the pulse is made for the entire time interval \(2\delta t\).
-
New speeds are calculated by new impulses: \begin{equation} \overrightarrow{v_i} = \frac{\overrightarrow{p_i}}{\gamma_i}, \end{equation} where \(\gamma_i = \sqrt{1 + \overrightarrow{p_i}^2}.\)
-
At new speeds, new coordinates are calculated: \begin{equation} \overrightarrow{r_i} = \overrightarrow{r_i} + 1\cdot\overrightarrow{v_i}, \end{equation} where the coefficient means that the increment of the coordinate is made for the time interval \(\delta t.\)
-
Calculation of magnetic fields \(\overrightarrow{H_i}\) at the new points where the particles are.
-
Calculated velocity values (after rotation in a magnetic field):
\[ b_1 = 1 - \frac{H_i^2}{\gamma_i}, b_2 = 1 + \frac{H_i^2}{\gamma_i}, b_3 = 2\cdot \frac{\overrightarrow{v_i}\cdot\overrightarrow{H_i}}{\gamma_i}, \]
\[ \overrightarrow{f_i} = 2\cdot \frac{\overrightarrow{v_i}\times \overrightarrow{H_i}}{\gamma_i}, \]
\begin{equation} \overrightarrow{v_i} = \frac{\overrightarrow{v_i}b_1 + \overrightarrow{f_i} + \frac{\overrightarrow{H_i}}{\gamma_i}b_3}{b_2}. \end{equation}
-
At new speeds, new coordinates are calculated: \begin{equation} \overrightarrow{r_i} = \overrightarrow{r_i} + 1\cdot\overrightarrow{v_i}, \end{equation} where the coefficient means that the increment of the coordinate is made for the time interval $\delta t.$
-
New impulses are calculated according to the new rates: \begin{equation} \overrightarrow{p_i} = \overrightarrow{v_i}\gamma_i. \end{equation}
One cycle is performed in a time interval \(2\delta t.\)
Python
import redpic as rp
import numpy as np
import holoviews as hv
hv.extension('matplotlib')
import warnings
warnings.filterwarnings('ignore')
rp.__version__
Some plotting options
%output size=100 backend='matplotlib' fig='png' dpi=300
%opts Curve Scatter [aspect=3 show_grid=True]
%opts Curve (linewidth=1 alpha=0.7 color='blue')
%opts Scatter (alpha=0.7 s=0.5)
Define accelerator beamline parameters
acc = rp.accelerator.Accelerator(0.7, 5, 0.01)
# Unique name, z-position [m], Ez [MV/m], Ez(z) profile
acc.add_accel('Acc. 1', 4.096, -1.1, 'Ez.dat')
acc.add_accel('Acc. 2', 5.944, -1.1, 'Ez.dat')
# Unique name, z-position [m], Bz [T], Bz(z) profile
acc.add_solenoid('Sol. 1', 0.450, -0.0580, 'Bz.dat')
acc.add_solenoid('Sol. 2', 0.957, 0.0390, 'Bz.dat')
acc.add_solenoid('Sol. 3', 2.107, 0.0250, 'Bz.dat')
acc.add_solenoid('Sol. 4', 2.907, 0.0440, 'Bz.dat')
acc.add_solenoid('Sol. 5', 3.670, 0.0400, 'Bz.dat')
acc.add_solenoid('Sol. 6', 4.570, 0.0595, 'Bz.dat')
acc.add_solenoid('Sol. 7', 5.470, 0.0590, 'Bz.dat')
acc.compile()
dim_z = hv.Dimension('z', unit='m')
dim_Ez = hv.Dimension('Ez', unit='MV/m', label='$E_z$')
dim_Bz = hv.Dimension('Bz', unit='Gs', label='$B_z$')
z = acc.z
z_Ez = hv.Curve((z, acc.Ez(z)), kdims=dim_z, vdims=dim_Ez)
z_Bz = hv.Curve((z, acc.Bz(z)*1e4), kdims=dim_z, vdims=dim_Bz)
(z_Ez + z_Bz).cols(1)

print(acc)
Accelerator structure.
