Async python
Нам предстоит погрузиться в мир асинхронного программирования. Сейчас уже сложно представить Python без асинхронного подхода — он только набирает популярность среди веб-разработчиков.
Итераторы
Разработчики используют итераторы в коде настолько часто, что даже не задумываются, в чём они помогают. Итераторы в Python — это списки, словари, множества, строки, файлы и другие коллекции. Везде, где вы пишете цикл for, используется итератор. Итераторы помогают перемещаться по объектам любого контейнера в коде. При этом вам не нужно задумываться о том, как хранятся и обрабатываются эти элементы: итератор инкапсулирует их. Проще говоря, это способ вычитывать элементы из объекта по одному.
Перейдём сразу к практике. Представим, что на собеседовании вас попросили реализовать аналог функции range.
class Range:
def __init__(self, stop_value: int):
self.current = -1
self.stop_value = stop_value - 1
def __iter__(self):
return RangeIterator(self)
class RangeIterator:
def __init__(self, container):
self.container = container
def __next__(self):
if self.container.current < self.container.stop_value:
self.container.current += 1
return self.container.current
raise StopIteration
Получили первую версию работающего кода. Запустим код и убедимся в этом.
_range = Range(5)
for i in _range:
print(i)
0
1
2
3
4
«А как это работает? Расскажите подробнее»
Начнём с класса Range. У него внутри реализован магический метод __iter__. Он обозначает, что объект этого класса итерабельный, то есть с ним можно работать в цикле for. Ещё говорят, что __iter__ отдаёт итерируемый объект.
Ограничимся понятиями итератора и итерабельного объекта. Чтобы код действительно отдавал новые данные из range, нужно реализовать соответствующую функцию. Она как раз и называется итератор. RangeIterator — итератор для класса range. Любой итератор должен реализовывать магическую функцию __next__, в которой он должен отдавать новые значения для объектов класса Range. Если вы дошли до конца множества значений, то появляется исключение StopIteration.
Для тех, кто привык читать первоисточники, существует PEP-234 (на английском). Там подробно изложена работа итераторов и итерабельных объектов.
Но можно ли как-то упростить написанный выше код? Да, можно.
class Range2:
def __init__(self, stop_value: int):
self.current = -1
self.stop_value = stop_value - 1
def __iter__(self):
return self
def __next__(self):
if self.current < self.stop_value:
self.current += 1
return self.current
raise StopIteration
В Python есть возможность объявить объекты класса и итерабельными, и итераторами. Это удобно, но с точки зрения принципов проектирования приложения, у такого объекта есть две ответственности: он является итератором и при этом выполняет какую-то свою логику. В мире Python это допустимо, но в некоторых других языках вас могут понять неправильно. Будьте бдительны!
Ещё стоит рассмотреть, как работает цикл for под капотом.
iterable = Range2(5)
iterator = iter(iterable)
while True:
try:
value = next(iterator)
print(value)
except StopIteration:
break
0
1
2
3
4
Генераторы
Работа генераторов построена на принципе запоминания контекста выполнения функции. Если не вдаваться в подробности работы Python-интерпретатора, то функция-генератор «запоминает», на каком месте она остановилась, и может продолжить своё выполнение после ключевого слова yield.
Рассмотрим простой пример.
def simple_generator():
yield 1
yield 2
return 3
Посмотрим, что будет, если вызвать такой код:
gen = simple_generator()
print(next(gen))
print(next(gen))
print(next(gen))
1
2
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
Cell In[7], line 4
2 print(next(gen))
3 print(next(gen))
----> 4 print(next(gen))
StopIteration: 3
То есть функция действительно запоминает, где она остановилась после каждого вызова функции next.
Генераторы удобны и для создания генераторных выражений — generator expressions. Особенно это полезно, если нужно сгенерировать много объектов, а память расходовать жалко. Код выглядит так:
gen_exp = (x for x in range(100000))
print(gen_exp)
<generator object <genexpr> at 0x7dbe33f1dfc0>
Есть ещё небольшой синтаксический сахар, связанный с генераторами. Представим функцию, внутри которой есть цикл по элементам списка, и они выводятся один за другим.
numbers = [1, 2, 3]
def func():
for item in numbers:
yield item
for item in func():
print(item)
1
2
3
За счёт генератора конструкция сокращается до такой:
def func():
yield from numbers
Бывает очень полезно, но на практике используется довольно редко.
Корутины
Затронем тему корутин — основных строительных блоков асинхронного программирования на Python. Они появились в ответ на невозможность использования полноценного распараллеливания программы с помощью тредов (потоков) из-за работы GIL. Для тех, кому интересно узнать подробнее про Global Interpreter Lock, есть хорошая обзорная статья.
Корутина — это генератор. Однако в PEP-342 предложили расширить возможности генераторов, добавив туда несколько конструкций, о которых сейчас пойдёт речь.