Solenoids:
[ 0.45 m, -0.058 T, Bz.dat, Sol. 1, 0.0 m, 0.0 rad, 0.0 m, 0.0 rad]
[ 0.957 m, 0.039 T, Bz.dat, Sol. 2, 0.0 m, 0.0 rad, 0.0 m, 0.0 rad]
[ 2.107 m, 0.025 T, Bz.dat, Sol. 3, 0.0 m, 0.0 rad, 0.0 m, 0.0 rad]
[ 2.907 m, 0.044 T, Bz.dat, Sol. 4, 0.0 m, 0.0 rad, 0.0 m, 0.0 rad]
[ 3.67 m, 0.04 T, Bz.dat, Sol. 5, 0.0 m, 0.0 rad, 0.0 m, 0.0 rad]
[ 4.57 m, 0.0595 T, Bz.dat, Sol. 6, 0.0 m, 0.0 rad, 0.0 m, 0.0 rad]
[ 5.47 m, 0.059 T, Bz.dat, Sol. 7, 0.0 m, 0.0 rad, 0.0 m, 0.0 rad]
Accelerating modules:
[ 4.096 m, -1.1 T, Ez.dat, Acc. 1, 0.0 m, 0.0 rad, 0.0 m, 0.0 rad]
[ 5.944 m, -1.1 T, Ez.dat, Acc. 2, 0.0 m, 0.0 rad, 0.0 m, 0.0 rad]
Quadrupoles:
Correctors x:
Correctors y:
Define beam parameters
beam = rp.beam.RadialUniformBeam(
type=rp.constants.electron,
energy = 1.32, # MeV
current = 0.5e3, # A
radius_x = 48e-3, # initial r (m)
radius_y = 48e-3, # initial r (m)
radius_z = 3.5,
radius_xp = 2*35.0e-3, # initial r' (rad)
radius_yp = 2*35.0e-3, # initial r' (rad)
x = 0.0e-3, # horizontal centroid position (m)
xp = 0.0e-3, # horizontal centroid angle (rad)
y = 0, # vertical centroid position (m)
normalized_emittance = 200e-6 # m*rad
)
beam.generate(10_000)
2023-08-31 21:35:33,649 - redpic.beam.base - INFO - Generate a radial-uniform beam with 10000 particles
beam.df
| x | y | z | px | py | pz | |
|---|---|---|---|---|---|---|
| 0 | 0.034491 | -0.010901 | -1.123685 | 0.100578 | -0.031122 | 1.747093 |
| 1 | 0.007980 | -0.003833 | 1.251044 | 0.022404 | -0.010670 | 1.749303 |
| 2 | -0.022694 | -0.010773 | -0.128508 | -0.067049 | -0.031592 | 1.741746 |
| 3 | 0.017086 | 0.014826 | -2.608725 | 0.048956 | 0.043029 | 1.763242 |
| 4 | -0.021815 | 0.015455 | 0.520279 | -0.062786 | 0.044937 | 1.759832 |
| ... | ... | ... | ... | ... | ... | ... |
| 9995 | 0.018885 | 0.028316 | 1.360050 | 0.054502 | 0.082155 | 1.746065 |
| 9996 | -0.021948 | 0.040885 | -2.615462 | -0.064131 | 0.119014 | 1.759089 |
| 9997 | -0.016885 | -0.017578 | 1.473440 | -0.048364 | -0.051265 | 1.740909 |
| 9998 | 0.027568 | -0.014905 | -0.467425 | 0.080297 | -0.042703 | 1.765850 |
| 9999 | 0.035333 | 0.010626 | 0.145074 | 0.103711 | 0.031025 | 1.771395 |
10000 rows × 6 columns
dim_x = hv.Dimension('x', unit='m', range=(-0.1, 0.1))
dim_y = hv.Dimension('y', unit='m', range=(-0.1, 0.1))
dim_z = hv.Dimension('z', unit='m', range=(acc.z_start, acc.z_stop))
dim_px = hv.Dimension('px', unit='MeV/c', label='$p_x$')
dim_py = hv.Dimension('py', unit='MeV/c', label='$p_y$')
beam_x_y = hv.Scatter(beam.df, kdims=[dim_x, dim_y])