Представьте себе метод, который на вход получает какое-то значение, как-то его обрабатывает и отдаёт результат. Пусть это будет функция, рассчитывающая количество денег на вашем счете через $N$ лет при определённом проценте. На вход функция принимает процент по депозиту в годовых и сумму на счёте.
import math
def cash_return(deposit: int, percent: float, years: int) -> float:
value = math.pow(1 + percent / 100, years)
return round(deposit * value, 2)
Теперь узнаем, сколько вы получите денег через $5$ лет, если сумма на депозите — $1 000 000$ рублей, а ставка по депозиту — $5%%$ годовых.
cash_return(1_000_000, 5, 5)
1276281.56
Теперь вы хотите посмотреть на то, как будет меняться итоговая сумма в зависимости от депозита. Тут приходит на помощь корутина.
import math
def cash_return_coro(percent: float, years: int) -> float:
value = math.pow(1 + percent / 100, years)
while True:
try:
deposit = (yield)
yield round(deposit * value, 2)
except GeneratorExit:
print('Выход из корутины')
raise
Запустим корутину с теми же условиями — $5$ лет и $5%%$ годовых.
coro = cash_return_coro(5, 5)
next(coro)
values = [1000, 2000, 5000, 10000, 100000]
for item in values:
print(coro.send(item))
next(coro)
coro.close()
1276.28
2552.56
6381.41
12762.82
127628.16
Выход из корутины
Разберёмся, что произошло. В коде видно четыре новых конструкции: (yield), send(...), close() и GeneratorExit. Корутины могут не только отдавать значения и запоминать место, где остановился код, но и ждать новых значений. Для этого ввели конструкцию (yield), которая позволяет принимать набор параметров. Так как приём параметров в корутине происходит необычным способом, то и отправка параметров сделана с помощью специальной функции send(...), через которую можно передать в функцию необходимые параметры. В конце ещё можно вызвать метод close(), который прекратит выполнение корутины. Когда вы вызываете метод close(), выбрасывается исключение GeneratorExit, которое можно перехватить и грамотно обработать.
Ещё одно преимущество — возможность запомнить контекст выполнения. В функции cash_return_coro нет необходимости вычислять переменную value каждый раз, когда вы хотите посчитать сумму. Недостатком такого подхода можно назвать большее количество кода, который надо написать, чтобы всё могло грамотно работать.
Асинхронное программирование
Асинхронное программирование в мире Python-разработки на пике популярности. Про него пишут статьи и делают доклады на конференциях. Концепция уже прижилась и во многих других популярных языках. Давайте восполним пробелы и погрузимся в работу с асинхронным кодом на Python.
Работа с разными типами задач
Раньше разработчики не сильно заостряли своё внимание на типе выполняемых задач внутри приложения — это было не нужно для индустрии в целом. Все писали достаточно большие монолитные приложения, а проблемы с производительностью обычно решались на уровне горизонтального масштабирования: через потоки, процессы или даже через несколько приложений на разных виртуальных машинах.
Сейчас использование только процессов и потоков не даёт нужной производительности. Рассмотрим три основных типа задач, с которыми сталкивается большинство разработчиков:
-
CPU bound-задачи. Задачи, для которых необходимо интенсивное использование процессора. К ним относят использование сложных математических моделей, обучение нейронных сетей, рендеринг графики и вычисление хэшей.
-
I/O bound-задачи (non-RAM I/O bound). Задачи, в которых основная часть работы приходится на ввод/вывод информации I/O или input/output. В основном такие задачи относятся к работе с файловой системой и с сетью.
-
Memory bound-задачи (RAM I/O bound). Задачи, в которых происходит интенсивная работа с оперативной памятью. Как правило, такие задачи появляются в сложных математических моделях. Из-за медленной работы с оперативной памятью всё больше моделей обрабатывают с помощью видеокарт, в которых работа с памятью устроена по-другому. Другой пример — обработка огромного объёма данных в Map-Reduce-системах, например, таких как Spark. Обработка будет идти быстрее, если оперативной памяти будет больше.
Подробнее об этом можно прочитать в англоязычных статьях: - о значении терминов CPU bound и I/O bound, - о производительности.
Из-за массового перехода на микросервисы количество сетевого взаимодействия между системами многократно возросло, как и нагрузка на базы данных. Проблемы работы с сетью или с доступом к БД относятся к I/O bound-задачам. То есть их основная работа — ожидание обработки запроса к внешней системе. Такой класс задач в монолитных системах решался пулом потоков — thread pool. Однако, его стало не хватать из-за достаточно интенсивной нагрузки на сеть между множеством сервисов.
Классический метод решения I/O bound задач — добавление ресурсов к существующим системам. Однако, многие компании не могут позволить себе «заливать всё железом» — докупать новые железные серверы, вместо оптимизации кода. Например, Instagram может себе такое позволить, поэтому они до сих пор используют Django даже с учётом всей нагрузки.