beam_z_x = hv.Scatter(beam.df, kdims=[dim_z, dim_x])
beam_x_px = hv.Scatter(beam.df, kdims=[dim_x, dim_px])
beam_y_py = hv.Scatter(beam.df, kdims=[dim_y, dim_py])
WARNING:param.Scatter: Chart elements should only be supplied a single kdim
2023-08-31 21:35:33,772 - param.Scatter - WARNING - Chart elements should only be supplied a single kdim
WARNING:param.Scatter: Chart elements should only be supplied a single kdim
2023-08-31 21:35:33,789 - param.Scatter - WARNING - Chart elements should only be supplied a single kdim
WARNING:param.Scatter: Chart elements should only be supplied a single kdim
2023-08-31 21:35:33,791 - param.Scatter - WARNING - Chart elements should only be supplied a single kdim
WARNING:param.Scatter: Chart elements should only be supplied a single kdim
2023-08-31 21:35:33,801 - param.Scatter - WARNING - Chart elements should only be supplied a single kdim
(beam_x_y + beam_z_x + beam_x_px + beam_y_py).cols(2)

print(beam)
Beam parameters:
Type electron
Distribution radial-uniform
Particles 10000
Current 500.0 A
Energy 1.32 MeV
Total momentum 1.7582483378931433 MeV/c
Rel. factor 3.583175582013202
Radius x 48.0 mm
Radius y 48.0 mm
Radius z 3.5 m
Radius x prime 70.0 mrad
Radius y prime 70.0 mrad
Horizontal centroid position 0.0 mm
Vertical centroid position 0.0 mm
Horizontal centroid angle 0.0 mrad
Vertical centroid angle 0.0 mrad
Normalized emittance x 200.0 mm*mrad
Normalized emittance y 200.0 mm*mrad
Run simulation
rp_sim = rp.solver.Simulation(beam, acc)
rp_sim.track()
z = 4.98 m (99.5 %)
Plot the simulation results
def plot(i):
df = rp_sim.result[i]
rp_z_x = hv.Scatter(df, kdims=[dim_z, dim_x], label='redpic')
return rp_z_x
items = [(i, plot(i)) for i in list(rp_sim.result.keys())]
holomap = hv.HoloMap(items, kdims = ['z'])
hv.output(holomap, widget_location='bottom')
Оптимизация огибающей пучка заряженных частиц с помощью генетического алгоритма
Sometimes it’s useful to use a computer to adjust the envelope.
Genetic algorithms work similarly to natural selection in nature. The basis of the genetic algorithm is the individual, chromosomes (genes), population (set of individuals), the functions of adaptability, selection, crossing and mutation. In practice, everything happens like this: the creation of the first generation, assessment, selection, crossing, mutation, new generation, evaluation, etc. until we get the desired result.
DEAP is a framework for working with genetic algorithms, containing many ready-made tools, the main thing is to know how to use them.
Create a beam and accelerator.
import kenv as kv
beam = kv.Beam(energy=2,
current=2e3,
radius=50e-3,
rp=50e-3,
normalized_emittance=1000e-6)
accelerator = kv.Accelerator(0, 5, 0.01)
Solenoids = [
[ 0.5000, 0.02, 'Bz.dat', 'Sol. 1'],
[ 1.0000, 0.02, 'Bz.dat', 'Sol. 2'],
[ 1.5000, 0.02, 'Bz.dat', 'Sol. 3'],
[ 2.0000, 0.02, 'Bz.dat', 'Sol. 4'],
[ 2.5000, 0.02, 'Bz.dat', 'Sol. 5'],
[ 3.0000, 0.02, 'Bz.dat', 'Sol. 6'],
[ 3.5000, 0.02, 'Bz.dat', 'Sol. 7'],
[ 4.0000, 0.02, 'Bz.dat', 'Sol. 8'],
[ 4.5000, 0.02, 'Bz.dat', 'Sol. 9'],
]
for z0, B0, filename, name in Solenoids:
accelerator.Bz_beamline[name] = kv.Element(z0, B0, filename, name)
accelerator.compile()
simulation = kv.Simulation(beam, accelerator)
simulation.track()
Graphic
matplotlib
import holoviews as hv
hv.extension('matplotlib')
%opts Layout [tight=True]
%output size=150 backend='matplotlib' fig='svg'
%opts Area Curve [aspect=3 show_grid=True]
%opts Area (alpha=0.25)
%opts Curve (alpha=0.5)
%opts Area.Beam [aspect=3 show_grid=True] (color='red' alpha=0.3)
import warnings
warnings.filterwarnings('ignore')
dim_z = hv.Dimension('z', unit='m', range=(accelerator.start, accelerator.stop))
dim_Bz = hv.Dimension('Bz', unit='T', label='Bz', range=(0, 0.1))
dim_Ez = hv.Dimension('Ez', unit='MV/m', label='Ez')
dim_r = hv.Dimension('r', label="Beam r", unit='mm', range=(0, 150))
z_Bz= hv.Area((accelerator.parameter,accelerator.Bz(accelerator.parameter)), kdims=[dim_z], vdims=[dim_Bz])
z_r = hv.Area(((accelerator.parameter,simulation.envelope_x(accelerator.parameter)*1e3)), kdims=[dim_z], vdims=[dim_r], group='Beam')
(z_r+z_Bz).cols(1)

As you can see, the envelope is far from perfect.
Apply the genetic algorithm.
Genetic algorithm
First we construct a model envelope.
import numpy as np
coefficients = np.polyfit([accelerator.start, (accelerator.start+accelerator.stop)/2, accelerator.stop], [0.15, 0.05, 0.03], 2)
envelope_mod = coefficients[0]*accelerator.parameter**2 + coefficients[1]*accelerator.parameter+ coefficients[2]
z_env = hv.Curve((accelerator.parameter, envelope_mod*1e3), kdims=[dim_z], vdims=[dim_r], label='Envelope_mod', group='Beam')
z_env

Connect the necessary libraries.
import random
from deap import creator, base, tools, algorithms
The first step is to create the necessary types. Usually it is fitness and the individual.
creator.create("FitnessMin", base.Fitness, weights=(-1.0,))
creator.create("Individual", list, fitness=creator.FitnessMin)
Next, you need to create a toolkit. To do this, you need to set the basic parameters for our algorithm.
Sol_B = 0.02 # [T] average Bz in the solenoids
Sol_B_max = 0.05 # [T] max Bz
Sol_B_min = 0.005 # [T] min Bz
Sol_Num = 9 # quantity
CXPB = 0.4 # cross chance
MUTPB = 0.6 # Mutation probability
NGEN = 100 # Number of generations
POP = 100 # Number of individuals
toolbox = base.Toolbox()
toolbox.register("attr_float", random.gauss, Sol_B, ((Sol_B_max - Sol_B_min)/2)**2)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_float, n=Sol_Num)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
Create a fitness function.
def evalution_envelope(individual):
for x in range(Sol_Num):
accelerator.Bz_beamline['Sol. %.d'%(x+1)].max_field = individual[x]
accelerator.compile()
simulation = kv.Simulation(beam, accelerator)
simulation.track()
tuple(envelope_mod)
tuple(simulation.envelope_x(accelerator.parameter))
sqerrors = np.sqrt((envelope_mod-simulation.envelope_x(accelerator.parameter))**2)
return sum(sqerrors)/len(accelerator.parameter),
toolbox.register("evaluate", evalution_envelope)
toolbox.register("mate", tools.cxUniform, indpb=MUTPB )
toolbox.register("mutate", tools.mutGaussian, mu=0, sigma=((Sol_B_max - Sol_B_min)/2)**2, indpb=MUTPB)
toolbox.register("select", tools.selTournament, tournsize=NGEN//3)
Logbook.