Перейдём к практике. Представьте приложение, которое ходит на некий сайт-агрегатор, достаёт данные по фильмам и сохраняет в БД. Код будет выглядеть так (ссылка на сайт выдуманная):
import requests
def do_some_logic(data):
pass
def save_to_database(data):
pass
data = requests.get('https://data.aggregator.com/films')
processed_data = do_some_logic(data)
save_to_database(data)
Этот код достаточно линейный. Если вместо загрузки фильмов в БД такой код будет выполнять отдачу данных о фильмах с этого же сайта, то при достаточной нагрузке приложение начнёт сильно проседать по скорости ответа клиентам. При этом бо́льшую часть времени код будет просто ждать запроса от клиента, делать запрос к сайту https://data.aggregator.com/films и отдавать данные. То есть в эти моменты интерпретатор не будет делать никаких полезных действий, а клиенты будут ждать.
Схематично изобразить выполнение программы можно вот так:
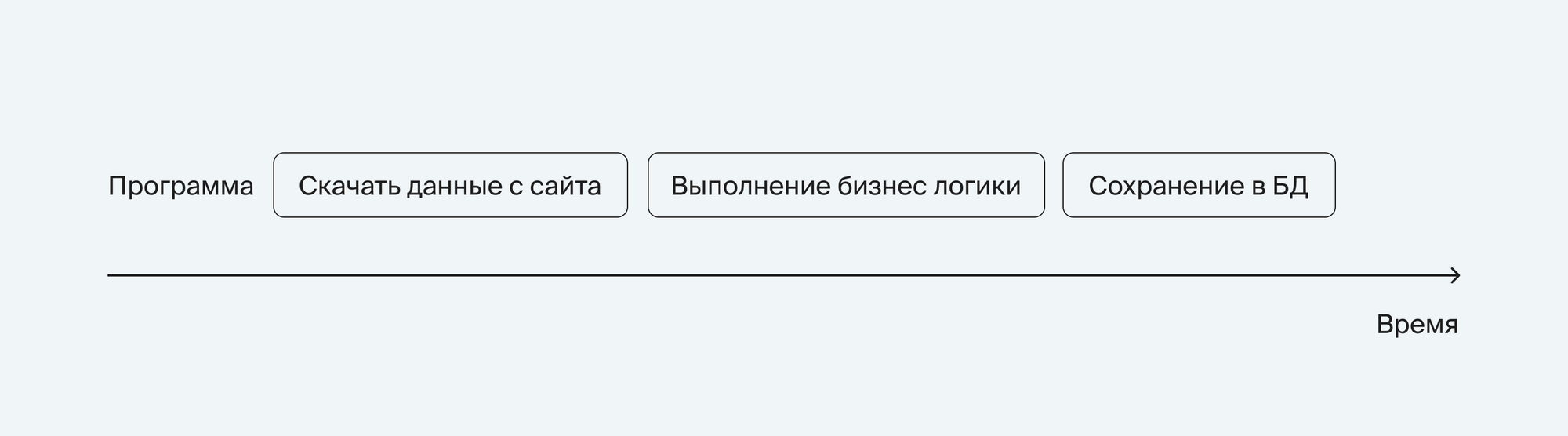
Теперь определим тип задачи в каждой ячейке:
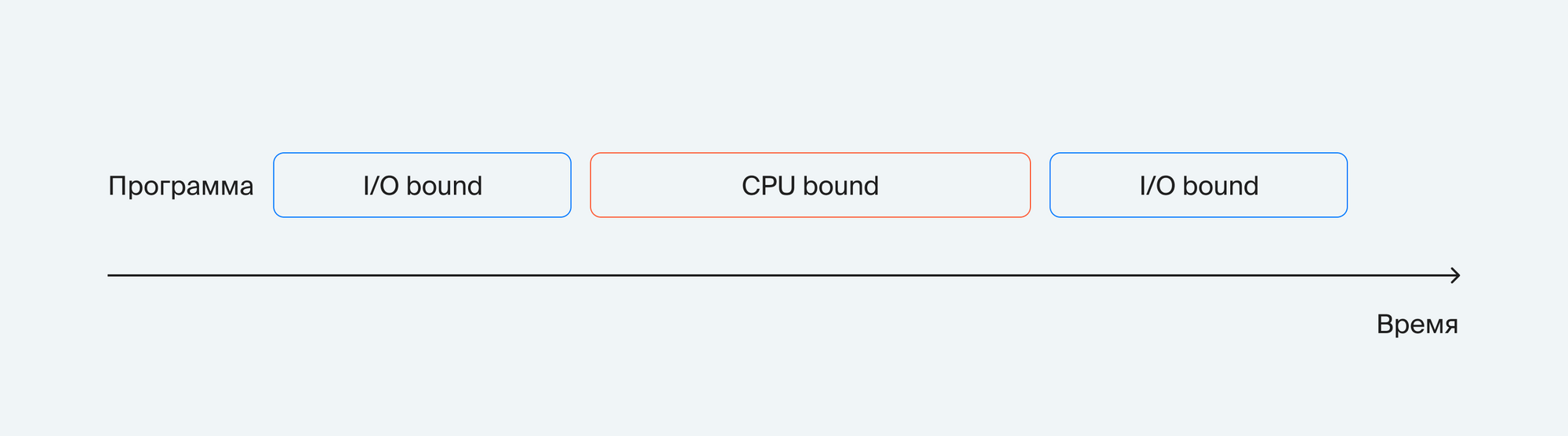
Интуитивно выполнение программы кажется примерно таким, как указано на картинке выше.