stats_fit = tools.Statistics(lambda ind: ind.fitness.values)
mstats = tools.MultiStatistics(fitness=stats_fit)
mstats.register("avg", np.mean)
mstats.register("std", np.std)
mstats.register("min", np.min)
mstats.register("max", np.max)
logbook = tools.Logbook()
population = toolbox.population(n=POP)
pop, logbook = algorithms.eaSimple(population, toolbox, cxpb=CXPB, mutpb=MUTPB, ngen=NGEN, stats=mstats, verbose=True)
fitness
--------------------------------------------------------------------------
gen nevals avg gen max min nevals std
0 100 0.0373577 0 0.0408331 0.0337452 100 0.00113532
1 82 0.0348016 1 0.0379858 0.0299872 82 0.00134257
2 69 0.0317311 2 0.0355503 0.0268419 69 0.00158446
3 70 0.0284586 3 0.0310798 0.0258454 70 0.00116153
4 77 0.0262835 4 0.028602 0.0245999 77 0.00073413
5 72 0.0248689 5 0.0268379 0.0234427 72 0.000541174
6 84 0.0237668 6 0.0256165 0.0221611 84 0.00067109
7 73 0.0225147 7 0.0241554 0.0203067 73 0.000610466
8 88 0.0210856 8 0.0235622 0.0194378 88 0.000755119
9 80 0.0197334 9 0.0209437 0.0190342 80 0.000337098
10 81 0.0191692 10 0.0204253 0.0183268 81 0.00035722
11 75 0.0185557 11 0.019661 0.0178986 75 0.000283725
12 78 0.0181075 12 0.0190688 0.0175483 78 0.00029574
13 72 0.0177022 13 0.018703 0.0172446 72 0.000248748
14 75 0.0174452 14 0.0183427 0.0169873 75 0.000190804
15 70 0.017232 15 0.0178082 0.0169012 70 0.000181106
16 79 0.0170371 16 0.0180127 0.0167734 79 0.000208848
17 80 0.0168772 17 0.0176019 0.0165999 80 0.000167511
18 80 0.0167085 18 0.0175836 0.0164198 80 0.000174468
19 77 0.0165316 19 0.0171106 0.0162831 77 0.000152431
20 76 0.0163782 20 0.0168837 0.0160568 76 0.000171506
21 69 0.0161959 21 0.0170411 0.015828 69 0.000194345
22 77 0.0159477 22 0.0166562 0.0156399 77 0.000157436
23 79 0.0158229 23 0.0184114 0.0155106 79 0.000314105
24 80 0.0156802 24 0.0167603 0.0153466 80 0.000234712
25 72 0.0154841 25 0.0165787 0.0152393 72 0.000184083
26 74 0.0153536 26 0.0160787 0.0150713 74 0.000201229
27 83 0.0152175 27 0.0160113 0.0147709 83 0.000237473
28 79 0.0149943 28 0.0159486 0.014535 79 0.00027873
29 80 0.0147364 29 0.0155165 0.0143068 80 0.000219007
30 78 0.0145096 30 0.0155232 0.01421 78 0.000219074
31 76 0.0143674 31 0.0162176 0.0141153 76 0.000292944
32 77 0.0142465 32 0.0154183 0.0139755 77 0.000228094
33 74 0.0141755 33 0.016872 0.0137429 74 0.000370584
34 65 0.0140263 34 0.0165405 0.0135535 65 0.000369079
35 79 0.0138775 35 0.0165023 0.0134757 79 0.000469816
36 78 0.0136499 36 0.0165048 0.0132913 78 0.00036574
37 77 0.0135281 37 0.0162187 0.0131399 77 0.000370037
38 72 0.0133894 38 0.0161935 0.013018 72 0.000407104
39 74 0.0132855 39 0.0151958 0.0129085 74 0.000356725
40 73 0.0132202 40 0.0158132 0.0127831 73 0.000502361
41 78 0.0131469 41 0.0154469 0.0126621 78 0.000549534
42 72 0.0128525 42 0.0153473 0.0125449 72 0.000371909
43 81 0.0128408 43 0.0143709 0.0124426 81 0.00037498
44 80 0.0128018 44 0.0143546 0.0122802 80 0.00042712
45 76 0.0126884 45 0.0149749 0.0122105 76 0.000484442
46 74 0.0124913 46 0.0141759 0.0121807 74 0.000374844
47 84 0.0124814 47 0.0150409 0.012149 84 0.000478495
48 65 0.012378 48 0.0143345 0.0120466 65 0.000396209
49 77 0.0123797 49 0.0141054 0.0119723 77 0.000465145
50 66 0.0122275 50 0.0136186 0.0119299 66 0.000324548
51 77 0.0122757 51 0.0142704 0.0118622 77 0.000472376
52 74 0.0121928 52 0.0138265 0.0118082 74 0.000460488
53 73 0.0121423 53 0.0145869 0.0117309 73 0.000487374
54 70 0.0120654 54 0.0132641 0.0116092 70 0.000405956
55 77 0.012012 55 0.0137579 0.0115895 77 0.00050723
56 73 0.0118692 56 0.0141939 0.0115563 73 0.000437811
57 83 0.0118798 57 0.0139667 0.0114851 83 0.000426248
58 71 0.0117967 58 0.01344 0.0114796 71 0.000419319
59 72 0.0117301 59 0.0145933 0.0114334 72 0.000445674
60 78 0.0116524 60 0.0135045 0.0113808 78 0.000333071
61 78 0.0116611 61 0.0132638 0.0113299 78 0.000437407
62 78 0.0116445 62 0.0140102 0.0113001 78 0.000467812
63 80 0.0116662 63 0.0138093 0.0112541 80 0.000496356
64 78 0.0115682 64 0.0126411 0.0112403 78 0.000360796
65 73 0.0115044 65 0.0133941 0.0112293 73 0.000428872
66 81 0.0114277 66 0.0134346 0.0112152 81 0.000315043
67 72 0.0114574 67 0.0132544 0.0111495 72 0.000390321
68 81 0.0114764 68 0.0135241 0.0110932 81 0.000486222
69 75 0.011434 69 0.0132443 0.0110874 75 0.000469529
70 74 0.0113903 70 0.0129446 0.0109944 74 0.000420948
71 80 0.0112841 71 0.0132937 0.0109944 80 0.000408004
72 75 0.0112891 72 0.0133998 0.010978 75 0.000465794
73 79 0.0112265 73 0.0122116 0.0109464 79 0.00029769
74 80 0.0112526 74 0.0129213 0.0108979 80 0.000417258
75 71 0.0112418 75 0.0128844 0.0108979 71 0.000447559
76 73 0.0111925 76 0.0138475 0.0108402 73 0.000519714
77 78 0.0111465 77 0.0132176 0.010835 78 0.000422602
78 79 0.0112091 78 0.0133698 0.0107964 79 0.000558782
79 73 0.0110862 79 0.0131931 0.0107964 73 0.000465272
80 67 0.011036 80 0.0127483 0.0107964 67 0.000386788
top = tools.selBest(pop, k=10)
gen = np.array(logbook.select("gen"))
fit_min = np.array(logbook.chapters["fitness"].select("min"))
fit_max = np.array(logbook.chapters["fitness"].select("max"))
fit_avg = np.array(logbook.chapters["fitness"].select("avg"))
for x in range(Sol_Num):
accelerator.Bz_beamline['Sol. %.d'%(x+1)].max_field = top[0][x]
accelerator.compile()
simulation = kv.Simulation(beam, accelerator)
simulation.track()
z_Bz_gen= hv.Area((accelerator.parameter,accelerator.Bz(accelerator.parameter)), kdims=[dim_z], vdims=[dim_Bz])
z_r_gen = hv.Area(((accelerator.parameter,simulation.envelope_x(accelerator.parameter)*1e3)), kdims=[dim_z], vdims=[dim_r], group='Beam')
(z_r_gen*z_env+z_Bz_gen).cols(1)

Коррекция равновесной орбиты в ускорителе заряженных частиц с применением матрицы отклика и нейронных сетей
Резюме
Литература
[1] Lawson John David. The physics of charged-particle beams. — 1977
[2] SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python / Pauli Virtanen, Ralf Gommers, Travis E. Oliphant et al. // Nature Methods. — 2020. — Vol. 17. — P. 261–272.