Однако, если привести картинку в соответствие с реальностью, получим следующий результат:
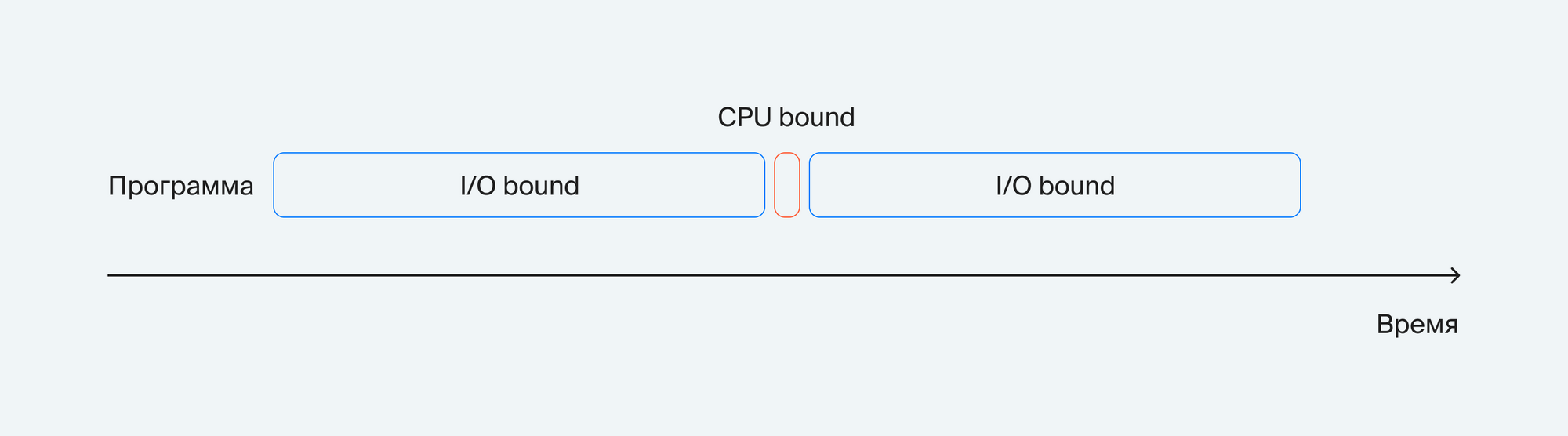
То есть бо́льшую часть времени программа ждёт ввода/вывода, а меньшая часть времени отводится на выполнение полезной работы.
Эту проблему можно решить, распараллелив код на процессы и потоки. Такой вариант поможет, но на короткое время — при таком подходе сильно увеличатся расходы ресурсов сервера. Плюс количество допустимых процессов и потоков ограничено. То есть либо закончится оперативная память под потоки, либо закончатся ядра под процессы. Вишенкой на торте становится GIL, который даёт работать только одному потоку в единицу времени. Это не позволяет эффективно использовать массовый параллелизм на потоках и добавляет свои накладные расходы, хоть и не очень заметные.
Посмотрим, как применение потоков сказывается на выполнении программы:
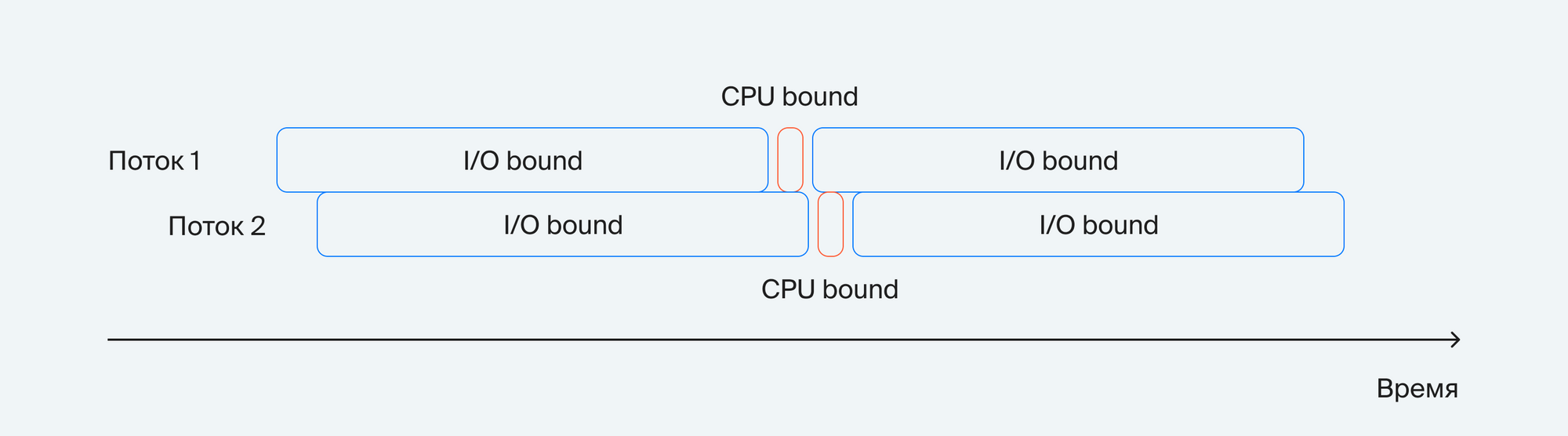
Действительно, два потока почти в два раза лучше отрабатывают I/O bound задачи. Но к сожалению, при таком подходе очень просто ошибиться и столкнуться с проблемой «состояния гонок». Можно попробовать вариант с корутинами, но его сложнее реализовать. И при таком способе не получится создать много потоков, так как они потребляют гораздо больше ОЗУ, чем корутины. Также написание многопоточного кода требует от разработчика большей внимательности, чем при написании линейного.
Стоит внимательнее присмотреться к проблеме. Всё ещё бо́льшую часть времени интерпретатор не совершает активных действий, а только ждёт ответа от ОС, завершилась ли та или иная операция ввода/вывода. В целом процессы и потоки не сильно помогут, ведь интерпретатор будет по-прежнему простаивать на каждом из них. При этом появится много накладных расходов на переключение контекста между процессами или на потребление оперативной памяти потоками, что может только ухудшить положение.
Все эти проблемы необходимо решать эффективно. С этим может помочь использование асинхронного кода.
Event-loop
Итак, вы добрались до сердца асинхронных программ в Python — цикла событий. Чтобы понять, как он работает, обратимся к простой реализации, которую предложил Девид Бизли (David Beazley) в 2009 году. Она хороша тем, что не содержит сложных конструкций, которыми сейчас обросли популярные реализации цикла событий на Python. Эта часть будет построена на разборе кода и практик, которые применяются для разработки цикла событий на основе кода Бизли, и как учитывать эти знания при разработке асинхронных приложений на Python. Код уже приведён к современной версии Python.
Начнём с архитектуры цикла событий.
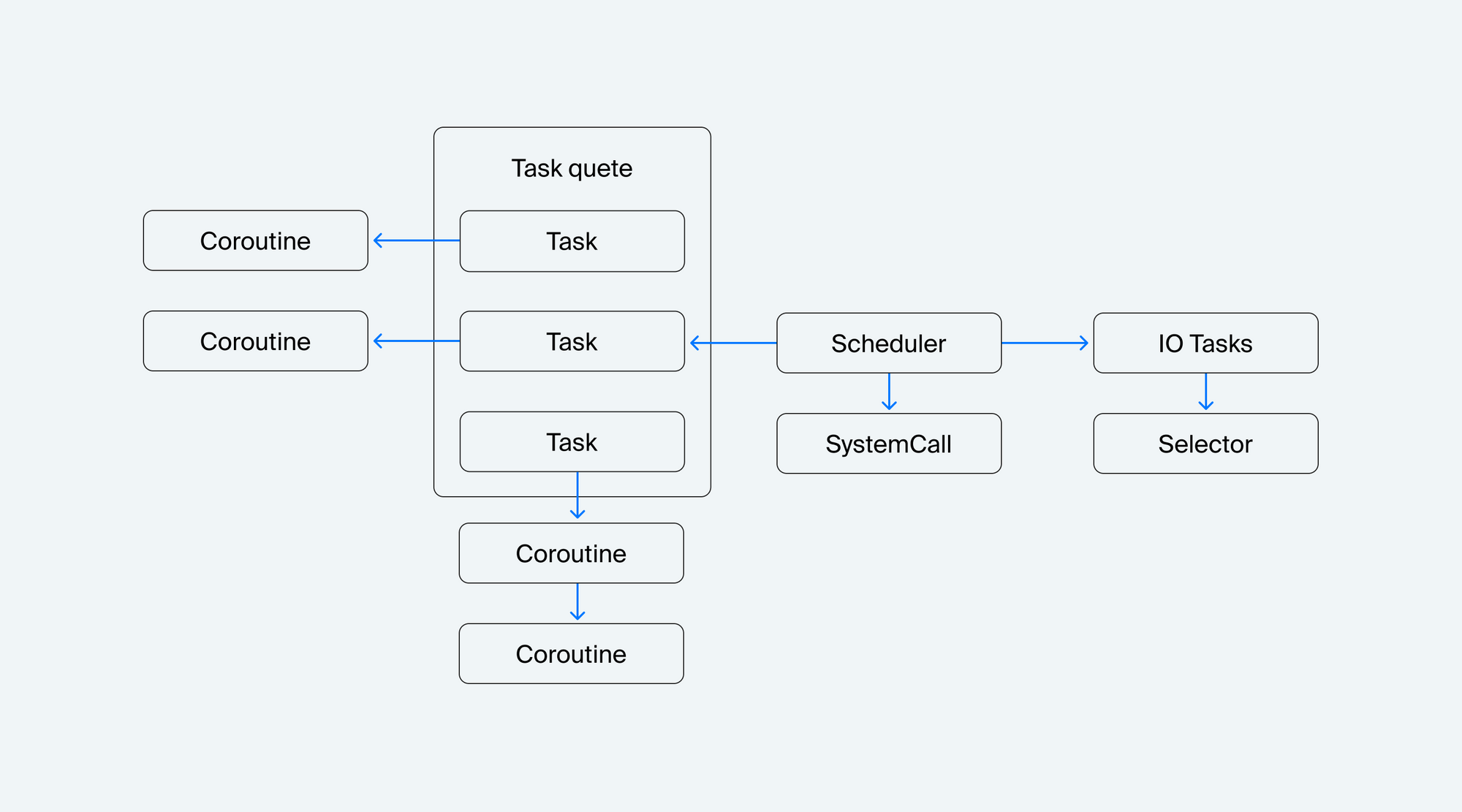
Расмотрим блоки:
- Планировщик (Scheduler). Корень всей программы. Обрабатывает задачи в очереди задач и следит за их правильным переключением между собой.
- Очередь задач (Task queue). Здесь собираются новые задачи на исполнение.
- Задача (Task). Основной блок работы цикла событий. В задачах хранится информация о выполняемой корутине. Умеет обрабатывать цепочку вложенных корутин.
- Корутина (Coroutine). Исполняемый код, которым оперирует планировщик задач.
- Системный вызов (SystemCall). Блоки кода, которые расширяют функциональность планировщика.