[3] Ivanov AV, Tiunov MA. ULTRASAM-2D code for simulation of electron guns with ultra high precision // Proceeding of EPAC-2002, Paris. — 2002. — P. 1634–1636.
[4] Fedorov VV, Nikiforov DA, Petrenko AV. KENV Kapchinsky Envelope code. — 2019. — https://github.com/fuodorov/kenv.
[5] Deap: A python framework for evolutionary algorithms / Fran¸coisMichel De Rainville, F´elix-Antoine Fortin, Marc-Andr´e Gardner et al. // Proceedings of the 14th annual conference companion on Genetic and evolutionary computation. — 2012. — P. 85–92.
[6] Федоров В. В., Никифоров Д. А., Петренко А. В. KENV, Свидетельство о государственной регистрации программы для ЭВМ № 2024611244 от 18.01.2024. — 2024. — URL: https://fips.ru/EGD/ f842405a-9bc0-422f-8c1e-c945356a93f9.
[7] Никифоров Д. А. Исследование динамики пучка электронов в мощном линейном индукционном ускорителе с фокусировкой на сосредоточен- 39 ных элементах : Дисс. . . кандидата наук ; ИЯФ СО РАН. — 2023. — С. 1–94. — URL: https://inp.nsk.ru/images/Nikiforov_disser.pdf.
[8] High-current electron-beam transport in the LIA-5 Linear Induction Accelerator / DA Nikiforov, MF Blinov, VV Fedorov et al. // Physics of Particles and Nuclei Letters. — 2020. — Vol. 17. — P. 197–203.
[9] High Current Electron Beam Transport and Focusing at the Linear Induction Accelerator / S.L. Sinitsky, E.S. Sandalov, D.I. Skovorodin et al. // 2020 IEEE International Conference on Plasma Science (ICOPS). — 2020. — P. 191–191.
[10] Investigation of high current electron beam dynamics in linear induction accelerator for creation of a high-power THz radiation source / D.A. Nikiforov, A.V. Petrenko, S.L. Sinitsky et al. // Journal of Instrumentation. — 2021. — nov. — Vol. 16, no. 11. — P. P11024. — URL: https://dx.doi.org/10.1088/1748-0221/16/11/P11024.
[11] Logatchev Pavel, Malyutin Dmitriy, Starostenko A. Application of a lowenergy electron beam as a tool of nondestructive diagnostics of intense charged-particle beams // Instruments and Experimental Techniques. — 2011. — 01. — Vol. 51. — P. 1–27.
[12] Martin Robert C. Clean architecture. — 2017.
[13] Shalloway Alan, Trott James R. Design patterns explained: A new perspective on object-oriented design, 2/E. — Pearson Education India, 2005.
[14] Meyer Bertrand. Object-oriented software construction. — Prentice hall Englewood Cliffs, 1997. — Vol. 2. 40
[15] UnitTest Unit testing framework. — URL: https://docs.python.org/ 3/library/unittest.html (online; accessed: 2024-01-01).
[16] PyTest helps you write better programs. — URL: https://github.com/ pytest-dev/pytest/ (online; accessed: 2024-01-01).
[17] Hodges Jr JL. The significance probability of the Smirnov two-sample test // Arkiv f¨or matematik. — 1958. — Vol. 3, no. 5. — P. 469–486.
[18] Merkel Dirk et al. Docker: lightweight linux containers for consistent development and deployment // Linux j. — 2014. — Vol. 239, no. 2. — P. 2.
[19] GitHub Actions is generally available. — URL: https://github.blog/ changelog/2019-11-11-github-actions-is-generally-available/ (online; accessed: 2024-01-01).