- Корутина для выполнения работы с I/O (I/O-tasks). В планировщик добавляется специальная задача (Task) для обработки I/O-событий от ОС.
- Селектор (Selector). Он слушает события от ОС и передаёт работу корутинам, которые ждут обработки I/O-сообщений.
Первым стоит рассмотреть работу планировщика. Его основные функции — приём и справедливая обработка списка задач.
import logging
from typing import Generator
from queue import Queue
class Scheduler:
def __init__(self):
self.ready = Queue()
self.task_map = {}
def add_task(self, coroutine: Generator) -> int:
new_task = Task(coroutine)
self.task_map[new_task.tid] = new_task
self.schedule(new_task)
return new_task.tid
def exit(self, task: Task):
del self.task_map[task.tid]
def schedule(self, task: Task):
self.ready.put(task)
def _run_once(self):
task = self.ready.get()
try:
result = task.run()
except StopIteration:
self.exit(task)
return
self.schedule(task)
def event_loop(self):
while self.task_map:
self._run_once()
Вся работа происходит в функции event_loop(), которая просто достаёт задачи одну за другой. В функции _run_once() идёт обработка итерации цикла событий, в которой поочерёдно берутся и запускаются задачи для обработки. Если задача не завершилась, то она ставится заново в очередь задач self.ready. Выполненные задачи нужно убрать из планировщика функцией exit().
Для добавления задачи используйте функцию add_task(). Она принимает корутину для выполнения и создаёт с ней задачу в планировщике. Чтобы поставить задачу напрямую в планировщик, необходимо вызвать функцию schedule().
Далее разберёмся с устройством задачи.
import types
from typing import Generator, Union
class Task:
task_id = 0
def __init__(self, target: Generator):
Task.task_id += 1
self.tid = Task.task_id # Task ID
self.target = target # Target coroutine
self.sendval = None # Value to send
self.stack = [] # Call stack
# Run a task until it hits the next yield statement
def run(self):
while True:
try:
result = self.target.send(self.sendval)
if isinstance(result, types.GeneratorType):
self.stack.append(self.target)
self.sendval = None
self.target = result
else:
if not self.stack:
return
self.sendval = result
self.target = self.stack.pop()
except StopIteration:
if not self.stack:
raise
self.sendval = None
self.target = self.stack.pop()
Сама по себе задача — обёртка над корутиной. У каждой задачи есть свой id, который учитывается в планировщике в словаре task_map. На его заполненность смотрит планировщик при выполнении задач.
Другая особенность задач — возможность выполнения корутин методом run(). Давайте посмотрим, как они выполняются в рамках задачи. Предположим, что есть корутина, которая вызывает другую корутину, а та — третью. Например, вот такой код:
def double(x):
yield x * x
def add(x, y):
yield from double(x + y)
def main():
result = yield add(1, 2)
print(result)
yield
Код является небольшой модификацией кода Бизли из его выступления. Теперь попробуем выполнить эту цепочку корутин в рамках Task.
task = Task(main())
task.run()
9
Таким же образом будут выполняться и остальные корутины в рамках планировщика. Осталось только расширить планировщик для работы с I/O-операциями.
В рамках планировщика добавляем специальную бесконечную задачу io_task перед стартом цикла событий. Эта функция имеет бесконечный цикл внутри и передаёт управление планировщику после вызова выполненных событий из селектора.
import logging
from typing import Generator, Union
from queue import Queue
from selectors import DefaultSelector, EVENT_READ, EVENT_WRITE
logger = logging.getLogger(__name__)
class Scheduler:
def __init__(self):
self.ready = Queue()
self.selector = DefaultSelector()
self.task_map = {}
def add_task(self, coroutine: Generator) -> int:
new_task = Task(coroutine)
self.task_map[new_task.tid] = new_task
self.schedule(new_task)
return new_task.tid
def exit(self, task: Task):
logger.info('Task %d terminated', task.tid)
del self.task_map[task.tid]
# I/O waiting
def wait_for_read(self, task: Task, fd: int):
try:
key = self.selector.get_key(fd)
except KeyError:
self.selector.register(fd, EVENT_READ, (task, None))
else:
mask, (reader, writer) = key.events, key.data
self.selector.modify(fd, mask | EVENT_READ, (task, writer))
def wait_for_write(self, task: Task, fd: int):
try:
key = self.selector.get_key(fd)
except KeyError:
self.selector.register(fd, EVENT_WRITE, (None, task))
else:
mask, (reader, writer) = key.events, key.data
self.selector.modify(fd, mask | EVENT_WRITE, (reader, task))
def _remove_reader(self, fd: int):
try:
key = self.selector.get_key(fd)
except KeyError:
pass
else:
mask, (reader, writer) = key.events, key.data
mask &= ~EVENT_READ
if not mask:
self.selector.unregister(fd)
else:
self.selector.modify(fd, mask, (None, writer))
def _remove_writer(self, fd: int):
try:
key = self.selector.get_key(fd)
except KeyError:
pass
else:
mask, (reader, writer) = key.events, key.data
mask &= ~EVENT_WRITE
if not mask:
self.selector.unregister(fd)
else:
self.selector.modify(fd, mask, (reader, None))
def io_poll(self, timeout: Union[None, float]):
events = self.selector.select(timeout)
for key, mask in events:
fileobj, (reader, writer) = key.fileobj, key.data
if mask & EVENT_READ and reader is not None:
self.schedule(reader)
self._remove_reader(fileobj)
if mask & EVENT_WRITE and writer is not None:
self.schedule(writer)
self._remove_writer(fileobj)
def io_task(self) -> Generator:
while True:
if self.ready.empty():
self.io_poll(None)
else:
self.io_poll(0)
yield
def schedule(self, task: Task):
self.ready.put(task)
def _run_once(self):
task = self.ready.get()
try:
result = task.run()
except StopIteration:
self.exit(task)
return
self.schedule(task)
def event_loop(self):
self.add_task(self.io_task())
while self.task_map:
self._run_once()
Код значительно разросся, но на самом деле ничего страшного не произошло. Рассмотрим изменения в порядке вызовов. В рамках планировщика добавляем специальную бесконечную задачу io_task перед стартом цикла событий. Эта функция имеет бесконечный цикл внутри и передаёт управление планировщику после вызова выполненных событий из селектора.
Рассмотрим подробнее устройство io_task. Если очередь задач пустая, то timeout для ожидания событий из селектора ставится в режим «до тех пор, пока не будет новых событий». В остальных случаях ставим таймаут 0, чтобы получить все события от ОС сразу же. Такую особенность работы этого метода рассмотрим чуть позже.
Если из селектора пришли новые события, то обрабатываем их и убираем из обработки файловые дескрипторы. Важный момент — хранение данных о задачах в селекторе. Одна и та же задача может ожидать чтения данных и пытаться записать новые данные. Именно поэтому в поле data хранится кортеж (reader, writer).
По сути, event_loop должен предоставлять интерфейс для работы с сокетами. Таких метода всего четыре:
wait_for_read,wait_for_write,_remove_reader,_remove_writer.