[20] Flake8 is a python tool that glues together pycodestyle, pyflakes, mccabe, and third-party plugins to check the style and quality of some python code. — URL: https://github.com/PyCQA/flake8 (online; accessed: 2024-01-01).
[21] PyLint It’s not just a linter that annoys you! — URL: https://github. com/pylint-dev/pylint (online; accessed: 2024-01-01).
[22] Numba A Just-In-Time Compiler for Numerical Functions in Python. — URL: https://github.com/numba/numba (online; accessed: 2024-01- 01).
[23] Fedorov VV, Nikiforov DA. REDPIC Relativistic Difference Scheme Particles-In-Cell. — 2020. — https://github.com/fuodorov/redpic.
[24] Федоров В. В., Никифоров Д. А. REDPIC, Свидетельство о государственной регистрации программы для ЭВМ 41 № 2023688768 от 25.12.2023. — 2023. — URL: https://fips.ru/ EGD/4182c66d-0ac9-4330-af31-cb2154704aa9.
О себе
Меня зовут Федоров Вячеслав Васильевич, я опытный разработчик программного обеспечения с глубокими знаниями в области физики и вычислительной математики. На протяжении нескольких лет я работаю в Институте ядерной физики им. Будкера, где занимаюсь разработкой наукоемкого прикладного программного обеспечения на языках высокого уровня Python и C++ для решения различных задач. Моя основная работа сосредоточена на моделировании динамики заряженных частиц в сложных электромагнитных полях, а также на внедрении алгоритмов машинного обучения для оптимизации и настройки ускорительных комплексов.
Мой опыт также включает работу в международной компании по разработке ПО и веб-приложений SIBERS, где я руководил командой разработчиков в создании ПО на основе микросервисной архитектуры для государственной организации, оказывающей финансовые услуги. Я активно участвовал в разработке дополнительных модулей для статического анализа кода для различных сред разработки, а также был ведущим разработчиком приложения для врачей, предназначенного для распознавания и присвоения кодов болезней в медицинских картах пациентов с использованием бессерверных вычислений и алгоритмов машинного обучения. Я внедрял процессы автоматизированного тестирования, непрерывной интеграции и доставки кода, проводил обзор и оценку кода, а также подготовил и прочитал полугодовой обучающий курс «Микросервисные масштабируемые веб-сайты» для команды.
Ранее я принимал участие в проектах Роскосмоса, в том числе в разработке ПО на языке C++ для инфракрасного датчика горизонта с использованием платформы Arduino для сверхмалого космического аппарата НГУ «Норби», успешный запуск которого состоялся в 2020 году.
У меня есть диплом бакалавра НГУ в области физики пучков заряженных частиц и физики ускорителей. Я прошёл курсы повышения квалификации по разработке и эксплуатации ПО на Python и C++, алгоритмам и структурам данных, системному администрированию и обеспечению надёжности информационных систем от «Образовательных технологий Яндекса», а также основы искусственного интеллекта и машинного обучения от НГУ.
Мои технические навыки включают: отличное владение языками программирования Python и C++, разнообразными фреймворками; работу с асинхронным и параллельным кодом; проектирование ПО, веб-приложений и микросервисов; создание документации; работу с реляционными базами данных и NoSQL-хранилищами; управление очередями сообщений и задач; владение методологиями непрерывной интеграции и доставки кода, автоматизации процессов сборки, настройки и развёртывания ПО. Мой опыт позволяет ускорять процессы производства IT-продуктов за счёт поиска и устранения «узких» мест, автоматизировать процесс разработки и развёртывания приложений, контейнеризировать приложения и размещать их в облачных сервисах. Я использую актуальные инструменты для обеспечения качества, скорости и стабильности приложений, управляю инфраструктурой в парадигме Infrastructure as Code, сокращая время команды на развёртывание и масштабирование, а также налаживаю коммуникацию между участниками процесса разработки продукта: службой эксплуатации, разработчиками, заказчиками от бизнеса и многими другими.