Эти методы позволяют работать с циклом событий, встроенным в ОС.
Работа с I/O для цикла событий — «пристройка сбоку» для обработки сетевых запросов. То есть основное назначение цикла событий в Python — обработка функций корутин, которые могут никуда не ходить по сети, а работать только с файловой системой.
Осталось разобраться с конструкцией SystemCall. Так как изначально цикл событий больше напоминает работу ОС, должен быть механизм прерываний, чтобы передать управление ОС. В асинхронном коде прерывание обеспечивается с помощью yield. После переключения контекста может вызываться системная функция для исполнения. Например, для создания новых задач можно использовать вот такой код:
class SystemCall:
def handle(self, sched: Scheduler, task: Task):
pass
class NewTask(SystemCall):
def __init__(self, target: Generator):
self.target = target
def handle(self, sched: Scheduler, task: Task):
tid = sched.add_task(self.target)
task.sendval = tid
sched.schedule(task)
В Scheduler достаточно добавить небольшой фрагмент кода:
class Scheduler:
...
def _run_once(self):
task = self.ready.get()
try:
result = task.run()
if isinstance(result, SystemCall):
result.handle(self, task)
return
except StopIteration:
self.exit(task)
return
self.schedule(task)
А в Task добавляем небольшое условие при выполнении корутин:
import types
from typing import Generator, Union
class Task:
...
def run(self):
while True:
try:
result = self.target.send(self.sendval)
if isinstance(result, SystemCall):
return result
...
Что всё это значит? Разберёмся на примере NewTask. Этот класс предоставляет интерфейс для создания новых задач в цикле событий. Такой интерфейс позволяет абстрагировать клиентский код. Это эмуляция защищённой среды ОС, когда последняя предоставляет безопасные методы для работы с ядром. Такие методы не дают клиентскому коду мешать другим программам в ОС. Таким же образом можно сделать KillTask или WaitTask.
Осталась последняя проблема — блокирующие операции. Из-за них код не может асинхронно обрабатывать события и цикл событий ждёт выполнения на каждой функции. Есть вариант решения проблемы:
- Сделать неблокирующими сокеты через
socket.setblocking(False).
Asyncio
Теперь у нас достаточно знаний, чтобы без труда освоить основную встроенную библиотеку для асинхронного программирования — asyncio.
С версии Python 3.5 в язык добавили специальный синтаксис — async/await. Он позволяет использовать «нативные» корутины, которые теперь являются частью языка. Они разделяют генераторы от асинхронного кода, что позволяет создавать асинхронные генераторы и ускорять работу асинхронного кода.
Посмотрим, как выглядит простая программа с использованием async/await.
import random
import asyncio
async def func():
r = random.random()
await asyncio.sleep(r)
return r
async def value():
result = await func()
print(result)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(value())
loop.close()
В целом изменений немного. Переменная loop — это не что иное, как планировщик задач. Он работает по схожим принципам с тем, что рассматривался ранее. Теперь все функции переключаются с помощью await.
Познакомимся с основными функциями asyncio, которые часто встречаются на практике:
gather— выполняет список корутин одновременно и дожидается результата выполнения всех корутин.sleep— заставляет корутину уснуть на определённое количество секунд.wait/wait_for— удобные функции, чтобы дождаться выполнения уже запущенной корутины.
Также стоит ознакомиться с основными функциями event_loop:
get_event_loop— получить новый объектevent_loopили тот, что уже существует. При этом одновременно может существовать только один объектevent_loop.run_until_complete/run— удобные функции для запуска и проверки асинхронных функций.shutdown_asyncgens— одна из самых недооценённых функций цикла событий, которая позволяет правильно завершить выполнение цикла событий и всех корутин.call_soon— позволяет запланировать выполнение корутины, но не ждать её выполнения. Таким образом можно вечно ставить на выполнение одну и ту же функцию.
Теперь стоит поговорить про ключевые различия между asyncio и предложенной реализацией цикла событий. Asyncio работает на функциях обратного вызова или колбэках (callback). Этот механизм запускает задачи «честнее», чем текущий планировщик. Каждая корутина по-честному ставится в очередь и исполняется. В простом планировщике переключения не произойдёт, пока вся цепочка корутин не выполнится, что блокирует выполнение остальных задач. Однако, у колбэков есть и свой недостаток — callback hell. Это состояние, когда после вызова каждой функции нужно вызвать ещё одну функцию и ещё одну функцию... Получаются интересные фрагменты кода:
func1.add_callback(
func2.add_callback(
func3.add_callback(func4)
)
)
К счастью, этого удаётся избежать через синтаксис async/await.
await func4()
await func3()
await func2()
await func1()
Такое поведение возможно благодаря введению класса Future. По сути, такие объекты спасают от колбэков и делают код более линейным. В современных версиях Python Future-объекты для нативных корутин не нужны.